
Neo4j SandBox レコメンド プロジェクトを体験してみた #Neo4j #SandBox #GDS
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
概要
Neo4j を使用したレコメンデーションアルゴリズムについて調べていたら、 sandbox に Recommendations プロジェクト があったので、使ってみました。
備忘録として、プロジェクトのシナリオを日本語でまとめたので公開します。

目次
目的
- Cypher クエリおよび GDS(Graph Data Science) ライブラリを使用したレコメンデーションの概要説明
予備知識
Neo4j と GDS の概要はこちらをご参照ください。
Neo4j Sandboxから下記のプロジェクトを選択して開始します。
シナリオ0: イントロダクション
レコメンデーション
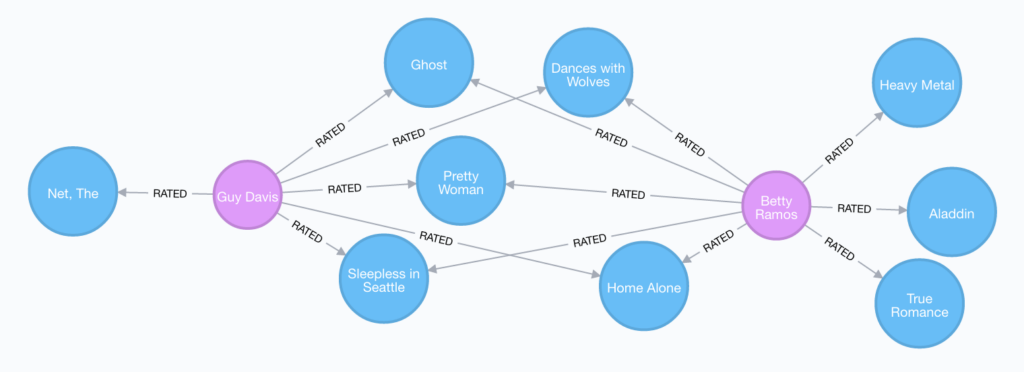
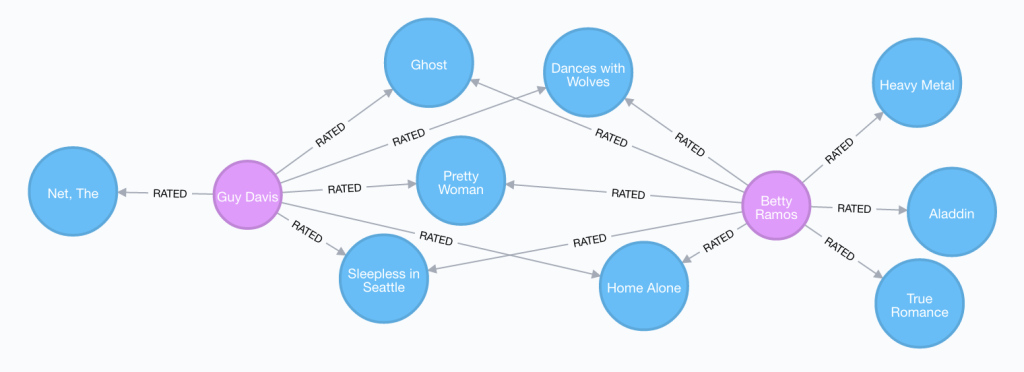
このシナリオでは、映画および映画の評価のデータセットを使用して、グラフベースのリアルタイムなパーソナライズされた商品のレコメンデーションを行う方法の概要を見ていきます。
パーソナライズされた商品のレコメンデーションにより、集客力が増し、販売率が改善し、より良いユーザー体験を提供できます。
このシナリオで紹介する方法は、異なるタイプの商品やコンテンツに幅広く応用することができます。
グラフベースのレコメンデーション
パーソナライズされたレコメンデーションの生成は、グラフデータベースの最も一般的なユースケースの1つです。
グラフを使用したレコメンデーションの主要なメリットは下記の通りです。
パフォーマンス
Neo4jでは各ノードが隣接するノードやリレーションシップに直接格納される "index-free adjacency"※1という仕組みを採用しており、高速な検索が可能であるため、レコメンデーションをリアルタイムで計算することができます。
レコメンデーションが常に適切で、最新の情報を反映することを保証します。
データモデル
ラベル付きプロパティグラフモデルによって、複数のデータソースからのデータセットを結合することが容易になります。
企業は、これまで分離されていたデータサイロから価値を引き出すことができるようになります。
シナリオ1: 映画のオープングラフデータモデル
プロパティグラフモデル
グラフデータベースのデータモデルは、ラベル付きプロパティグラフモデルと呼ばれます。
| 要素 | 説明 |
| ノード | ノードはデータの実体を表します。 |
| ラベル | 各ノードにはノードのタイプを指定する1つ以上のラベルを付けることができます。 |
| リレーションシップ | リレーションシップはノード同士を結合します。単一の方向およびタイプを持ちます。 |
| プロパティ | プロパティはキーとバリューのペアをなし、各ノードと各リレーションシップに格納されます。 |
データサイロによるデータの分離を解除する
このユースケースでは、グラフを使用して複数のデータサイロからのデータを結合します。
| データ種別 | 説明 |
| 商品カタログ | 映画を説明するデータは、商品カタログのデータサイロから取得。 |
| ユーザーの購買履歴/レビュー | ユーザーの購買履歴やレビューデータは、ユーザーまたはトランザクションのデータサイロから取得。 |
グラフを使用して上記のデータサイロからのデータを結合することによって、データセットを横断するクエリを走らせて、パーソナライズされた商品のレコメンデーションを生成することができるようになります。
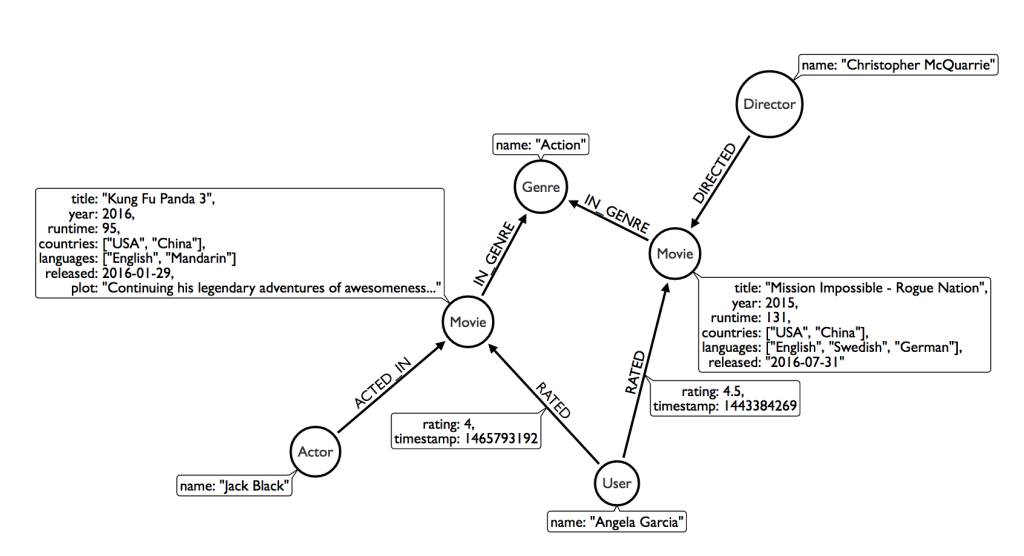
シナリオ2: Cypher 入門
ラベル付きプロパティグラフで作業するためには、グラフを扱うクエリ言語が必要です。
グラフパターン
Cypher はグラフのクエリ言語であり、グラフパターンを中心にしています。
グラフパターンは Cypher ではアスキーアートのような構文によって表現されます。
| 要素 | 説明 | 例 |
| ノード | ノードは丸カッコ内に定義され、オプションでノードラベルを指定できます。 | (:Movie) |
| リレーションシップ | リレーションシップは角カッコ内に定義され、オプションでタイプと方向を指定できます。 | (:Movie)<-[:RATED]-(:User) |
| エイリアス | グラフ要素はエイリアスにバインドでき、あとでクエリで参照できます。 | (m:Movie)<-[r:RATED]-(u:User) |
上記のグラフパターンにフィルタを適用し、適合するパスを絞り込みます。
ブール論理演算子、正規表現、文字列比較演算子が使用できます。
COUNTなどの集計関数を使用する場合のために、暗黙的にグルーピングが行われます。
Cypher の構文を学ぶための参考資料として、Cypher Refcardをぜひご活用ください。
Cypherステートメントの分析
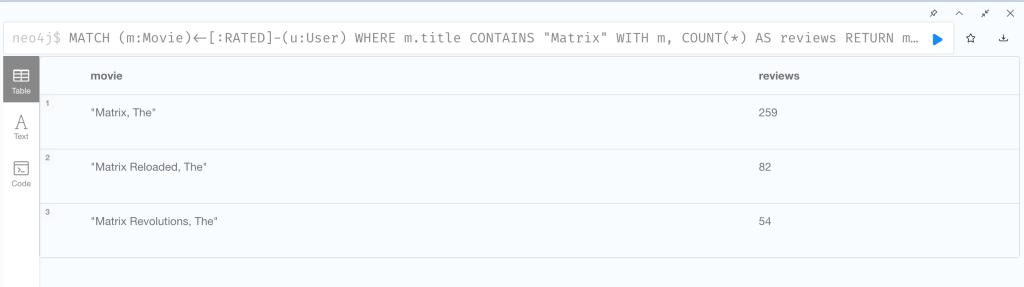
「『Matrix』シリーズの映画には何件のレビューがありますか?」という問いに答えるCypherクエリを見てみましょう。
もしこれが複雑に思えても心配する必要はありません。Cypher の理解を深めながら、進めていきたいと思います。
MATCH (m:Movie)<-[:RATED]-(u:User) WHERE m.title CONTAINS "Matrix" WITH m, COUNT(*) AS reviews RETURN m.title AS movie, reviews ORDER BY reviews DESC LIMIT 5;
| 操作 | Cypher | 説明 |
| 検索 | MATCH (m:Movie)<-[:RATED]-(u:user) | パターンにマッチするパスを検索します。 |
| フィルタ | WHERE m.title CONTAINS "Matrix" | 検索したパスを指定した条件にマッチするものだけに絞り込みます。 |
| 集計 | WITH m, COUNT(*) AS reviews | フィルタにマッチしたパスの数をカウントし、変数に格納します。 |
| 値を返す | RETURN m.title as movie, reviews | Cypher ステートメントが最終的に返すデータを指定します。 |
| ソート | ORDER BY reviews DESC | レビュー数の降順にソートすることを指定します。 |
| 制限値 | LIMIT 5; | 最初の5つのレコードのみを返すことを指定します。 |
このクエリの実行結果は下記のようになります。
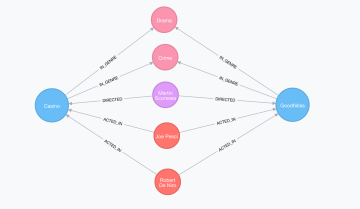
シナリオ3: レコメンデーションアルゴリズムの2つのアプローチ
レコメンデーションアルゴリズムには2つの基本的なアプローチがあります。
 |
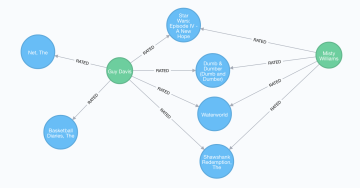 |
| コンテンツベースフィルタリングの模式図 | 協調フィルタリングの模式図 |
コンテンツベースフィルタリング
ユーザーが閲覧したり、高く評価したり、以前に購入したりしている映画に似ている映画をレコメンドします。
ECサイトなどの「あなたが今見ている商品に似ている商品を表示します」などという表示に対応する機能です。
協調フィルタリング
ネットワークの中の他のユーザーの好みや評価や行動を使用して、レコメンドする映画を見つけます。
ECサイトなどの「この商品を買ったユーザーは、こちらの商品も買っています」などという表示に対応する機能です。
シナリオ4: コンテンツベースフィルタリング
コンテンツベースフィルタリングの目的は、アイテムの属性や特徴を使用して、類似のアイテムを見つけることです。
このシナリオの映画のデータを使用するなら、類似性を定義する方法の一つとして、共通のジャンルを持つという特徴を用いる方法があります。
共通のジャンルに基づく類似性
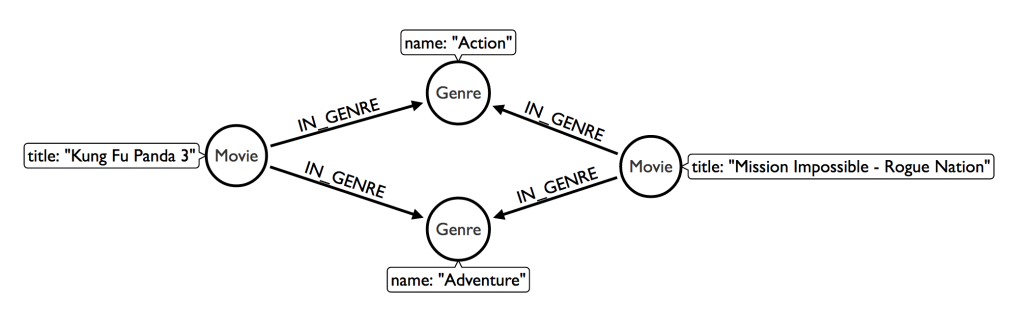
イメージを掴むために、まずは単純にジャンルの共通性から『Inception』に最も近い映画を探します。
// Find similar movies by common genres MATCH (m:Movie)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) WHERE m.title = "Inception" WITH rec, COLLECT(g.name) AS genres, COUNT(*) AS commonGenreCount RETURN rec.title, genres, commonGenreCount ORDER BY commonGenreCount DESC LIMIT 10;
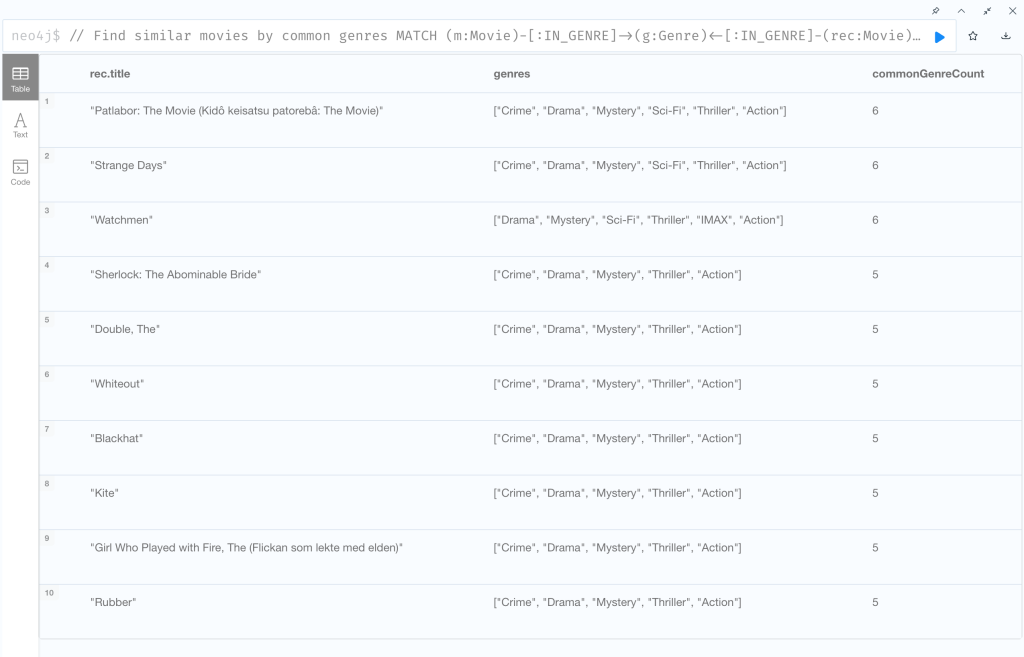
レコメンドリストが作成できました。
『Inception』を見たなら、『Patlabor: The Movie』『Strange Days』『Watchmen』がおすすめという結果ですね。
いかかでしょうか? 共通ジャンルだけではレコメンド結果は微妙と言わざるを得ません。
これではレコメンドの精度は低いので、ユーザの評価を取り入れて改良してみます。
ジャンルに基づくパーソナライズされたレコメンデーション
ユーザーが既に評価した映画の情報を使用して、類似の映画をレコメンドすることができます。
ユーザーが評価した映画と共通のジャンルを持つ映画の情報をもとにおすすめ度を計算し、類似する映画をレコメンドします。
// Content recommendation by overlapping genres
MATCH (u:User {name: "Angelica Rodriguez"})-[r:RATED]->(m:Movie),
(m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)
WHERE NOT EXISTS( (u)-[:RATED]->(rec) )
WITH rec, [g.name, COUNT(*)] AS scores
RETURN rec.title AS recommendation, rec.year AS year,
COLLECT(scores) AS scoreComponents,
REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score
ORDER BY score DESC LIMIT 10
| Cypher | 説明 |
| MATCH (u:User {name: "Angelica Rodriguez"})-[r:RATED]->(m:Movie), (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) |
Angelica Rodriguezが評価した映画と共通のジャンルを持つ映画を取得して、対象の映画とする |
| WHERE NOT EXISTS( (u)-[:RATED]->(rec) ) | ただし、Angelica Rodriguez自身が評価したものは含めない |
| WITH rec, [g.name, COUNT(*)] AS scores | 対象の映画のスコアコンポーネントを宣言する スコアコンポーネントは次の2要素からなる 1. 対象の映画の属する各共通ジャンル名 2. 各共通ジャンルに属する映画の内、Angelica Rodriguezが評価した映画の数(ジャンルのスコア) |
| RETURN rec.title AS recommendation, rec.year AS year, COLLECT(scores) AS scoreComponents, REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score |
次の要素を返り値とする 1. 対象の映画のタイトル 2. 対象の映画の公開年 3. 対象の映画のスコアコンポーネント 4. 対象の映画の属するジャンルのスコアの合計値 |
| ORDER BY score DESC LIMIT 10 | ジャンルのスコアの合計値の降順でソートし、上位10件を返す |
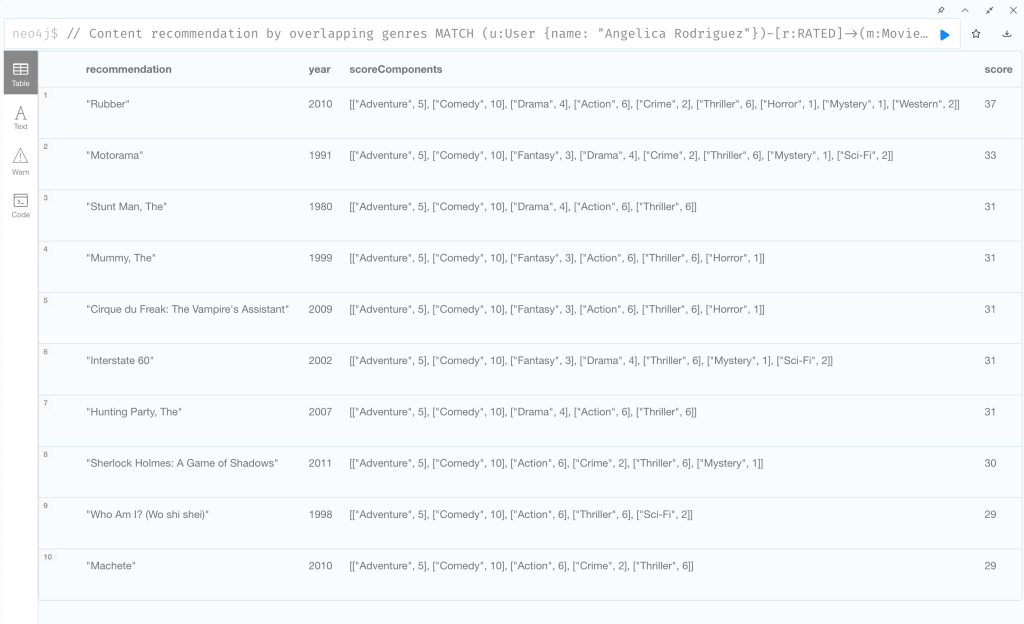
さきほどのレコメンド結果とは全く異なり、ユーザ自身のお気に入りジャンルが多い映画をおすすめするレコメンドリストになりました。
これまでは映画ジャンルのみからレコメンドを作成しましたが、次はジャンル以外の要素も考慮に入れて高度なレコメンドをしてみたいと思います。
重み付けされたコンテンツのアルゴリズム
ジャンルの他にも類似度を計算するために考慮できる特徴は多くあります。俳優や監督などです。
ジャンルや俳優や監督などの共通項の数をもとに、加重和でおすすめ度を計算し、レコメンドの精度を上げましょう。
重複している特徴の数と種類をもとに、加重和を計算します。
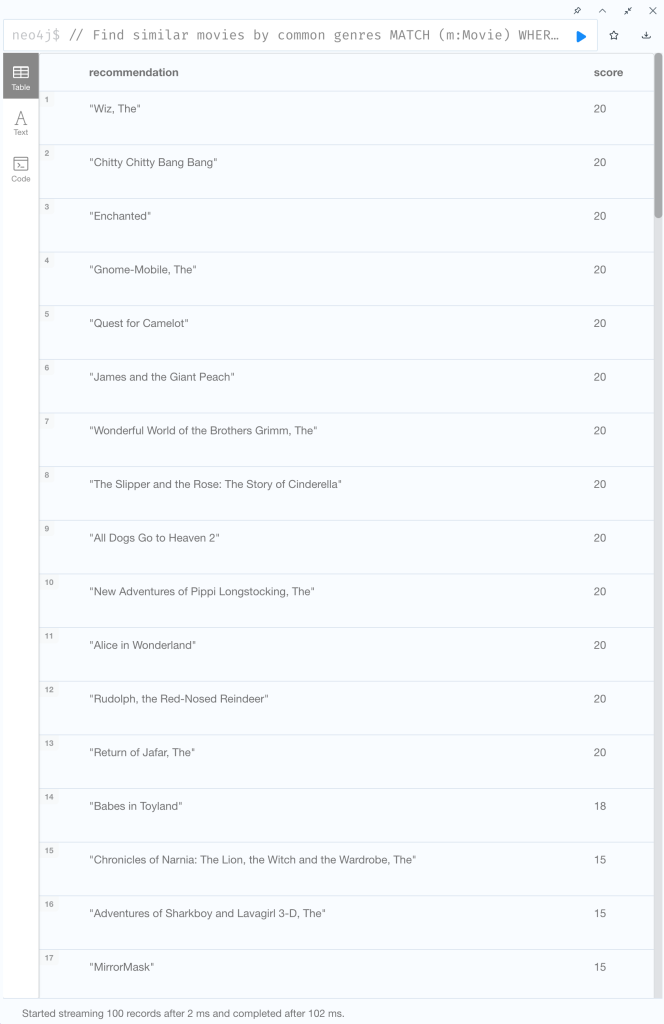
// Find similar movies by common genres MATCH (m:Movie) WHERE m.title = "Wizard of Oz, The" MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) WITH m, rec, COUNT(*) AS gs OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec) WITH m, rec, gs, COUNT(a) AS as OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Director)-[:DIRECTED]->(rec) WITH m, rec, gs, as, COUNT(d) AS ds RETURN rec.title AS recommendation, (5*gs)+(3*as)+(4*ds) AS score ORDER BY score DESC LIMIT 100
| Cypher | 説明 |
| MATCH (m:Movie) WHERE m.title = "Wizard of Oz, The" MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) |
The Wizard of Ozと共通のジャンルを持つ映画を取得し、対象の映画とする |
| WITH m, rec, COUNT(*) AS gs | 対象の映画がThe Wizard of Ozと共通して持つジャンルの数gsを求める |
| OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec) WITH m, rec, gs, COUNT(a) AS as |
対象の映画がThe Wizard of Ozと共通して持つ俳優の数asを求める |
| OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Director)-[:DIRECTED]->(rec) WITH m, rec, gs, as, COUNT(d) AS ds |
対象の映画がThe Wizard of Ozと共通して持つ監督の数dsを求める |
| RETURN rec.title AS recommendation, (5*gs)+(3*as)+(4*ds) AS score ORDER BY score DESC LIMIT 100 | 対象の映画のタイトルおよびスコア (5*gs)+(3*as)+(4*ds) を返り値とする スコアの降順にソートし上位100件を返す |
類似性メトリクスを使用するモデル
これまで、類似度を評価する方法として、共通の特徴の数を使用してきました。
ここでは、類似性メトリクスを使用して類似度を定量化するより信頼性のある方法を考えましょう。
類似性メトリクスは一般的なパーソナライズされたレコメンデーションに使用される重要な構成要素であり、これを用いて2つのアイテムがどれだけ似ているかを定量化できます。
また、のちほど見るように、2人のユーザーの好みの傾向がどれだけ似ているかを定量化するのにも用いられます。
Jaccard 係数
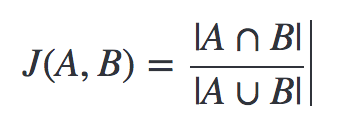
類似度を量る指標として良く利用される指標の1つに「Jaccard 係数」というものがあります。
Jaccard 係数は0から1までの数字を取り、2つの集合(=例えば映画のジャンルのリスト)がどの程度類似しているかを示します。
2つの集合が全く同一の場合 Jaccard 係数は1です。2つの集合が共通の要素を持たない場合、Jaccard 係数は0です。
Jaccard 係数は2つの集合の積集合のサイズを2つの集合の和集合のサイズで割ったものです。※2
映画のジャンルの集合の Jaccard 係数を計算することで、2つの映画がどの程度類似しているかを判断できます。
映画のジャンルの集合の Jaccard 係数を計算して、どの映画が『Inception』と最も類似しているのか調べてみましょう。
MATCH (m:Movie {title: "Inception"})-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(other:Movie)
WITH m, other, COUNT(g) AS intersection
MATCH (m)-[:IN_GENRE]->(mg:Genre)
WITH m, other, intersection, COLLECT(mg.name) AS s1
MATCH (other)-[:IN_GENRE]->(og:Genre)
WITH m, other, intersection, s1, COLLECT(og.name) AS s2
WITH m, other, intersection, s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2
RETURN m.title, other.title, s1, s2, ((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100
| Cypher | 説明 |
| MATCH (m:Movie {title: "Inception"})-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(other:Movie) | Inceptionと共通のジャンルを持つ映画を取得し、対象の映画とする |
| WITH m, other, COUNT(g) AS intersection | 共通のジャンルの数intersectionを求める |
| MATCH (m)-[:IN_GENRE]->(mg:Genre) WITH m, other, intersection, COLLECT(mg.name) AS s1 |
Inceptionが属するジャンルのリストs1を求める |
| MATCH (other)-[:IN_GENRE]->(og:Genre) WITH m, other, intersection, s1, COLLECT(og.name) AS s2 |
対象の映画が属するジャンルのリストs2を求める |
| WITH m, other, intersection, s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2 | s1にs2にあってs1にはない要素を加えて和集合unionを作る |
| RETURN m.title, other.title, s1, s2, ((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100 | 次の要素を返り値とする 1. InceptionのタイトルとInceptionが属するジャンルのリストs1 2. 対象の映画のタイトルと対象の映画が属するジャンルのリストs2 3. intersectionをunionのサイズで割ることにより得られるjaccard係数 jaccard係数の降順にソートし上位100件を返す |
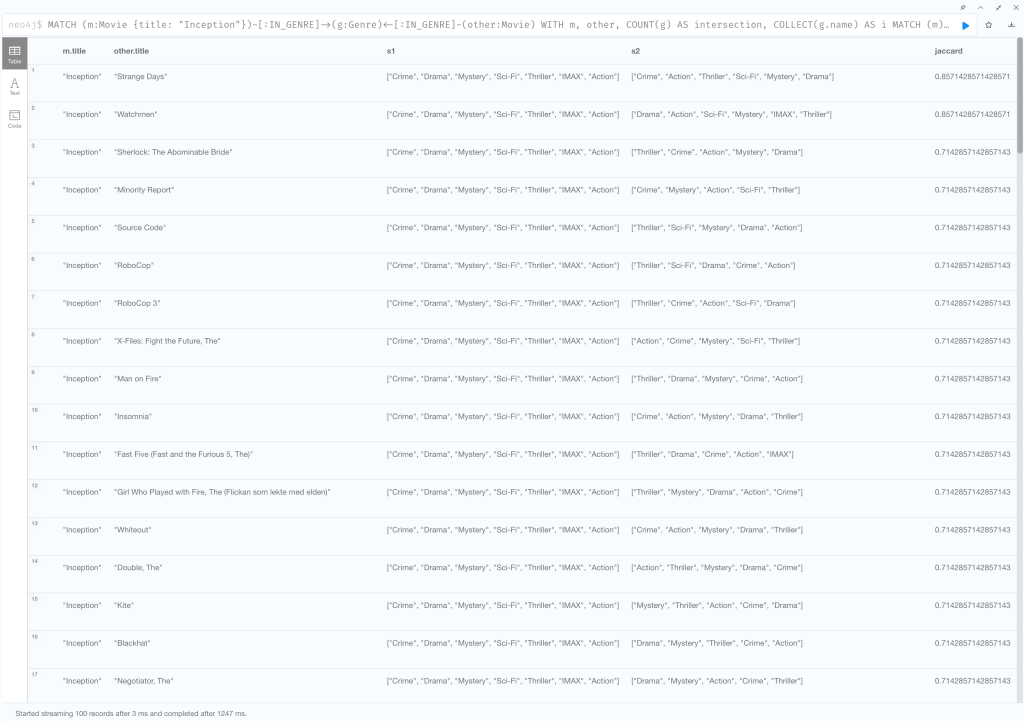
これと同じアプローチを(ジャンル、俳優、監督などの)全ての映画の特徴に適用することができます。
MATCH (m:Movie {title: "Inception"})-[:IN_GENRE|ACTED_IN|DIRECTED]-(t)<-[:IN_GENRE|ACTED_IN|DIRECTED]-(other:Movie)
WITH m, other, COUNT(t) AS intersection
MATCH (m)-[:IN_GENRE|ACTED_IN|DIRECTED]-(mt)
WITH m, other, intersection, COLLECT(mt.name) AS s1
MATCH (other)-[:IN_GENRE|ACTED_IN|DIRECTED]-(ot)
WITH m, other, intersection, s1, COLLECT(ot.name) AS s2
WITH m, other, intersection, s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2
RETURN m.title, other.title, s1, s2, ((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100
| Cypher | 説明 |
| MATCH (m:Movie {title: "Inception"})-[:IN_GENRE|ACTED_IN|DIRECTED]-(t)<-[:IN_GENRE|ACTED_IN|DIRECTED]-(other:Movie) | Inceptionと共通の属性(ジャンル、俳優、監督)を持つ映画を取得し、対象の映画とする |
| WITH m, other, COUNT(t) AS intersection | 共通の属性の数intersectionを求める |
| MATCH (m)-[:IN_GENRE|ACTED_IN|DIRECTED]-(mt) WITH m, other, intersection, COLLECT(mt.name) AS s1 |
Inceptionが保持する属性のリストs1を求める |
| MATCH (other)-[:IN_GENRE|ACTED_IN|DIRECTED]-(ot) WITH m, other, intersection, s1, COLLECT(ot.name) AS s2 |
対象の映画が保持する属性のリストs2を求める |
| WITH m, other, intersection, s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2 | s1にs2にあってs1にはない要素を加えて和集合unionを作る |
| RETURN m.title, other.title, s1, s2, ((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100 | 次の要素を返り値とする 1. InceptionのタイトルとInceptionが保持する属性のリストs1 2. 対象の映画のタイトルと対象の映画が保持する属性のリストs2 3. intersectionをunionのサイズで割ることにより得られるjaccard係数 jaccard係数の降順にソートし上位100件を返す |

コンテンツベースフィルタリングの例示は以上です。
コンテンツベースフィルタリングは、アイテムの属性や特徴を使用して、類似のアイテムを見つけるアプローチでした。
既に述べたように、もう一つのアプローチとして協調フィルタリングと言われるものがあります。
協調フィルタリングは、似ているユーザーは好みの傾向も似ているという仮定のもと、ユーザーによるアイテムの評価の情報を利用してレコメンドを行うものです。
シナリオ5: 協調フィルタリング
このシナリオで使用しているデータには、ユーザーによる映画の評価のデータも含まれています。
協調フィルタリングのアプローチは、アイテムの評価の情報を利用してレコメンドを行うものです。
協調フィルタリングは、次のステップにより行います。
- ネットワークの中で似ているユーザーを探す。
- 似ているユーザーは好みの傾向も似ていると仮定し、似ているユーザーが好む映画をレコメンドする。
準備
ユーザー「Misty William」が行ったすべての評価を表示してみましょう。
// Show all ratings by Misty Williams
MATCH (u:User {name: "Misty Williams"})
MATCH (u)-[r:RATED]->(m:Movie)
RETURN *;
Misty Williams が行った評価の平均値を求めてみましょう。
// Show all ratings by Misty Williams
MATCH (u:User {name: "Misty Williams"})
MATCH (u)-[r:RATED]->(m:Movie)
RETURN avg(r.rating) AS average;

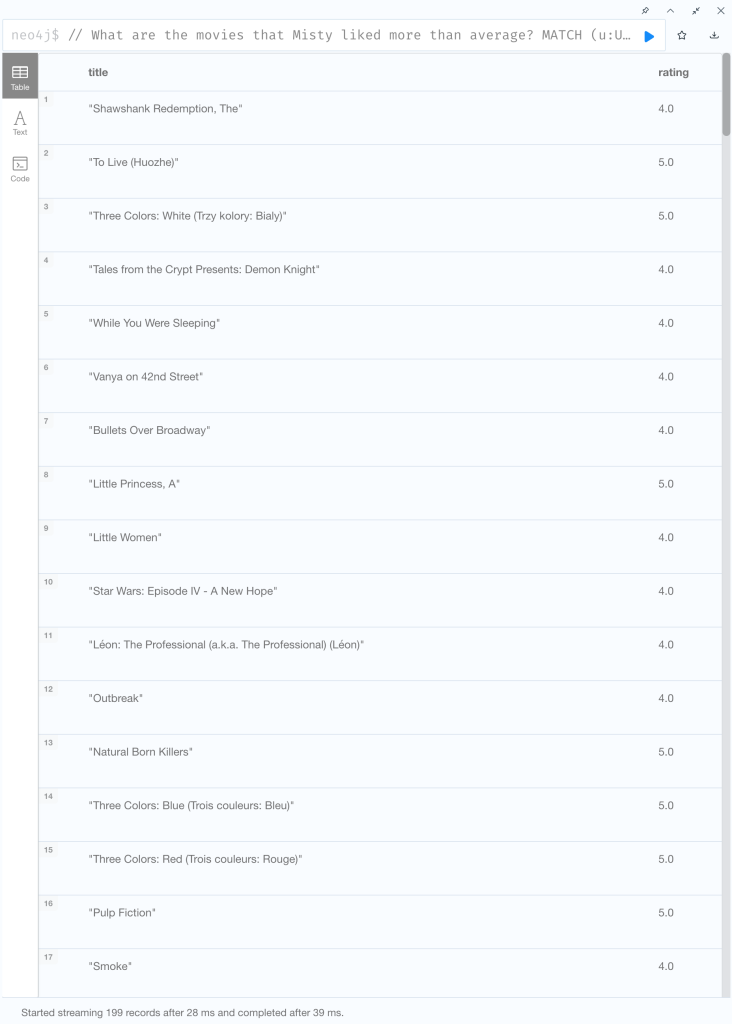
Misty Williams が平均より気に入っているのはどのような映画か調べてみましょう。
// What are the movies that Misty liked more than average?
MATCH (u:User {name: "Misty Williams"})
MATCH (u)-[r:RATED]->(m:Movie)
WITH u, avg(r.rating) AS average
MATCH (u)-[r:RATED]->(m:Movie)
WHERE r.rating > average
RETURN m.title AS title, r.rating AS rating;
シンプルな協調フィルタリング
まず、次のようなシンプルなアプローチを考えます。
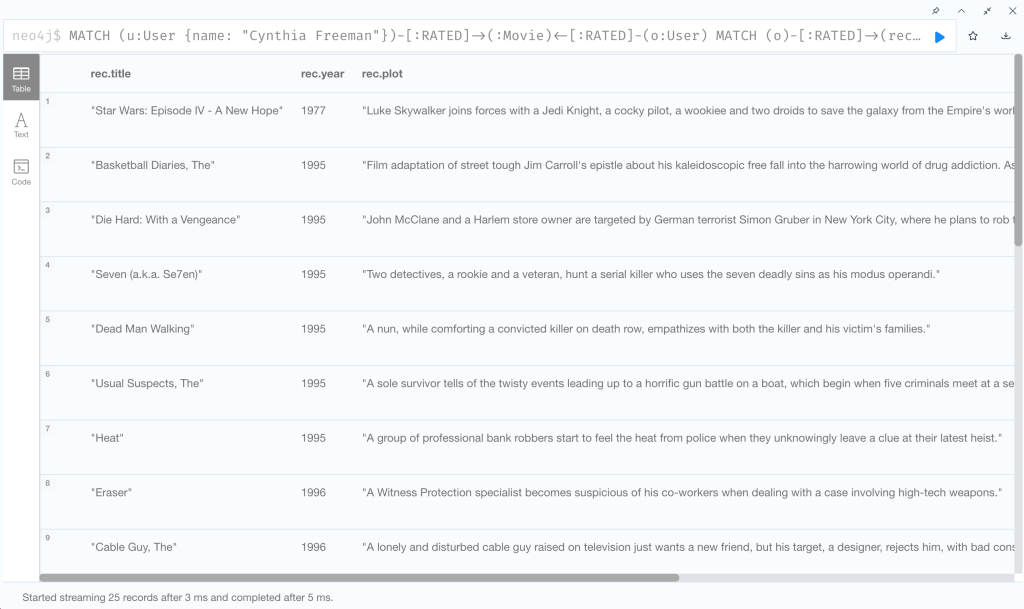
すなわち、ユーザー「Cynthia Freeman」がある映画を評価しているとき、その映画を同様に評価している別のユーザーが評価している映画の内、Cynthia Freeman がまだ評価していない映画をレコメンドします。
MATCH (u:User {name: "Cynthia Freeman"})-[:RATED]->(:Movie)<-[:RATED]-(o:User)
MATCH (o)-[:RATED]->(rec:Movie)
WHERE NOT EXISTS( (u)-[:RATED]->(rec) )
RETURN rec.title, rec.year, rec.plot
LIMIT 25
言うまでもなく、このアプローチは単純すぎますし、このクエリには多くの問題点があります。
例えば、人気度に応じた正規化がされていなかったり、評価値を考慮していなかったりします。
以降の例ではこれらの欠点について改善を行っていきます。
まず、協調フィルタリングとコンテンツベースフィルタリングを組み合わせたアプローチを試してみましょう。
ユーザーが好きなジャンルのみを考慮するモデル
多くのレコメンドシステムは協調フィルタリングとコンテンツベースフィルタリングの両方のアプローチを使用します。
一例として、映画のジャンルの情報とユーザーの評価値の情報を組み合わせてレコメンドを行う方法を試みます。
ユーザーが平均以上の評価をした映画の属するジャンルの情報をもとに、映画のおすすめ度を計算してみましょう。
MATCH (u:User {name: "Andrew Freeman"})-[r:RATED]->(m:Movie)
WITH u, avg(r.rating) AS mean
MATCH (u)-[r:RATED]->(m:Movie)-[:IN_GENRE]->(g:Genre)
WHERE r.rating > mean
WITH u, g, COUNT(*) AS score
MATCH (g)<-[:IN_GENRE]-(rec:Movie)
WHERE NOT EXISTS((u)-[:RATED]->(rec))
RETURN rec.title AS recommendation, rec.year AS year, COLLECT(DISTINCT g.name) AS genres, SUM(score) AS sscore
ORDER BY sscore DESC LIMIT 10
| Cypher | 説明 |
| MATCH (u:User {name: "Andrew Freeman"})-[r:RATED]->(m:Movie) WITH u, avg(r.rating) AS mean |
Andrew Freemanが行った全評価の平均値meanを求める |
| MATCH (u)-[r:RATED]->(m:Movie)-[:IN_GENRE]->(g:Genre) WHERE r.rating > mean WITH u, g, COUNT(*) AS score |
Andrew Freemanが平均値以上の評価をした映画の属するジャンルを全て取得し、評価対象ジャンルとする 各評価対象ジャンルにつき、Andrew Freemanが平均値以上の評価をした映画の数を評価対象ジャンルのスコアとする |
| MATCH (g)<-[:IN_GENRE]-(rec:Movie) WHERE NOT EXISTS((u)-[:RATED]->(rec)) |
評価対象ジャンルに属する映画の内、Andrew Freemanがまだ評価していないものをレコメンド候補映画として求める |
| RETURN rec.title AS recommendation, rec.year AS year, COLLECT(DISTINCT g.name) AS genres, SUM(score) AS sscore ORDER BY sscore DESC LIMIT 10 |
次の要素を返り値とする 1. レコメンド候補映画のタイトル 2. レコメンド候補映画の公開年 3. レコメンド候補映画の属する評価対象ジャンルのリスト 4. レコメンド候補映画の属する評価対象ジャンルのスコアの合計値 |
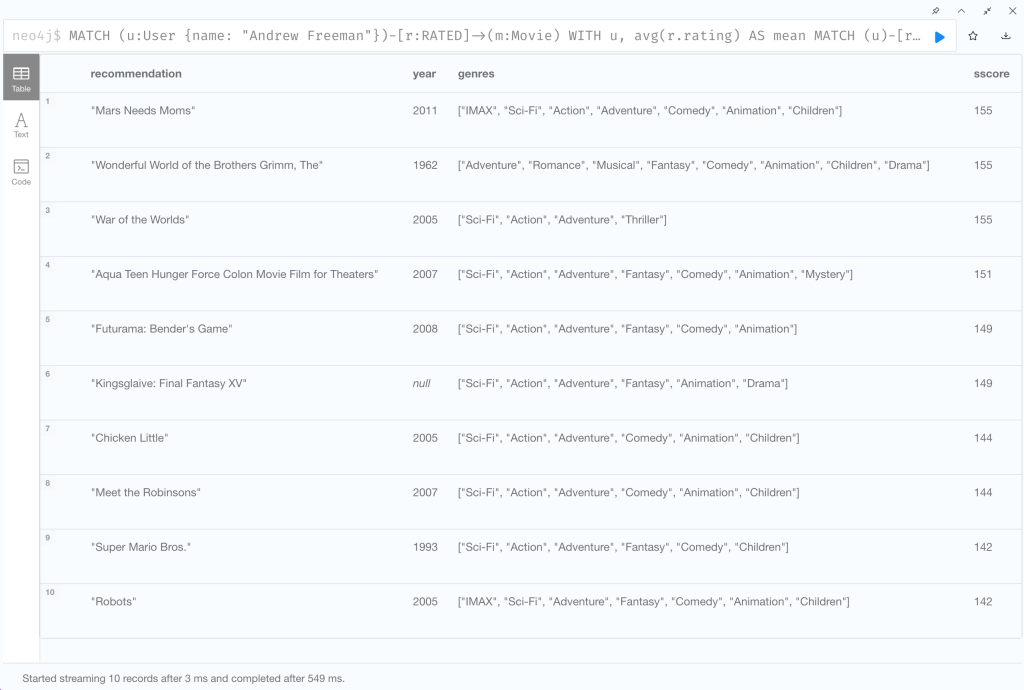
ジャンルによる映画の類似性とユーザーの評価の傾向の両方を考慮したレコメンドの結果が得られました。
このように、評価値の情報を加味することによって単純なコンテンツベースフィルタリングのみの場合よりも精度が向上します。
今回は、評価値の情報からユーザーの類似性を計算することはしませんでした。
次に見るように、類似性メトリクスを使用することで、2人のユーザーの評価値からユーザーがどの程度類似しているのかを定量化し、それをもとに協調フィルタリングによるレコメンドを行うことができます。
類似性メトリクスを使用するモデル
類似性メトリクスを使用することで、2人のユーザーあるいは2つのアイテムがどの程度類似しているのかを定量化することができます。
すでに、コンテンツベースフィルタリングでは、Jaccard 係数を使用しました。
協調フィルタリンングでは、どのような類似性メトリクスを使用するのが適切でしょうか。
Cosine 類似度
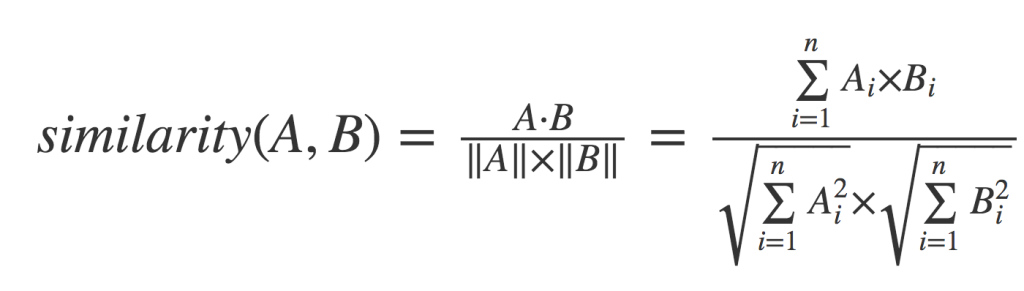
Jaccard 係数は映画を比較する場合に役立ちました。
Jaccard 係数の本質は2つの集合(ジャンル、俳優、監督などのグループ)を比較することです。
しかし、映画の評価では、各リレーションシップの重み、すなわち評価値を考慮に入れる必要があります。
2人のユーザーの評価値の Cosine 類似度によって、映画に対する好みの類似度を求めることができます。
高い Cosine 類似度を持つユーザー同士は好みの傾向が似ています。
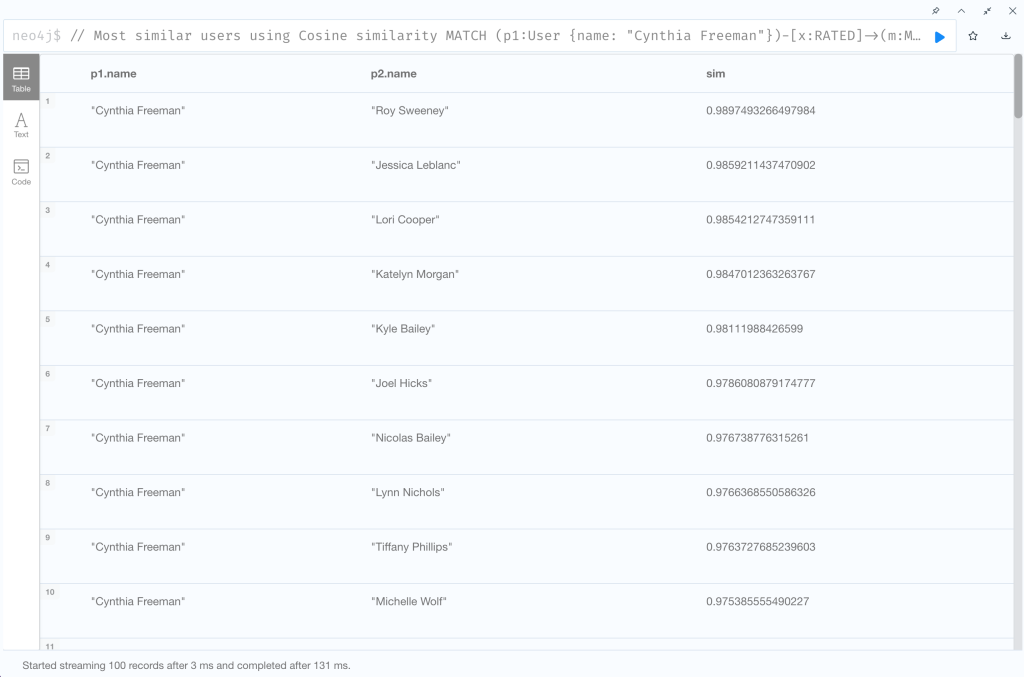
Cosine 類似度によって、ユーザー「Cynthia Freeman」と最も好みの傾向が似ているユーザーを見つけてみましょう。
// Most similar users using Cosine similarity
MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(m:Movie)<-[y:RATED]-(p2:User)
WITH COUNT(m) AS numbermovies, SUM(x.rating * y.rating) AS xyDotProduct,
SQRT(REDUCE(xDot = 0.0, a IN COLLECT(x.rating) | xDot + a^2)) AS xLength,
SQRT(REDUCE(yDot = 0.0, b IN COLLECT(y.rating) | yDot + b^2)) AS yLength,
p1, p2 WHERE numbermovies > 10
RETURN p1.name, p2.name, xyDotProduct / (xLength * yLength) AS sim
ORDER BY sim DESC
LIMIT 100
| Cypher | 説明 |
| MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(m:Movie)<-[y:RATED]-(p2:User) | Cynthia Freemanと対象のユーザーが同じ映画を評価しているケースを取得する |
| WITH COUNT(m) AS numbermovies, SUM(x.rating * y.rating) AS xyDotProduct, SQRT(REDUCE(xDot = 0.0, a IN COLLECT(x.rating) | xDot + a^2)) AS xLength, SQRT(REDUCE(yDot = 0.0, b IN COLLECT(y.rating) | yDot + b^2)) AS yLength, p1, p2 WHERE numbermovies > 10 |
共通のジャンルの数intersectionを求める 1. ケースに合致する映画の数:numbermovies 2. Cynthia Freemanの評価値と対象のユーザーの評価値の内積:xyDotProduct 3. Cynthia Freemanの評価値の絶対値:xLength 4. 対象のユーザーの評価値の絶対値:yLength ただし、 numbermovies > 10 であるケースに絞る |
| RETURN p1.name, p2.name, xyDotProduct / (xLength * yLength) AS sim ORDER BY sim DESC LIMIT 100 |
次の要素を返り値とする 1. Cynthia Freemanの名前 2. 対象のユーザーの名前 3. Cosine類似度 sim = xyDotProduct / (xLength * yLength) Cosine類似度の降順にソートし上位100件を返す |
Neo4j GDS ライブラリにある Cosine 類似度アルゴリズムを使用して Cosine 類似度を計算することもできます。
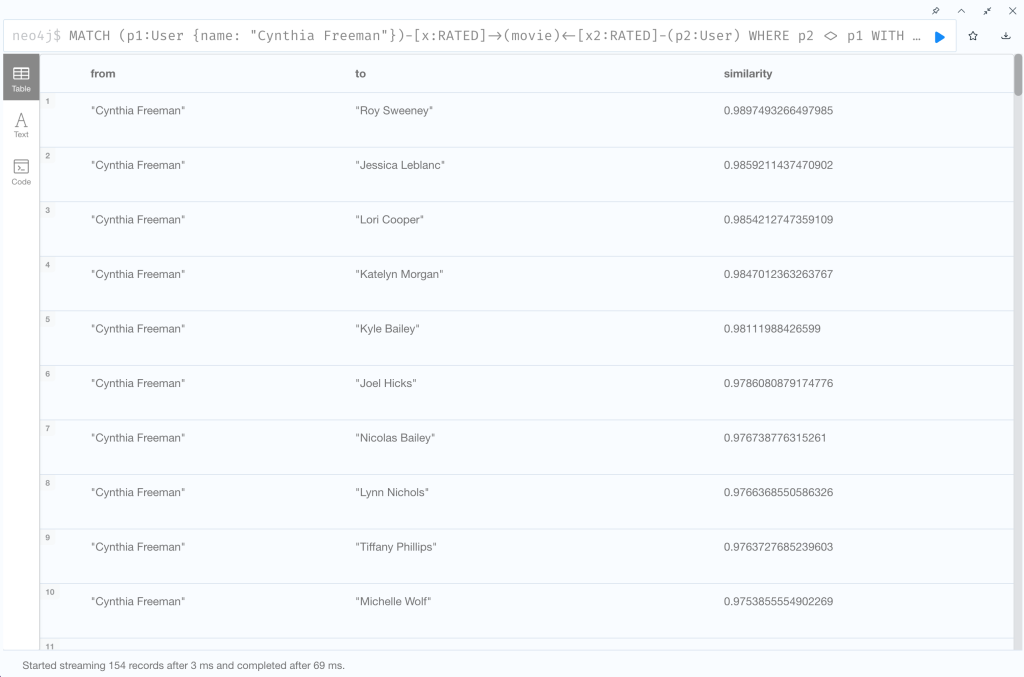
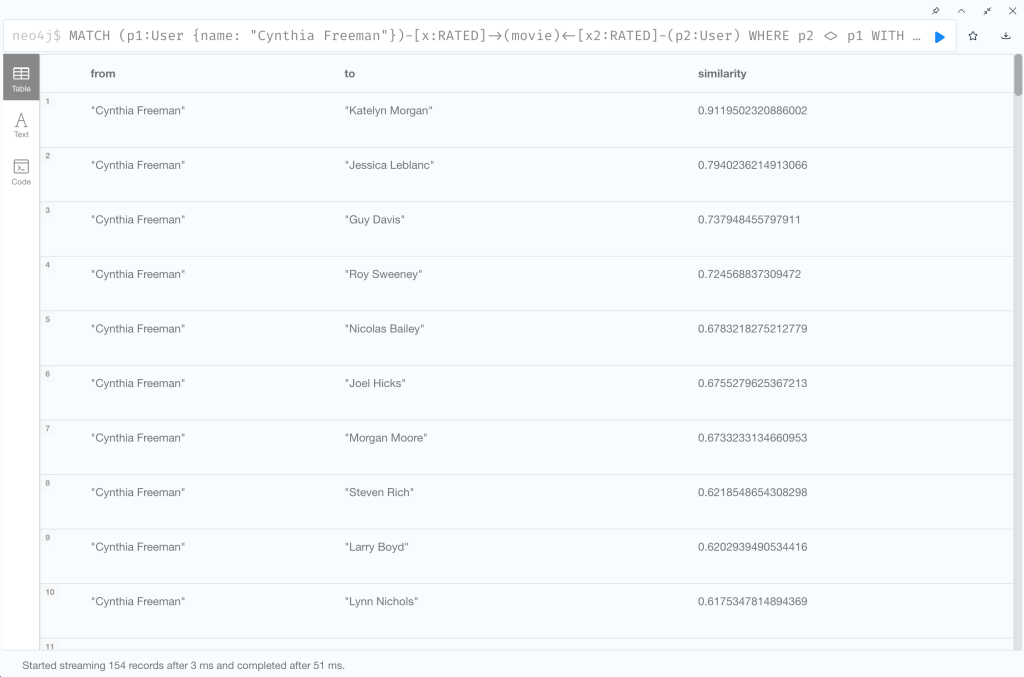
Cosine 類似度関数を使用して、Cynthia Freeman と最も好みの傾向が似ているユーザーを見つけてみましょう。
MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(movie)<-[x2:RATED]-(p2:User)
WHERE p2 <> p1
WITH p1, p2, collect(x.rating) AS p1Ratings, collect(x2.rating) AS p2Ratings
WHERE size(p1Ratings) > 10
RETURN p1.name AS from,
p2.name AS to,
gds.similarity.cosine(p1Ratings, p2Ratings) AS similarity
ORDER BY similarity DESC
| Cypher | 説明 |
| MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(movie)<-[x2:RATED]-(p2:User) WHERE p2 <> p1 |
Cynthia Freemanと対象のユーザーが同じ映画を評価しているケースを取得する |
| WITH p1, p2, collect(x.rating) AS p1Ratings, collect(x2.rating) AS p2Ratings WHERE size(p1Ratings) > 10 |
Cynthia Freemanの評価値p1Ratingsと対象のユーザーの評価値p2Ratingsを宣言する |
| RETURN p1.name AS from, p2.name AS to, gds.similarity.cosine(p1Ratings, p2Ratings) AS similarity |
GDSの関数を使用してp1Ratingsとp2RatingsのCosine類似度を計算し、返り値とする |
| ORDER BY similarity DESC | Cosine類似度の降順にソートして返す |
Pearson 類似度
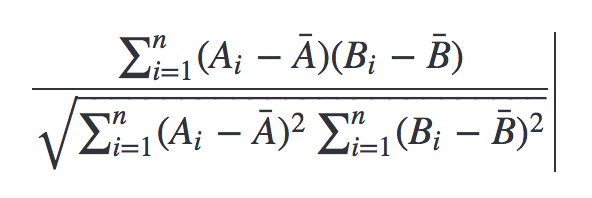
Cosine 類似度の代わりに、Pearson 類似度(あるいは Pearson 相関係数)を使用することも可能です。
Cosine 類似度はユーザーごとの平均評価値の違いを考慮しませんが、Pearson 類似度は平均評価値の違いを考慮します。
あるユーザーが他のユーザーよりも高い評価をしがちであるということはよくありますが、Pearson 類似度は平均評価値の違いを考慮して、より適切なレコメンデーションを行います。
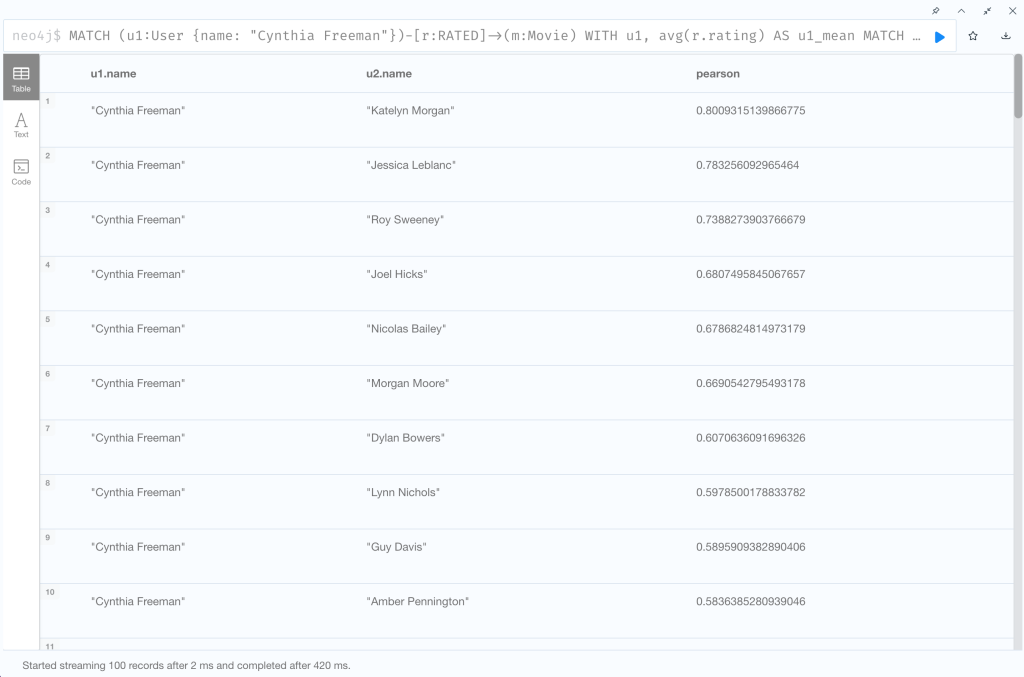
Pearson 類似度によって、ユーザー「Cynthia Freeman」と最も好みの傾向が似ているユーザーを見つけてみましょう。
MATCH (u1:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH u1, avg(r.rating) AS u1_mean
MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2)
WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (u2)-[r:RATED]->(m:Movie)
WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom,
sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom,
u1, u2 WHERE denom <> 0
RETURN u1.name, u2.name, nom/denom AS pearson
ORDER BY pearson DESC LIMIT 100
| Cypher | 説明 |
| MATCH (u1:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie) WITH u1, avg(r.rating) AS u1_mean |
Cynthia Freemanの評価の平均値u1_meanを宣言する |
| MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2) WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10 |
Cynthia Freemanと対象のユーザーが同じ映画を評価しているケースを取得し、それぞれの評価値ratingsを宣言する |
| MATCH (u2)-[r:RATED]->(m:Movie) WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings |
対象のユーザーの評価の平均値u2_meanを宣言する |
| UNWIND ratings AS r WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom, sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom, u1, u2 WHERE denom <> 0 |
評価値ratingsと平均値u1_mean,u2_meanを用いて、Pearson類似度の要素nomとdenomを計算する |
| RETURN u1.name, u2.name, nom/denom AS pearson ORDER BY pearson DESC LIMIT 100 |
Pearson類似度 pearson = nom/denom を返り値として、Pearson類似度の降順にソートし上位100件を返す |
Neo4j GDS ライブラリにある Pearson 類似度アルゴリズムを使用することで Pearson 類似度を計算することもできます。
Pearson 類似度関数を使用して、Cynthia Freeman と最も好みの傾向が似ているユーザーを見つけてみましょう。
MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(movie)<-[x2:RATED]-(p2:User)
WHERE p2 <> p1
WITH p1, p2, collect(x.rating) AS p1Ratings, collect(x2.rating) AS p2Ratings
WHERE size(p1Ratings) > 10
RETURN p1.name AS from,
p2.name AS to,
gds.similarity.pearson(p1Ratings, p2Ratings) AS similarity
ORDER BY similarity DESC
| Cypher | 説明 |
| MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(movie)<-[x2:RATED]-(p2:User) WHERE p2 <> p1 |
Cynthia Freemanと対象のユーザーが同じ映画を評価しているケースを取得する |
| WITH p1, p2, collect(x.rating) AS p1Ratings, collect(x2.rating) AS p2Ratings WHERE size(p1Ratings) > 10 |
Cynthia Freemanの評価値p1Ratingsと対象のユーザーの評価値p2Ratingsを宣言する |
| RETURN p1.name AS from, p2.name AS to, gds.similarity.pearson(p1Ratings, p2Ratings) AS similarity |
GDSの関数を使用してp1Ratingsとp2RatingsのPearson類似度を計算し、返り値とする |
| ORDER BY similarity DESC | Pearson類似度の降順にソートして返す |
近傍探索(k近傍法)に基づくレコメンデーション
これまで、ユーザーの好みの傾向に基づいて似ているユーザーを検索する方法を見てきました。
最後に、対象のユーザーに最も似ているユーザーk人にどの商品をレコメンドすべきか投票して決めてもらう方法(k近傍法)を見ます。
簡単に言うと、次のような問いに答えることになります。
「映画の好みが私に最も似ているユーザーを10人あげてください。
彼らが高い評価をしている映画で私がまだ観ていないものはありますか?」
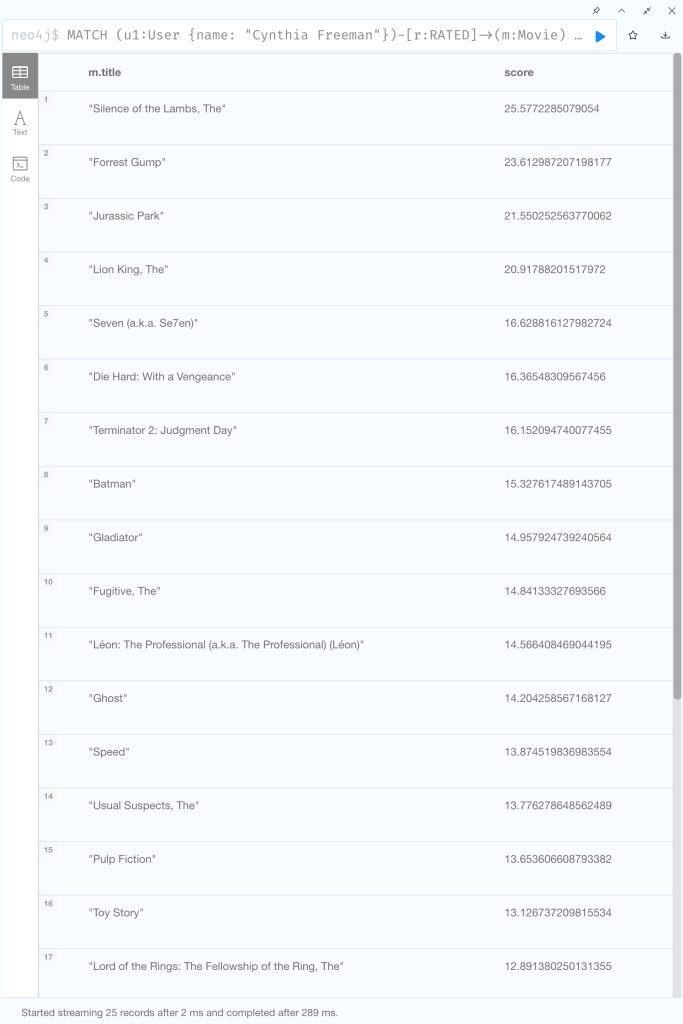
Pearson 類似度を使用したk近傍法による映画のレコメンド
MATCH (u1:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH u1, avg(r.rating) AS u1_mean
MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2)
WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (u2)-[r:RATED]->(m:Movie)
WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom,
sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom,
u1, u2 WHERE denom <> 0
WITH u1, u2, nom/denom AS pearson
ORDER BY pearson DESC LIMIT 10
MATCH (u2)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (u1)-[:RATED]->(m) )
RETURN m.title, SUM(pearson * r.rating) AS score
ORDER BY score DESC LIMIT 25
| Cypher | 説明 |
| MATCH (u1:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie) WITH u1, avg(r.rating) AS u1_mean |
Cynthia Freemanの評価の平均値u1_meanを宣言する |
| MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2) WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10 |
Cynthia Freemanと対象のユーザーが同じ映画を評価しているケースを取得し、それぞれの評価値ratingsを宣言する |
| MATCH (u2)-[r:RATED]->(m:Movie) WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings |
対象のユーザーの評価の平均値u2_meanを宣言する |
| UNWIND ratings AS r WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom, sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom, u1, u2 WHERE denom <> 0 |
評価値ratingsと平均値u1_mean,u2_meanを用いて、Pearson類似度の要素nomとdenomを計算する |
| WITH u1, u2, nom/denom AS pearson ORDER BY pearson DESC LIMIT 10 |
Pearson類似度 pearson = nom/denom を宣言し、Pearson類似度の降順にソートし上位10件を取得する |
| MATCH (u2)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (u1)-[:RATED]->(m) ) | 上位10件のユーザーが評価済みでCynthia Freemanが未評価の映画を取得する |
| RETURN m.title, SUM(pearson * r.rating) AS score | 次の要素を返り値とする 1. 取得した映画のタイトル 2. 上位10件のユーザーの取得した映画に対する評価値とpearsonの積の合計(映画のスコア) |
| ORDER BY score DESC LIMIT 25 | 映画のスコアの降順にソートし上位25件を返す |
さらに学んでみたい方へ - エクササイズ集
Exercise.1 時間的要素
好みの傾向が時間と共に変化することを考慮し、最近の映画の評価を使用して、適切なレコメンドを行うようにモデルを改良しましょう。評価時のタイムスタンプを用います。
Exercise.2 キーワード抽出
各映画のプロットの説明文からキーワードを抽出して、映画の特徴を考慮したモデルを作成してみましょう。
Exercise.3 ポスターを使用した画像認識
各映画のポスター画像を用いて、レコメンドシステムを強化してみましょう。画像認識とタグづけを行うフリーのライブラリやAPIを使用してください。
感想
従来の RDB と Python スクリプトの組み合わせなどで実装すると長大なコードになってしまうレコメンドアルゴリズムが、Neo4j を使用するとコンパクトに書けますし、パフォーマンスも改善します。
これは、Neo4j がデータの関連性を RDB と比較してより人間の発想に近い形で格納するためです。
従来はコンピュータリソースの制約もあり、データベースといえば RDB しかありませんでしたが、世の中に存在するデータは元来表形式というよりネットワーク状になっているものが数多くあります。
ですから、ネットワーク状のデータ形式を自然に扱うことができるグラフデータベースは、データを本来の形で扱うことができる技術であり、潜在的な可能性を多く含んでいると感じます。
※1index-free adjacency 参考資料 1, 2, 3, 4
※2集合Aと集合Bの和集合とは、AとBのいずれかもしくは両方に属する要素からなる集合のこと。集合Aと集合Bの積集合とは、AとBの両方に属する要素からなる集合のこと。



