
Neo4j SandBox 金融不正検知プロジェクトを体験してみた #Neo4j #SandBox #FraudDetection #不正検知 #GDS
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
概要
金融関系の企業からNeo4jに関する問い合わせがあり、デモとして良いツールがないかと探したら、SandBox にFraud Detection(不正検知)のプロジェクト があったので使ってみました。
プロジェクト内のシナリオが金融の不正の知識や、Graph Data Science(GDS)の予備知識が必要だったので、備忘録としてまとめました。
目的
- Fraud DetectionやDGSの使い方の備忘録
- SandBox Fraud Detectionプロジェクトの紹介
- 日本語解説の公開
✅ コメント
Fraud Detectionシナリオの内容を解説しますが、説明の順序を入れ替えたり、実行する内容を追加・省略しています。リクエストあればちゃんとした翻訳をやります。
予備知識1:SandBoxて何さ?
詳しいセットアップ方法はCL Lab:Neo4jサンドボックスの紹介を確認。
Launch the Free Sandbox:https://neo4j.com/sandbox/
Neo4jの体験サイトで無料で使えます。neo4jにサインアップして、2,3クリックしたら、Webブラウザを使って利用できます。デモ用のデータと演習シナリオ※1が用意されてるので、グラフデータベースの活用を検討したり、まずは体験するのに、シンプルなアプリケーションです。
利用できるのは3日間で、データは引き継げませんが、再度セットアップすれば何度でも利用できます。
-
SandBoxのセットアップ
Neo4j SandBox プロジェクトリスト FraudDetectionを選択 
-
起動するとシナリオがスライド形式で表示されます
予備知識2:Neo4j Graph Data Science(GDS)て何さ?
下記も参照ください。
CL Lab:Neo4j Graph Data Science Library(GDS)の紹介
Neo4j:Graph Data Science
Neo4j:GDSL Manual
データを用いて有益な知見を引き出そうとするアプローチをData Sienceといいますが、それをグラフデータを対象とした手法・情報科学・統計学・アルゴリズムなどをまとめて、Graph Data Science(GDS)と呼びます。
今回利用するグラフアルゴリズムのカテゴリを紹介します。
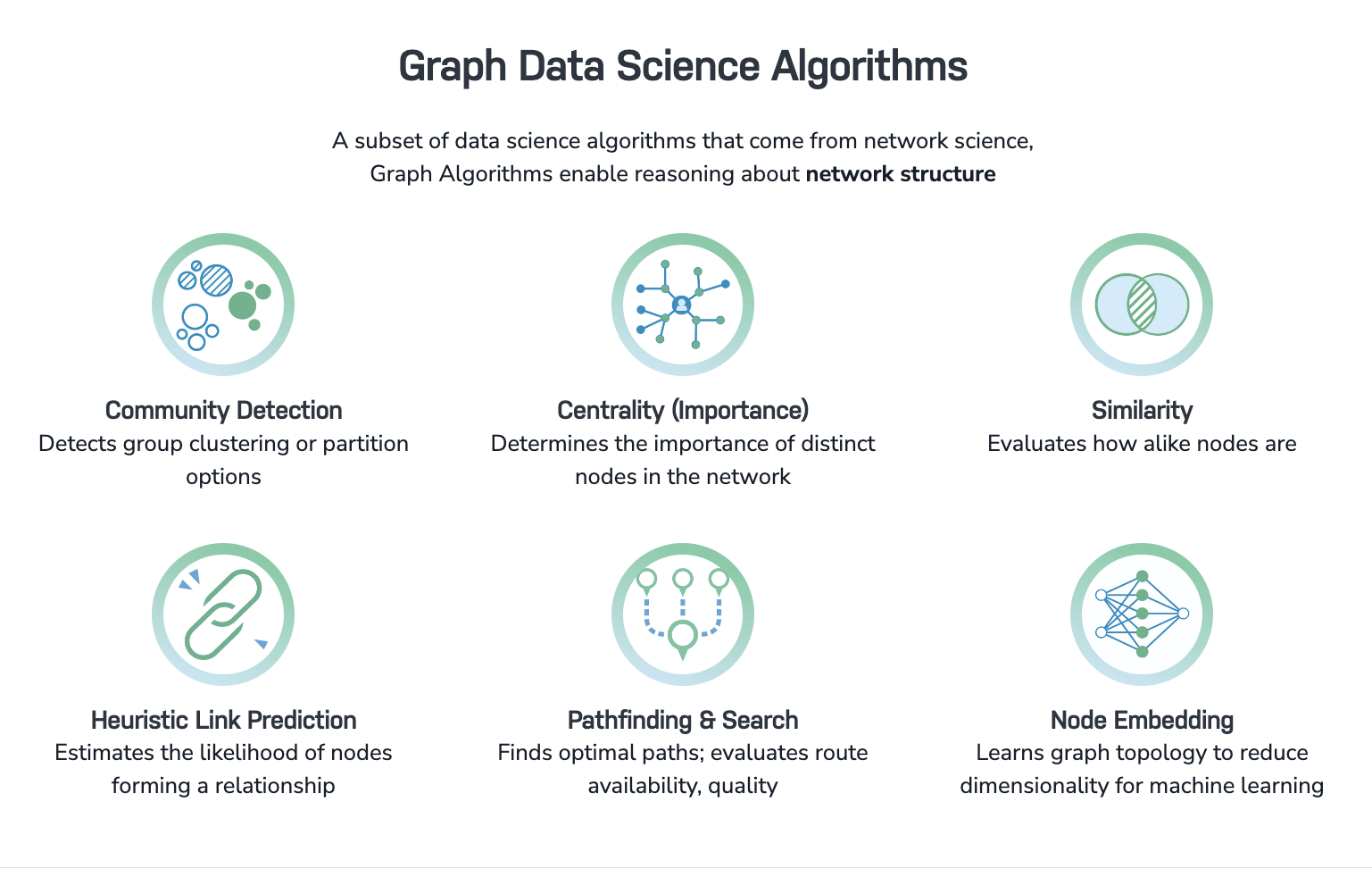
-
中心性
ネットワーク中で、影響力が高いノードの検出に利用します。
接続するリレーションシップの数や向き、ホップ数などを用いて、ノードのスコアリングをします。
主なアルゴリズム:PageRank, Degree Centrality -
コミュニティ検出
リレーションシップで繋がれたコミュニティ(グループ、クラスタ)の検出に利用します。
各コミュニティIDを生成し、そのIDをコミュニティに所属するノードに割当てます。
主なアルゴリズム:Weakly Connected Components(WCC), Louvain, Label Propagation -
類似度
プロパティの値などの特性や近傍性を基に、ノードとノードの類似度を算出します。
主なアルゴリズム:Node Similarity, K-Nearest Neighbors
これらのアルゴリズムをNeo4jで効率的に利用できるようにまとめたプラグインが、Neo4j Graph Data Science Library(GDSL)になります。GDSLには下記特徴があります。
| Neo4j GDSL イメージ | Neo4j プロジェクショングラフモデル |
 |
 |
-
インメモリ
アルゴリズムを効率的に実行するために、Neo4j DBからメモリ内にグラフデータをロードしインメモリでアルゴリズムを適応します。RDBにおけるビューのようなものです。ロードするメモリ領域をカタログ、ロードされたグラフデータをプロジェクショングラフと呼びます。インメモリで実行するため、実行コストの見積もりが大切になります※2。 -
stream, mutate, write, stats モード
アルゴリズムはNeo4jプロシージャとして実装されています。これらのアルゴリズムの一部には、stream, mutate, write, statsの実行モードがあります-
streamモード
一般的なCypherのRETURNクエリのように、アルゴリズムの計算結果を返します。
アルゴリズムは各ノードのコンポーネントIDを返します。
例えば、コミュニティ検出アルゴリズムの場合、ノードIDとそれが属するコミュニティIDを返し、類似度アルゴリズムの場合ノードIDと類似度スコアを返します。 -
mutateモード
アルゴリズムの計算結果をプロジェクショングラフに書き戻します。アルゴリズムの実行のために、データベースへ書込むことなく、複数のアルゴリズムを実行できます。また、Cypher経由でアルゴリズムの結果の問い合わせができるようになります。 -
writeモード
アルゴリズム計算結果をNeo4jBDに書き戻します。実際にデータに変更を加える唯一の実行モードです。返り値には、実行の統計サマリが返されます。
ノードのプロパティ(PageRankスコアなど)、新しいリレーションシップ(Node Similarityなど)、リレーションシッププロパティになります。 -
statsモード
アルゴリズムの実行結果ではなく、カウントやパーセンタイル分布のような統計結果のみを返します。
-
予備知識3:Fraud Detection(不正検知)て何さ?
Fraud(不正行為)とは、個人や集団が身分を偽り、製品・サービス・金融などの取引を行ったり、または、履行するつもりのない偽の約束をして、故意に欺く行為を指します。
不正の分類(参照:idenfy blog)
-
First-Party Fraud(1stパーティ不正)
自分自身の身分を偽ったり、虚偽の情報を提供する不正行為。例えば、金融商品やサービスを契約する際に、より有利な金利を得るためや、ローンを返済の意思なく申込み、利益を得るためなど。 -
Second-Party Fraud(2ndパーティ不正)
故意に自分の個人情報を他人に提供したり、誰かが本人に代わって利益を得る不正行為。名義貸し、フレンドリー不正と呼ばれる行為です。 -
Third-Party Fraud(3rdパーティ不正)
他人の身分証明書や個人情報を悪用して、口座を開設したり乗っ取ったりする不正行為。最も一般的な不正行為です。
このような不正を行いそうな/行っている疑いがあるクライアントを検知し、その不正行為を暴いたり、未然に防ぐことが不正検知の目的です。
本プロジェクトでは、金融の不正検出デモとして、First-Party不正者検知とSecond-Party不正者検知のシナリオが用意されています。
シナリオ0:利用データの説明
インターネット送金フローネットワークをモデリングしたPaysimデータセットを使います(詳細はDave Voutilaのブログを参照)。
データベーススキーマと統計情報
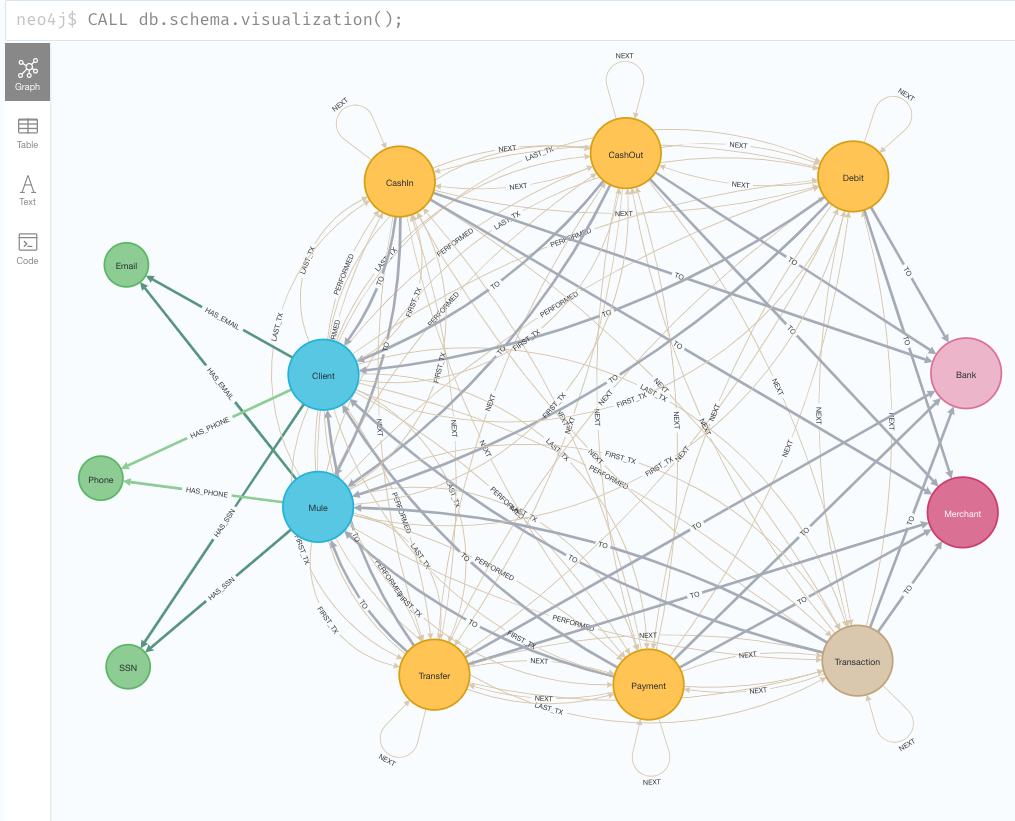
まずはデータの全体像を把握
CALL db.schema.visualization();
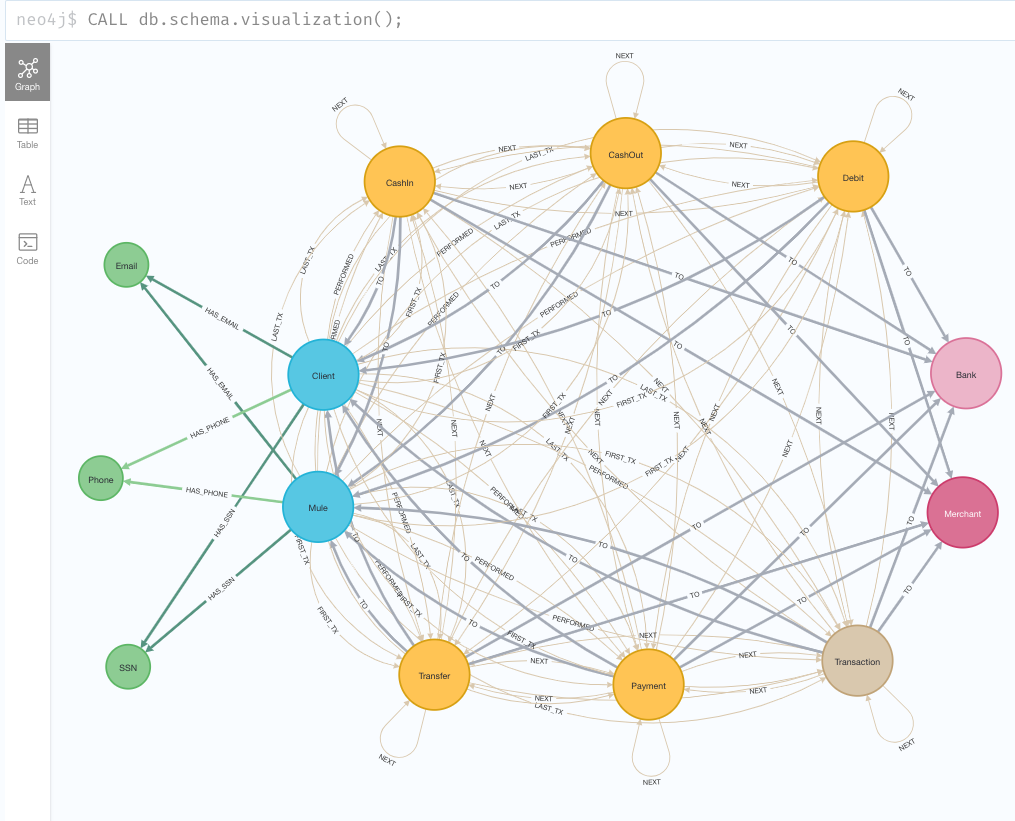
ノードの種類
- クライアントノード:ネットワークの資金を操作するノード
- Client:利用者。エンドクライアント
- Mule:クライアントの代わりに送金するプログラム(ミュールとは、運び屋の意味)Muleラベルを持つノードは、必ずClientラベルも持ちます
- 下記3つの個人情報ノードを持ちます
- Mail:メールアドレス.クライアントノードからHAS_EMAILリレーションシップで繋がれる
- Phone:電話番号. クライアントノードからHAS_PHONEリレーションシップで繋がれる
- SSN:社会保障番号. クライアントノードからHAS_SSNリレーションシップで繋がれる
- Merchant:商品/サービスを提供するベンダーや企業。ネットワークの資金の移動を仲介するノード
- Bank:銀行。ネットワークの資金の移動を仲介するノード
- トランザクションノード:ユーザがマーチャントノードを介して行う資金の取引内容を表すノード。下記のノードは必ずTransactionのラベルを持ちます。
- CashIn:ネットワークへ資金を移動させる
- CashOut:ネットワークから資金を移動させる
- Debit:銀行に資金を移動する
- Transfer:別のクライアントに資金を送る
- Payment:商品/サービスへの支払い
シナリオ1:First-Party不正者の検知
検知方針
まずは、First-Party不正者を検知します。本シナリオでは、次の仮定をもとに検知を行います。
自分の個人情報を他のクライアントと共有しているクライアントは、不正を行っている可能性や今後不正を働く可能性が高い。
しかし、家族でメールアドレス共同で利用するように、個人情報を共有している全てのクライアントが容疑者ではありません。
そこで、複数のクライアント間で共有さている個人情報ノードに紐づくリレーションシップを使って、不正スコアを計算し、上位X%のクライアントを不正者としてラベル付けすることにします。
下記のステップで検知を実施します。
- 個人情報ノードを共有するクライアントノード間にSHARED_IDENTIFIERSリレーションシップを新規作成
- 個人情報ノードを共有するクライアント同士の繋がりからクラスタを生成
- クラスタ内のクライアント同士で類似度スコアを算出
- 類似度スコアからクライアントの不正スコアを算出
- 不正スコアの上位X%のクライアントを不正者としてラベル付け
1-1. SHARED_IDENTIFIERSリレーションシップの作成
- Cypherコード
MATCH (c1:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]->(n)<-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-(c2:Client) WHERE id(c1) < id(c2) WITH c1, c2, count(*) as cnt MERGE (c1)-[:SHARED_IDENTIFIERS {count: cnt}]->(c2); -
説明
個人情報ノード:nを共有しているクライアントノード:c1,c2を抽出
c1->n<-c2 と c2->n<-c1
とのように、同じつながりが重複して抽出されるため、重複を削除
c1,c2のペア毎にレコード数(=共有個人情報ノード数)をカウント
c1->c2で SHARED_IDENTIFIERSリレーションを作成※3 -
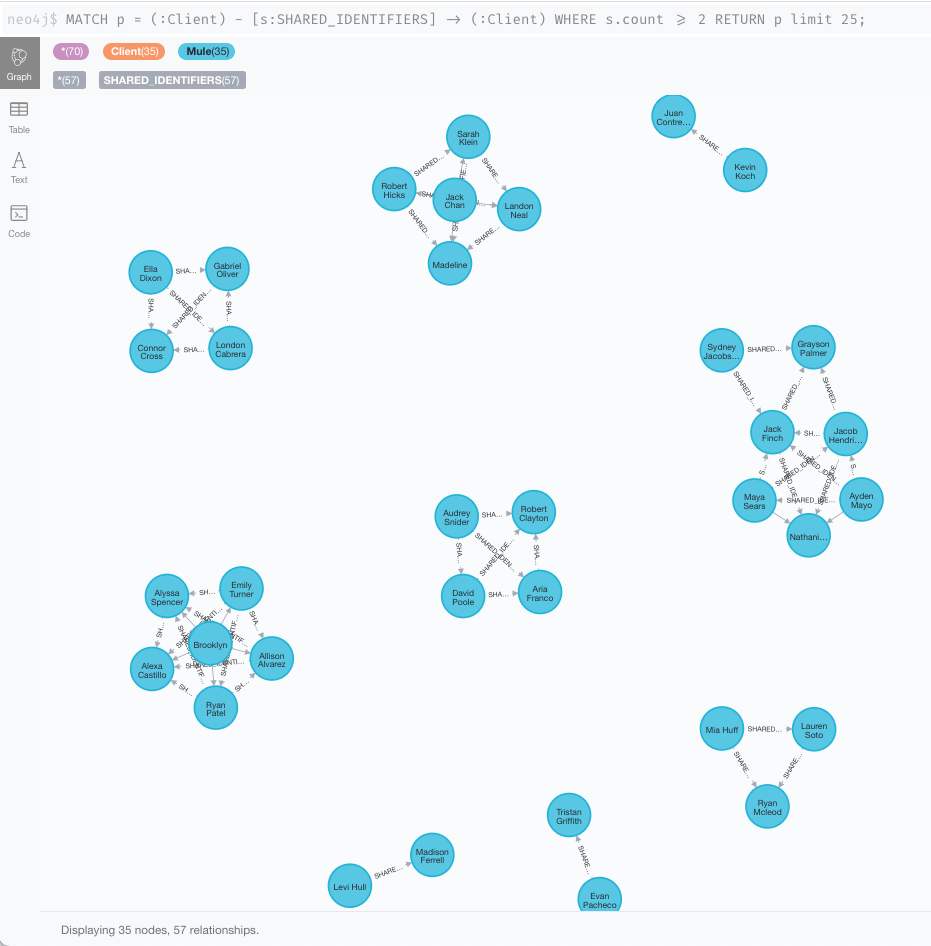
結果表示
MATCH p=(:Client)-[s:SHARED_IDENTIFIERS]->(:Client) WHERE s.count >= 2 RETURN p LIMIT 25;
このクライアントの塊1つ1つがクラスタになります。
1-2. クラスタ作成
各クラスターに番号(id)を割り当てます。idを割り当てるには、GDSのComminity Detection系のアルゴリズムを利用すると簡単です。今回は Weakly Connected Components(WCC)メソッド を使います。
wccと名前で、プロジェクショングラフ(Prjグラフ)を作成します。
-
Cypherコード
CALL gds.graph.project( 'wcc', {Client: {label: 'Client'}}, {SHARED_IDENTIFIERS:{ type: 'SHARED_IDENTIFIERS', orientation: 'UNDIRECTED', properties: {count: {property: 'count'}} }} ) YIELD graphName, nodeCount, relationshipCount, projectMillis; -
説明
Prjグラフ作成メソッドの呼び出し{ Prjグラフの名称:wcc, Prjグラフのノードの設定:{ノード名: {DBのどのノードを使うか}}, Prjグラフのリレーションシップの設定:{リレーションシップ名:{ DBのどのリレーションシップを使うか: 'SHARED_IDENTIFIERS', リレーションシップの向きを設定: 'NATURAL(DBと同じ向き)'、'REVERSE(逆向き)'、'UNDIRECTED(向無し)', プロパティを設定: {プロパティ名: {BDのどのプロパティを使うか: 'count'}} }} ) 返り値 グラフ名, ノード数, リレーションシップ数, 生成ミリ秒; -
結果

クライアントノードに、どのクラスターに属しているかを表す firstPartyFraudGroupパラメータ追加し、クラスタ番号を代入します。
- Cypherコード
CALL gds.wcc.stream( 'wcc', { nodeLabels: ['Client'], relationshipTypes: ['SHARED_IDENTIFIERS'], consecutiveIds: true }) YIELD componentId, nodeId WITH componentId AS cluster, gds.util.asNode(nodeId) AS client WITH cluster, collect(client.id) AS clients WITH cluster, clients, size(clients) AS clusterSize WHERE clusterSize > 1 UNWIND clients AS client MATCH (c:Client) WHERE c.id = client SET c.firstPartyFraudGroup = cluster; -
説明
wccメソッドをstreamモードで呼び出し( 利用するPrjグラフ:'wcc', { 対象ノード名: ['Client'], 対象リレーションシップ名: ['SHARED_IDENTIFIERS'], コンポーネントIDを連番にする?: true }) メソッドの返り値:クラスタIDとノードIDのペアを展開 クラスタIDとBDノードのペアを取得 クラスタIDごとにBDノードIDを1行にまとめる クラスタIDごとのノード数を算出 ノードが複数あるクラスタのみに絞る クラスタIDとノードIDのペアを1行ずつ返す DBからClientノードを取得 対象のノードIDを見つけたら firstPartyFraudGroupプロパティにクラスタIDをセット※consecutiveIdsの説明を理解できませんでした(Table 7. Algorithm specific configuration:Flag to decide whether component identifiers are mapped into a consecutive id space)
-
サンプル出力
クライアントノード数が9以上のクラスターを表示します。MATCH (c:Client) WITH c.firstPartyFraudGroup AS fpGroupID, collect(c.id) AS fGroup WITH *, size(fGroup) AS groupSize WHERE groupSize >= 9 WITH collect(fpGroupID) AS fraudRings MATCH p=(c:Client)-[:HAS_SSN|HAS_EMAIL|HAS_PHONE]->() WHERE c.firstPartyFraudGroup IN fraudRings RETURN p;
クラスタノード数9以上のクラスタ ノードを整頓して並べてみがたが、なんともダサい。グラフのレイアウトって才能。 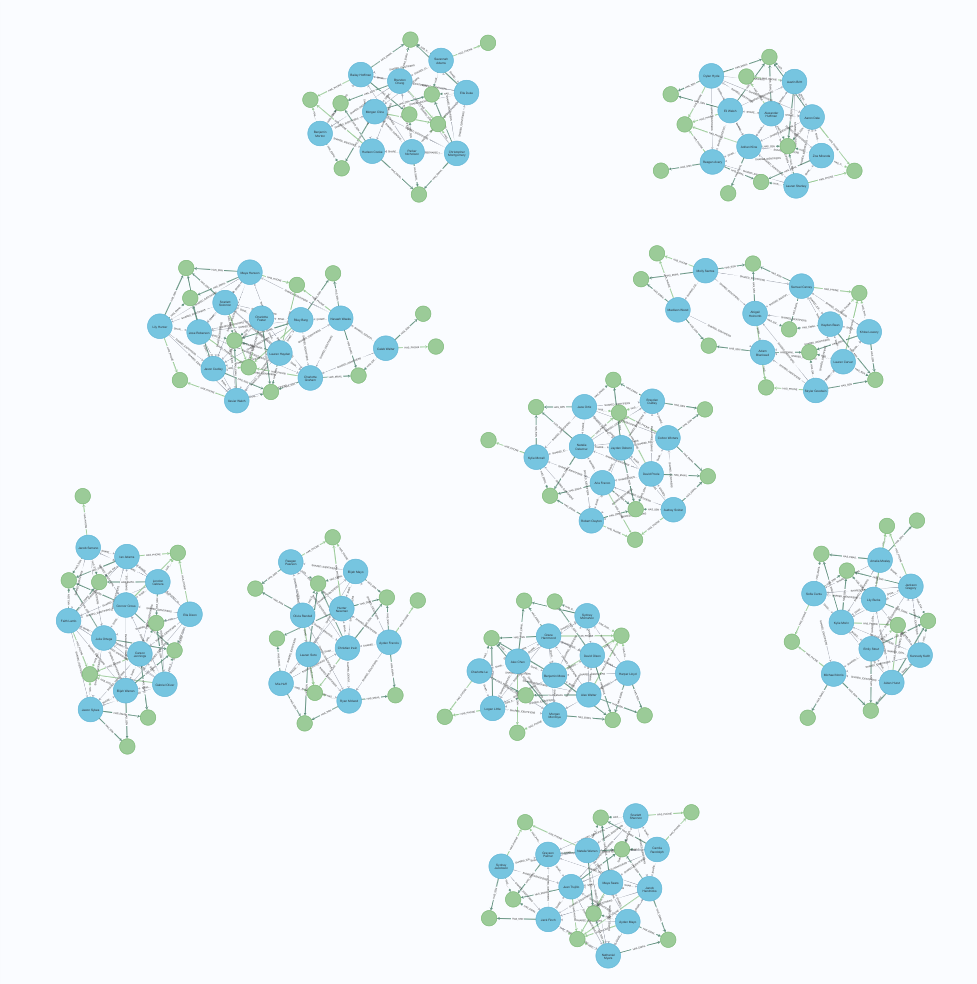
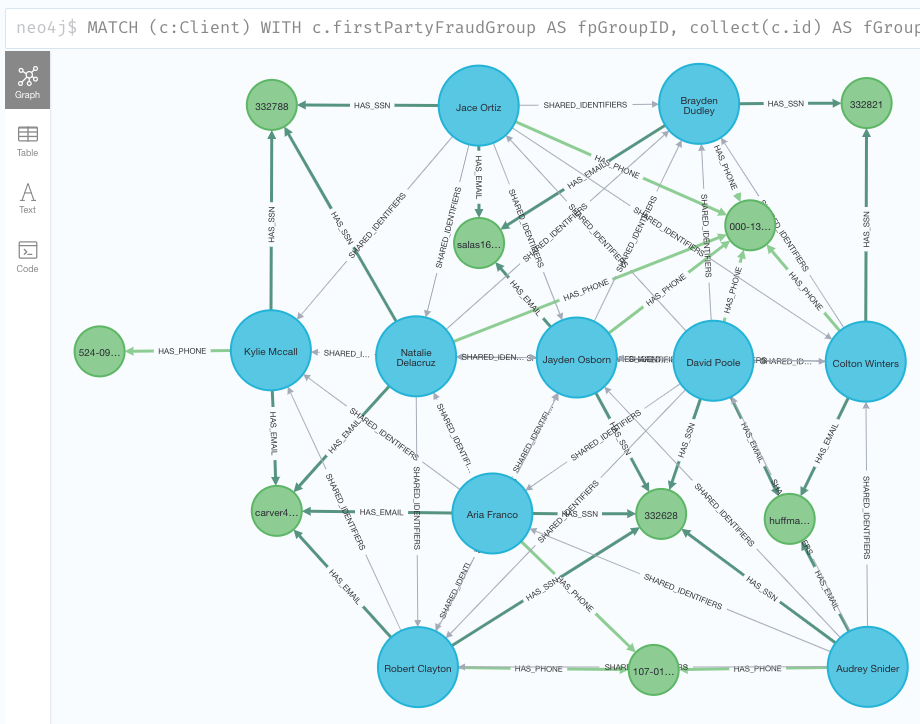
1-3. 類似スコアの算出
新たなPrjグラフを作成します。名前はsimilarityとします。
- コード
MATCH (c:Client) WHERE c.firstPartyFraudGroup is not NULL WITH collect(c) as clients MATCH (n) WHERE n:Email OR n:Phone OR n:SSN WITH clients, collect(n) as identifiers WITH clients + identifiers as nodes MATCH (c:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]->(id) WHERE c.firstPartyFraudGroup is not NULL WITH nodes, collect({source: c, target: id}) as relationships CALL gds.graph.project.cypher( 'similarity', "UNWIND $nodes as n RETURN id(n) AS id, labels(n) AS labels", "UNWIND $relationships as r RETURN id(r['source']) AS source, id(r['target']) AS target, 'HAS_IDENTIFIER' AS type", {parameters: {nodes: nodes, relationships: relationships}} ) YIELD graphName, nodeCount, relationshipCount, projectMillis RETURN graphName, nodeCount, relationshipCount, projectMillis; - 説明
firstPartyFraudGroupプロパティを持つクライアントノードを取得し、 対象ノード全てを配列(clients)に格納 個人情報ノードを取得し、 配列(identifiers)に格納 配列(clients)と配列(identifiers)を連結し配列(nodes)に格納 firstPartyFraudGroupプロパティを持つクライアントノードと、それに接続する個人情報ノードを取得し、 クライアント(source)と個人情報(target)のペアを配列(relationships)に格納 PrjグラフをCypherで定義する( Prjグラフ名:similarity 対象ノード: 配列(nodes)に含まれるノード, 対象リレーションシップ:配列(relationships)に含まれるHAS_IDENTIFIERリレーションシップ 上記Cypherで利用できるように、パラメータ$nodes, $relationshipsと変数nodes, relationshipsとのマッピング設定 ) グラフ名, ノード数, リレーションシップ数, 実行時間(ms)を展開 グラフ名, ノード数, リレーションシップ数, 実行時間(ms)を表示;
- 結果

gds.nodeSimilarityメソッドをsimilarity Prjグラフに対して実行し類似スコアを算出します。
- コード
CALL gds.nodeSimilarity.mutate( 'similarity', { topK:15, mutateProperty: 'jaccardScore', mutateRelationshipType:'SIMILAR_TO' } ); - 説明
実行モードmutateでnodeSimilarityメソッドを呼び出し( 利用するPrjグラフ:similarity { ノードごとに類似度スコアを最大何個返すか:15 利用アルゴリズム:jaccardScore Prjグラフに生成するリレーションシップ名:SIMILAR_TO } );
類似スコアをSIMILAR_TOリレーションシップとしてデータベースに書込みます。
- コード
CALL gds.graph.writeRelationship('similarity', 'SIMILAR_TO', 'jaccardScore'); -
説明
メモリグラフ:similarityからSIMILAR_TOリレーションシップをDBへ書き戻します。
リレーションシップのプロパティにjaccardScoreを付与します - サンプル出力
MATCH p=(:Client)-[s:SIMILAR_TO]->(:Client) RETURN p LIMIT 25;
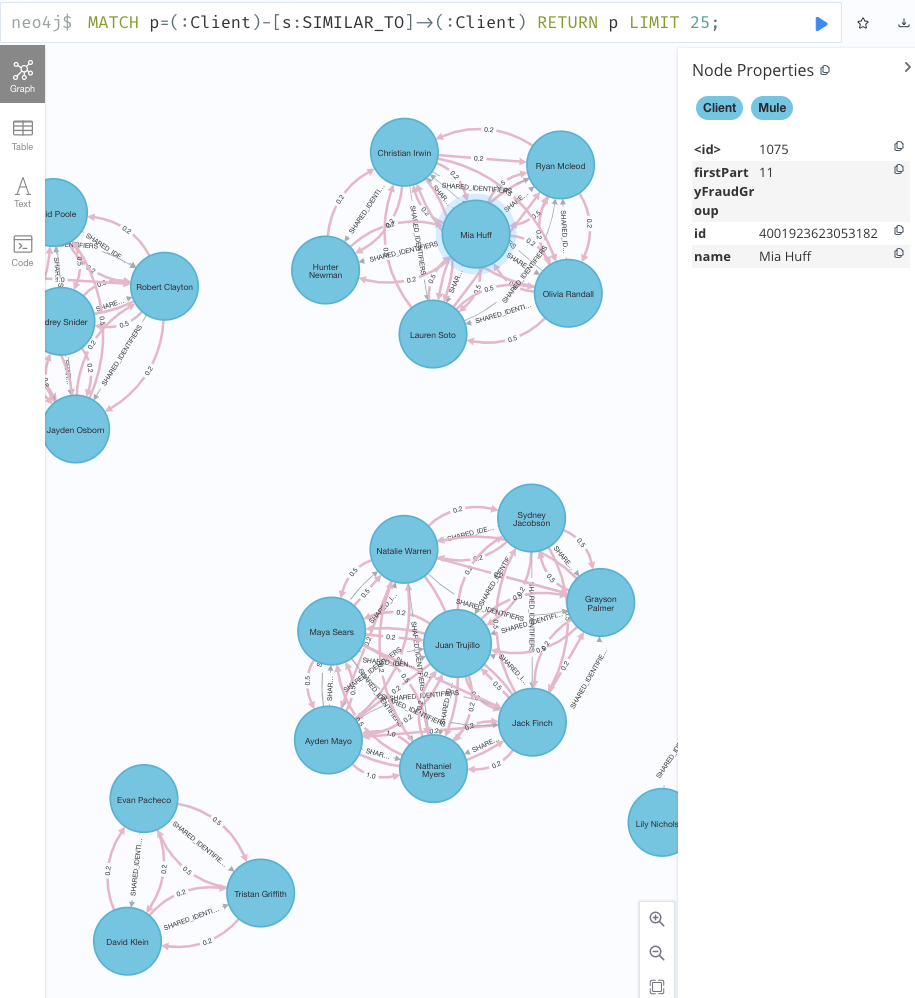
1-4. ノードの不正スコアを算出
Weighted Degree Centrality Algorithm(WDC, 重み付き次数中心性アルゴリズム)を使用して、クライアントノードのFirst-Party不正スコアを計算します。
クライアントノードに流入するSIMILAR_TOリレーションシップのjaccardScoreの合計値をfirstPartyFraudScoreとしてノードプロパティに書込みます。
firstPartyFraudScoreが高いほど、不正行為を働く可能性が高いクライアントとなります。
- コード
CALL gds.degree.write( 'similarity', { nodeLabels: ['Client'], relationshipTypes: ['SIMILAR_TO'], relationshipWeightProperty: 'jaccardScore', writeProperty: 'firstPartyFraudScore' } ); - 説明
Degree Centralityメソッドをwriteモードで呼び出し( 利用するPrjグラフ名:similarity { 対象ノードをフィルタリング:['Client'], 対象リレーションシップをフィルタリング:: ['SIMILAR_TO'], 重み付けアルゴリズム: 'jaccardScore', DBに書き込むノードのプロパティ名: 'firstPartyFraudScore' } ); - 結果
MATCH p=(:Client)-[s:SIMILAR_TO]->(:Client) RETURN p LIMIT 25;
firstPartyFraudScoreが追加されている。
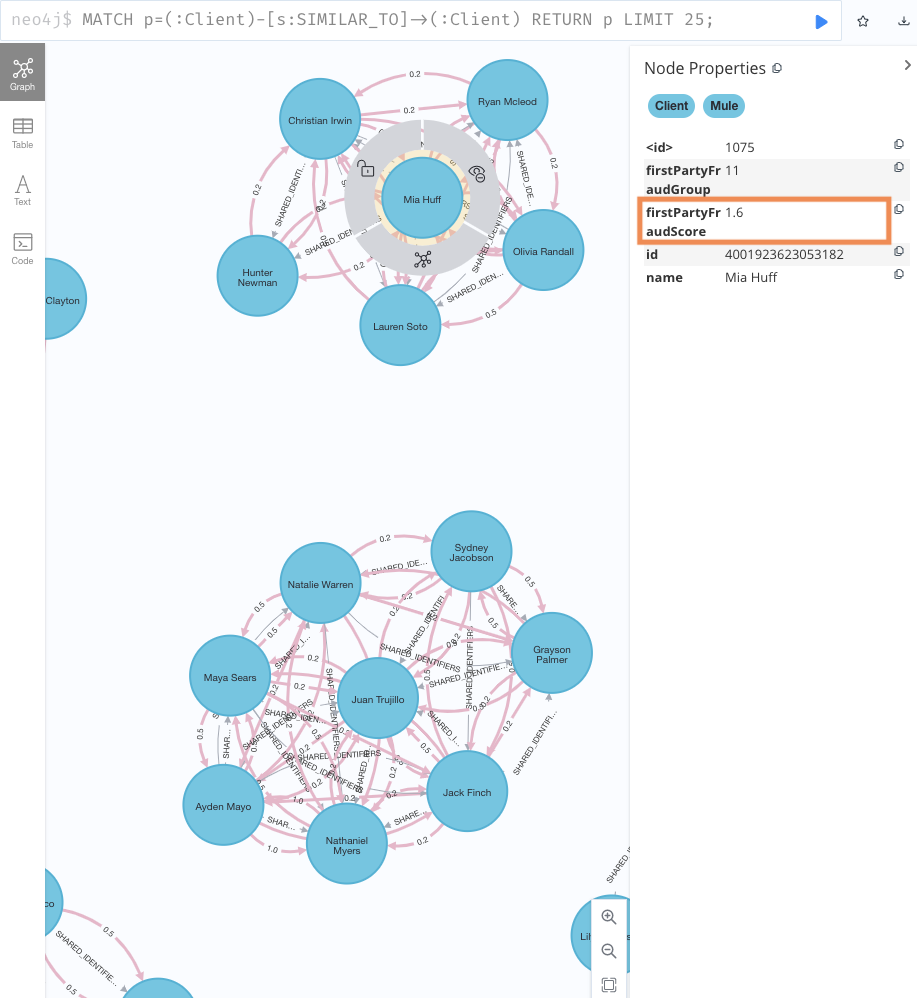
1-5. 不正者ラベルをつける
FirstPartyFraudScoreがある値以上クライアントを見つけ、FirstPartyFraudsterラベルを付けます。
このシナリオでは、95パーセンタイルを閾値として、FirstPartyFraudsterラベルを付けます。
- コード
MATCH (c:Client) WHERE c.firstPartyFraudScore IS NOT NULL WITH percentileCont(c.firstPartyFraudScore, 0.95) AS firstPartyFraudThreshold MATCH(c:Client) WHERE c.firstPartyFraudScore > firstPartyFraudThreshold SET c:FirstPartyFraudster;
-
結果のグラフ出力
MATCH p=(:FirstPartyFraudster)-[s:SIMILAR_TO]->(:Client) RETURN p limit 25;
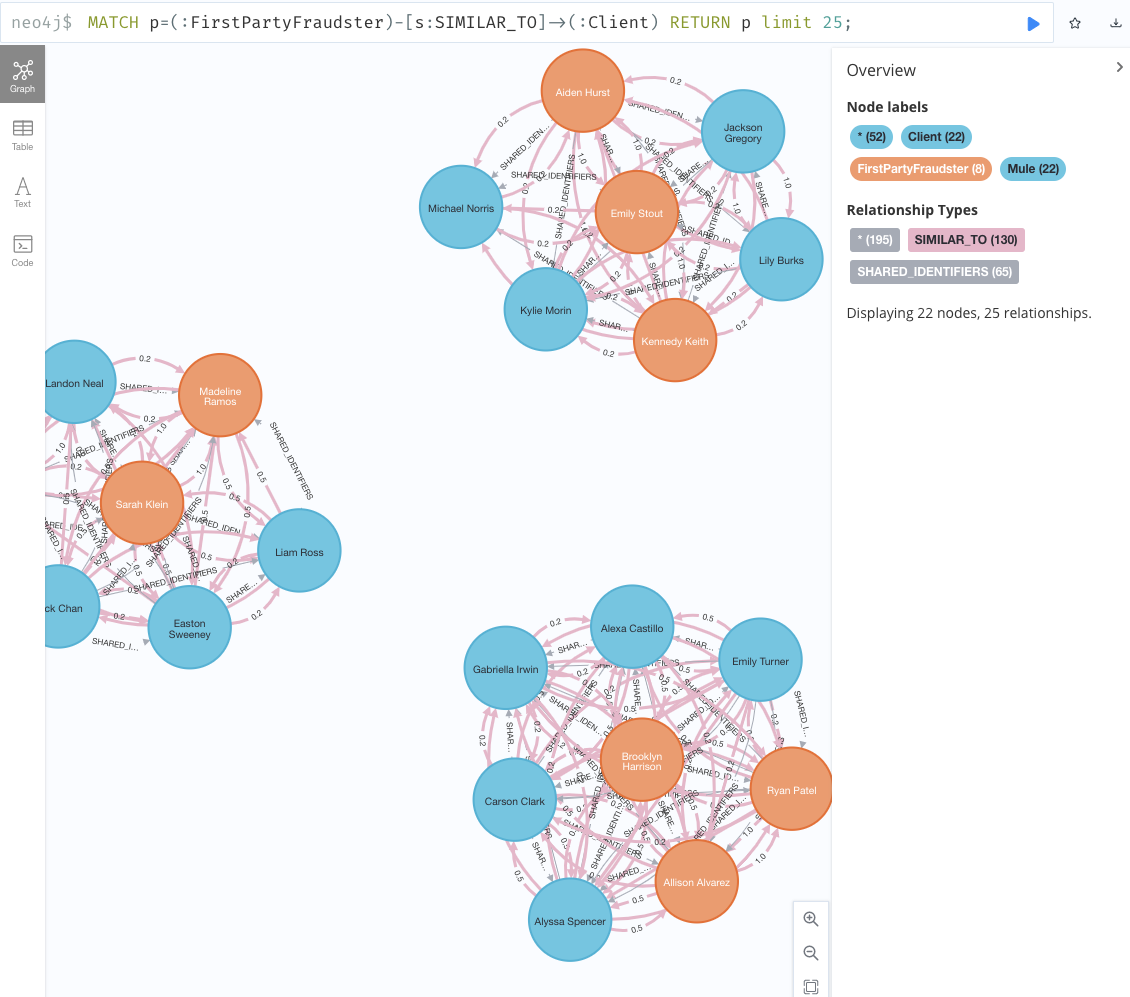
- 不正者のリストアップ
// Table出力 MATCH (f:FirstPartyFraudster) RETURN f.name AS ClientName, f.firstPartyFraudScore AS firstPartyFraudScore, f.firstPartyFraudGroup AS firstPartyFraudGroup ORDER by f.firstPartyFraudScore DESC; // またはJSON出力 MATCH (f:FirstPartyFraudster) RETURN f ORDER by f.firstPartyFraudScore DESC;
Table出力 JSON出力 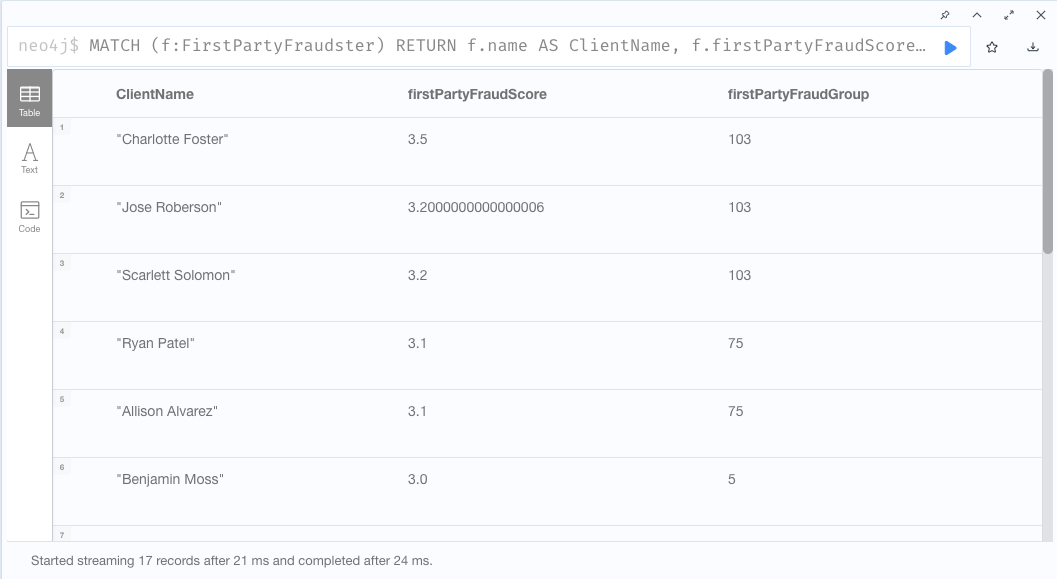

以上で、シナリオ1は終わりです。
シナリオ2:Second-Party不正者の検知
検知方針
FBIによると、犯罪者はオンライン不正や不正行為から得た収益を洗浄するために、マネーミュール(仲介人)を利用します。マネーミュールは被害者と不正者の間に何層もの距離を置き、法執行機関が追跡することを難しくしています。
このシナリオでは、下記の仮説をもとに、paysimのデータセットからマネーミュールを検出します。
First-Party不正者と取引を行うクライアントは、Second-Party不正のである可能性が高い。
First-Party不正者をサポートしている可能性があり、First-Party不正者候補として識別されていないクライアントを見つけることです。
下記のステップで検知を実施します。
- TRANSFER_TOリレーションシップの作成
- Second-Party不正者のクラスタを作成
- Second-Party不正者スコアを算出
2−1. TRANSFER_TOリレーションシップの作成
firstPartyFraudsterラベルを持つクライアントと他のクライアントの間に新たなリレーションシップを作成します。リレーションシップのプロパティとして、疑わしい取引の合計金額を追加します。
不正者からクライアントへの送金と、逆方向の送金がそれぞれあるので、別々のクエリでリレーションシップを作成する必要があります。
- Cypherコード
//First-Party不正者と取引があるクライアントにSecondPartyFraudSuspectラベルをつけ、TRANSFER_TOリレーションシップを作成する MATCH (c1:FirstPartyFraudster)-[]->(t:Transaction)-[]->(c2:Client) WHERE NOT c2:FirstPartyFraudster WITH c1, c2, sum(t.amount) AS totalAmount SET c2:SecondPartyFraudSuspect CREATE (c1)-[:TRANSFER_TO {amount:totalAmount}]->(c2);//逆方向のTRANSFER_TOリレーションシップを作成する MATCH (c1:FirstPartyFraudster)<-[]-(t:Transaction)<-[]-(c2:Client) WHERE NOT c2:FirstPartyFraudster WITH c1, c2, sum(t.amount) AS totalAmount SET c2:SecondPartyFraudSuspect CREATE (c1)<-[:TRANSFER_TO {amount:totalAmount}]-(c2); - 結果の表示
MATCH p=(:Client:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client) WHERE NOT c:FirstPartyFraudster RETURN p;
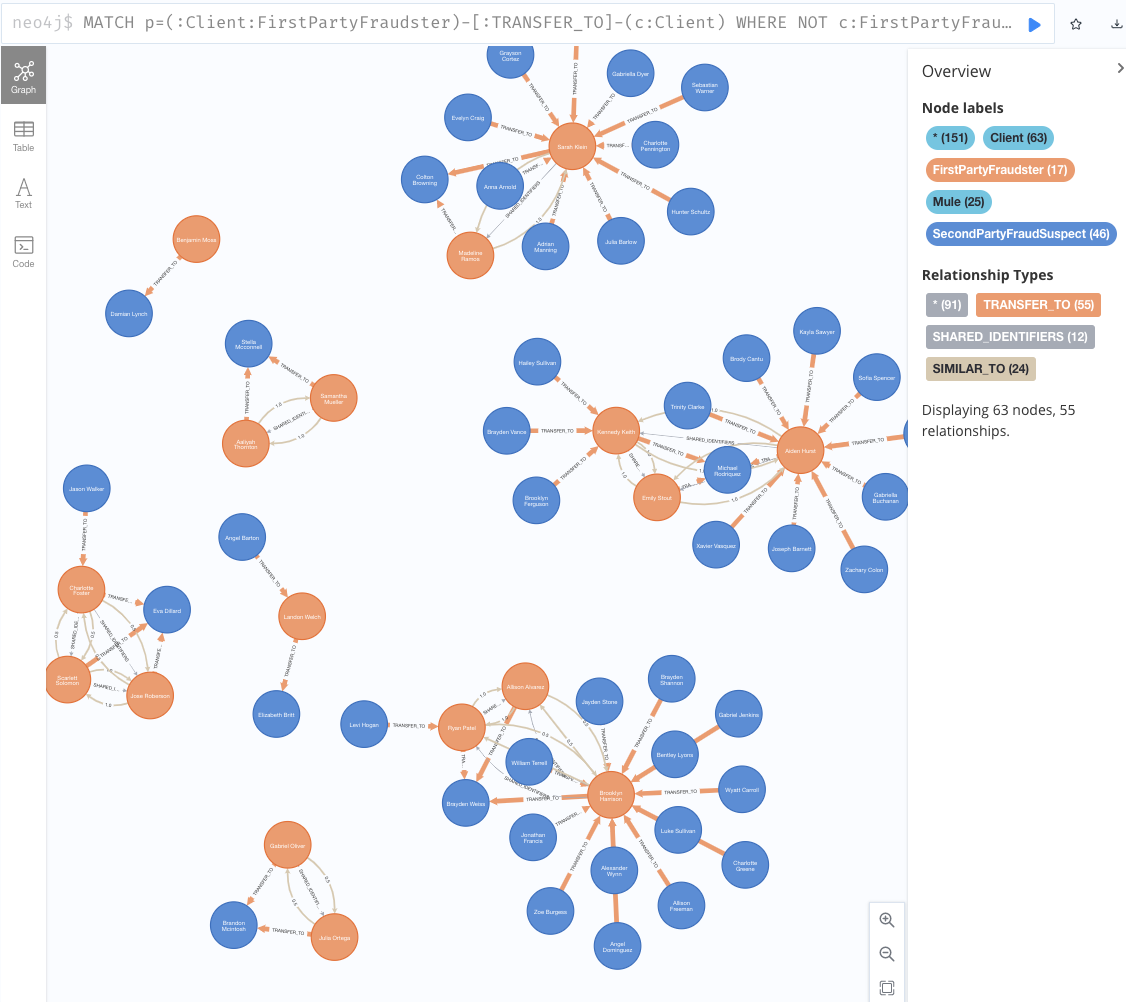
2−2. Second-Party不正者のクラスタを作成
クライアントノードとTRANSFER_TOリレーションシップをもとにメモリグラフSecondPartyFraudNetworkを作成します。
// メモリグラフ:SecondPartyFraudNetworkの作成
CALL gds.graph.project(
'SecondPartyFraudNetwork',
'Client',
'TRANSFER_TO',
{relationshipProperties:'amount'}
);
WCCメソッドを使用して、TRANSFER_TOリレーションシップでつながったクラスタを生成します。対象のクライアントノードにsecondPartyFraudGroupパラメータを追加し、クラスタIDをノードに書込みます。
(後でローカルクエリを使用してそれらを検索するようにします。)
//secondPartyFraudGroupプロパティにクラスタIDを追加
CALL gds.wcc.stream('SecondPartyFraudNetwork')
YIELD nodeId, componentId
WITH gds.util.asNode(nodeId) AS client, componentId AS clusterId
WITH clusterId, collect(client.id) AS cluster
WITH clusterId, size(cluster) AS clusterSize, cluster
WHERE clusterSize > 1
UNWIND cluster AS client
MATCH (c:Client {id:client})
SET c.secondPartyFraudGroup = clusterId;
結果の出力
MATCH p=(:Client:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client) WHERE NOT c:FirstPartyFraudster AND c.secondPartyFraudGroup is not Null RETURN p;
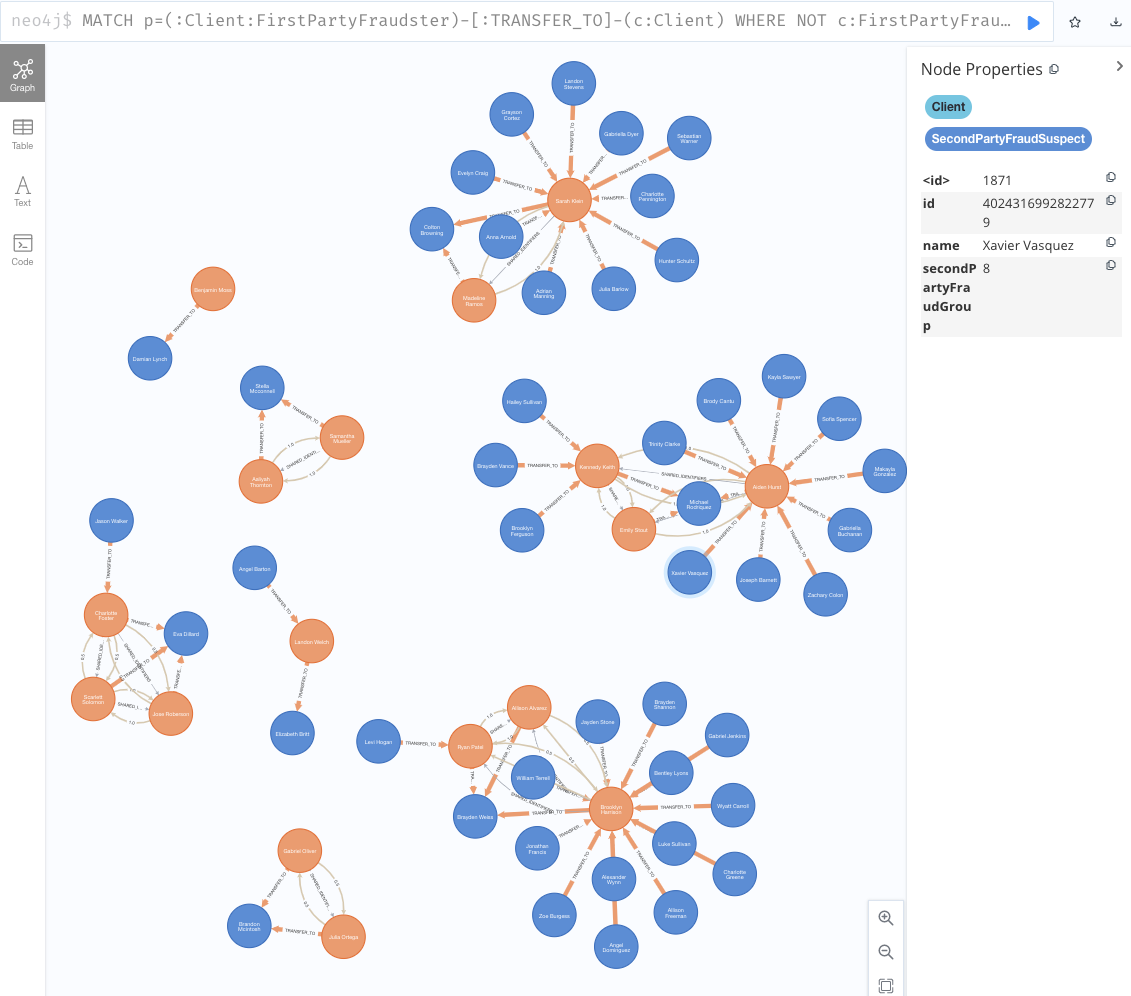
2-3. Second-Party不正者スコアを算出
First-Party不正者への送金総額で重みを付けたPageRankアルゴリズムをつかって、Second-Party不正者スコアを算出し、ノードプロパティsecondPartyFraudScoreに書き込みます。また、スコアリングされたノードをSecondPartyFraudとしてラベリングします
CALL gds.pageRank.stream(
'SecondPartyFrudNetwork',
{relationshipWeightProperty:'amount'}
)
YIELD nodeId, score
WITH gds.util.asNode(nodeId) AS client, score AS pageRankScore
WHERE client.secondPartyFraudGroup IS NOT NULL
AND pageRankScore > 0
AND NOT client:FirstPartyFraudster
MATCH (c:Client {id:client.id})
SET c:SecondPartyFraud
SET c.secondPartyFraudScore = pageRankScore;
以上で、Second-Party不正ネットワークを可視化できました。
これをもとに、様々な施策を実施します。
// Second-Party不正ネットワークの表示 MATCH p=(:Client:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client) WHERE NOT c:FirstPartyFraudster RETURN p;
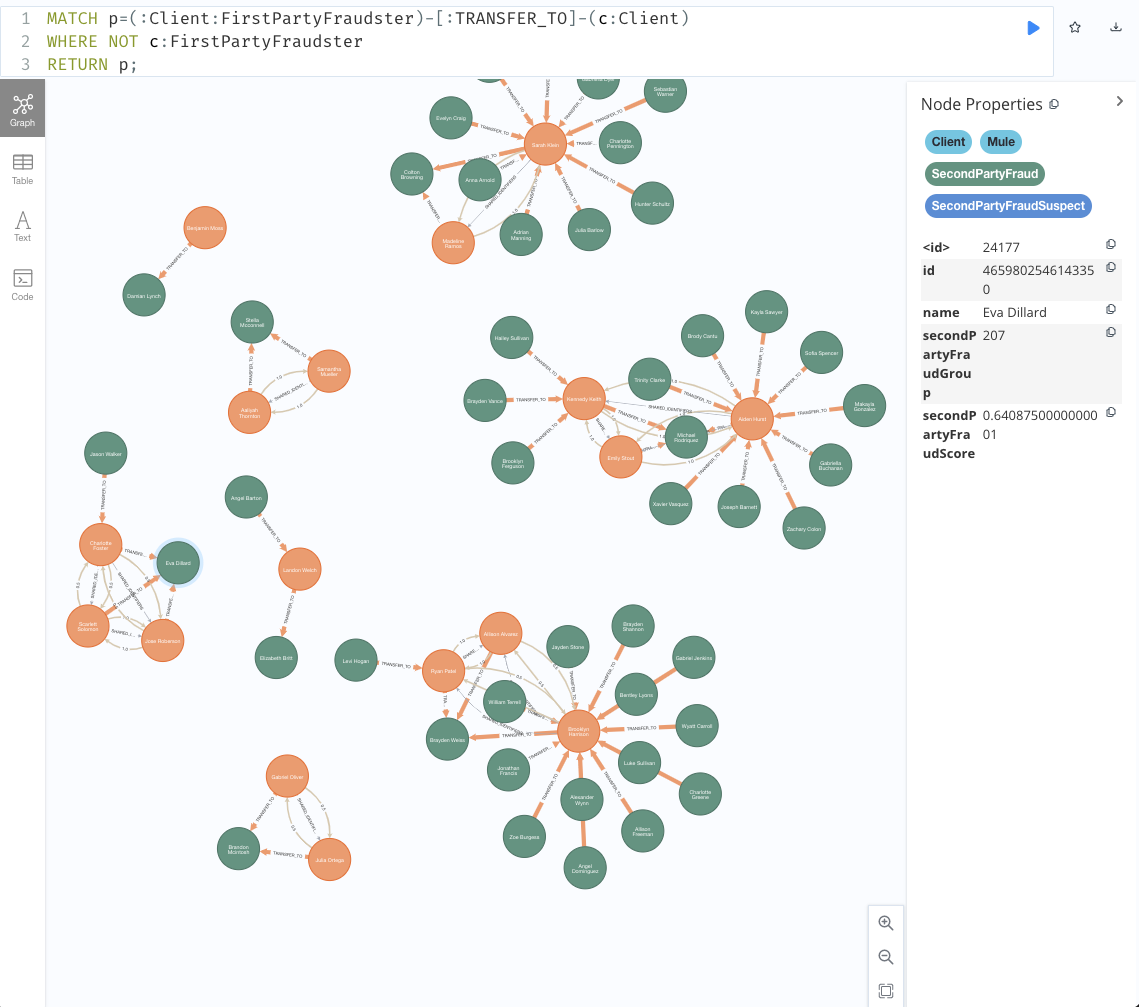
緑のノードがSecondPartyFraudで、secondPartyFraudScoreを持ちます。今回は全てをSecondPartyFraudにしましたが、FirstPartyFrauderのように、スコアから閾値を決めてラベリングもできます。



