
HadoopをMicrosoft Azure上で動かしてみる! (3/4)

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

クリエーションライン渡辺です。今回は連載の第三回で、Hadoopエコシステムの一つである並列グラフ処理基盤「Giraph」をAzure上で動かしてみます。データがハチの巣のように集まるApache Hiveの次はキリンの首の様にスケールアウトできるグラフ基盤Giraphです。
第三回: Giraphでネットワーク最短距離を探索する
1.Apache Giraphの紹介
Apache GiraphはAzure HDInsightに対応していて、ネットワーク分析などで応用されるグラフ処理をスケーラブルな環境で行うためのシステムです。現にFacebook社が自社の巨大なソーシャルネットワークの管理、分析に活用していることで有名です。GiraphはJavaで開発されていて、利点はやはりHadoopと連携してグラフ計算をHadoopジョブとして大量のデータに対して流すことができるということです。
ソーシャルネットワーク分析以外にも、グラフ処理はウェブのページランキングやコンピュータネットワーク間の最短距離などを調査することに便利です。CL Labでは普段あまり見られないユニークな応用も紹介しています。こちらもぜひご参照ください。
Apache Giraphのデータフロー
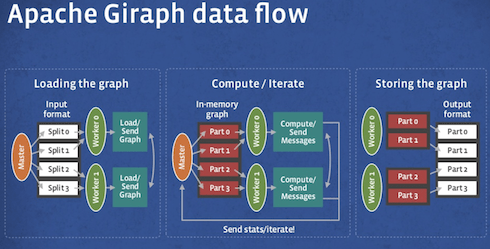
上記がGiraphにおける一般的なデータフローチャートです。まずマスターノードから指定されたフォーマットの入力がワーカーノードにロードされます。次にメモリ内に置かれたグラフに対して各ワーカーノード毎に繰り返しの処理が行われます。この間ワーカーノード間とワーカーノードからマスターへの通信は常に行われている状態です。最後に分割されたグラフが指定された出力ファイルとして保管されます。
2. 実践
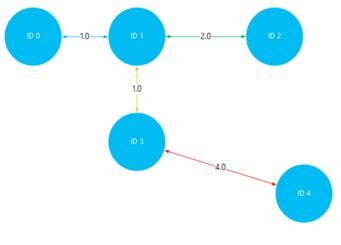
では早速実践に入ります。以下の図のようなネットワーク図を作成し、ノードID1から他のノードへの最短距離を探索します。
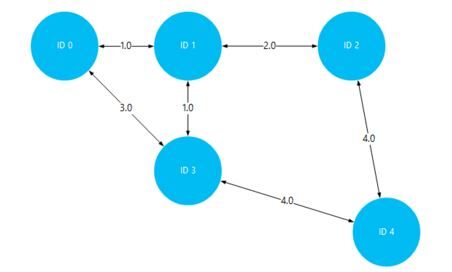
各頂点(ノード)にはIDが振られており、ノード間の辺(エッジ)には距離になる要素が含まれています。上図のデータを作成するために、vi エディタを開いて以下を書き込みます。
[0,0,[[1,1],[3,3]]]
[1,0,[[0,1],[2,2],[3,1]]]
[2,0,[[1,2],[4,4]]]
[3,0,[[0,3],[1,1],[4,4]]]
[4,0,[[3,4],[2,4]]]
このデータは[source_id, source_value,[ [destination_id, edge_value],[..., ...] ] ]という形式になっています。要するに[接続元ID, 接続元値, [ [ 接続先ID, 辺値], [..., ...] ] ] であります。
比較対象としてSparkのグラフ処理システムであるGraphXで上図を作成すると期待入力形式は以下のようになります。
0, 1, 1
0, 3, 3
1, 0, 1
1, 2, 2
1, 3, 1
2, 1, 2
2, 4, 4
3, 0, 3
3, 1, 1
3, 4, 4
4, 3, 4
4, 2, 4
GraphXではsource_id, destination_id, edge_value (接続元、接続先、辺値)という形式になります。
二つを比較するとSparkのグラフデータ形式は読みやすく、初見で理解しやすいことがわかります。この形式にパースするのも比較的簡単であります。一方でGiraphは各ノードからの辺を1行でまとめて格納しているのでデータ行が少なくなります。グラフデータをエッジデータとノードデータに分ける必要もありません。
続いて作成したグラフデータをプライマリストレージに格納します。プライマリストレージとはHDInsightのストレージにあたるBLOBストレージ上で動いているHDFSです。以下のコマンドで行います。
hadoop fs -copyFromLocal tiny_graph.txt /example/data/tiny_graph.txt
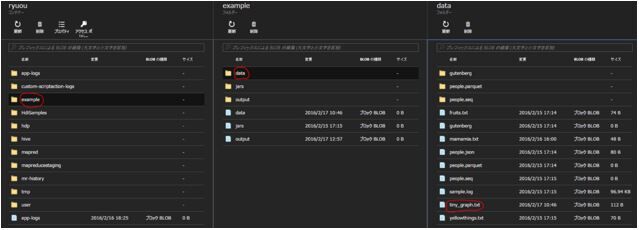
プライマリストレージは各クラスターごとにコンテナで区別されています。ryuoクラスターのコンテナ内の/example/data/に作成したグラフが格納されたことが分かります。
次にGiraphプログラムのパラメータとして必要であるサーバーのFQDNを取得します。
hostname -f
watanabe@hn0-ryuou:~$ hostname -f
hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net
FQDNを取得したら、以下のコマンド形式でGiraphプログラムを実行します。
hadoop jar (jarファイル) (クラス名) (関数) -ca (ヘッドノード) -vif (入力形式) -vip (入力データ) -vof (出力形式) -op (出力場所) -w (ワーカー数)
実例
watanabe@hn0-ryuou:~$ hadoop jar /usr/hdp/current/giraph/giraph-examples.jar org.apache.giraph.GiraphRunner org.apache.giraph.examples.SimpleShortestPathsComputation -ca mapred.job.tracker=HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.clou>dapp.net -vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat -vip /example/data/tiny_graph.txt -vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat -op /example/output/shortestpaths -w 2
出力結果
16/02/17 02:21:44 INFO utils.ConfigurationUtils: No edge input format specified. Ensure your InputFormat does not require one.
16/02/17 02:21:44 INFO utils.ConfigurationUtils: No edge output format specified. Ensure your OutputFormat does not require one.
16/02/17 02:21:44 INFO utils.ConfigurationUtils: Setting custom argument [mapred.job.tracker] to [HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net] in GiraphConfiguration
16/02/17 02:21:46 INFO job.GiraphJob: run: Since checkpointing is disabled (default), do not allow any task retries (setting mapred.map.max.attempts = 1, old value = 10)
16/02/17 02:21:47 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/
16/02/17 02:21:48 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
16/02/17 02:21:52 INFO mapreduce.JobSubmitter: number of splits:3
16/02/17 02:21:52 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455616569359_0006
16/02/17 02:21:53 INFO impl.YarnClientImpl: Submitted application application_1455616569359_0006
16/02/17 02:21:54 INFO mapreduce.Job: The url to track the job: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455616569359_0006/
16/02/17 02:21:54 INFO job.GiraphJob: Tracking URL: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455616569359_0006/
16/02/17 02:21:54 INFO job.GiraphJob: Waiting for resources... Job will start only when it gets all 3 mappers
16/02/17 02:31:19 INFO job.HaltApplicationUtils$DefaultHaltInstructionsWriter: writeHaltInstructions: To halt after next superstep execute: 'bin/halt-application --zkServer 10.0.0.5:22181 --zkNode /_hadoopBsp/job_1455616569359_0006/_haltComputation'
16/02/17 02:31:19 INFO mapreduce.Job: Running job: job_1455616569359_0006
16/02/17 02:31:20 INFO mapreduce.Job: Job job_1455616569359_0006 running in uber mode : false
16/02/17 02:31:20 INFO mapreduce.Job: map 67% reduce 0%
16/02/17 02:51:22 INFO mapreduce.Job: map 100% reduce 0%
16/02/17 02:51:23 INFO mapreduce.Job: Job job_1455616569359_0006 failed with state KILLED due to: Kill job job_1455616569359_0006 received from watanabe (auth:SIMPLE) at 10.0.0.5
Job received Kill while in RUNNING state.
おっとfailしてしまいました。前回のR検証の際のバグも踏まえて推測するとどうやらreduceの処理が怪しいです。
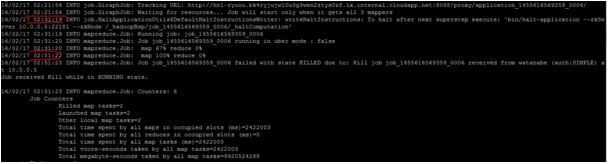
キュー待ちで反応がなく、killされている状態であります。
tracking URLにアクセスしても、接続拒否されています。
![]()
reduceは各ノードの結果を集計する作業なので、もしかすると原因はワーカーノードが1個の場合、動かないのではないかと推測します。(*連載第一回クラスタ作成のノード料金レベルを参照)
そこでダッシュボードの「すべてのリソース」→「クラスタ名(ryuou)」→「クラスタのスケール設定」→「ワーカーノードの数」を設定し直します。
以前は1ノードで検証を行っていたが、ノード数を2個に更新しました。
再挑戦してみます
watanabe@hn0-ryuou:~$ hadoop jar /usr/hdp/current/giraph/giraph-examples.jar org.apache.giraph.GiraphRunner org.apache.giraph.examples.SimpleShortestPathsComputation -ca mapred.job.tracker=HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net -vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat -vip /example/data/tiny_graph.txt -vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat -op /example/output/shortestpaths -w 2
出力
16/02/17 05:37:32 INFO utils.ConfigurationUtils: No edge input format specified. Ensure your InputFormat does not require one.
16/02/17 05:37:32 INFO utils.ConfigurationUtils: No edge output format specified. Ensure your OutputFormat does not require one.
16/02/17 05:37:32 INFO utils.ConfigurationUtils: Setting custom argument [mapred.job.tracker] to [HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net] in GiraphConfiguration
16/02/17 05:37:34 INFO job.GiraphJob: run: Since checkpointing is disabled (default), do not allow any task retries (setting mapred.map.max.attempts = 1, old value = 10)
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory wasb://ryuou@akibaline.blob.core.windows.net/example/output/shortestpaths already exists
再度failいたしましたが、「すでにアウトプットファイルが存在する」というエラーですので、再実行の際は生成済みの出力ディレクトリを消すか、出力ディレクトリ先を変更することが必要です。
再々挑戦
watanabe@hn0-ryuou:~$ hadoop jar /usr/hdp/current/giraph/giraph-examples.jar org.apache.giraph.GiraphRunner org.apache.giraph.examples.SimpleShortestPathsComputation -ca mapred.job.tracker=HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net -vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat -vip /example/data/tiny_graph.txt -vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat -op /example/output/shortestpaths -w 2
出力
16/02/17 03:58:09 INFO utils.ConfigurationUtils: No edge input format specified. Ensure your InputFormat does not require one.
16/02/17 03:58:09 INFO utils.ConfigurationUtils: No edge output format specified. Ensure your OutputFormat does not require one.
16/02/17 03:58:09 INFO utils.ConfigurationUtils: Setting custom argument [mapred.job.tracker] to [HEADNODE:hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net] in GiraphConfiguration
16/02/17 03:58:10 INFO job.GiraphJob: run: Since checkpointing is disabled (default), do not allow any task retries (setting mapred.map.max.attempts = 1, old value = 10)
16/02/17 03:58:12 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/
16/02/17 03:58:13 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
16/02/17 03:58:16 INFO mapreduce.JobSubmitter: number of splits:3
16/02/17 03:58:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455616569359_0007
16/02/17 03:58:17 INFO impl.YarnClientImpl: Submitted application application_1455616569359_0007
16/02/17 03:58:17 INFO mapreduce.Job: The url to track the job: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455616569359_0007/
16/02/17 03:58:17 INFO job.GiraphJob: Tracking URL: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455616569359_0007/
16/02/17 03:58:17 INFO job.GiraphJob: Waiting for resources... Job will start only when it gets all 3 mappers
16/02/17 03:58:39 INFO job.HaltApplicationUtils$DefaultHaltInstructionsWriter: writeHaltInstructions: To halt after next superstep execute: 'bin/halt-application --zkServer 10.0.0.5:22181 --zkNode /_hadoopBsp/job_1455616569359_0007/_haltComputation'
16/02/17 03:58:39 INFO mapreduce.Job: Running job: job_1455616569359_0007
16/02/17 03:58:40 INFO mapreduce.Job: Job job_1455616569359_0007 running in uber mode : false
16/02/17 03:58:40 INFO mapreduce.Job: map 33% reduce 0%
16/02/17 03:58:47 INFO mapreduce.Job: map 67% reduce 0%
16/02/17 03:58:57 INFO mapreduce.Job: map 100% reduce 0%
16/02/17 03:59:06 INFO mapreduce.Job: Job job_1455616569359_0007 completed successfully
16/02/17 03:59:06 INFO mapreduce.Job: Counters: 53
処理が詰まりません!やった!これで正常完了です。
正常サイン
Giraph Stats
Aggregate edges=12
Aggregate finished vertices=5
Aggregate sent message message bytes=410
Aggregate sent messages=12
Aggregate vertices=5
Current master task partition=0
Current workers=2
Last checkpointed superstep=0
Sent message bytes=0
Sent messages=0
Superstep=4
Giraph Timers
Initialize (ms)=13670
Input superstep (ms)=307
Setup (ms)=62
Shutdown (ms)=9116
Superstep 0 SimpleShortestPathsComputation (ms)=109
Superstep 1 SimpleShortestPathsComputation (ms)=125
Superstep 2 SimpleShortestPathsComputation (ms)=88
Superstep 3 SimpleShortestPathsComputation (ms)=72
Total (ms)=9881
出力された結果を見てみます。HadoopやSparkなどの並列処理システムの設定では出力ファイルは各ノードごとに吐き出されるため、textコマンドを使いHDFS上でまとめてから見るか、getコマンド後にローカルでcatします。
watanabe@hn0-ryuou:~$ hadoop fs -text /example/output/shortestpaths/*
0 1.0
4 5.0
2 2.0
1 0.0
3 1.0
ID1ノードからの最短経路グラフの図
以上です。Giraphの公式チュートリアルはこちらです。
ここまでの感想
今回のエラーは他所でコンパイル済みのサンプルjarファイルを使用したことで発生しました。既存のjarプログラムの作動範囲の環境を整備することが重要でした。仮にソースコードが提供されていたのであれば、自分の環境にも対応するようプログラムを修正し、jarファイルをコンパイルし直すこともできたのかなと思います。いずれにしてもエラーの内容をよく見て、適切に対応することが大切です。
次回はazureのクラスターをコマンドラインで操作できるCLI(コマンドラインインターフェース)を使ってみます。



