
HadoopをMicrosoft Azure上で動かしてみる! (1/4)

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

クリエーションライン渡辺です。今回はMicrosoft Azure上でHDInsightを動かしてみる検証を行います。全4回の連載としてお送りします。今回は第1回として、Microsoft Azure, HDInsightの紹介から、HDInsightクラスター作成までを紹介します。
第1回: HDInsightイントロダクションとクラスター作成
1. Microsoft Azureの紹介
Microsoft AzureはMicrosoftが提供するパブリッククラウドプラットフォームです。プラットフォームというのですから簡単に説明すれば構築基盤ですが、このプラットフォームという表現は様々な意味で適切です。
この「プラットフォーム」にのればクラウド上の様々なアプリケーションの出入り口となりますし、クラウド基盤のプロトタイプを作り上げることができます。要するに空色(Azureの日本語訳)のプラットフォームに乗ればクラウドなんて容易に手が伸ばせるということです。素晴らしいですね!
AWSとよく比較されるAzureですが、その中でAzureの人気ソリューションは以下の図に示されています。

アプリのデプロイ、仮想マシンの作成、データベース管理、データ分析など幅広く活躍するなんでも屋さんです。もちろんMicrosoft製品であるOffice 365やPowerBIなどにも連携しています。
2. HDInsightの紹介
HDInsightはオンプレミス環境では構築・運用ともに扱いにくいHadoopシステムを簡単に利用できるサービスです。Hortonworks社と連携して開発されたオリジナルのHadoopがWindowsで動く仕様になっています(Hadoop on Windows serverの取組みについては、たくさんの解説記事があるのでそちらを参照ください。例えば技術評論社gihyo.jpに詳しい解説記事が掲載されています: gihyo.jp - 「HDInsightを知る~ビッグデータ×クラウド - 第1回 HDInsightとは何か?」)。
HDInsightは高コストである何百ノードのクラスター構築、運用を効率化するために従来の年間あたりのサブスクリプション購入ではなく、時間あたりの課金をサポートしています。つまり、必要な時にクラスターを作成し、ジョブが終わり次第削除でき、使った分だけ料金を支払うことで大規模な計算ジョブを低価格で実行できるという柔軟性を保ちます。
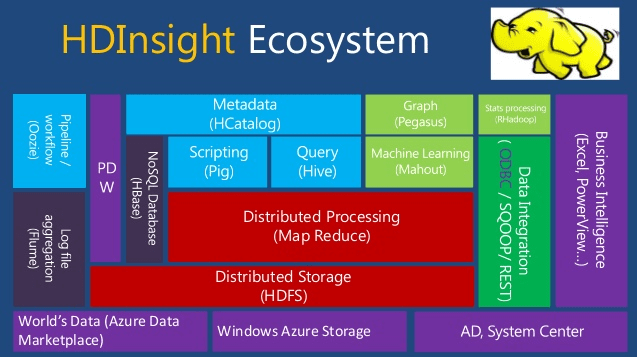
HDInsightのエコシステム図を見ていただくと、Hadoop専用のストレージから機械学習ライブラリなどの多様なコンポーネントがサポートされていることが分かります。
3. アカウント+クラスター作成
では実際にHadoopをAzureで動かしてみましょう。
3-1. アカウント作成
まずはお決まりのアカウント作成をします。必要なアカウントは以下になります。
a) Microsoftアカウント
マイクロソフト公式のサイトから作成し (https://signup.live.com/)、メールで本人確認し、ログインします。
b) MicrosoftAzureアカウント
先ほど取得したMicrosoftアカウントを使い、Azureにサインアップします (https://portal.azure.com/)。この際に無料お試しサービスを選択(1ヶ月)します。
3-2. クラスター作成
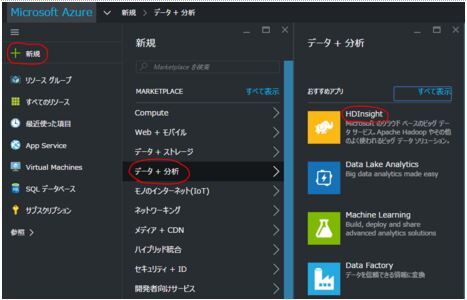
Azureポータルにログインしたら、以下のようなダッシュボードにたどり着きます。まずはクラスターを作成してみましょう。ダッシュボード画面から新規、データ+分析、HDInsightをクリックします。
ダッシュボード画面
尚、Azureアカウントを作成の際にサブスクリプションを登録してない場合はここでサブスクリプション登録画面に飛びます。
サブスクリプション登録画面
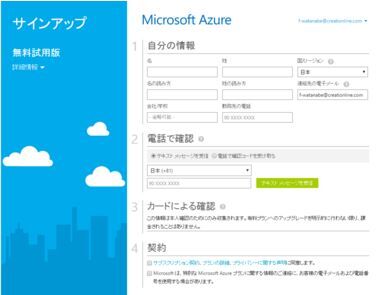
サブスクリプションはMicrosoft Azureの利用契約です。サブスクリプションを新規登録すると20,500円分の無料試用権(クレジット)が付属してきます。※2016年3月3日 現在
サブスクリプションの登録が完了すると以下のようなクラスター設定ブレードが現れます。最初に新規のクラスターの根本的な設定を行います。
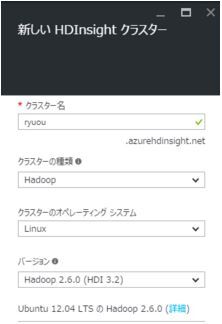
クラスター名、クラスター種類、オペレーティングシステム、バージョンを選択できます。クラスターの種類はHadoopのほかに、HBase, Storm, Sparkなどが利用できます。OSもLinux、Windowsから選択できます。
クラスター種類を選択し構築することは簡単なのですが、現状では複数のクラスターを一緒にして(例えばHBaseとStormを一緒のクラスターとして)構築することはできないようです。さらに、一度作成したクラスターに、後からSparkやStormなどを追加することもできない模様です。このオプションがあると便利だと思います。
次にクラスターの細かな設定を行います。基本設定の下には以下のようなブレードがあります。
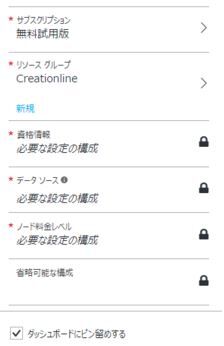
サブスクリプションは上記で登録した無料試用版を使用します。
リソースグループはクラスターやストレージ、及び仮想マシンなどのリソースを作成する際これらの親となり、グループの管理が容易になります。初回なので制限上の名前を使い、新規で作成します。今後作成するクラスターは既在のリソースグループが使えます。
次に資格情報を入力します。
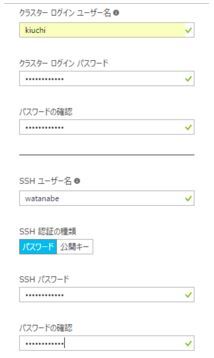
資格情報で指定するクラスターユーザ名はジョブ監視ツールなどのWebUIにログインする時に使います。SSHユーザ名はリモートでSSHを使いクラスターサーバにログインする時に使います。クラスターユーザ名とSSHユーザ名は同じにしてはいけないようです。
次にデータソースを設定します。
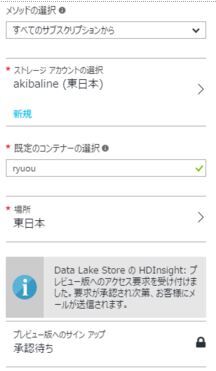
ストレージアカウントはAzure特有のBLOBストレージを管理するアカウントです。今回はリソースグループ同様新規で作成し、名前を付けます。コンテナは各ストレージに対して複数作成できます。名前はクラスター名と同じにすることが推奨されてます。これによりデータの紐づけ、管理が容易になります。場所はクラスターと同じ場所を選びます。
次にノード料金レベルを設定します。
ノード料金レベルでは様々なスペックのオプションとその価格を選択することができます。一時間単位の価格です。無償版のクレジットは1ノードでおよそ5日ほど使える程度の価格になっています。
最後に省略可能な構成を設定します。
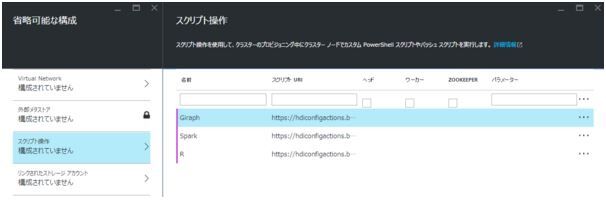
省略可能と書いてありますが、ここではスクリプト操作という追加のパッケージをインストールできるオプションがあります。ここでSpark、Giraph、R、Hue、Solrなどのツールを併用して追加できるオプションがあります。必要に応じてスクリプトリストからURLを貼って準備をします。(サンプルスクリプト: https://hdiconfigactions.blob.core.windows.net/linuxrconfigactionv01/r-installer-v01.sh)
ただし、このアクションスクリプトはクラスター作成後には実行できないようです。一通り探してはみたのですが、一度作成したクラスターに後からアクションスクリプトを適用する操作を見つけることができませんでした。ユーザ視点から考えると、クラスター作成時には必要ないと思っていた機能をあとから追加したい場合もありますので、作成後のクラスターにアクションスクリプトを実行できるような機能があれば、便利になると考えます。
これらをすべて設定し作成ボタンを押すと、デプロイが開始されます。追加したオプションによってデプロイ時間が変わりますが、私の場合は追加物無しで20分くらいかかりました。リージョンは東日本です。
開始と終了には通知が来ます。これでクラスターが完成します。
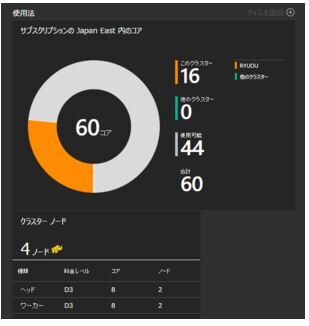
ここまでの感想
引っかかったところは登録するアカウント情報、クラスター設定情報の数が多かったので、それぞれ異なる名前をつける手間がかかったぐらいでしょうか。命名条件を満たさない物は教えてくれるので慣れの問題でもあります。デプロイ時間は他のHadoopディストリビューションと比較しても一般的です。Hadoop単体のインストールで20分ぐらい掛かりました。例えばテンプレートを展開して少し設定を修正して動かせるようになれば、もっとデプロイを高速化できると思います。
しかし、デプロイにたどり着くまでのクラスター設定などの作業が非常に直感的なので、全体のクラスター作成作業は早く感じました。プロセス、リソースの可視化はピカイチです。すぐに処理状況、スペックの監視ができます。公式のチュートリアルも非常に解りやすかったです。
続きは作成したクラスターでApache HiveとRを使ってみます!



