
HadoopをMicrosoft Azureで動かしてみる! (2/4)

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

クリエーションライン渡辺です。今回は連載の続きで、前回作成したHDInsightクラスターを使い、Apache HiveとRの動作検証を行います。まずApache HiveとRの概要説明から入り、その後実際に手を動かしています。
第2回: Apache HiveとRの検証
1. Apache Hiveの紹介
Apache HiveはHadoopに詳しい方にはすでに説明不要というぐらいメジャーなHadoopコンポーネントです。改めて解説すると、Apache Hiveは並列処理基盤に対応するデータウェアハウスシステムです。HiveQLというSQL言語に似たクエリ言語を使い、HDFS上のデータに対して、集計や分析などを行います。Hiveの利点としては巨大な非構造データに構造を被せることができます。これでJavaやMapReduceの知識がない方も、HiveQLを使い、SQLに近いステートメントでデータを検索することができます。
2. Apache HiveでApache log4jファイルを調査する
では早速実践に入ります。最初にAzureポータルにログインし、ダッシュボードの「すべてのリソース」から作成した専用クラスターを選択します。画面中央にあるクイックリンクの中から監視ツールの一つであるAmbari Viewsを選択するとウェブUIが開かれます。
ポータルのダッシュボード画面
WebUIが開いたら、クラスター作成時に登録したクラスター名とパスワードを入力し、ユーザ認証をします。
Apache AmbariのUIはとても綺麗ですが、動作にすこし不可解なところがあります。一回目に開いたときはなぜかAmbariがload状態で詰まります(正しい名前とパスを記入したにも関わらず)。ぺージ更新ボタンを押すと素早くロードされます。もう一つ気になったところはログインする際に認証を間違えたらブラウザーを一回閉じないと再認証させてくれなかった所です。これは少し不便です。
認証とロードが完了したら、画面右上のオプションボタンの中からHive Viewを開きます。すると以下のようなスクリーンに飛びます。
Hive View画面
今回使用するサンプルファイルは、Azure専用ストレージシステムであるBLOBコンテナに格納されているApache のlog4jファイルです。このファイルはスペースで区切られた、以下脳様なデータ形式で格納されています。
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
Query Editorという入力ボックス内に以下のコマンドを入れます。
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION 'wasb:///example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;
すぐに結果がでるはずです。処理後の結果は画面下に表示されます。
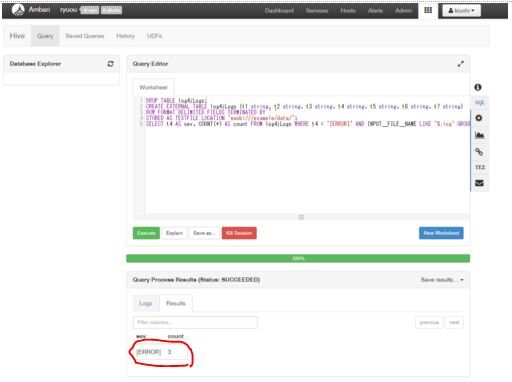
このファイルは3つのエラーログが記録されていました。
演習用にGROUP BY をGROUPBYにしてエラー画面をチェックすると以下のように教えてくれます。
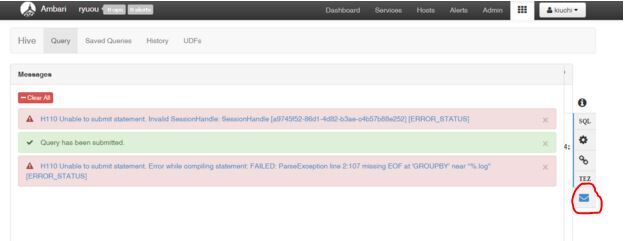
Missing EOF at 'GROUPBY'と適切に教えてくれます。
クエリーをセーブしたい、もしくはクエリー結果をセーブしたいという場合は以下の番号がついた場所を選択します。
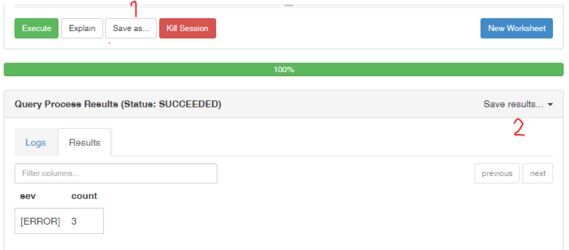
1のSave asはクエリの保存を行い、2のSave resultsは結果のダウンロードを行います。これは便利です。
Hive Viewと同様に右上のオプションにあるTez Viewを利用し、有効非巡回グラフ(DAG)を観覧してみます。
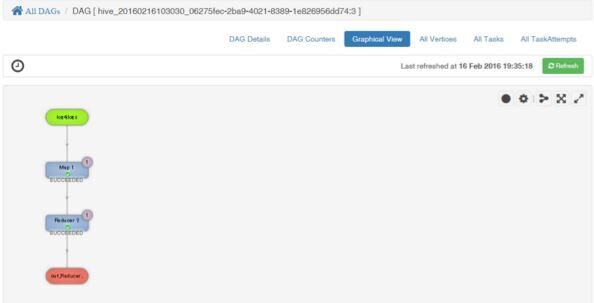
これを選択すると流したジョブのステージが詳しく示されています。もう少し複雑なジョブを流すと、バグ追跡に役立ちます。
以上がApache Hiveを使った簡単なログ分析でした。この検証はMicrosoft Azureの公式チュートリアルに基づいています。
3. RをHadoop環境で動かす
これからアクションスクリプトとして追加したRをHadoopジョブとして流しています。Rはオープンソースの統計処理システムです。データサイエンティストに好まれ、Rを利用してできないデータ分析はないというほどまで言われていますが、一番の課題は速度です。ある一定のデータ量を超えると、処理が非常に重くなります。そこで、RをHadoop環境で並列処理することでこの問題を解決し、強みである幅広いデータ分析を行います。
そこで、並列環境に変えたRジョブはどれだけ違うのかを比較する検証を行います。
Rはクラスター作成時にすでにインストール済みなので、Rコマンドを呼ぶだけで起動します。
watanabe@hn0-ryuou:~$ R R version 3.2.3 (2015-12-10) -- "Wooden Christmas-Tree" Copyright (C) 2015 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit)
疑問: ここでふと思ったことですが、もしクラスターをスケールアウトし、ノード数を増やしたら、アクションスクリプトなどの機能はすでに各ノードにインストールされているのでしょうか?これはドキュメント設備の問題かもしれませんが、クラスタースケーリング後に内部構造がどのようになるのかについて言及されていると助かります。
では早速Rのジョブを流します。初めにHadoopと連携するために必要なライブラリを呼び、簡単な関数を実行します。
> library(rmr2) > ints = to.dfs(1:100) > calc = mapreduce(input = ints, map = function(k, v) cbind(v, 2*v))
まず、1から100の配列を作成し、HDFS上に格納します。mapReduce関数を使い、配列を2倍にした数値と一緒にデータフレームを作成します。Hadoop上のRジョブの結果はHDFS上から呼び戻さなければいけませんので、以下のように結果を呼ぶだけだと、格納されているフォルダーへのポインターしか表示されません。
>print(calc()) [1] "/tmp/fileb10c5b8b52eb"
結果を呼び出す方法はfrom.dfsを使用します。
>print(from.dfs(calc())) $key NULL $val v [1,] 1 2 [2,] 2 4 [3,] 3 6 [4,] 4 8 ………… [97,] 97 194 [98,] 98 196 [99,] 99 198 [100,] 100 200
従来のローカルなRジョブと比較してみます。
> v = 1:100 > calc = cbind(v, sapply(v, function(x) x^2)) > print(calc) v [1,] 1 1 [2,] 2 4 [3,] 3 9 [4,] 4 16 ……………
Hadoopの場合はまずデータをHDFS上に格納しないといけません。さらにクラスタ環境なのでmapreduce関数をsapplyの代わりに呼び、各ノード間で共有する変数を扱うためのキーバリュ―の形式で実行します。最後に出力もHDFS上にあるので従来のやり方ではポインターしか呼ばれないので、from.dfsを使わないといけません。
続いて、もう少しヘビーな処理を行います。二項分布を求める関数をローカルRジョブとHadoopRジョブで比較します。
ローカルジョブ
> groups = rbinom(32, n = 50, prob = 0.4) > tapply(groups, groups, length) 7 8 9 10 11 12 13 14 15 16 17 18 1 2 3 1 6 7 9 6 4 6 3 2
既存のライブラリからrbinom関数を使って、例えばコインが表となる確率が40%あった時に32回中何回表となったかを数えます。この検査を50回行い、何回表となったのかを纏めた答えが上記となります。
続いてHadoop環境で同じジョブを流したいときは以下のようなコマンドになります。
> groups = to.dfs(groups) 16/02/16 09:02:10 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library 16/02/16 09:02:10 INFO compress.CodecPool: Got brand-new compressor [.deflate] > from.dfs(mapreduce(input = groups, map = function(., v) keyval(v, 1), reduce = function(k, vv) keyval(k, length(vv))))
まず先ほど作成したgroups変数をHDFS上に格納します。普段大量のデータをHDFS上に格納するのはこの方法ではなく、FlumeやSqoopのようなスケーラブルにデータ移動を行えるシステムを使用します。しかし、今回の入力はgroupsという変数を使用したデータの場所を保管してあるビッグデータオブジェクトですので、to.dfsを利用します。
map関数は各ノードに散らばったgroups変数に値する表回数をカウントします。reduce関数はカウントの数をまとめます。
一回目の実行結果は以下のような出力でした。
packageJobJar: [] [/usr/hdp/2.2.9.1-1/hadoop-mapreduce/hadoop-streaming-2.6.0.2.2.9.1-1.jar] /tmp/streamjob2096906629556146005.jar tmpDir=null 16/02/16 09:03:07 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/ 16/02/16 09:03:07 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/ 16/02/16 09:03:08 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 16/02/16 09:03:09 INFO mapred.FileInputFormat: Total input paths to process : 1 16/02/16 09:03:09 INFO mapreduce.JobSubmitter: number of splits:2 16/02/16 09:03:10 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455523261589_0016 16/02/16 09:03:11 INFO impl.YarnClientImpl: Submitted application application_1455523261589_0016 16/02/16 09:03:11 INFO mapreduce.Job: The url to track the job: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455523261589_0016/ 16/02/16 09:03:11 INFO mapreduce.Job: Running job: job_1455523261589_0016 16/02/16 09:03:20 INFO mapreduce.Job: Job job_1455523261589_0016 running in uber mode : false 16/02/16 09:03:20 INFO mapreduce.Job: map 0% reduce 0% 16/02/16 09:03:25 INFO mapreduce.Job: Task Id : attempt_1455523261589_0016_m_000000_0, Status : FAILED Error: Java heap space 16/02/16 09:03:31 INFO mapreduce.Job: Task Id : attempt_1455523261589_0016_m_000000_1, Status : FAILED Error: Java heap space
・・・見事に失敗してしまいました。
一つ目の比較ジョブは厳密にいうとmap処理だけを行っていました。二つ目のジョブはmap処理とreduce処理が入ったものであります。従って現状の環境ではRのmapReduceジョブはreduceを組み込むとfailする結果となりました。
ErrorがJava heap spaceということで、リソース・ジョブ監視ツールであるAmbariを使用し修正を試みました。
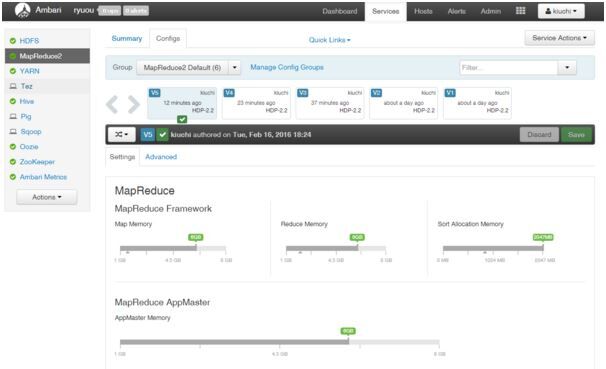
Ambari画面のService→MapReduce2を選択すると、初見とは思えないほど見慣れた設定画面に辿りつきました。従来設定では1024mbに設定されていましたが、徐々に上げていき、成果が見られなかったため、最終的には思い切って6GBまで上げました。
この一連の操作で感じたことはAmbariのレコメンド設定はすごく便利であるにもかかわらず、リスタート操作は少し不便であることです。
レコメンド設定というのは一つの設定を変えると依存性のあるコンフィグを知らせてくれる機能です。さらに、変更事項によって影響を受けた設定の適切値を推薦してくれるので助かります。
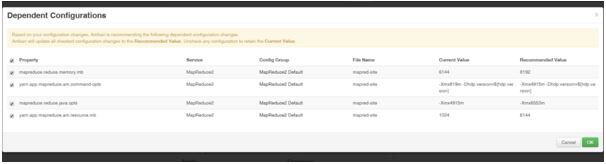
再起動方法については少し改善できないかと思いました。設定変更を反映するために、ノードをリスタートする必要がありますが、各ホスト毎のリスタートか、各サービスに関係しているコンポーネント毎にリスタートする方法しか現状ではありません。すでに、ある程度まとめたリスタート方法が実装されていますが、もう一歩進んでリスタートが必要なもの全てをリスタートするというオプションがあったらノード数がかなり多いときに便利だと思います。楽をしすぎか
ホスト画面
サービス画面
すべてのリスタートを完了し、再実行しましたがまたFailしていました。そこでR環境内で設定をいじってみることにしました。
>help(hadoop.settings) #を読むとrmr.optionsでメモリ量を変えられるらしい。 #現状況チェック rmr.options(“backend.parameters”)
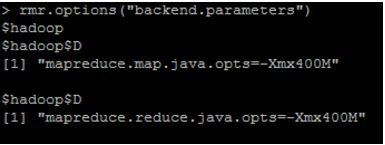
上図を見るとAmbari経由でserviceのmapReduce2のconfigでmemoryを6GBに調整しましたが、反映されていない模様です。
そこでR環境内でJavaメモリ設定を行います。
#パラメータ変数作成 >bp = rmr.options(“backend.parameters”) #パラメータ変数変更 >bp$hadoop[1] = “mapreduce.map.java.opts=-Xmx4092M” >bp$hadoop[2] = “mapreduce.reduce.java.opts=-Xmx4092M” # >rmr.options(backend.parameters=bp)
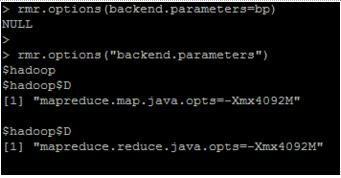
設定が変更されたところで再挑戦します。
> groups = to.dfs(rbinom(32, n = 50, prob = 0.4)) 16/02/17 09:02:10 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library 16/02/17 09:02:10 INFO compress.CodecPool: Got brand-new compressor [.deflate] > from.dfs(mapreduce(input = groups, map = function(., v) keyval(v, 1), reduce = function(k, vv) keyval(k, length(vv)))) packageJobJar: [] [/usr/hdp/2.2.9.1-1/hadoop-mapreduce/hadoop-streaming-2.6.0.2.2.9.1-1.jar] /tmp/streamjob9130136134571085855.jar tmpDir=null 16/02/17 09:04:37 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/ 16/02/17 09:04:38 INFO impl.TimelineClientImpl: Timeline service address: http://hn0-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8188/ws/v1/timeline/ 16/02/17 09:04:38 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2 16/02/17 09:04:40 INFO mapred.FileInputFormat: Total input paths to process : 1 16/02/17 09:04:40 INFO mapreduce.JobSubmitter: number of splits:2 16/02/17 09:04:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1455692794185_0003 16/02/17 09:04:41 INFO impl.YarnClientImpl: Submitted application application_1455692794185_0003 16/02/17 09:04:41 INFO mapreduce.Job: The url to track the job: http://hn1-ryuou.bk4ryjujw10u3g3wen2ztys0zf.lx.internal.cloudapp.net:8088/proxy/application_1455692794185_0003/ 16/02/17 09:04:41 INFO mapreduce.Job: Running job: job_1455692794185_0003 16/02/17 09:04:51 INFO mapreduce.Job: Job job_1455692794185_0003 running in uber mode : false 16/02/17 09:04:51 INFO mapreduce.Job: map 0% reduce 0% 16/02/17 09:04:59 INFO mapreduce.Job: map 100% reduce 0% 16/02/17 09:05:06 INFO mapreduce.Job: map 100% reduce 100% 16/02/17 09:05:08 INFO mapreduce.Job: Job job_1455692794185_0003 completed successfully 16/02/17 09:05:08 INFO mapreduce.Job: Counters: 50 ……………………………………………………………… 16/02/17 09:05:08 INFO streaming.StreamJob: Output directory: /tmp/fileb10c6b3a1afb 16/02/17 09:05:16 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 360 minutes, Emptier interval = 0 minutes. Moved: 'wasb://ryuou@akibaline.blob.core.windows.net/tmp/fileb10c5b8b52eb' to trash at: wasb://ryuou@akibaline.blob.core.windows.net/user/watanabe/.Trash/Current $key [1] 5 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $val [1] 1 1 1 4 4 4 7 7 7 4 4 2 2 1 1
見事に流れてくれました!
このRの検証の公式版はこちらです。
ここまでの感想
Rのmapreduceジョブは独自の設定ファイルを参照していると思われます。Ambariで設定を変えられる方法があるのか、または設定を連携させることができるのかが不透明です。ともあれAmabri上でconfigを直感的に変えられるので、変更が追跡できるのはありがたいです。
ビッグデータをRでも処理できるようにHadoopを経由するとロジックは同じだが環境に合わせたプログラミングが必要になります。
次回はGiraphをHadoopで動かしてみます!



