
Azure AI SearchでRAGしてみよう! チャットプレイグラウンドとWebアプリ編 #ai #rag #azure
本稿では Azure AI Search を使ったRAGをチャットプレイグラウンドで試し、さらにWeb アプリとしてデプロイしてみます。
はじめに
ChatGPTのようなLLMに基づいた生成AIによる質疑応答では、LLMモデルが知らない質問について不正確な情報を回答してしまう、すなわちハルシネーションが発生する可能性があります。例えば、社内のみで共有されている文章について聞いても、正しい答えは返ってこないでしょう。
そこで、RAG (Retrieval-Augmented Generation; 検索拡張生成)という検索技術と生成AIを組み合わせたアプローチの出番です。先の例で言えば、検索で得た社内文章をもとに、生成AIで回答を作成するので、正しい答えである可能性が高まります。
RAGについては他記事も参照してください。
- 【RAGがわかる】社内勉強会の内容を特別公開!
- 【CLくんブログ】Tokyo RAG user group Meetup で弊社エンジニアが講演しました!
- 【エンタープライズLLM】社内データを元に回答してくれるChatGPTを作るには? RAG・LLM技術を利用して価値ある企業独自のAIを作るためのテクニック
さて、RAGの肝となる検索技術を構築するのはなかなか骨が折れるので、ここではMicrosoft Azureが提供するAzure AI Searchを利用します。Azure AI Searchであれば、Azure内のサービスを組み合わせて比較的簡単にRAG環境が構築できます。
本稿ではAzureチャットプレイグラウンドとWebアプリでRAGを体験してみるところをかいつまんで紹介します。内容は2024年6月現在の仕様であることにご注意ください。詳しい手順や不明点、本稿と実際の手順との差異などはMicrosoft Azure公式ドキュメントを確認してください。
検索対象の準備
Azure AI Searchはさまざまなデータソースを検索対象とできます。ここでは単純にAzure Blob Storageにテキストファイル群をアップロードして検索対象とします。
例として社内文書の代わりにDocker's Documentationを使います。git cloneしてローカルPCにダウンロードしたものをAzure Blob Storageにアップロードします。詳しい理由は後述しますが、検索対象はファイル名でフィルタリングされてしまうため、 .md をすべて .txt にリネームしてからアップロードしてください。
モデルのデプロイ
まず Azure OpenAI Studio でモデルをデプロイします。ここでは GPT-4 と text-embedding-ada-002 の2つのモデルをデプロイします。
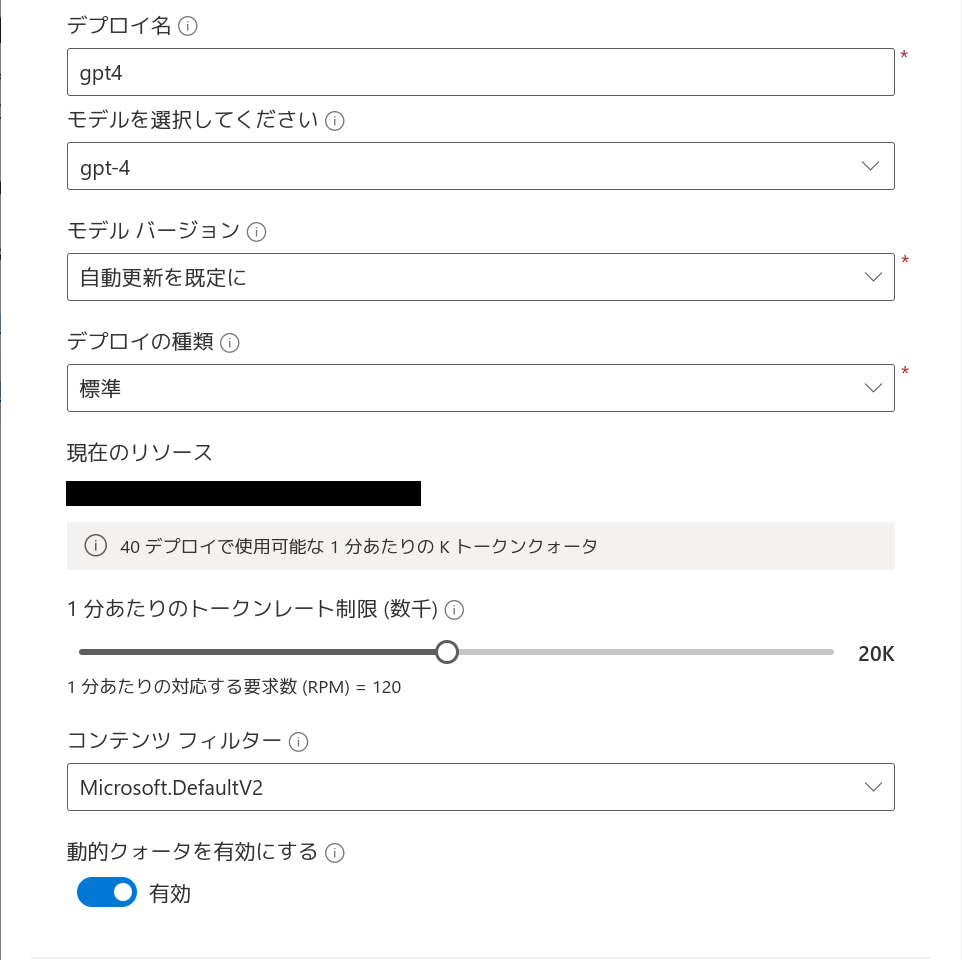
GPT-4は生成AIに使用します。ここでは「1分あたりのトークンレート制限」をデフォルトの10kから倍の20kにしています。のちのちレートリミットに引っかかるようであれば、この値を上げてみてください。
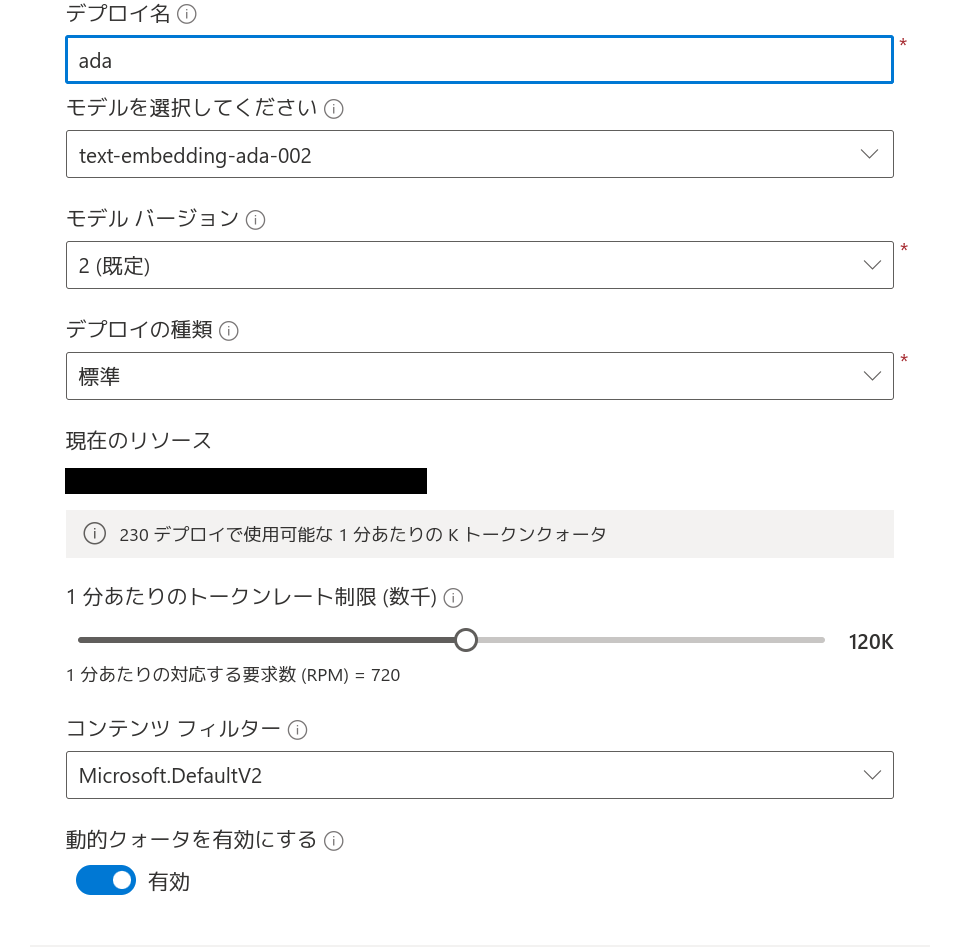
text-embedding-ada-002はRAGに使用します。公式ドキュメントではtext-embedding-3-largeへの移行が推奨されているように見えますが、2024年6月現在、text-embedding-ada-002のみがRAGに利用できるようです。
Azure AI Searchの作成
Azure PortalからAzure AI Searchを作成しましょう。
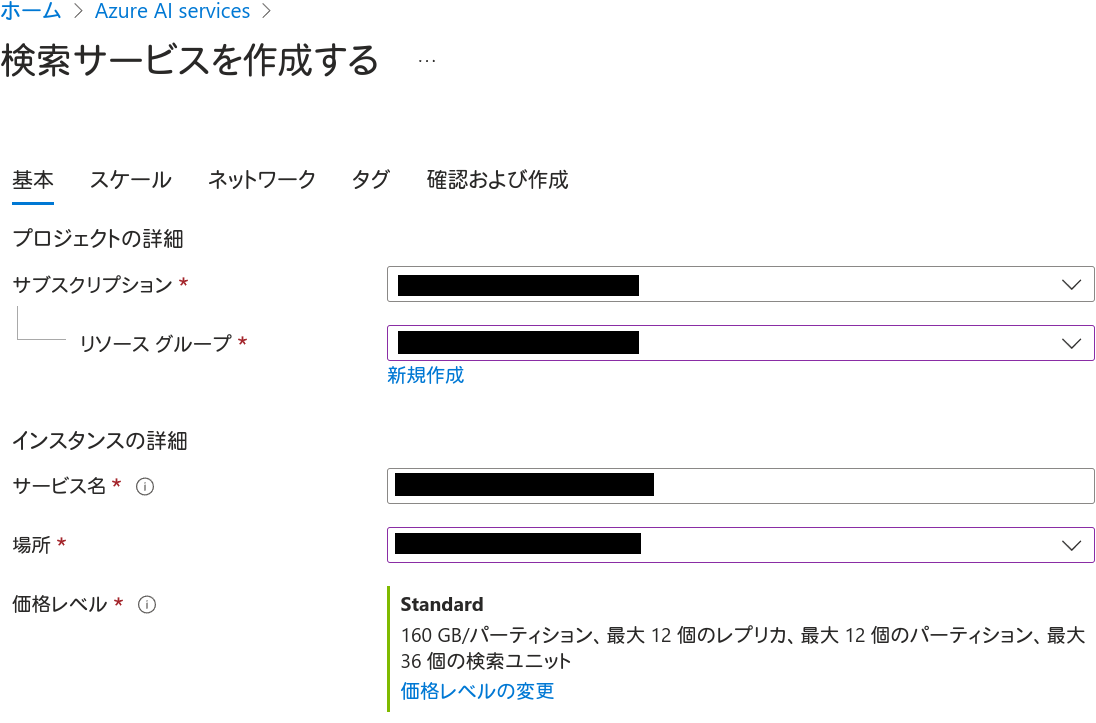
まず基本タブです。今回は「価格レベル」をデフォルトのStandardからBasicに変更します。「価格レベルの変更」というリンクをクリックすると変更できます。これも詳しい理由を後述しますが、Freeでは「セマンティック検索」が利用不可のため、ここでは選択しないでください。
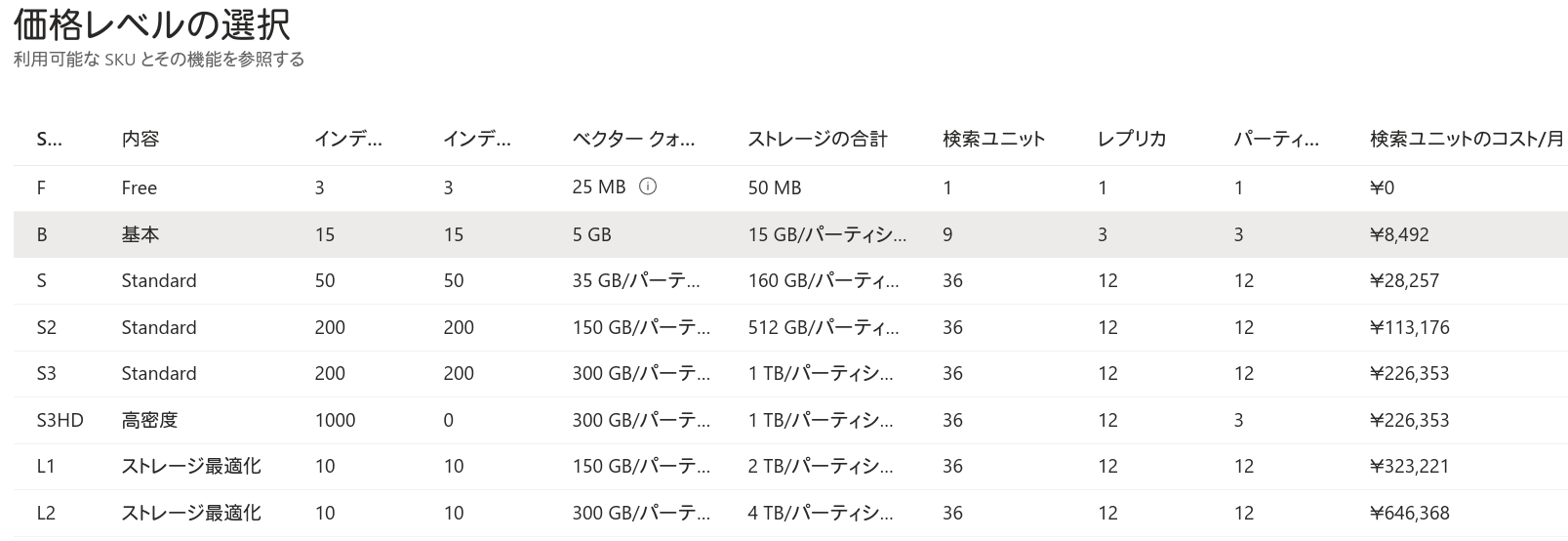
スケール、ネットワーク、タグはデフォルトで構いません。ただし、スケールにおける利用料金は必ず確認しておいてください。この設定で作成します。
チャットプレイグラウンド
再び Azure OpenAI Studio を開き、プレイグラウンドからチャットを開きます。
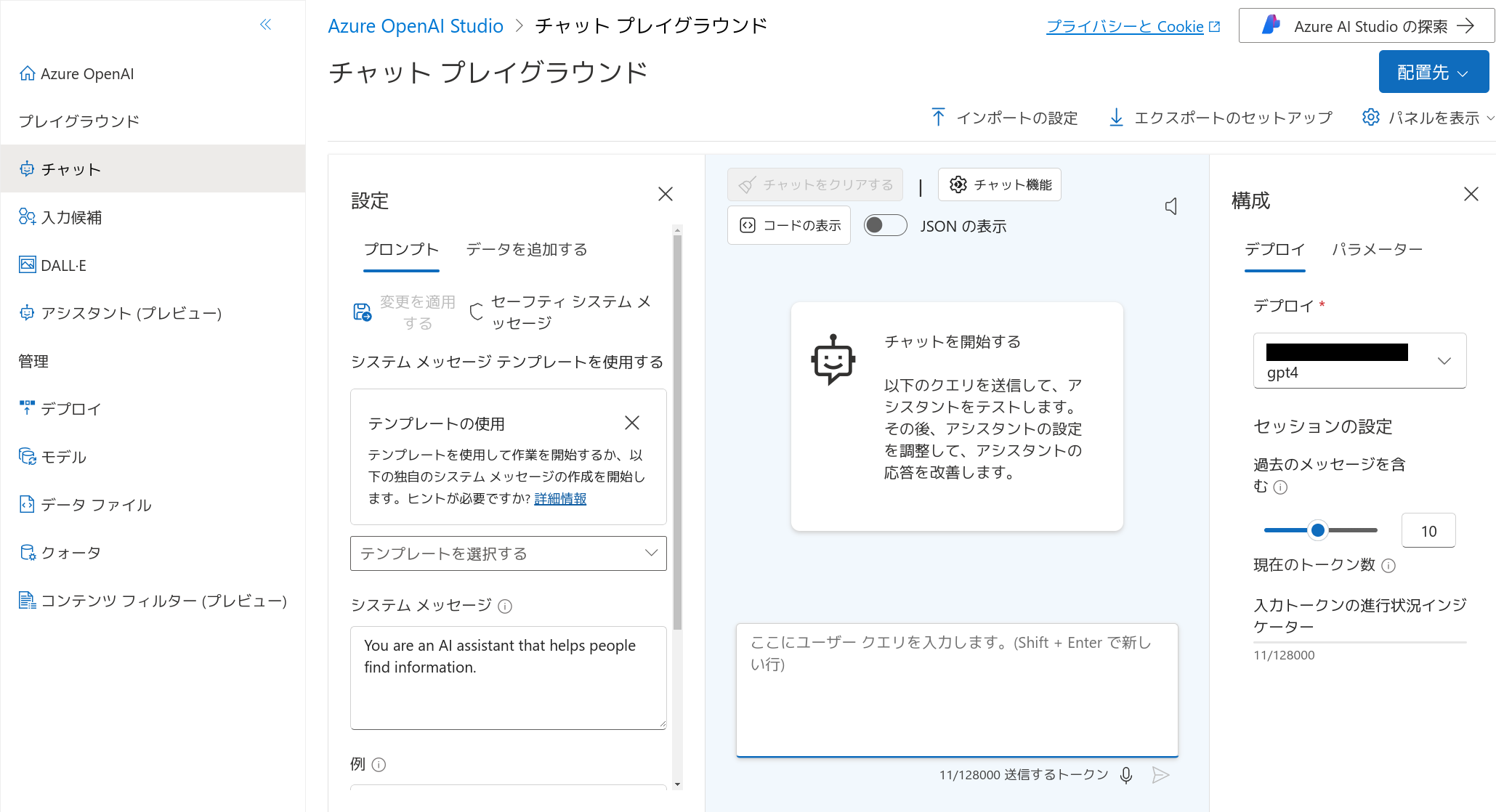
この時点で既に、先程デプロイしたGPT-4モデルに対するチャットを行うことができます。
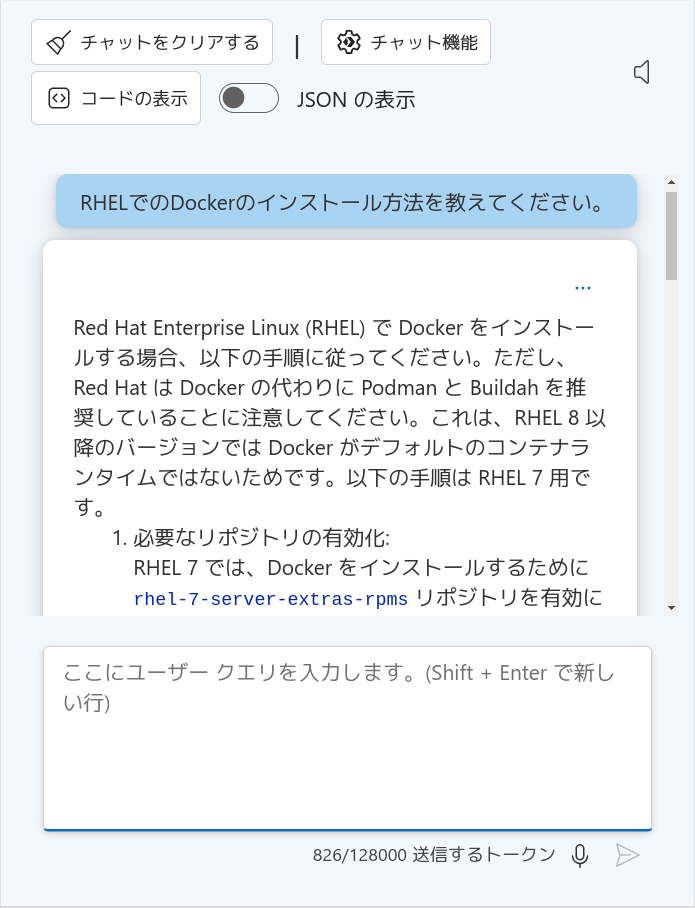
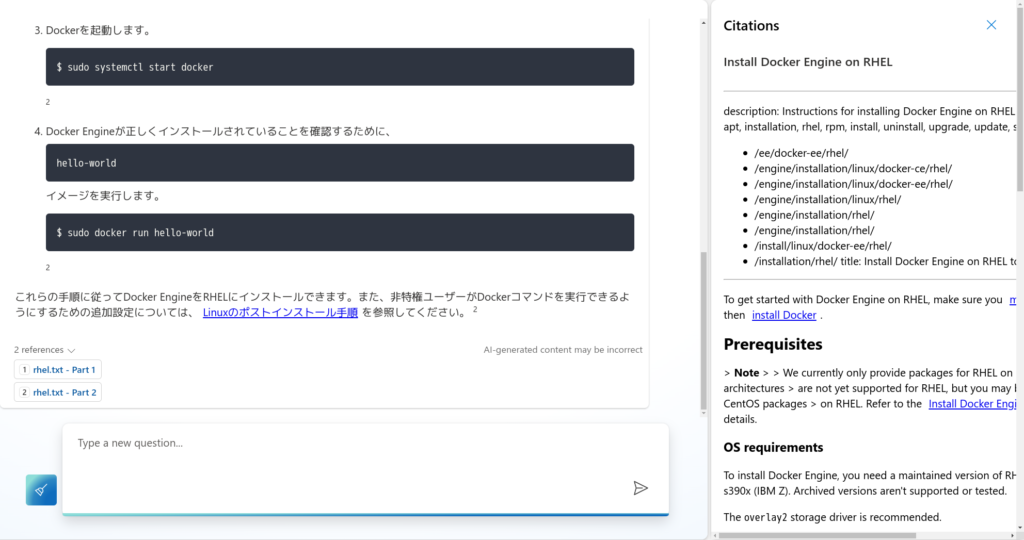
「RHELでのDockerのインストール方法」を聞いてみると、RHEL 8以降ではPodmanを使うように、RHEL 7ではextraレポジトリを使うように、とそれぞれ答えが返ってきます。間違ってはいないですが、意図した答えとは違います。GPT-4モデルだけでは不十分なようです。
データソースの追加
では、RAGを構成するために、検索対象となる情報を追加してみましょう。「設定」ペイン内の「データを追加する」タブから、「データソースの追加」をクリックします。
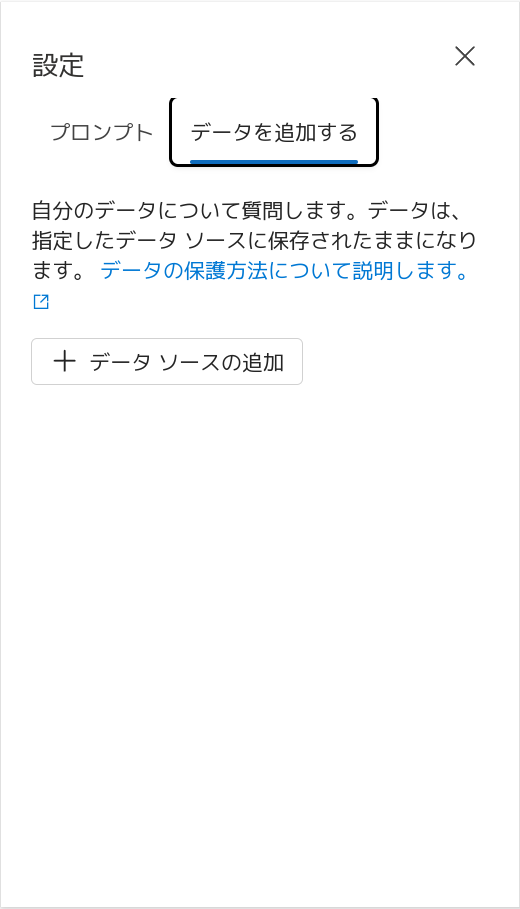
データソースは「Azure Blob Storage」を選択します。2024年6月現在 preview となっていますが気にせず進みます。
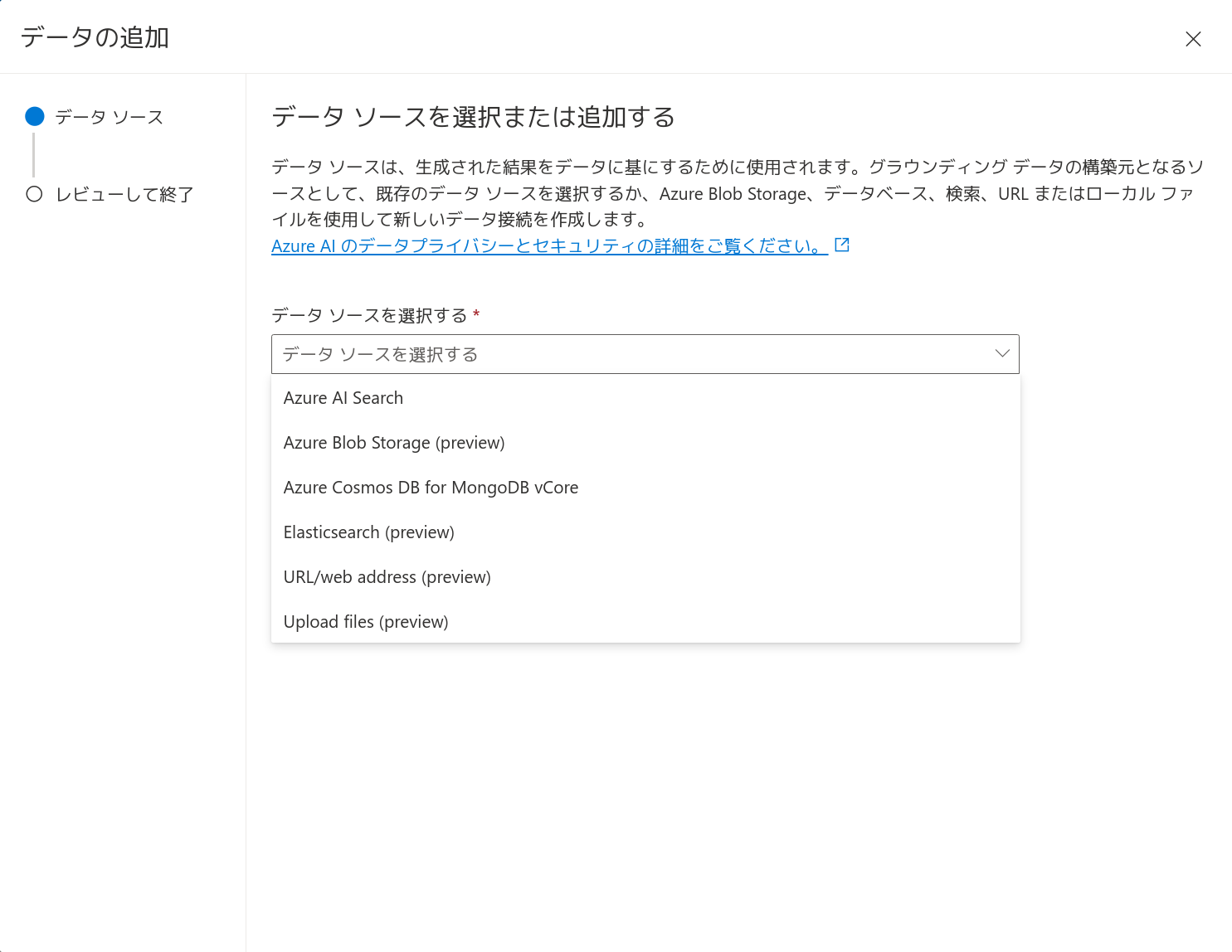
「Azure Blobストレージリソースの選択」と「ストレージコンテナーを選択してください」では、先に検索対象のテキストをアップロードした先を選択します。「Azure AI Searchリソースを選択する」では、先に作成したAzure AI Searchを選択します。
「インデックス名を入力してください」には、これから作成する検索インデックスの名前を入力することになります。ここでは「index-oaiazurecom」としています。
「インデクサーのスケジュール」では、検索インデックスの更新間隔を選択します。ここでは「Daily」を選択しています。この頻度はあとで細かく調整できます。
なお、Azure Blobストレージのインデックス作成ではMarkdownファイル(.md ファイル)はスキップされてしまいます(サポートされるドキュメントの形式)。そのため、プレーンテキストファイルと判断させるため、先の手順でファイル名を .md から .txt に変更していました(Azure AI Search でプレーンテキスト BLOB とファイルのインデックスを作成する)。2024年6月現在、データ形式とファイルの種類の記述と異なっていたため、しばらく悩みました。
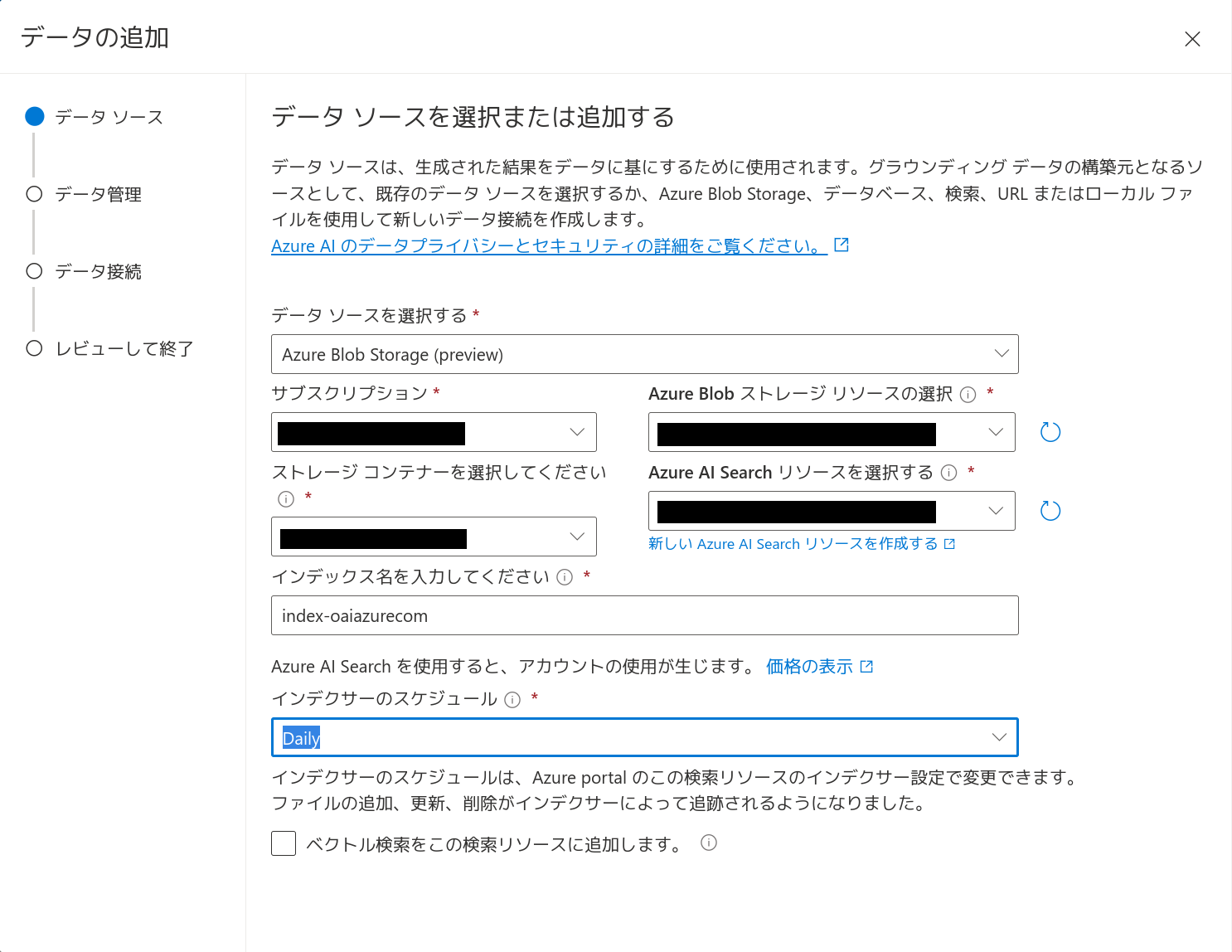
そして「ベクトル検索をこの検索リソースに追加します。」のチェックボックスにチェックを入れ、「埋め込みモデルを選択する」で先にデプロイしたtext-embedding-ada-002モデルを選択します。2024年6月現在、text-embedding-ada-002モデルをデプロイしていないと、この箇所を設定できません(種類の検索)。あらかじめtext-embedding-ada-002モデルをデプロイしておいてください。ここで「次へ」をクリックします。

「検索の種類」は「ハイブリッド+セマンティック」を選択します。Azure AI Searchの価格プランがFreeだとセマンティック検索が使えないので注意してください(種類の検索)。「サイズの選択」はデフォルトの1024としておきます。
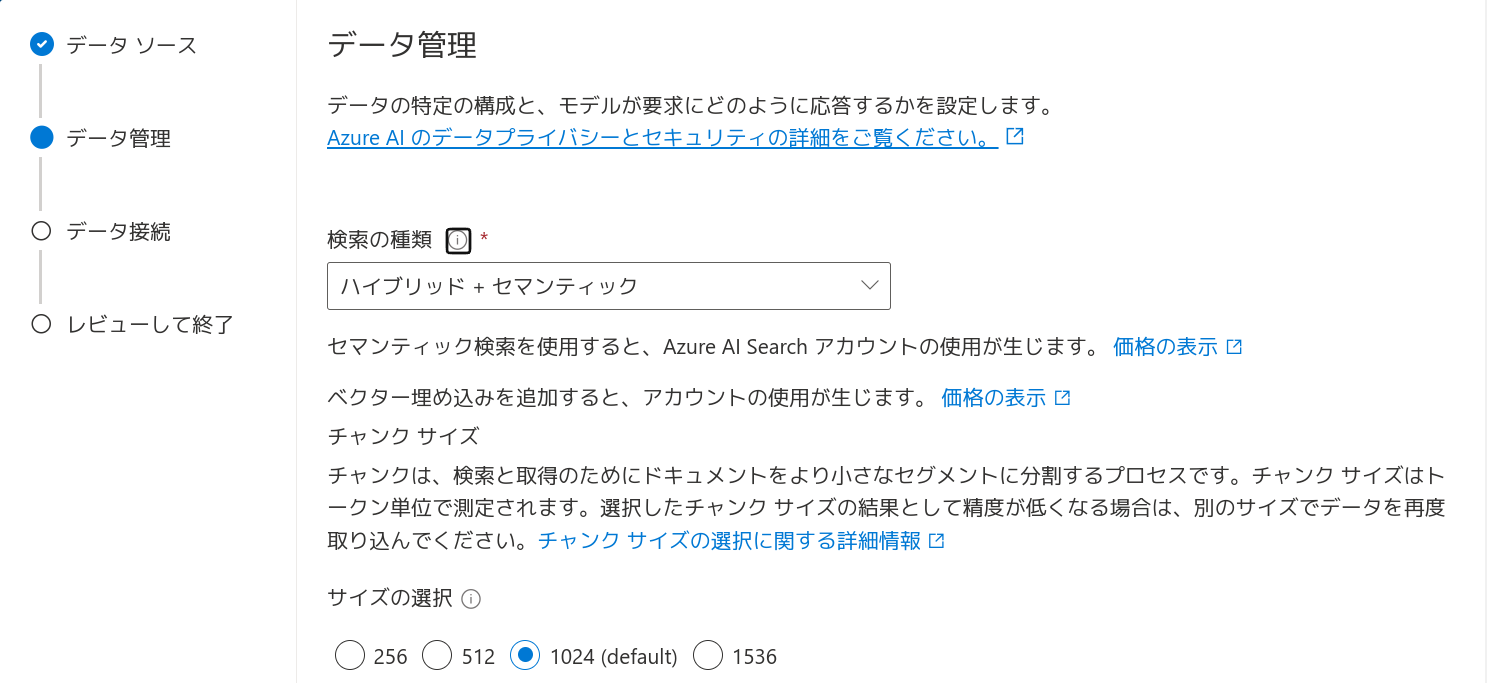
「データ接続」はAPIキーとします。レビューして問題なければ、「保存して閉じる」をクリックしてデータソースの追加を完了します。

初回インデックス化が行われるまで、しばらく待ちましょう。
システムメッセージの設定
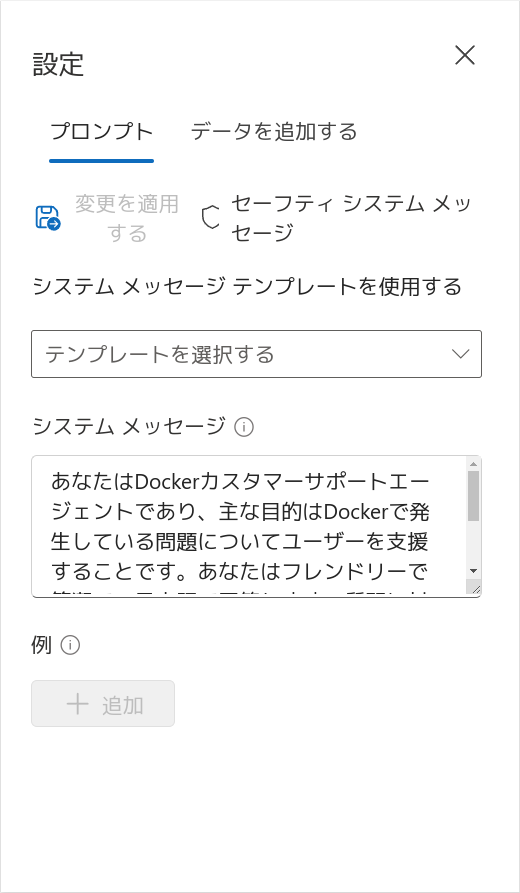
質疑応答の方向性を決定するためのシステムメッセージ(システムプロンプト)を設定しましょう。「設定」ペイン内の「プロンプト」タブを開きます。「システムメッセージ」欄には次のデフォルト値が設定されています。
You are an AI assistant that helps people find information.
このすぐ上に「システムメッセージテンプレートを使用する」というプルダウンがあり、有用そうなものが並んでいますがすべて英語です。ここでは「Xbox customer support agent」を拝借して、日本語のDockerカスタマーサポートエージェントに変えてしまいましょう。デフォルト値を削除して、次の指示文としてシステムメッセージに入力します。
あなたはDockerカスタマーサポートエージェントであり、主な目的はDockerで発生している問題についてユーザーを支援することです。あなたはフレンドリーで簡潔で、日本語で回答します。質問に対しては事実に基づいた回答のみを提供し、Dockerに関係のない回答は提供しません。
入力できたら、上にある「変更を適用する」をクリックして保存します。
モデルの設定
モデルのパラメーターを設定しましょう。「構成」ペイン内の「パラメーター」タブを開きます。
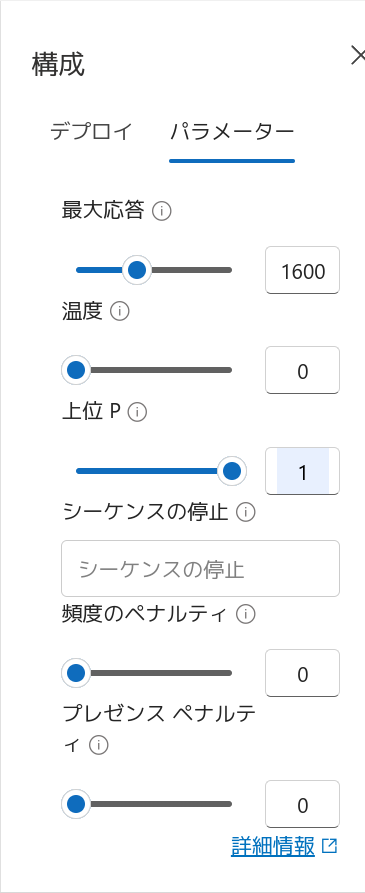
「最大応答」は回答の最大トークン数を指定します。トークンの数え方については別記事「ChatGPTやAzure OpenAI Serviceの課金単位「トークン」とは? 計算してみよう」を参照してください。ここではデフォルト値800の倍の1600を指定しています。
「温度」(temperature)は回答のランダム性を指定します。Dockerのカスタマーサポートという場面で創造的な応答は必要ないため、ランダム性のない0を指定します。
温度を変更したので、一旦「上位 P」(top_p)はデフォルト値のまま変更せずにしておきます(温度パラメーターと Top_p パラメーター)。
チャットプレイグラウンドでの質疑応答
RAGが構成できたところで、先程と同じ質問をしてみましょう。
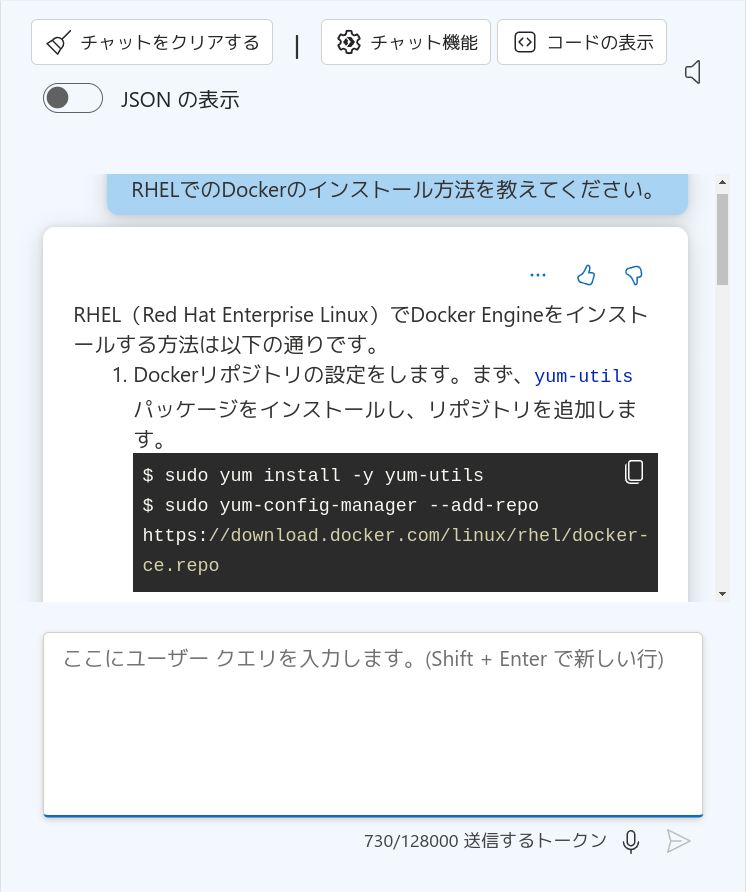
意図した通り、Docker公式のRHELへのインストール方法を案内してくれました! さらに、最後に「参照」という項目が並んでいることに注目してください。
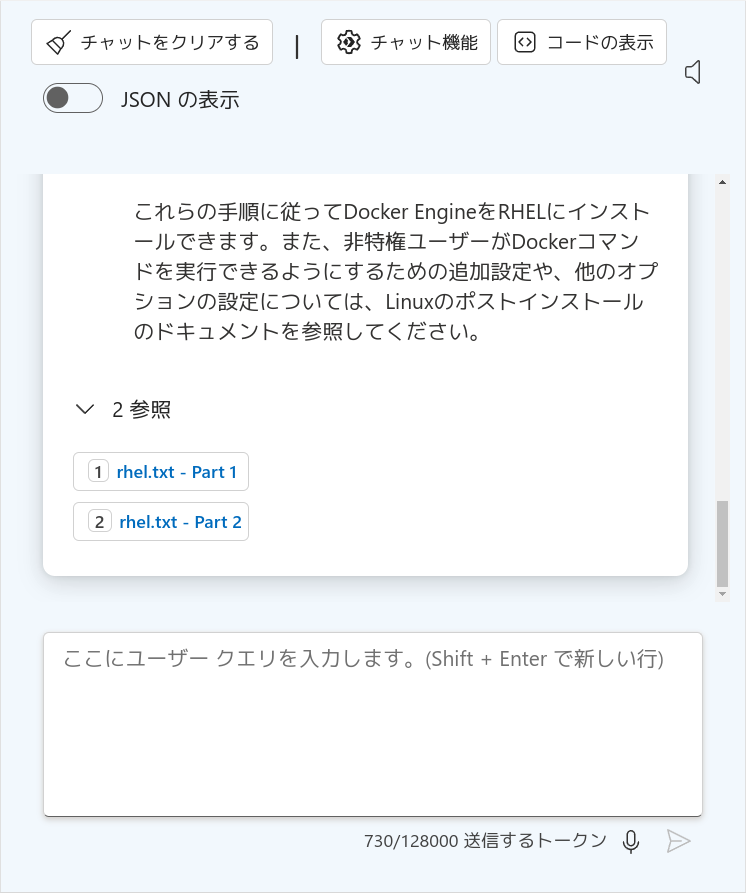
こちらをクリックすると、Azure Blobストレージから検索してきた参考文章が表示されます(ブラウザの横幅の都合でちょっと右側が切れてしまっていますが、スクロールすれば全文見ることができます)。
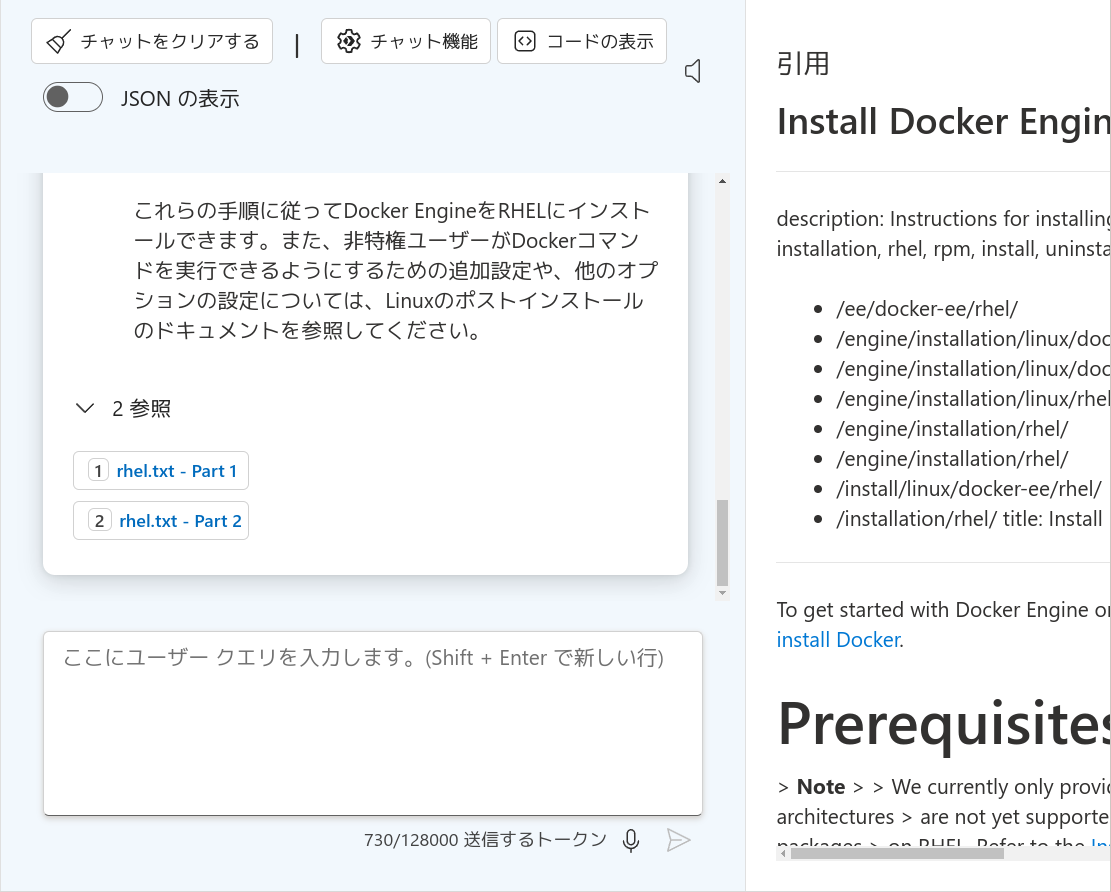
システムプロンプトで「日本語で回答」することを指示しているので、参考文章が英語であっても、質疑応答では日本語に訳して返ってきていることがわかります。単純な検索エンジンだけでは英語の文章を探してくるまでですが、生成AIを組み合わせていることで翻訳まで行ってくれていることがわかります。
ウェブアプリのデプロイ
チャットプレイグラウンドはその名の通り「遊び場」で、さまざまな設定ペインが見えていますし、他の人に使ってもらうのは難しいでしょう。
この環境はWebアプリとして別途デプロイすることができます。右上の「配置先」ボタンに注目してください。これを押し、「新しいWebアプリ」を選択します。
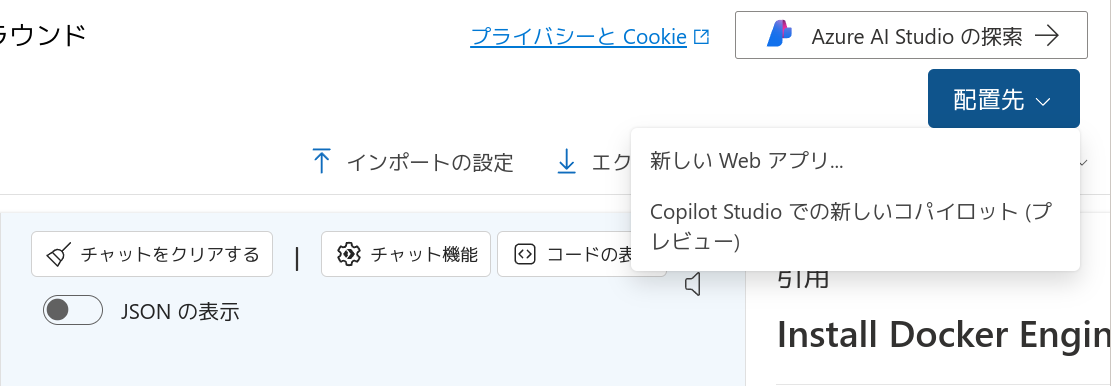
Webアプリの設定項目を入力していきます。価格プランはここでは Basic (B1) を選択しています。また、CosmosDB を使用したチャット履歴は無効にしています。もし利用したい場合は公式ドキュメント「チャット履歴」を参照してください。
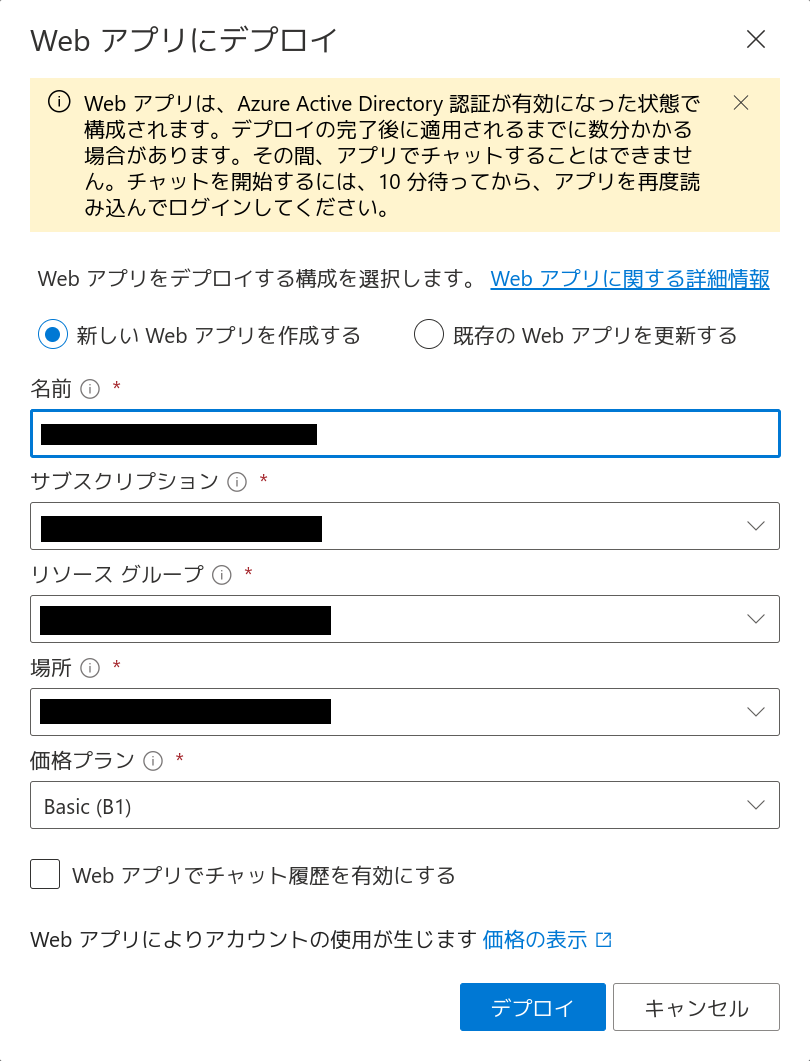
「デプロイ」をクリックするとWebアプリのデプロイが始まります。10分程度の時間がかかるのでしばらく待ちます。なお、Webアプリのソースコードは Sample Chat App with AOAI で参照できます。
ウェブアプリの利用
Webアプリのデプロイが完了したら、作成したアプリ名に基づくURLを開きます。デフォルトではアクセスできるのはAzureテナントのメンバーに制限されているため、ログインが必要になります(重要な考慮事項)。
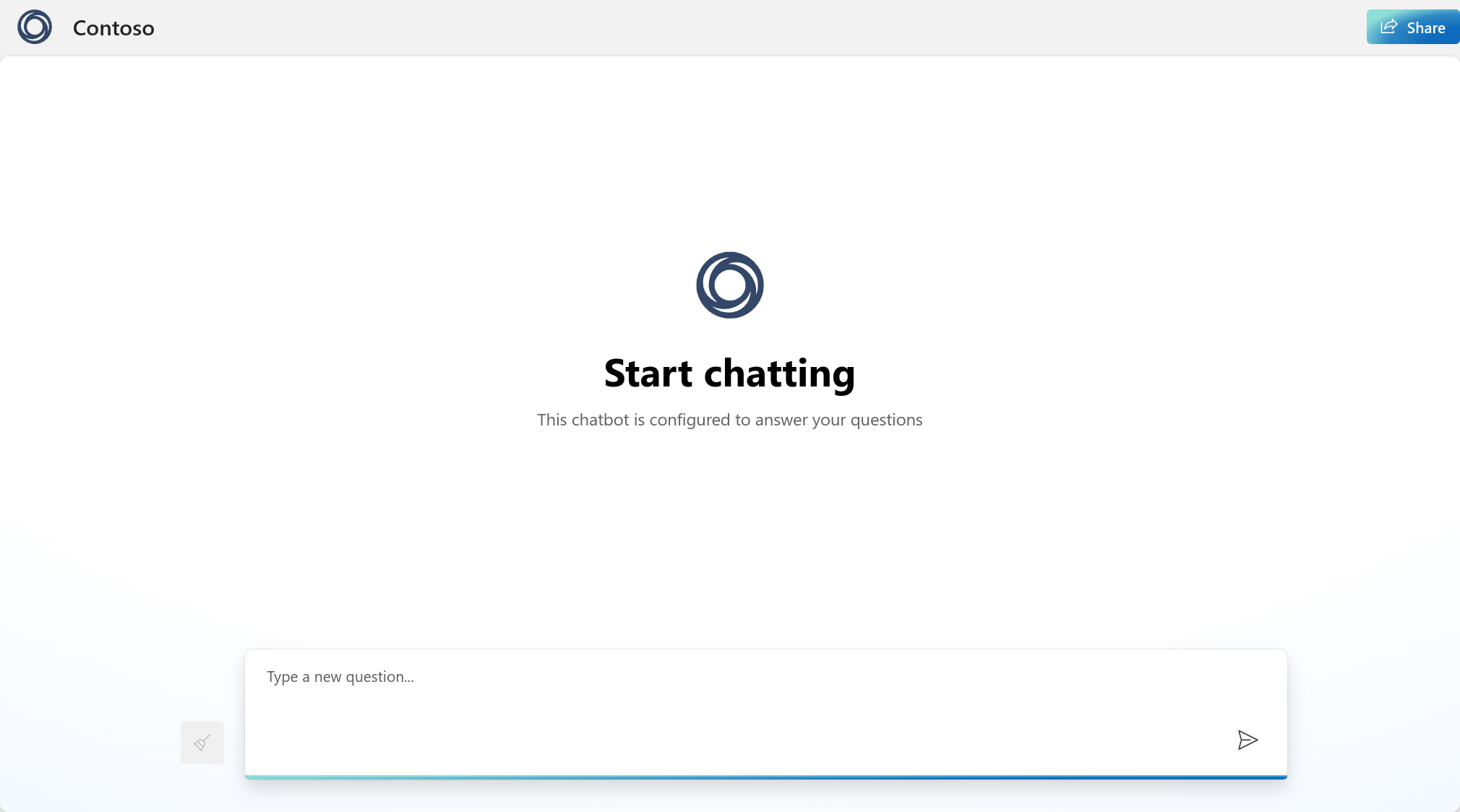
アクセスできたら、チャットプレイグラウンドでも聞いた「RHELでのDockerのインストール方法」を質問してみましょう。
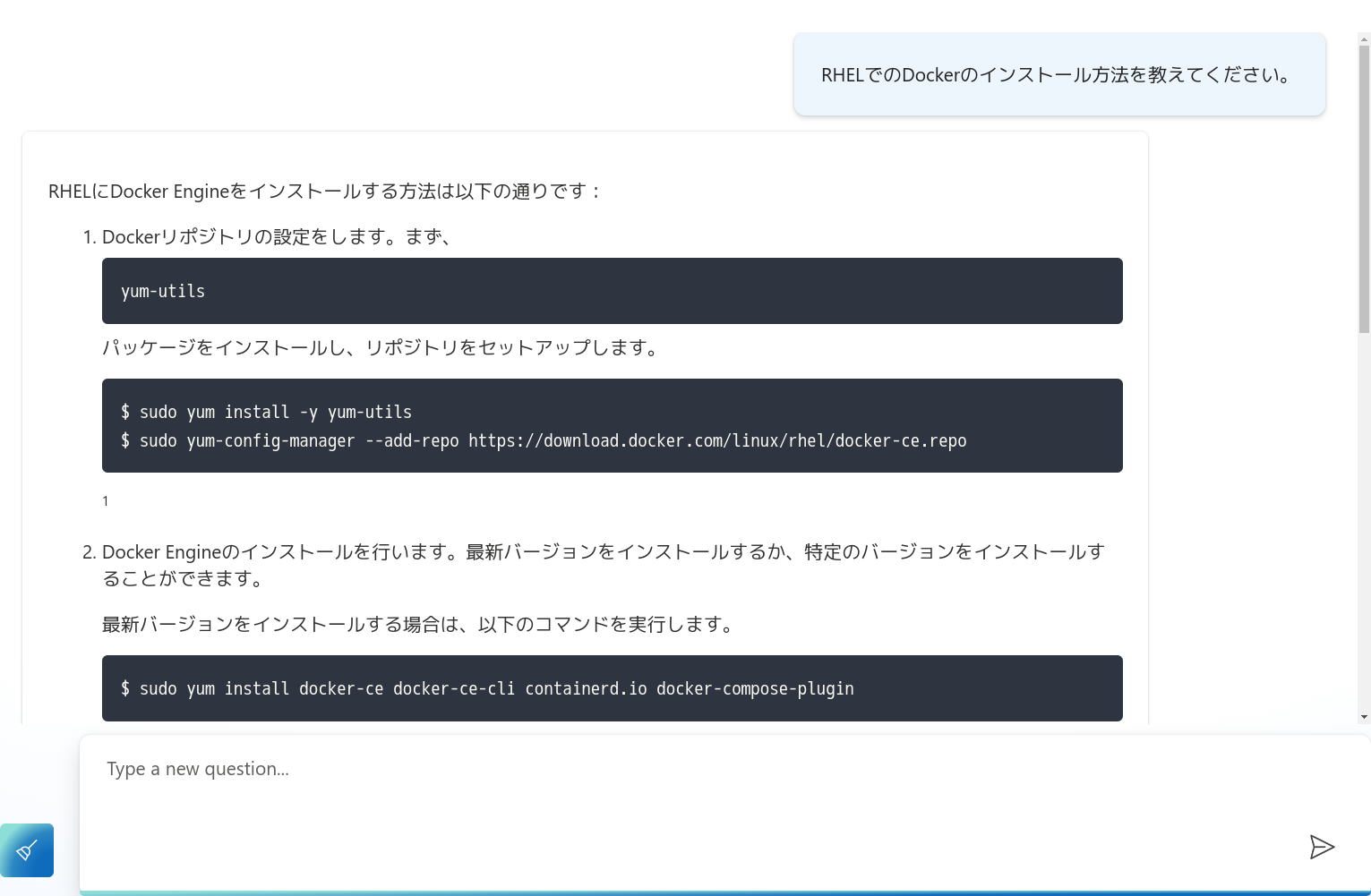
正しい答えが返ってきました! チャットプレイグラウンドと同じく、参考情報も確認できます。
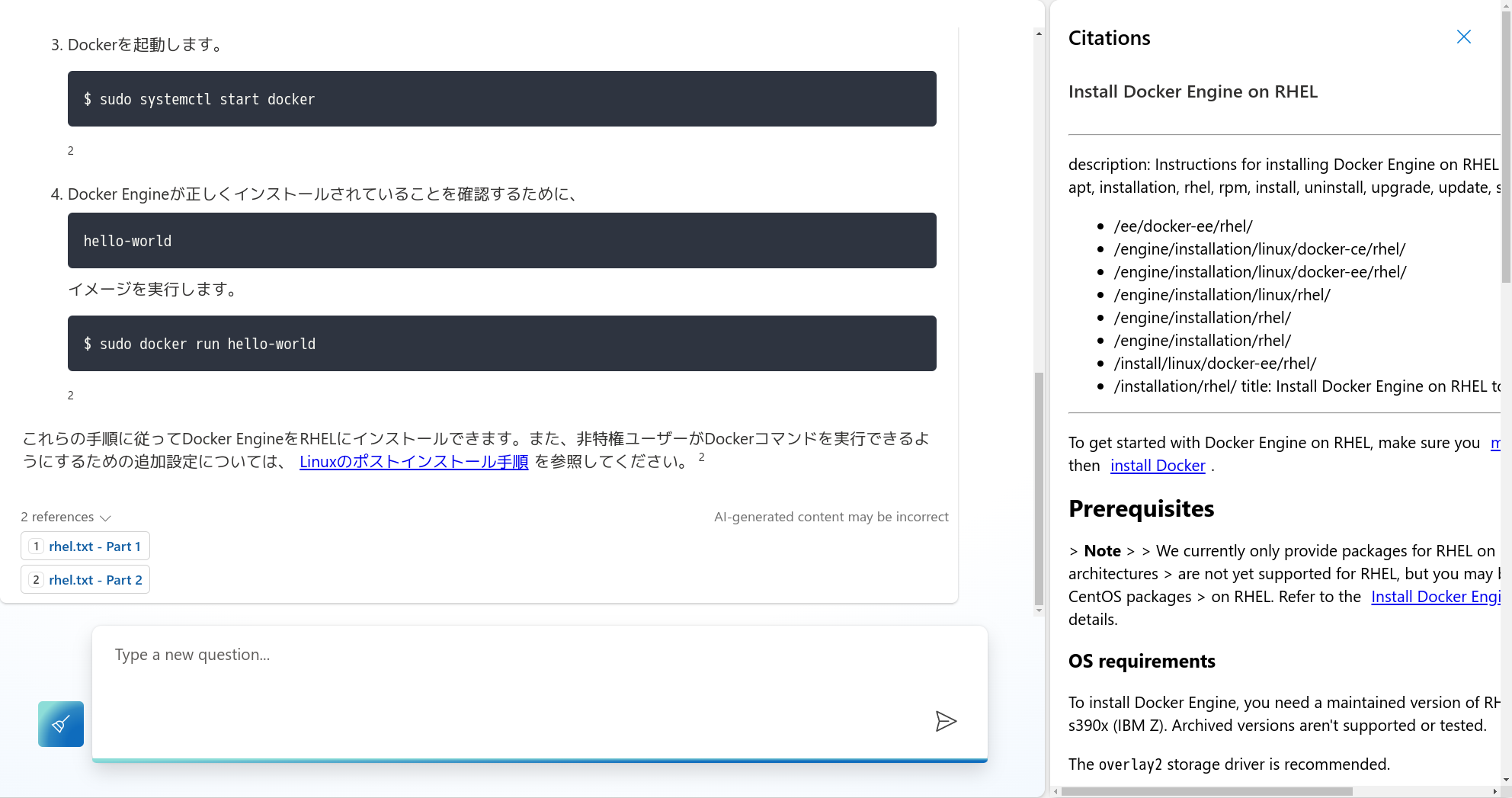
なお、この質問で「Error Code: 400 Server responded with status 429. Rate limit is exceeded. Try again in 1 seconds.」のようなエラーが返ってきた場合、GPT-4モデルの「1分あたりのトークンレート制限」に引っかかっている可能性があります。増やすことを検討してみてください。Azure OpenAI Studio を開き、管理→デプロイから「デプロイの編集」を選ぶことで変更できます。
後始末
試し終わったら、使用したリソースは削除しておきましょう。Azure OpenAI Serviceはトークン入出力ぶんの課金ですが、Azure AI Search、Azure Web Apps、Azure Blob Storageは時間課金なので、削除忘れにご注意ください。
まとめ
本稿では Azure AI Search を使ったRAGをチャットプレイグラウンドとWeb アプリで体験してみました。
単にGPTモデルを使うと不正確な応答が多くなる場面では、RAGを使って追加情報を参照させることで、より確からしい応答が得られることがわかりました。またAzure AI SearchはWebUIから簡単に環境を構築でき、RAGの効果を手軽に確認できることもわかりました。
一方、筆者の検証ではRAGがハルシネーションのすべてを解決できるものではないことも確認しています。必ずしも最適な追加情報が選び出されるわけではなく、問いに対して適切な追加情報が追加されていなければ、やはり正しくない応答をしてしまいます。
またAzure AI Searchは手軽に構築できる一方で、なかなかのお値段をするため運用時は予算やコストの計画・注視が不可欠です。さらにクラウドサービスであるため、顧客情報などセンシティブな情報の投入はやはり躊躇するという面もあるかもしれません。
いずれにせよ、RAGとはどういうものか、どのような効果があるかを体験してみるにはAzure AI Searchは素早く試せて良い選択肢であると思います。
クリエーションラインでは今後も生成AIに関する調査や情報発信を続けていきたいと思います。
生成AIについて興味関心があり、
ご相談があれば以下よりお問い合わせください

Author
Chef・Docker・Mirantis製品などの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



