
【エンタープライズLLM】社内データを元に回答してくれるChatGPTを作るには? RAG・LLM技術を利用して価値ある企業独自のAIを作るためのテクニック #chatgpt #rag #enterprise-llm

はじめに
ChatGPTに代表されるLLMの登場と進化により多くの企業がAI・LLMを活用したサービス開発と業務効率改善に向けての意欲が高まってきています。このような中、生成AIを利用して企業独自のAI・LLMを作ることが非常に着目されています。
企業としてはAI・LLMに自社独自のノウハウを学習させ、業務の効率化に役立つソリューション・システムを作りたいという、業務の効率化観点でのモチベーションは当然発生します。また企業独自のノウハウを入れたAIアプリケーションやシステムをプロダクト・サービスとして提供、あるいはすでにある自社サービスに機能追加することで、サービスの付加価値の追加、顧客への価値提供の向上、企業価値を向上させたい狙いも発生します。
一方で、ChatGPTに代表されるサービスとして広く提供されているLLMは、インターネットで公開されているデータ(世界知識)を元に学習しています。このため企業内部の情報を元に答えることはできません。加えて、精度の高いLLMモデルを作成するには膨大な計算量が必要のため、学習データも最新よりも少し遅れた内容になってしまいます。
このため、AI・LLMに企業独自のノウハウを学習させ、業務の効率化に役立つソリューションを作るには、別のアプローチが必要になります。独自のノウハウを学習させるにはLLMモデルに対する追加学習という方法もありますが、「検索強化生成(RAG:Retrieval-Augmented Generation)」(以降はRAGと記載)が非常に有効です。本記事ではRAGを利用する場合の流れとポイントについて述べていきます。
検索強化生成(RAG:Retrieval-Augmented Generation)とは?
検索強化生成(RAG:Retrieval-Augmented Generation)は、LLMへの問い合わせの際に独自データベースを検索することにより、独自の知識を取り出し、その知識を質問(Query)に付加した形でLLMに問い合わせを行います。
以下は企業の社内情報を元に回答するAIチャットシステムのRAGアーキテクチャーの一例です。チャットを利用して社内情報やさまざまなナレッジを活用し、エンドユーザーへのサポート業務などを支援する基盤として利用することができます。
企業の社内情報を元に回答するAIチャットシステムのRAGアーキテクチャ
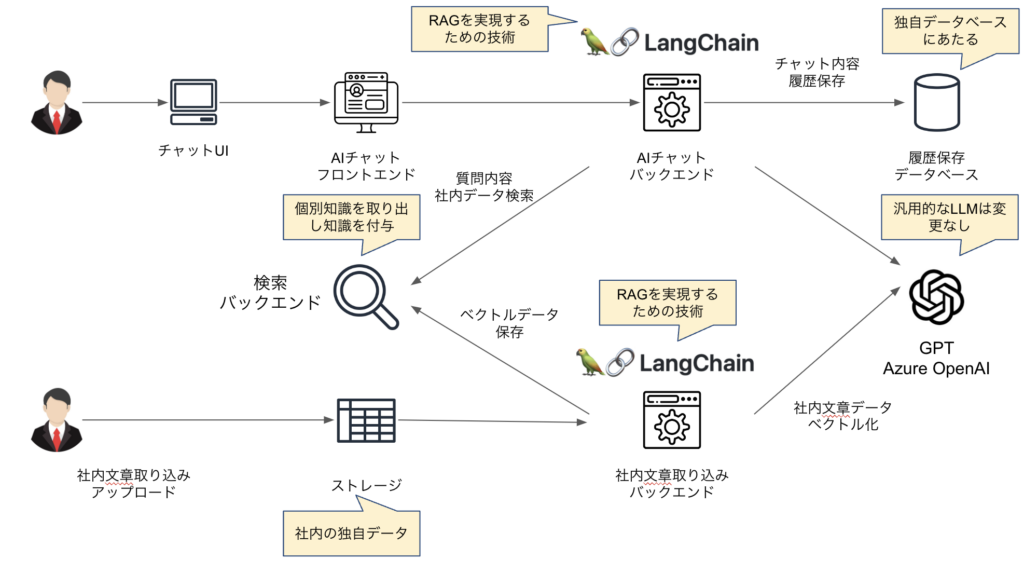
※上図で出てくるLangChainはRAGを実装するために代表的なソフトウェアの一つです。(LangChainについては別途解説する記事を作る予定です。)
RAGを利用することにより、汎用的なLLM自体は変更することなく、独自の知識を与えた上で回答を得ることができます。
RAGを実現するための技術として、オープンソース系では前述のLangChain、Llamaindex、クラウドサービスでは、Amazon Bedrock、Azure Machine Learningなどの技術・サービスが多数登場しています。また、DifyというノーコードでRAGを作成できるサービス・ツールも登場しています。このため、企業独自のAIプロダクト・サービスを作る上での技術的なハードルはどんどん低くなってきています。
一方で、RAGを利用したプロダクト・サービスの構築自体はできるものの、以下の課題が発生することが多々あります。
・RAGを作ってみたものの、それっぽい回答は出るが、本当に正解か解らない。
・作ったものが事業的に価値があるか?効果が出ているか?が解らない。
・継続的に精度をあげたり、効果をあげる方法が解らない。
実は技術的にRAGを構築することは難しくありません。一方で企業の事業にとって価値がある(有効である)独自のAIシステム・プロダクトを作っていくことは簡単ではありません。
この記事ではこのような悩みを持つ方々向けに企業にとって事業価値の高い・有効性の高いRAGを構築していくための流れを解説します。
「継続的に」精度と有効性を高める仕組みが、ソリューション・プロダクトそのもの以上に重要
前章でも触れましたが技術的にRAGを構築することは難しくありません。一方で企業の事業にとって、価値がある(有効である)独自のAIソリューション・プロダクトを作っていくことは簡単ではありません。
また、GPT4, Claude3 Ops, Mystralなどの新しいLLMのリリース、GPT-4oの登場など、LLMのベースモデルは今後も非常に早いスピードで進化していきます。またDifyの登場に代表されるようにRAGを構築するための技術やサービスも進化していきます。このような技術進化の非常に大きな波の中、RAGを利用したソリューション・プロダクトも作ってリリースして終わりではなく、日々アップデートしていくことが大前提になります。
このためAIソリューション・プロダクトを作っていく上では、AIソリューション・プロダクトをそのもの以上に「継続的に」精度、有効性を高められる プロダクト・ソリューションを作るための仕組みを作ることが非常に重要になります。
同時にRAGに与える企業独自のノウハウ・知識の設計は事業価値の高い・有効性の高いソリューション・プロダクトを作る上での根幹になります。この知識設計はユーザからのフィードバックを元に知識を追加したり、新たに知識を取得する仕組みを既存システムに追加したり、RAGの知識構造など見直し更新したり様々な試行錯誤を行う必要があります。
【RAGを利用したAIプロダクト開発の流れ(知識設計)】
「継続的に」精度・有効性を高める仕組みが、ソリューション・プロダクトそのもの以上に重要と述べましたが、具体的にはどのような仕組みが必要でしょうか? ここではRAGを利用した企業独自のAIソリューション・プロダクト開発の流れを図解して解説します。
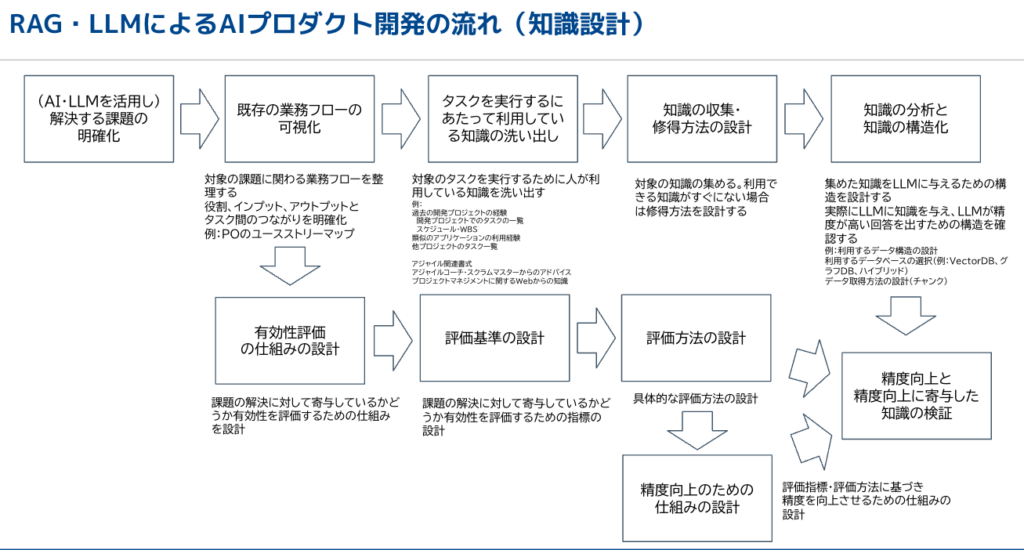
この図解は、RAG(Retrieval-Augmented Generation)とLLM(Large Language Model)を活用したAIプロダクト開発の流れを示しています。まず、AIやLLMを活用して解決する課題を明確にし、次に既存の業務フローを可視化します。これにより、対象の課題に関連する業務フローを整理し、役割やインプット、アウトプット、タスク間のつながりを明確にします。その後、タスクを実行するために利用している知識を洗い出し、知識の収集・修得方法を設計した上で、集めた知識をLLMに与えるための構造を設計し、高い回答を出すための構造を確認します。
次に、課題の解決に対して有効性を評価するための仕組みと指標を設計し、具体的な評価方法を決定します。最後に、評価指標と評価方法に基づき、精度を向上させるための仕組みを設計し、精度向上と精度向上に寄与した知識の検証を行います。
この一連のプロセスを通じて、AIプロダクトの開発を進めていくわけですが、もう少し掘り下げていきたいと思います。
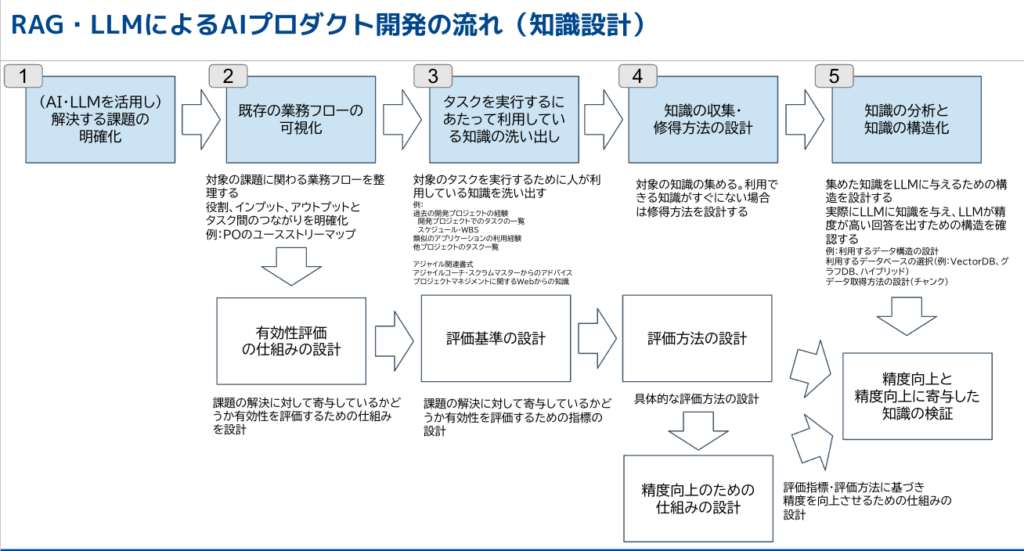
[1] AI・LLMを活用し解決する課題の明確化
プロダクト開発を始めるにあたり、まず重要なのは解決すべき課題・期待を明確にすることです。漠然と「AI・LLMを利用して業務効率化をしたい」ではなく、業務プロセスや組織内にどのような課題があり、課題の改善のためにどのような状態にすることが期待値なのかを明確にする必要があります。このフェーズは事業価値があるプロダクトを作ること、有効性評価のために極めて重要です。曖昧なままで始めると、有効性評価の設計のタイミングで迷うことになります。
また、課題により、AI・LLMを利用して解決できること(効果が高いもの)・解決できないこと(あまり効果が期待できないもの)もあります。
このあとのフェーズを進めるにあたってもAI・LLMを活用し解決する課題や期待することを明文化し、目的を明確にしておくことが非常に重要です。
[2] 既存の業務フローの可視化
AIやLLMを活用して解決する課題を明確にした後、次のステップとして既存の業務フローを可視化します。AIを用いて新たな業務フローを構築する際には、まず既存の業務フローを理解し、その上で新しい設計を行う必要があります。
可視化された業務フローを基に、課題に関連する業務フローを詳細に分析します。この分析を通じて、AIやLLMをどの業務プロセスに適用すべきか、またAIやLLMの活用によって効果が期待できるタスクを特定していきます。
[3] タスクを実行するにあたって利用している知識の洗い出し
AIやLLMを活用するには、必要な知識の整理と設計が欠かせません。このプロセスでは、対象タスクを実行するために利用されている知識を洗い出します。知識の洗い出しには、実際に該当業務を担当しているメンバーからのヒアリングが有効です。この過程で、暗黙知として利用されている知識も明らかになります。過去の経験に基づく知識も含まれており、「経験」とされるものを分解することで、使用されている知識をより詳細に洗い出すことが可能です。
以下は、プロダクトオーナーがプロダクトバックログアイテムを作成する際に利用している知識の一例です。一般に「経験」とされるものも、実は様々な知識に基づいています。この段階では、知識が取得可能か、言語化可能かにかかわらず、まずは洗い出しを行います。(知識の取得可能性や言語化可能性については、次のフェーズで詳細に検討します。)
- 認識の開発プロジェクトの経験
- 開発手法プロジェクトでのタスクの一覧
- スプリントレビューWBS
- 新規のアプリケーションの利用経験
- 他プロジェクトのタスク一覧
[4] 知識の収集・優先方法の設計
知識の洗い出しを行っても、その全ての知識やデータが入手可能であるとは限りません。入手可能なものであっても、時間がかかる場合や収集に多大な労力を要する場合があります。さらに、現時点で未収集の知識やデータも存在します。
このため、各知識について、収集の難易度を推定すると共に、その知識をRAGに加えることによってもたらされる効果を推定し、これらを基に知識の優先順位を決定する必要があります。また、利用可能な有効な知識が少ない場合には、知識の獲得方法を設計する必要があります。さらに、代替となる知識についても検討することが求められます。
[5] 知識の分析と知識の体系化
集めた知識を分析し、RAGを通じてLLMが精度の高い回答を提供するための知識構造を設計します。一般的に、RAGでは類似性検索に強いVectorDBが利用されることが多いです。知識間の関連をグラフで表現できる場合、グラフDBを利用することで精度の向上が期待できます。また、知識の内容が類似性ではなく、より厳密性を要求される場合もあります。このような状況では、リレーショナルデータベース(RDB)の利用が適切な選択肢となります。
【RAGを利用したAIプロダクト開発の流れ(評価設計)】
次に図の下の流れを見ていきます。上の流れが重要そうに見えますが、実は下の流れがRAGで有効なプロダクトを作っていくためには最も重要です。
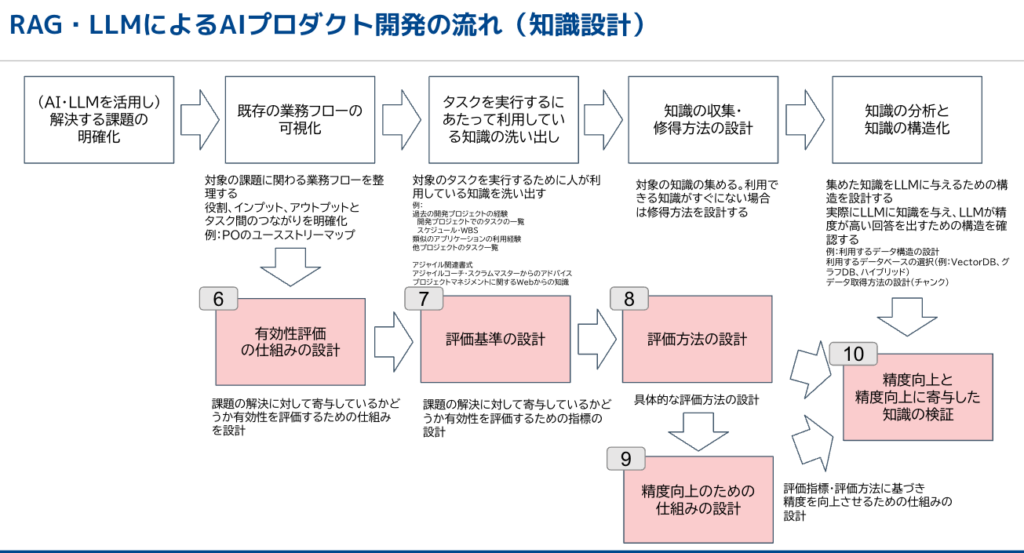
[6] 有効性評価の仕組みの設計
RAGの導入は、導入自体がゴールではなく、RAGプロダクトが課題解決に貢献している状態を目指すべきです。このためには、「RAGプロダクトは有効か?」すなわち、「課題に対して適切に機能しているか?」という観点から有効性を定義し、設計することが必要です。
また、単に「有効である」「有効でない」という二元論ではなく、「どの程度有効に機能しているか?」という観点が求められます。実際には、「有効である」という状態を定量的に評価することは難しい場合があります。例えば、サポートの回答精度を向上させたい、またはサポート応答時間を短縮したいと考えた場合でも、評価に必要な主要なメトリクス(この場合はサポート回答精度やサポート応答時間に関する指標)が計測できていなければ、その効果を正確に評価することはできません。
このような場合、有効性の定義と同時に、メトリクスの収集メカニズムも設計する必要があります。
[7] 評価基準の設計
評価基準の設計は、[6]での有効性評価とも密接に関連しています。RAGおよびLLMが生成する回答が適切であるか(有効性で定義された効果を引き出す回答であるか)を定量的に評価するための基準を設計します。例えば、前述のサポートの場合、生成されたサポート回答が文章的に正しいか、技術的に間違っていないか、必要な参考情報が付与されているか等の観点が必要になります。
これらの観点を整理した後、定量的に評価するための基準(例:回答精度の5段階評価基準)を作成します。
冒頭に述べた通り、AIソリューション・プロダクトをそのもの以上に「継続的に」精度と有効性を高められるプロダクト・ソリューションを作ることが大切です。そのためには、生成された回答の品質と精度を定量的に評価できる状態にしておく必要があります。
また、その評価基準は、[6]で示したRAGプロダクトが課題解決に貢献している状態(有効性)に即した基準である必要があります。
[8] 評価方法の設計
[7]の評価基準を設計すると共に、その評価を行うための仕組みも設計する必要があります。例えば、基準に基づいて人が評価するためには、評価のための仕組み(例:ユーザによるABテストのインターフェイス)を開発し、プロダクトの機能として組み込む必要があります。
また、利用ユーザとは別にテストユーザに評価してもらう場合には、テストユーザをどのように集めるかも評価方法の設計に含まれます。
[9] 精度向上のための仕組みの設計
有効性と精度を評価する仕組みと共に、精度を継続的に向上させるための仕組みの設計も必要です。そのためには、新しい知識をRAGに取り込む仕組みを構築することや、実際の利用者からのフィードバックを得るための機能をRAGプロダクトに組み込むことが求められます。
[10] 設問回答と設問回答に寄与した知識の検証
ここで青色の[3]〜[5]の流れと、赤色の[6]〜[9]の下の流れが合流します。[3]〜[5]の流れにより、新規の知識がRAGに追加されます。同時に、[6]〜[9]の仕組みを通じて、追加した知識がRAG+LLMにより生成される回答の精度と有効性の変化を検証することが可能になります。
[10]のフェーズでどのような知識の追加が精度および有効性に効果的なのかを体系的に把握することができます。これにより、知識設計の見直しや優先順位の変更が可能になり、より効率的に知識を収集し、プロダクトの効果を高めることができます。
この[10]のフェーズにより「継続的に」精度と有効性を高める仕組みが、完成することになります。
まとめ
今回の記事では、RAGとLLMの組み合わせによるエンタープライズLLMを作成する流れをご説明しました。RAGにより、LLMに対して個別の知識を与え、企業ごとにカスタマイズされたLLMを作ることが可能になります。
一方で、開発したLLMを有効にそして継続的に価値をもたらす状態にするには、知識設計と評価設計が非常に重要になります。
RAGやLLMの技術が日進月歩で進化する中、回答の内容も変化します。このような中で開発したプロダクトがしっかり価値を提供できるようにするには、「継続的に」精度と有効性を高める仕組みが非常に重要になります。
今回述べたように、むしろリリースされたプロダクトそのもの以上に、「継続的に」精度と有効性を高める仕組みの方が重要と言えます。このようなことを実践することで、ただRAGを作っただけではなく、企業活動にとって本当に役立つエンタープライズLLM(RAGプロダクト)が提供できるようになります。本記事がこのような取り組みや課題で悩まれている方の一助になれば幸いです。
生成AIについて興味関心があり、
ご相談があれば以下よりお問い合わせください

Author
クリエーションライン株式会社 取締役 兼 最高技術責任者(CTO)
クラウド黎明期からオープンなクラウド技術に取り組み、実際に大規模クラウドのアーキテクチャ設計・実装・運用なども行う。2018年からはクリエーションラインのお客様と一緒にチームを立ち上げ Factory IoTのデータ基盤、MaaSデータ基盤、5G IoT基盤、ロジスティックのアプリ・データ基盤などなど多数のアジャイル開発プロジェクトを立ち上げ・推進。
現在はモバイルアプリ開発やAI/機械学習、MLOps基盤、トレーニング開発、お金の計算、交通整理など幅広く関わる。
将来的にはウェアラブル、メタバース、ブレインマシンインターフェイス等のヒューマンインターフェイスに携わりたい。



