
Neo4j SandBox Graph Data Science プロジェクトを体験してみた(前編) #Neo4j #SandBox #GDS
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
概要
Neo4j を使用したデータ分析について調べていたら、sandboxに Graph Data Science プロジェクト があったので、使ってみました。
備忘録として、プロジェクトのシナリオを日本語でまとめたので公開します。

目次
- 目的
- 予備知識
- シナリオ0: イントロダクション
- シナリオ1: データセット
- シナリオ2: プロジェクショングラフについて
- シナリオ3: PageRank - 中心性の測定
- シナリオ4: Louvain Modularity 法 - コミュニティ(クラスタ)の検出
- シナリオ5: Jaccard 係数 - ノード類似度の測定
- シナリオ6: ダイクストラ法 - 経路探索
- 終わりに
(注:「シナリオ4: Louvain Modularity 法 - コミュニティ(クラスタ)の検出」以降は後編にて)
目的
- Graph Data Science の概要説明
- GDS ライブラリの使い方の説明
予備知識
Neo4j と GDS の概要はこちらをご参照ください。
Neo4j Sandboxから下記のプロジェクトを選択して開始します。
シナリオ0: イントロダクション
なぜデータサイエンスにグラフを使用するのか
伝統的データサイエンスと機械学習においてデータ理解をする際には、もっぱら表形式のデータを使用し、それぞれのデータ行は他のデータから独立するものとして扱われていました。
一方で、それぞれのデータ行同士の関係を考慮に入れたほうがより正確なモデルを生み出すことができる場合があります。
SNSの分析や、レコメンデーションシステム、不正検知、検索、チャットボットの開発などです。
このシナリオでは、グラフデータサイエンスでよく使用されるアルゴリズムの例をいくつかご説明します。
また、グラフを使用して一般的なデータサイエンスの問題を解くにあたって Neo4j Graph Data Science (GDS) の使用方法をご紹介します。
Neo4j Graph Data Science (GDS)
公式のGDSのドキュメントはこちらをご参照ください。
Neo4j Graph Data Science (GDS) にはさまざまなグラフアルゴリズムが含まれ、Cypher によって使用することができます。
グラフアルゴリズムは、グラフの要素や構造への洞察を与えることができます。
例えば、中心性や類似度を計算したり、コミュニティを検出したりすることができます。
このシナリオでは、グラフアルゴリズムを実行する際の通常のワークフローを示します。
一般的なワークフロー
- プロジェクショングラフを作成する
- プロジェクショングラフに対し、グラフアルゴリズムを実行する
- 結果を示し、結果の解釈を行う
シナリオ1: データセット
データの概要
どんなアルゴリズムを実行するにしても、まずデータを指定する必要があります。
このシナリオで使用するサンプルデータセットは、世界中に広がる空港の間のつながりを表すものです。※1
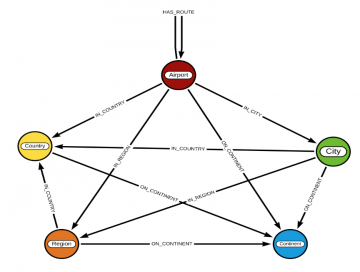
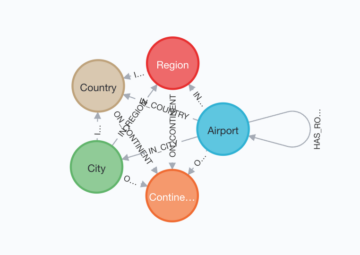
サンプルデータには、'Airport', 'City', 'Country', 'Continent', 'Region' の5種類のノードラベルがあり、
':HAS_ROUTE', ':IN_CITY', ':IN_COUNTRY', ':IN_REGION', ':ON_CONTINENT' の5種類のリレーションがあります。
データのロード
Cypher コマンド 'LOAD CSV' を使用して、GitHub でホストされた CSV ファイルからデータを Neo4j にインポートします。
CSV ファイルは一行ずつオブジェクトにパースされ、Cypher で使用できるように変換されます。
まず、個々のノードに 'uniqueness constraints' を作成し、クエリを高速化します。
CREATE CONSTRAINT airports IF NOT EXISTS ON (a:Airport) ASSERT a.iata IS UNIQUE; CREATE CONSTRAINT cities IF NOT EXISTS ON (c:City) ASSERT c.name IS UNIQUE; CREATE CONSTRAINT regions IF NOT EXISTS ON (r:Region) ASSERT r.name IS UNIQUE; CREATE CONSTRAINT countries IF NOT EXISTS ON (c:Country) ASSERT c.code IS UNIQUE; CREATE CONSTRAINT continents IF NOT EXISTS ON (c:Continent) ASSERT c.code IS UNIQUE; CREATE INDEX locations IF NOT EXISTS FOR (air:Airport) ON (air.location);
次に、'Airport', 'Country', 'Continent' ノードをインポートし、プロパティを設定し、':IN_CITY', ':IN_COUNTRY', ':IN_REGION', ':ON_CONTINENT' リレーションを設定します。
WITH
'https://raw.githubusercontent.com/neo4j-graph-examples/graph-data-science2/main/data/airport-node-list.csv'
AS url
LOAD CSV WITH HEADERS FROM url AS row
MERGE (a:Airport {iata: row.iata})
MERGE (ci:City {name: row.city})
MERGE (r:Region {name: row.region})
MERGE (co:Country {code: row.country})
MERGE (con:Continent {name: row.continent})
MERGE (a)-[:IN_CITY]->(ci)
MERGE (a)-[:IN_COUNTRY]->(co)
MERGE (ci)-[:IN_COUNTRY]->(co)
最後に、'(Airport)-[:HAS_ROUTE]->(Airport)' リレーションをインポートします。
リレーションは 'distance' プロパティを持つことに注意してください。これはそれぞれの空港間の距離を示しています。後で重み付きグラフを作成するために使用します。
LOAD CSV WITH HEADERS FROM 'https://raw.githubusercontent.com/neo4j-graph-examples/graph-data-science2/main/data/iroutes-edges.csv' AS row
MATCH (source:Airport {iata: row.src})
MATCH (target:Airport {iata: row.dest})
MERGE (source)-[r:HAS_ROUTE]->(target)
ON CREATE SET r.distance = toInteger(row.dist);
データの可視化
アルゴリズムの実行に入る前に、データを可視化しましょう。
次のクエリを走らせることで、グラフのスキーマを取得することができます。
CALL db.schema.visualization()
このクエリにより、5つのノードタイプと5つのリレーションタイプがあることが可視化されます。
基本的なグラフ探索的データ分析 (EDA)
GDSのアルゴリズムを使用する前に、まず基本的なグラフ探索的データ分析 (exploratory data analysis: EDA) によってデータの統計分析をしてみましょう。
グラフに含まれるいくつかの空港ノードを調べて、どのようなプロパティが空港ノードに関連づけられているかを見てみます。
MATCH (a:Airport) RETURN a LIMIT 3
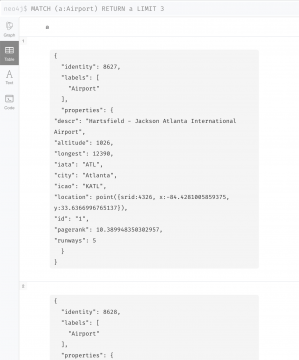
大陸ごとの空港数の分布を調べてみます。
MATCH (c:Continent) return c.name AS continent_name, SIZE((:Airport)-[:ON_CONTINENT]->(c)) AS num_airports ORDER BY num_airports DESC
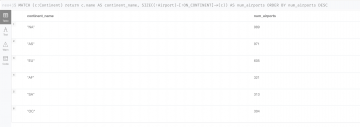
空港のフライト数の標準偏差、平均値、最大値、最小値を求めてみます。
MATCH (a:Airport)-[:HAS_ROUTE]->() WITH a, count(*) AS num RETURN min(num) AS min, max(num) AS max, avg(num) AS avg_routes, stdev(num) AS stdev

シナリオ2: プロジェクショングラフについて
プロジェクショングラフとは
GDS アルゴリズムを実行するためにはまず、プロジェクショングラフ(インメモリグラフ)をユーザー定義名で作成することが必要です。
プロジェクショングラフとは、GDS アルゴリズムによる計算の効率を向上させるために、グラフカタログと呼ばれるメモリ内の領域に、反復して用いられるグラフの要素をマッピングしたものです。
プロジェクショングラフを作成することで、グラフの要素の性質が下記のように変化する可能性があります。
- ノードとリレーションの名称が変更されることがあります
- ノードとリレーションが一部マージされることがあります
- リレーションの向きが変わることがあります
- 並行リレーションが集約されることがあります
- リレーションはより大きなパターンから派生されることがあります
グラフプロジェクションの作成方法には、ネイティブプロジェクションによる方法と Cypher プロジェクションによる方法がありますが、このセクションでは、ネイティブプロジェクションのアプローチを使用して プロジェクショングラフを作成します。
ネイティブプロジェクションによってプロジェクショングラフを生成する
ネイティブプロジェクションは、プロジェクショングラフを生成するための最も早い方法です。
ネイティブプロジェクションは graphName, nodeProjection, relationshipProjection の3つの必須のパラメータを取ります(オプションで configuration パラメータを指定して、グラフの高度な設定を行うこともできます)。
一般に、ネイティブプロジェクションを生成する構文は下記の通りです。
CALL gds.graph.project(
graphName: String,
nodeProjection: String or List or Map,
relationshipProjection: String or List or Map,
configuration: Map
)
YIELD
graphName: String,
nodeProjection: Map,
nodeCount: Integer,
relationshipProjection: Map,
relationshipCount: Integer,
projectMillis: Integer,
createMillis: Integer
今回の例なら、例えば次のようにして全ての空港間のルートのプロジェクショングラフを作成できます。
CALL gds.graph.project(
'routes',
'Airport',
'HAS_ROUTE'
)
YIELD
graphName, nodeProjection, nodeCount, relationshipProjection, relationshipCount
これはとてもシンプルなプロジェクショングラフですが、これに加えてノードやリレーションのプロパティや複数のノードタイプやリレーションタイプを追加することもできます。
プロジェクショングラフの生成に関するその他の例に関しては GDS ドキュメントを参照してください。
グラフカタログ
グラフカタログとは、プロジェクショングラフをロードするメモリ領域のことです。
グラフカタログにある全てのグラフとプロパティの一覧を取得するのは次の構文を使用します。
CALL gds.graph.list()
個々のグラフについて確認することもできます。例えば、先ほど作成した routes グラフの存在を確認するには次の構文を使用します。
CALL gds.graph.list('routes')
結果は下記のようになります。
プロジェクショングラフの4つの実行モード
名前付きのプロジェクショングラフを作成した場合、それぞれのアルゴリズムについて、次の4つの実行モードがあります。
- stream: データベースを変更せずに、アルゴリズムの結果をレコードのストリームとして返します
- write: Neo4j データベースにアルゴリズムの結果を書き込み、1レコードの統計情報を返します
- mutate: プロジェクショングラフにアルゴリズムの結果を書き込み、1レコードの統計情報を返します
- stats: Neo4j データベースにもプロジェクショングラフにも書き込みを行わずに、1レコードの統計情報を返します
mutate モードに関する特記事項
特徴量エンジニアリングを行うとき、GDS によって計算された数値をプロジェクショングラフに埋め込むと効率的な場合があります。そのための手段が mutate です。
mutate は、先々の計算で必要となる計算結果を、データベースを変更せずに、 プロジェクショングラフの各ノードに書き込みます。
この振る舞いは複雑なグラフアルゴリズムやパイプラインを使用する場合に役に立ちます。詳細はAPI ドキュメントを参照してください。
一般的なアルゴリズムの使用方法
4つの実行モードのうちの一つを使用するにあたって、グラフアルゴリズムを呼び出す一般的な方法は下記のようになります。
CALL gds[.<tire>].<algorithm>.<execution-mode>[.<estimate>]( graphName: String, configuration: Map )
[]で囲まれた部分はオプションです。
- <tire>が存在する場合は、アルゴリズムがアルファ版あるいはベータ版であることを表します(本番では使用しません)
- <algorithm>はアルゴリズムの名称を表します
- <execution-mode>は4つの実行モードのうちの一つを表します
- <estimate>はオプションフラグで、メモリ使用量の推定値を返すかどうかを示します
シナリオ3: PageRank - 中心性の測定
PageRank とは
ノードの中心性や重要度を決定する方法は多くありますが、PageRank の計算は最も人気のある方法の一つです。
PageRank はノードの推移的あるいは方向的な影響力を測定します。このアプローチの特徴は、ターゲットノードの影響力を判断する際に、隣接ノードの影響力を考慮するということです。
基本的な考え方は、他のノードからより多くのリンクおよびより影響力のあるリンクを持つノードがより重要である(高い PageRank を持つ)と見なされるということです。
このアルゴリズムは反復アルゴリズムです。反復の回数は GDS の構成パラメータとして設定されますが、ノードスコアが指定された許容値に基づいて収束した場合、アルゴリズムが終了する場合があります。この挙動は GDS で設定することができます。
ノードの次数による中心性の測定
それぞれのノードの PageRank を計算する前に、まずそれぞれの空港に出入りするフライトの総数を求めましょう。
これは '[:HAS_ROUTE]' 関係の合計次数になります。次のクエリを使います。
MATCH (a:Airport) WITH a, SIZE((a)-[:HAS_ROUTE]-(:Airport)) AS degree RETURN a.city AS city, a.iata AS airport_code, degree ORDER BY degree DESC
結果は下記のようになります。
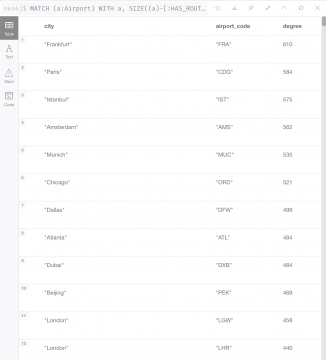
PageRank による中心性の測定
ノードの次数は中心性の一つですが、ノードのPageRankは中心性のより正確な表現になります。
PageRank を計算するには、既に作成済みの 'routes' プロジェクショングラフを使用します。
もし、'routes' プロジェクショングラフをまだ生成していないか、既に削除している場合は、再生成する必要があります。
既に存在する名前でグラフを再生成しようとすると、次のエラーが発生します。
Failed to invoke procedure `gds.graph.project`: Caused by: java.lang.IllegalArgumentException: A graph with name 'routes' already exists.
stream モードを使用する
既に述べたように、stream モードはデータベースやプロジェクショングラフを変更せずに計算結果を出力します。
下記で実行します。
CALL gds.pageRank.stream('routes')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).iata AS iata, gds.util.asNode(nodeId).descr AS description, score
ORDER BY score DESC, iata ASC
1, 2行目で、内部のIDスペース(ノードIDやリレーションIDを格納している領域)にマップされた計算結果と PageRank スコアが返されます。
3行目で、 'gds.util.asNode()' を使用してIDスペースから空港の 'iata' コードを引き抜きます。そして、PageRank スコアの降順にソートされた空港コードが出力されます。
結果は下記のようになります。
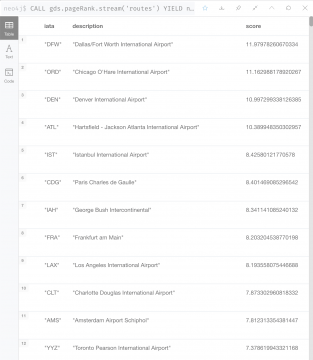
予想通り、PageRank スコアが最も高い空港は、世界の中でも大変有名な空港であることが分かります。
PageRank はここで使用されたような基本的なグラフだけでなく、重み付けされたグラフでも同様に動作します。重み付けされたグラフでの実行結果については、GDS ドキュメントを参照してください。
※ GDS は内部のIDスペースを計算のために使用しますが、これはグラフ自体の認識可能な情報に対応していません。
そのため、アルゴリズムから結果を返す場合、IDスペースに返されます。
これを実際のグラフに対応する何かに変換するためには、次の組み込みメソッドを使用します。
gds.util.asNode(nodeId).property_name AS property_name
この方法で、IDスペースに基づくプロジェクショングラフから所望の property_name を取り出すことができます。
write モードを使用する
PageRank の計算結果をグラフ中のそれぞれのノードのプロパティとして付与したい場合、次のように '.write()' を使用します。
CALL gds.pageRank.write('routes',
{
writeProperty: 'pagerank'
}
)
YIELD nodePropertiesWritten, ranIterations
結果は次で確認できます。
MATCH (a:Airport) RETURN a.iata AS iata, a.descr AS description, a.pagerank AS pagerank ORDER BY a.pagerank DESC, a.iata ASC
結果は stream の場合と同一になります。
続きは後編の記事にてご覧いただけます。
※1:このデータセットは Kelvin Lawrence によって作成されたもので、Apache ライセンスver2.0 の元で利用可能です。オリジナルはGitHubリポジトリ(https://github.com/krlawrence/graph)にありますが、このシナリオの目的に沿って修正してあります。




