
Spark Summit2016報告会&データ分析勉強会に行ってきた。 #Sparkmeetup

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
今回のブログは6月にサンフランシスコで開催されたSpark Summit2016の振り返りとSparkを中心としたデータ分析についてセミナーが開かれましたのでそのレポートをしてみたいと思います。

会場はNHNテコラスさんのセミナースペースをお借りして2016年7月26日に開催されました。
開催のお知らせはここ→ http://connpass.com/event/34579/
ビッグデータ分析ということではHadoop/MapReduceというのが皆さんも御存知だと思いますが、既に世の中には新しいソフトウェアが登場しています。それがApache Sparkです。Sparkについては去年のSpark Summitのレポートも参考にしてください。
Spark Summit 2015レポート: http://www.creationline.com/lab/11182
今回のセミナーでは、木内と鈴木がSpark Summit2016の簡単な振り返りを行いました。まずは鈴木のセッションから。

約2500人が参加したSpark Summit2016ですが、中国からの参加者(もしくは中国人の参加者?)が非常に多かったそうです。去年のサミットのユースケースでもTencentやAlibabaの事例が紹介されていましたから、これはある意味、当然の結果かも知れません。日本のデータサイエンティストももっと海外に積極的に情報収集とコミュニティへの参加をして頂きたいところです。
そんなSpark Summit 2016ですが、話題の中心はやはりまもなくリリースされるSpark 2.0。キーノートでもDatabricksのCTOでCo-FounderのMatei Zaharia氏が新しい機能などについてプレゼンテーションを行いました。鈴木が注目したのは、実際に2016年の大統領選を題材にしてtwitterからのデータをストリーミングとして受け取り、どの候補の名前がいつ、どれくらい出てくるのか?を実際にDatabricksのクラウドサービスを使ってデモを行ったという部分です。

2016年の大統領選のツイートをSparkで可視化。
こういうデモを実際にリアルタイムでサラッと出来てしまうところが、Databricksのスゴイところ、でしょうか。
そして木内のプレゼンテーションは主にSpark 2.0の話題です。この夏にリリースされる予定のSpark 2.0ですが、Summitのキーノートのメインのトピックだったわけで、その中でも「Easier, Faster, Smarter」をゴールに開発が進められているということです。

特にGPUを使った高速化、Pythonを言語として利用した際の高速化など、JavaやScalaを使わずに使い慣れたPythonを使って如何に高速にするのか?についてのセッションが数多くあったようです。高速化についてはTungsten Engineというインメモリの実行エンジンが第2世代になって「WholeーStage Code Generation」ということで全てのコードを中間コードに変換できるようになったことで更に高速化が進んだということです。
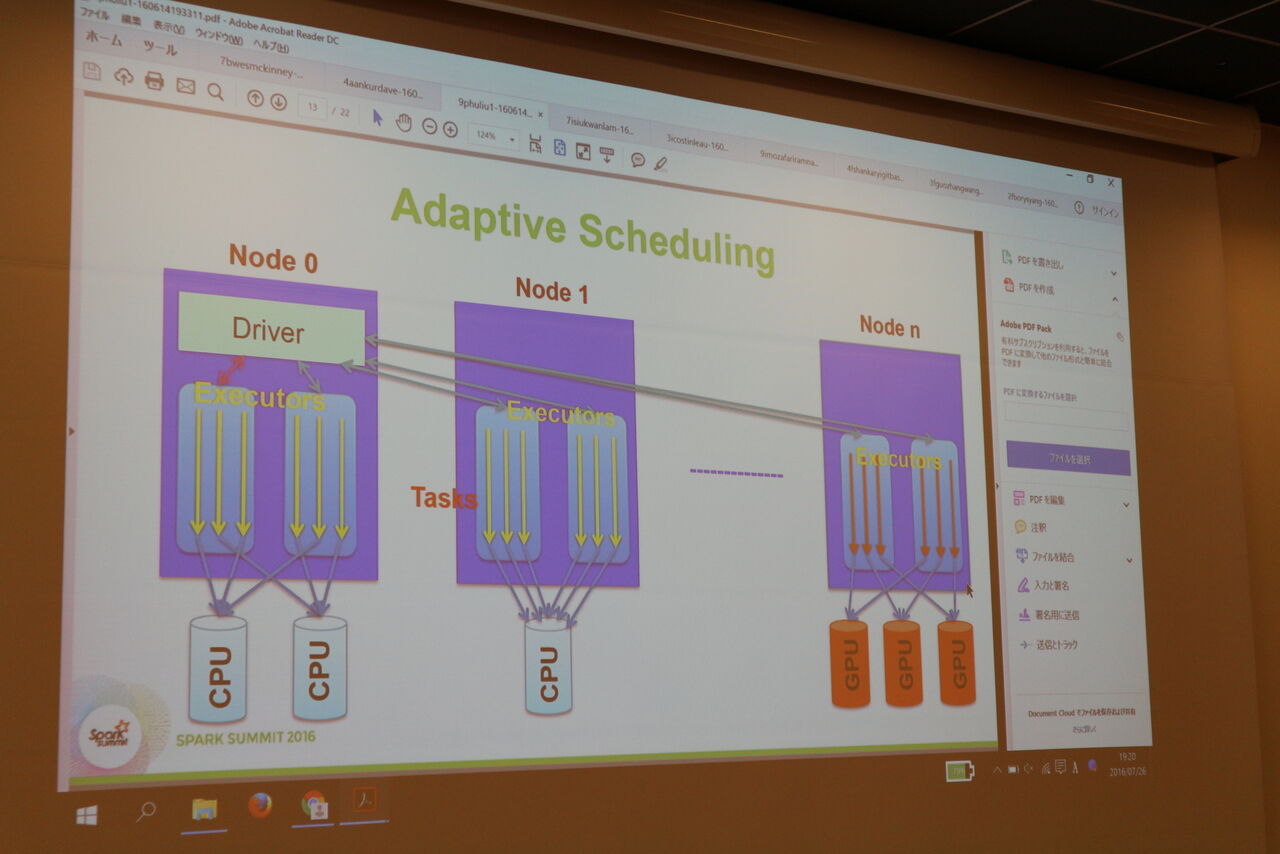
GPUを利用してクラスターのWorker(Executor)を高速化。
またユースケースに関しても様々な業種業界での利用が進んでいることが分かったと説明しました。特にインターネット系企業だけではなく様々な企業がSparkを使ってデータ分析を行っているということです。木内が強調していたSpark 2.0の新機能の中では機械学習の中で使われる教師データを保存して他のシステムに持っていけるようになったことが地味に良い機能である、とのことです。この辺は実際にシステムを構築しているエンジニアならではの気づきかもしれません。

様々な企業がSparkを使い始めているというスライド。
次に登壇したのはリクルートテクノロジーズの石川有さんです。石川さんはSparkのコミッターとしても活躍されています。Sparkに関する様々な勉強会やイベントでもおなじみの方ですが、今回は「Learning Data Science with SparkR and Databricks Cloud CE」というタイトルでR言語を使ってSparkを利用可能にしたSparkRの紹介とSparkの開発で有名なDatabricksが提供している無償のクラウドサービス、Databricks Community Editionの紹介を行いました。
Rはデータ分析を行う専門家の間ではよく使われている言語ですが、そのRをそのまま使ってSparkを使えるようにしたのがSparkRです。石川さんはその特徴とアーキテクチャーを分かりやすく解説してくれました。またDatabricksのクラウドサービス、Databricks Community Editionの紹介では実際にデモデータ(サンフランシスコの不動産データだそうです)を用いて間取りと価格の相関関係や偏差値などを簡単にしかもインタラクティブに求めることができることを紹介しました。Community Editionは使える規模は小さいながらもSparkを使ったデータ分析を始めるには最適の入り口かもしれません。

SparkRのアーキテクチャー。
次に登壇したのは今回の会場を提供してくれたNHNテコラスの データサイエンティスト佐藤 哲さんです。佐藤さんは実際にテコラスのWebサイトを訪れるユーザーのアクセスパターンをSparkを活用して分析するという事例を紹介して頂きました。

今回の事例の概要。クラスタリングがキモですね。
実際にアクセスデータを分析してみるとかなり色々なことが分かったようです。年代別のアクセスパターンから人気の高いコンテンツを好むクラスタとある特定のコンテンツばかりを好むマニア的なクラスタとの違いが見えてきたそうで、Webサイト分析の次の一手として参考になった参加者も多そうでした。
最後は、Hadoop御三家の1社、Hortonworksのソリューションアーキテクト、今井雄太さんです。
Spark Summit 2016の感想ということで、ユースケースについてもNetflixやUberの例を挙げてより詳細な内容に切り込んでいるのがスゴイですね。特にSpark Streamingについては「どこに行ってもDisられていた」という辺りがとってもリアリティがあって良かったと思います。

SparkのユースケースとSpark Streamingについて。
また特に目立ったユースケースとして自動車をIoTデバイスとして、大量に吐き出されるセンサーデータを元に故障の事前予測を行うユースケースが紹介されました。この辺りにもSparkによるデータ分析がリアルなビジネスの現場で使われようとしているのを感じます。
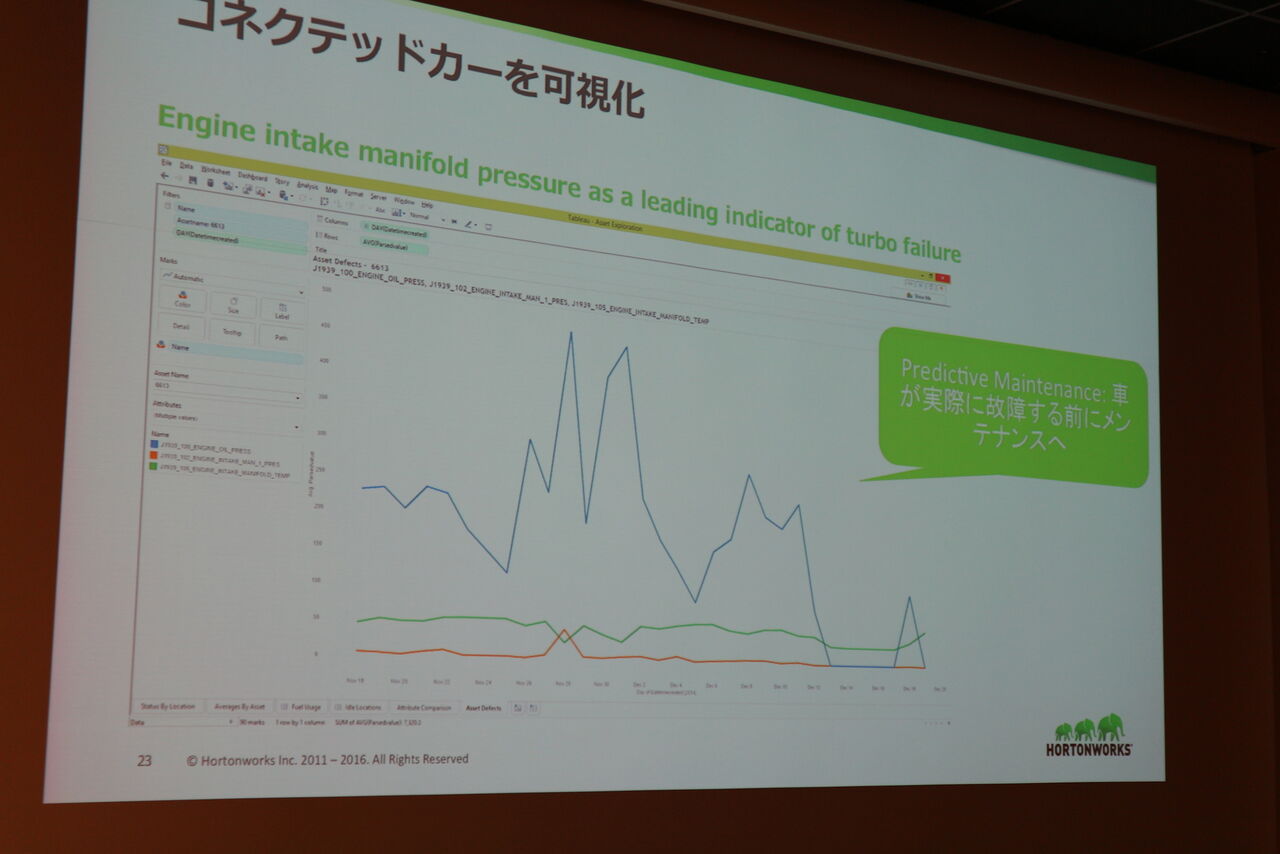
コネクテッドカーの故障予測の事例(吸気圧からターボの故障を予測)
最後に参加者の皆さんとピザとビールの懇親会を楽しんでこの勉強会は無事に終了しました。
当日の資料や動画は
http://connpass.com/event/34579/presentation/
こちらをご参照ください。



