
Spark Summit 2015 レポート01:Keynoteスピーチ

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
Spark Summit 2015(https://spark-summit.org/)が2015年6月15〜17日にサンフランシスコにて実施されました。
講演内容を何回かに分けてご報告いたします。
----
Spark Summit 2015:Keynoteスピーチ(6/15/2015)

Sparkの2014年の活動のまとめ
今後の方針についての解説

Matei Zaharia氏:Databricks社CTO
2015年はSparkにとってもっとも成長した年になった

データ処理の領域においてもっとも活発なオープンソースだった
R言語サポートは、Sparkのデータ分析領域に展開する象徴的な動き
新機能の開発:今まで以上に開発のスピードが促進している
コミュニティの成長
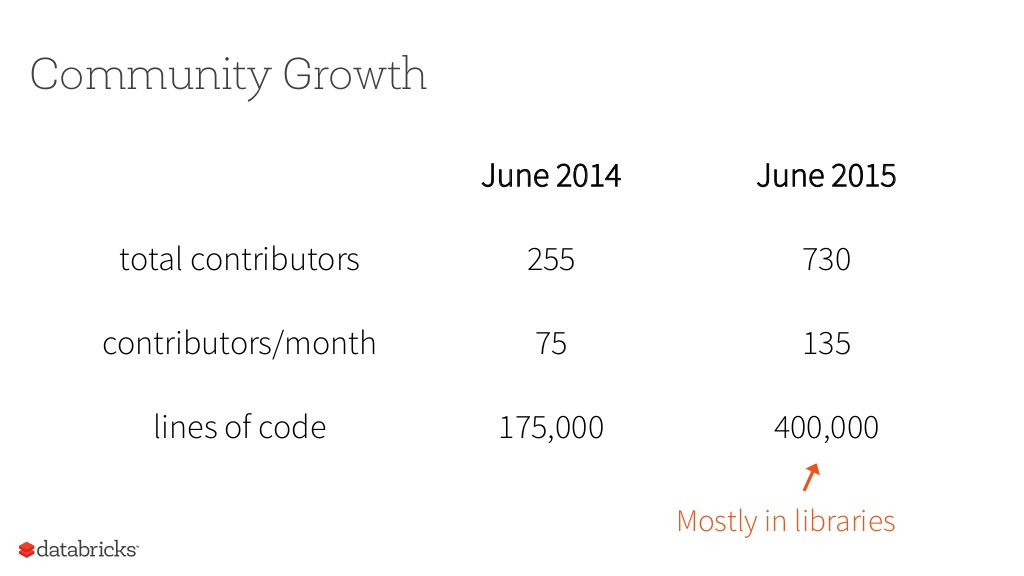
Contributorの人数は730人に増え、今年末で1000人超える模様
2/3は新しい人で構成でどんどん増えている
開発されたコード量は40万行に及ぶ(大部分はSparkのライブラリの一部に含まれる)
市場での採用も広がっている

1000社以上がSparkを利用している、という実態
採用されている業界の広さも顕著:従来のインターネットベンダに加え、銀行、自動車メーカ、等
50社以上の再販/アプリ開発パートナーが存在
ほとんどのBIベンダーはコネクターを開発、提供している
大規模ユーザ

最大のクラスターは、Tencent社の8000ノード:Tencent社のユーザ数は10億人を超えている
最大のジョブは、Alibaba社の実行している1PB(ペタバイト)
最大のストリーミングジョブは、Janelia farmで実施している30〜40台のマシンを使った1TB/時間
エコシステムの成長

アプリケーション:Hadoopエコシステムの大方はSparkをサポートしている。
稼働環境:コンテナも含めたほとんどのデプロイ環境でサポート
データソース:ほとんどのデータベース技術はSparkとの連携をサポートしている
現時点でのSparkのコンポーネント構成

コアエンジンである、Spark Coreの上に複数のライブラリを組合せて利用できるフレームワーク
統合フレームワークであるがゆえに、複数コンポーネントを組合せた使いやすさが魅力
今後の方針

データサイエンス:
大量のクラスター上のデータ分析のみならず、小さなノード上のデータ分析でも同じAPIとツールが使えるように、Sparkの応用範囲を広げる。
プラットホームAPI:
簡単なプラグインの手法をさらにエンハンス、エコシステムを拡大
データサイエンス

今年は3つ発表
データフレーム:Python、R同様にSparkでもこのAPIをサポート
マシンラーニング:Spark上でマシンラーニングのワークフローを開発できる環境
R言語サポート:Spark 1.4でサポート
プラットホームAPI

異なるデータソースを統合してサポートするインタフェース
Spark Packages:70以上がすでにコミュニティで提供されている
Sparkエンジンのエンハンス

プロジェクトTungsten:ベアメタル上でのSparkの実装による、Spark処理性能の向上
DAG処理のビジュアライゼーション/デバッグツール
Spark 1.4リリースの概要

Patrick Wendell氏の解説
Spark 1.4は既にリリースされている
230人のエンジニアが開発に参画(内、Databricksの従業員は70人弱)=>外部からのContributionが大きい
R言語サポート
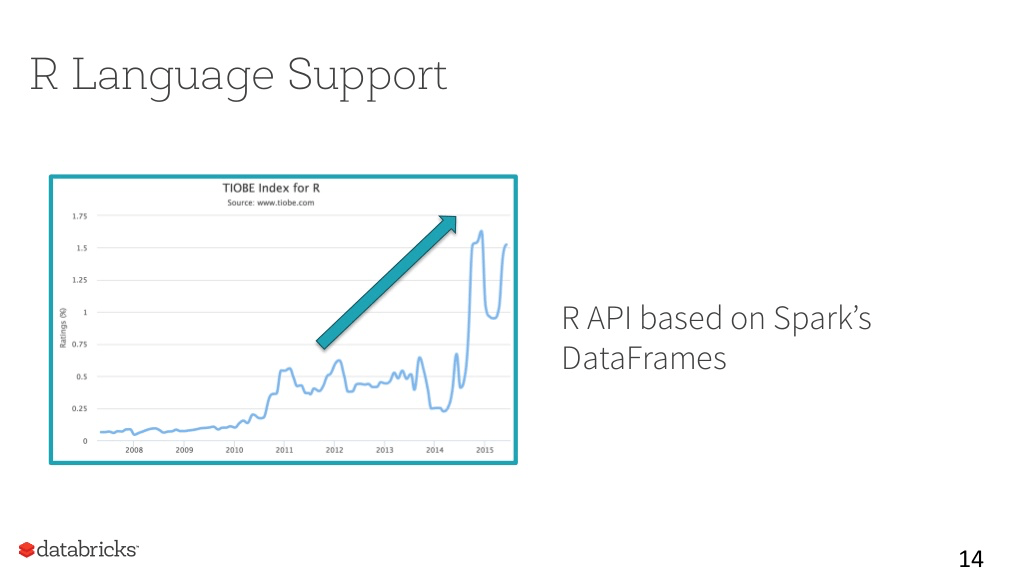
Rはデータサイエンティスト向けの言語:開発言語のエコシステムで急激に成長している
元はAMPLabで開発されたものをDatabricksでSpark上に移植
Spark RはSparkのデータフレーム機能を利用し、性能を大幅にアップしている
R Runtime機能

元のR Runtimeはマルチコアランタイムエンジンじゃないため、大量のサーバ上で大規模データセットの分析には向いていない。
Sparkはそこを改善している。
最適化:性能への注力
I/Oライブラリアクセス

様々なデータソースからのSparkへの読み込みが非常に簡単に
JSONサポート
MySQL(JDBC)サポート
Hiveテーブルサポート
その他のデータベースとの接続

その他、広い範囲のデータベースエンジンとの接続も既にサポート
CSV
Cassandra
MongoDB
等
マシンラーニングパイプライン
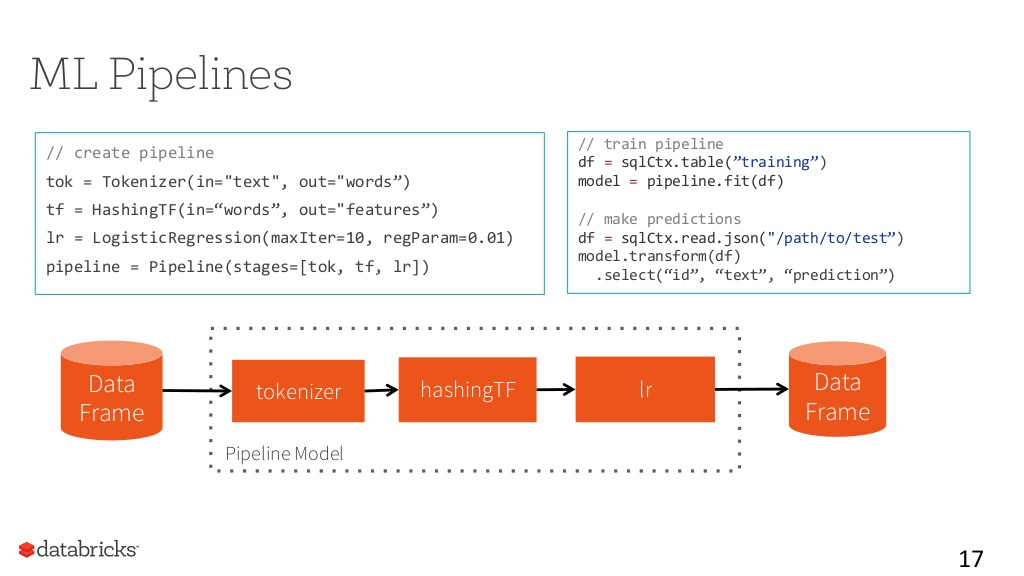
大規模なマシンラーニングを採用している組織の運用モデルをベースに開発
典型的なパイプラインモデル
データソースをベースにTokenize処理を行う:データを言葉ごとに分離
hashingTFを通して頻度分析を行う
Logistic Regressionを通した内容分析
このパイプラインを再利用する事が可能なため、応用範囲が広い
マシンラーニングのStableAPI:正式なリリース

APIのロックイン:3rdパーティのパイプラインの開発可能
新しいツールやアルゴリズムを追加
JavaやScalaのAPIにかなり理解レベルに達している
プロジェクトTungsten:性能改善
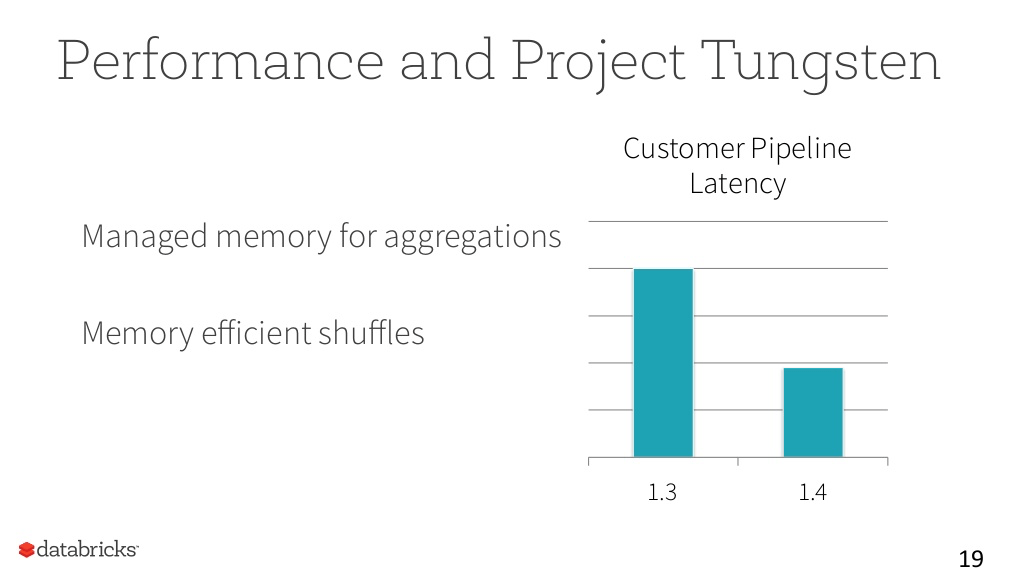
Spark 1.4では、初期的な開発をリリースしている。
既存のアプリに変更を加えずに、50%程度の性能向上が実現されている。
3ヶ月後のV1.5でさらに機能は1充実させる予定
Spark 1.5で予定される機能

プロジェクトTungsten:大方の機能の開発完了、デフォルトで性能はかなり改善される見込み
Sparkストリーミング:データフローの管理機能の強化、データ処理の安定化の強化
マシンラーニング:単一マシンでの比較的小規模な演算処理機能の強化、複数機能を組合せた際のスケーラビリティ強化
R言語:マシンライニング機能との統合強化



