
【Event-Driven Architectureへの道】データメッシュを実現する「Starburst」解説!

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
前回の記事(データメッシュ概要、イベント駆動型データメッシュ)ではデータメッシュの思想・原則やアーキテクチャについて説明しました。製品としてのデータ(Data as a Product)で触れたとおり、データにはさまざまな種類があり、例えば、運用データは、多くの場合、非構造化データとして取り込まれますが、前処理として、クリーンアップされ、イベントとエンティティに構造化する必要がありました。
[以下は前回の記事で記載した、Data as a Productの一例]
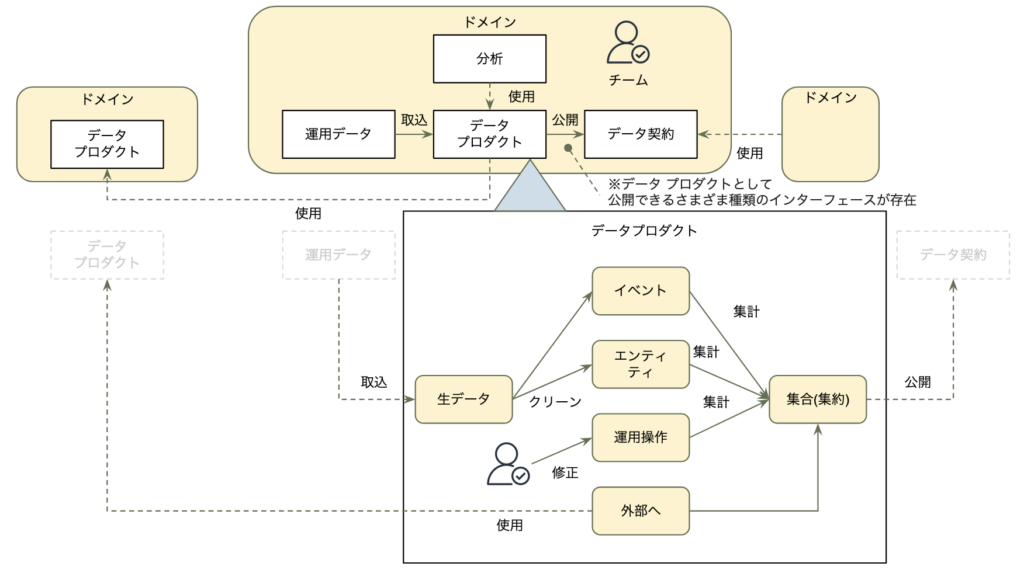
上記のような必要な構成を実現する製品プラットフォームの一例として、Starburst Platform があります。本記事では、Starburst の概要について紹介します。
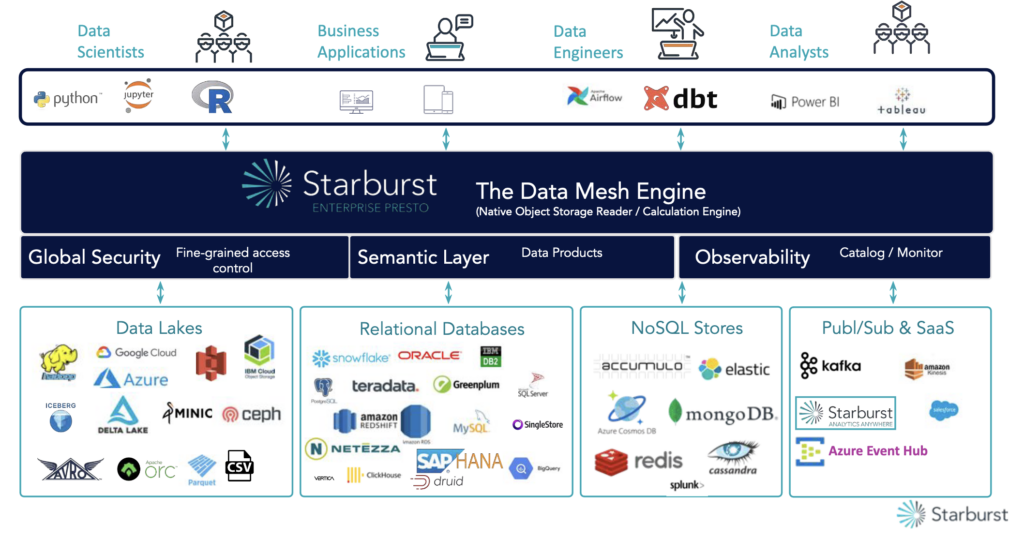
Starbustの概要
Starburst(スターバースト)は、オープンソースのデータクエリエンジンである Trino(トリノ)をベースとしたソフトウェアです。Trino は以前は Presto という名前で知られており、分散型のSQLクエリエンジンで、分散された複数の大規模なデータセットに対する高速かつ効率的なクエリ処理を実現します。
Presto は、Facebookが開発した分散型のSQLクエリエンジンで、2012年にFacebook内で開発が始まり、2013年にオープンソースプロジェクトとして公開されました。Facebook、Airbnb、Netflixなど、大規模なウェブサービス企業がPrestoを採用してきましたが、2019年に、Trinoは、Prestoのフォークとして誕生しました。オープンソースとしてはよくある出来事ですが、Prestoの開発コミュニティにおいて、開発の方向性やライセンスに関する意見の違いが生じ、一部の開発者がPrestoをフォークし、Trinoとして独立したプロジェクトがスタートしました。Trinoは、Prestoと同様に高速なデータクエリエンジンとして位置づけられ、Prestoのコードベースを継承しており、オープンソースコミュニティによってアクティブな開発とメンテナンスが行われています。
Starburst(スターバースト)はStarburst Data(スターバーストデータ)社が提供すプロダクトラインです。Starburst Data(スターバーストデータ)社では以下の2つのプロダクトを提供しています。
Starburst Galaxy: Starburst Galaxyは、SaaSとして提供されるマネージドなデータクエリエンジンサービスです。マネージドサービスなので、AWS、 Azure、Google Cloud上でワーカーノード追加や、パッチ適用などは考慮する必要がありません。ワーカーノードサイズと利用時間により料金が決まっている提供モデルです。
価格モデル

無料で利用できる機能
- 3 つの標準実行クラスター
- 18 個以上のデータソース
- 10 名以上のクライアント
- ユニバーサル検索
- 自動データカタログ作成
- フルマネージドメタストア
- 役割ベースのアクセス制御
- データ製品
無料プランに加えて Pro で利用できる内容
- 高度なクラスター構成 – カスタム実行モード、自動スケーリング、およびジョブ管理
- クロスクラウドおよびクロスリージョンフェデレーション
- 属性ベースのアクセス制御
- プライベート接続
- サービスアカウント
- SSO と SCIM
クレジットの仕組み
以下は、Pro をベースとしたクレジットの内訳となっており、実際に使用したリソースに対する支払いモデルとなります。各クレジットは、実行中のクラスター内の 1時間のワーカーノードあたりで 、1 時間のコンピューティングに相当します。また、月額料金は、使用されたクレジット数に基づいて計算され、使用量は最初の 1 分以降の最も近い秒数に四捨五入されます。

Starburst Enterprise: Starburstの主力製品であり、Trinoをベースにしたエンタープライズ向けのデータクエリエンジンです。Enterpirseは、オンプレミスやクラウド環境に対応し、さまざまなデータソースにアクセスし、高速なSQLクエリ処理を実現し、エンタープライズ向けの大規模なデータセットに対応してます。製品問い合わせなどのサポートはありますが、実際のワーカーノードの追加やパッチ適用は自社にて運用が必要です。
どちらも、24時時間365日のサポートが提供されてます。
Starbust Galaxyの機能
Trino から拡張されている Starbust Galaxy 固有の機能をピックアップしてみます。
Global search:Starburst Galaxy 内のデータエンティティを検索できる機能で、エンティティ名、説明、タグ、所有者、テーブル内の列名などを入力して検索します。
PyStarburst:PyStarburst ライブラリは、標準の Python DataFrame API を実装しており、DataFrame と呼ばれるデータ構造を使用して 2 次元データを分析、操作可能です。このライブラリは、アプリケーションコードが実行されるシステムにデータを移動せずに、Python を使用して複雑な変換パイプラインを作成し、データを操作できます。
Data Lineage:Data Lineageは、データがどこから来て、どのように変換されて、最終的にどのように表示されたかのフローの追跡をサポートします。Starburst Galaxy で実行されるワークロードのテーブル、ビュー、マテリアライズド ビュー間のデータフローを視覚化する機能です。
Starburst Warp Speed:Starburst Warp Speed は、インデックス作成層とキャッシュ層を透過的に追加して、高いパフォーマンスを可能にする機能です。利用する構成としては、マネージドの Kubernetes クラスタ上の Deployment から オブジェクトストレージにアクセスするカタログに対して、Starburst Warp Speed ユーティリティ コネクタを構成することで、パフォーマンスが向上する機能です。パフォーマンスを改善する機能tは、Starburstの強みではないでしょうか。
role-based access control (RBAC) :RBAC を使用すると、カタログ、スキーマ、およびテーブルに対するユーザーのアクセス権限を操作可能です。テーブル内の特定の列、関数、ストアドプロシージャ、セッションプロパティなどのアクセス権限操作が可能です。
Row filters and column masks:ユーザーが表示できるデータを行および列レベルで制限できます。データをマスクして行をフィルタリングすることにより、別のユーザーが同じクエリを実行できるようにします。ロールに適用できる権限には、以下の2 種類があります。
- 列マスク:テーブル内の 1 つ以上の列に適用され、構成された式に従って選択された値を非表示にします。
- 行フィルター:行が 1 つ以上の SQL に一致する場合、クエリによって返される行を除外します。
提供される価格のモデルは、容量ベースの価格モデルを採用しており、実行中のクラスター内のワーカーノードのサイズに応じて 、1 時間あたりのコンピューティングリソースを支払います。ユーザーは必要なリソースを前払いすることで価格が予測しやすくなり、予算が立てやすくなります。
Starburst Enterpriseの機能
Starburst Enterpriseでは、上記に記載したGalaxyの機能に加えて、様々なコネクターが提供されています。提供される価格のモデルは、vCPUに応じたライセンス課金で、先ほどの Starburst Warp Speed は、追加のエリートライセンスが必要です。提供できる環境は、オンプレミスと、AWS、Azure、GCP、Red Hat OpenShift などに構築する kubernetes 環境となります。
Additional connectors:さまざまなデータソースからデータアクセスをするためにカタログを作成しますが、Starburst Enterprise では多くのコネクタが提供されてます。オブジェクトストレージコネクタや、RDBMSコネクタ、ストリーミングコネクタ、ユーティリティコネクタ(Starburst Warp Speed、JMX)などに分類されています。
Long-term support(LTS):Starburst Enterpriseで は、長期サポート (LTS) リリースと短期サポート (STS) リリースがあります。LTSの概要は以下の通りです。
- 実稼働環境での使用が 12 か月間サポートされます。
- 選択された Trino オープンソース リリースでのみ利用可能です。
- 年間リリース数が限られており、四半期ごとに最大 1 回のリリースがあります。
Insights cluster history:特定の時間範囲における Starburst Enterprise Platform (SEP) クラスターの負荷状態を可視化してWeb管理コンソールからメトリックスが確認可能です。
Insights query overview:Insights クエリは、Starburst Enterprise Platform (SEP) で クラスター上で処理された実行中とキューに登録されたクエリ、完了(失敗)したクエリに関する情報が提供されます。
データレイクハウスとStarburst
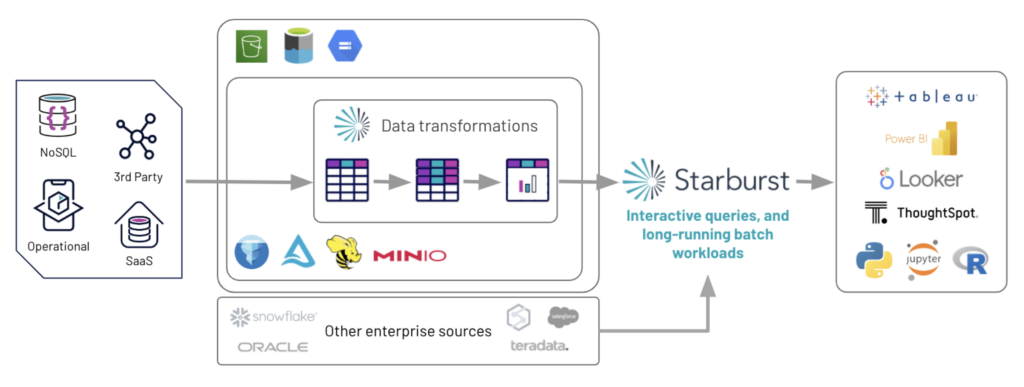
データレイクハウスはデータレイクとデータウェアハウスの優れた要素を取り入れたオープンで新たなデータ管理パラダイムです。データレイクハウスは、データレイクに格納された膨大なデータに対して、効率的かつセキュアに人工知能(AI)やビジネスインテリジェンス(BI)を直接実行できるアーキテクチャとなります。例えば、データレイク上で BI を高速に動作させる SQL とパフォーマンス機能(インデックス、キャッシュ)など、大規模なスケールで、企業のあらゆるデータを使用した AI と BI の両方を効率的に実現するために貢献します。データレイクハウスを実現するための主要なテクノロジーは、Delta Lake、Hudi、Iceberg などのオープンソースで、注力しているベンダーには、Databricks、AWS、Dremio、Starburst などがあります。ちなみに、データウェアハウスを提供するベンダーには、Teradata、Snowflake、Oracle などがあります。
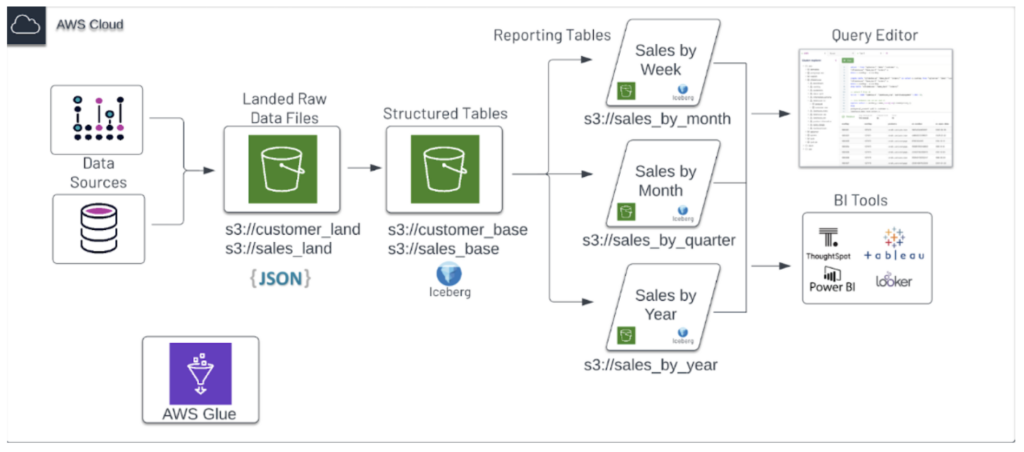
例えば、上記のようなStarburstにおけるデータレイクハウスの概要図に対して、下記のような環境構築を行なって紹介されている内容があります。ここでは、さまざまなData Source(csv、txt、Parquet、ORC など) から JSON 形式で S3 に保存され、そのデータが「構造化」レイヤーと呼ばれるパーティション化されたテーブル(Structured Tables)に挿入されます。そして、定期的にレポーティングテーブルとして週・月・年などのタイミングで作成および更新され、外部のBI Tools や、Starburst Galaxyの Query Editor によってSQL BI レポートとアドホックなクエリにより、必要に応じてベーステーブルに直接クエリを実行します。また、Starburst Galaxy コネクタにより、Data Sourceを始めとして様々なデータに対してコネクタを利用してアクセスします。
Starburst vs Snowflake
ここで、クラウドベースのデータレイクハウスの代表的なソリューションである Snowflake とStarburstの比較は興味がある方も多いと思います。以下の記事では Snowflake とStarburstについて比較がされています。
https://www.starburst.io/blog/snowflake-data-warehouse/
価格モデルについては、Snowflake は従量制の価格モデルを採用しており、ユーザーは保存するデータ量と消費するリソースに基づいて料金が請求されます。一方で、Starburst は容量ベースの価格モデルを採用しており、ユーザーは必要なリソースを前払いして行うため、計画が立てやすく、全体として価格が抑えらるメリットがあります。
パフォーマンスについてですが、Snowflake と Starburst はどちらも、高いパフォーマンスと大量のデータを処理できることで知られています。
この記事では特にTCO(Total Cost of Ownership:システム(製品やサービス)の導入から運用・管理、さらには利用終了までの総保有コスト)において Starburstが非常に優れているとされています。
ただし筆者の経験上は、Snowflake とStarburstが直接競合するケースは稀でそれぞれ得意なユースケースがあると感じています。高い性能が求められる領域では Snowflake、性能要件が厳しくなくTCOや導入時のコスト低減を図りたい場合は Starburstというように適所での使い分けが重要になると考えています。
まとめ
今回の記事では、データメッシュを実現する技術・プロダクトとして、Starbustについて紹介しました。今後、自社のデータ戦略のためにデータメッシュ等の設計思想・アーキテクチャを取り入れていくなかで実装や製品プラットフォームの選定の参考になればと思います。
お気軽にお問い合わせください
マイクロサービス・イベントドリブンについて
興味関心があり、ご相談があれば
以下よりお問い合わせください




