
【Event-Driven Architectureへの道】結果整合性にどのように向き合うか? データベース分割とビジネスインパクトへの対応

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
これまでに、【Event-Driven Architectureへの道】シリーズで記載した内容にもあるように、イベントドリブンアーキテクチャの導入により、パフォーマンス、スケーラビリティ、弾力性、拡張性、耐障害性、可用性、デプロイ単位の最小化、サービスごとに別の技術を採用できる、などの多くのメリットがあります。一方で、トレードオフとして、結果整合性の特性を考慮しサービスとシステムの設計をしていく必要があります。
一般的にマイクロサービスアーキテクチャでは、各マイクロサービス内でのローカルトランザクションを勧める一方で、グローバルトランザクション(分散トランザクション)を推奨していません。分散トランザクションを用いるとスケールが非常に難しく、また、各ドメイン毎のサービスを疎結合にすることを阻害するためです。スケールし疎結合のマイクロサービスアーキテクチャを作るには、分散トランザクションではなく、イベントドリブンアーキテクチャの幾つかのパターンを利用し複数のサービスを接続する必要があります。
データベースの分割
マイクロサービスアーキテクチャーでは、ドメイン毎にデータベースを分割することが前提になっています。データベースをどうやって分割するのかの疑問については、Database per serviceというパターンが一つの手法になります。
Database per serviceでは、例えば、機能AはデータベースAと直接データのやり取りを行い、データベースBへの接続方法やスキーマについては一切関知しないことを前提としています。機能Bも同様に、データベースAに依存しません。つまり、データベースはそれを必要とする機能毎に持たせようという考え方で、機能はデータベースとセットになります。他の機能との間でデータベースも疎結合が維持されます。
実際には機能Aと機能Bはデータベースが分かれていても、業務プロセスにおいて関係性があり整合性を取る必要があります。このため、機能毎にデータベースを分割する方法においては、整合性をどのように担保するかが重要になります。データベースが一つであれば、例えば、外部キーを用いてあるデータを別のデータと結び付け、参照先のデータが変更されれば、JOINを使うことで自動的に変更後のデータと結び付けることができます。
しかし、Database per service パターンでは、データベースは機能ごとに持つことが原則で、複数の機能が同じデータベースを参照することは許容しません。もし同じデータを複数の機能が保持する場合には、一方の機能がデータベースのデータを変更しても、もう片方の機能が持つデータは自動的には変更されません。このようなケースでは機能によって、同じデータなのに値が異なるという事態が起きてしまいます。
このようなデータベースの分割に伴う整合性の問題への解決法としては、一方のデータ変更をもう片方の機能に伝える方法があります。データベースのレプリケーションのような機能もありますが、別の方法として同じデータを持つデータベースの一つに変更が加えられた際にその変更をほかのデータベースにイベントとして伝えてデータの更新を行う方法があります。これは 非同期イベントドリブン通信 と呼ばれます。
データベースの分割がもたらす整合性の確保は非常に重要で、イベントドリブンアーキテクチャにおける検討・設計ポイントとしても非常に大きなポイントになります。更にイベントドリブンアーキテクチャでは結果整合性が前提になるため、結果整合性にどのように向き合うかが大きなポイントになります。
結果整合性のパターン
結果整合性はイベントドリブンアーキテクチャだけで発生する課題ではありません。ここでは、イベントドリブンアーキテクチャに限定せず結果整合性の主要な3つのパターンについて見ていきたいと思います。データソースやシステム間の結果整合性を実現する方法は昔から数多く存在します。主なパターンには、バックグラウンド同期パターン(バッチ処理)、リクエストベースのオーケストレーションパターン、イベントベースパターンがあります。
各パターンの説明のために、例として「カスタマーサービス」の業務システムを考えてみましょう。結果整合性で重要なポイントとしては、「① 業務フローに矛盾が出ないか」「② 影響やリスクがある場合にトレードオフとして許容できるか」も挙げられますので、このポイントも含めて見ていきます。
今回の例の「カスタマーサービス」の業務システムでは、顧客管理機能、顧客サポート機能、請求・決済管理機能の3つの機能(ドメイン)があります。
- 顧客管理機能:顧客の個人情報を管理する機能
- 顧客サポート管理機能:顧客が契約しているサポートプランなどの個別情報を管理する機能
- 請求・決済管理機能:契約している月額のサポートプランなどの料金を請求・支払いする機能
それぞれの機能は各々のデータベースのテーブルにデータを格納してます。
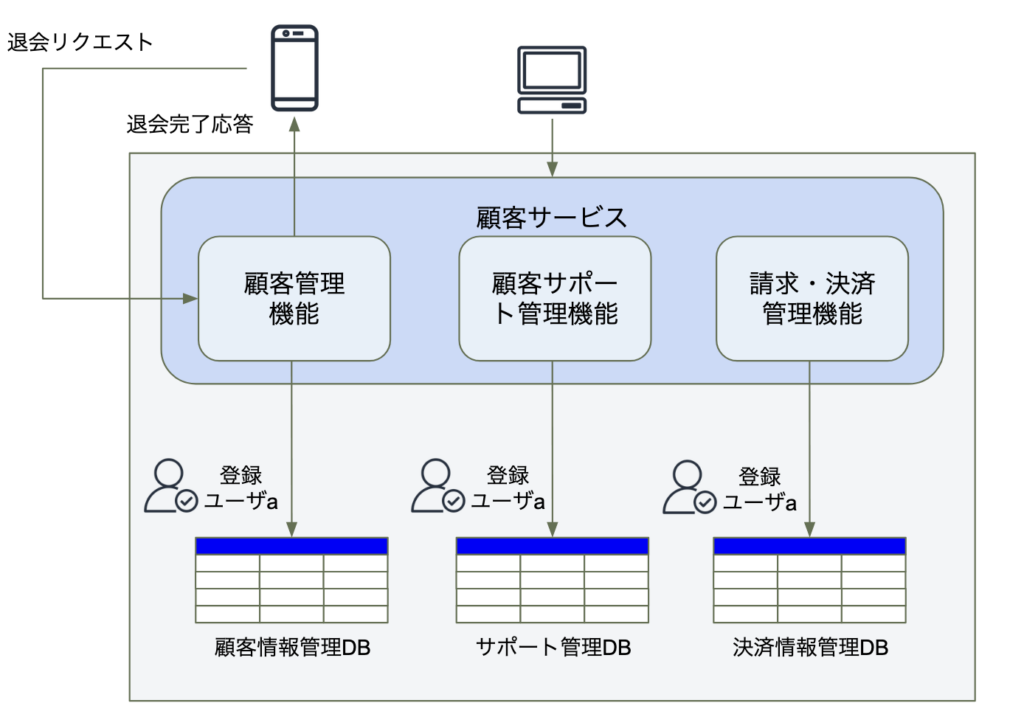
例えば、登録ユーザaがサービスから退会したい場合、顧客管理機能はユーザから退会要求を受け取り、ユーザの個人情報などを顧客情報管理DBから削除します。登録ユーザには正常に退会処理が完了したことを通知または画面反映しますが、サポート管理DBや決済情報管理DBには、サポートプランの個別情報や、請求・支払いの履歴情報などがまだ存在していることになります。要するに、ここですべてのデータを同期させるための整合性が必要になります。
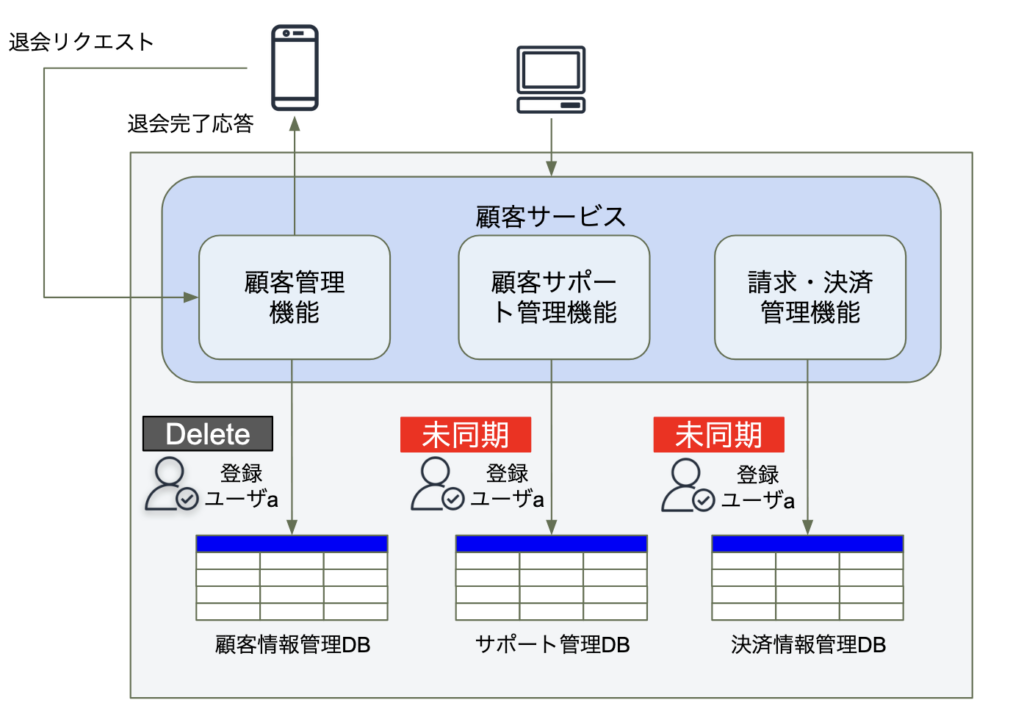
バックグラウンド同期パターン(バッチ処理)
バックグラウンド同期パターンでは、別の外部サービスやバッチ処理プロセスなどを使用して、各管理DBのテーブルを定期的にチェックまたは一定周期で、テーブル間の同期を実施します。このパターンを用いた場合は、各テーブルが結果的に整合するにあたりリアルタイム性はなく、バッチ処理プロセスが開始され完了するまでの時間を要することになります。バッチ処理と聞けば繁忙期でない時間を狙っての夜間のバッチなどが誰しもが経験するパターンではないでしょうか。
このパターンは、テーブルの結果整合性が保たれるまで長時間かかるので、これが許容できるのか?が焦点になります。短時間にバッチを完了させたい、という要望も出ることが多いですが、本当にそこまで必要でしょうか。登録ユーザaが退会しているため、登録ユーザaにとっては、サポート契約の情報や請求や決済の履歴情報に関しては即座の反映は必要ないと考えられます。このため長時間であれ結果整合性が合えば業務フローやユーザ体験からみた要求としては十分と言えます。
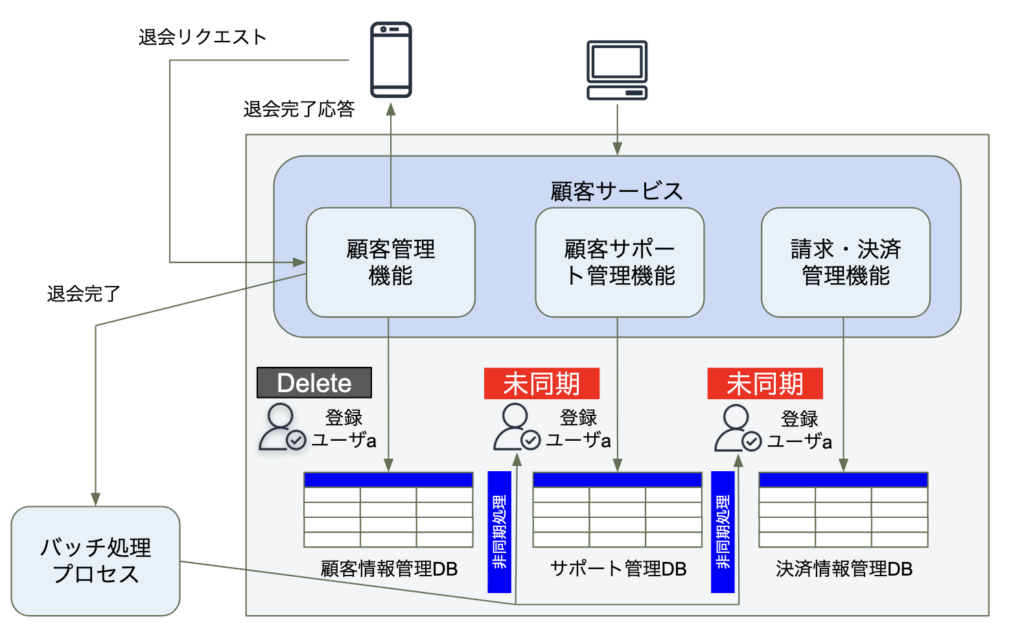
リクエストベースのオーケストレーションパターン
マイクロサービスアーキテクチャでの整合性を管理する手法としてよく求めがちな要求として、登録ユーザaの操作の流れの中で、処理フローの業務要求が終わるまでに、すべてのテーブルが同期されるようにすることがあげられます。(登録ユーザaから見た要求というよりは、システムを運営する企業が過剰に要求してしまうことが多く、それはそれで課題です。)
上記のような要求を実現する方法としては、リクエストベースのオーケストレーションパターンと呼ばれる方法が挙げられます。
オーケストレーションパターンを実現する例として、登録ユーザaに一番近い顧客管理機能が他の全てのサービスの分散トランザクションの管理を受け持つ方法があります。ただ、この方法は、顧客管理機能の責任範囲が膨大となり、機能・サービス間の密結合や同期的な依存関係が発生します。
この課題解決のためには、業務処理フローや、ビジネス要求用に専用のオーケストレーションサービスを用意する方法が挙げられます。この方法では、顧客管理機能を分散トランザクションの管理責任から解放し、分散して、それぞれの機能の責任でオーケストレーションサービスに任せることができます。
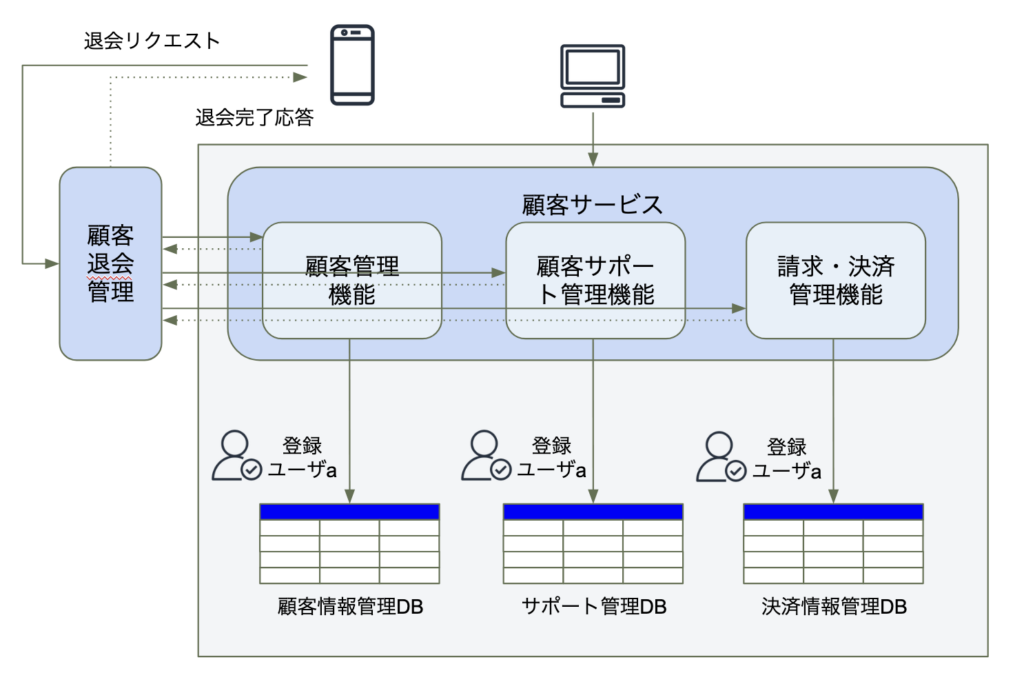
退会リクエストがオーケストレーターサービスによって受信されると、リクエスト・リプライのやり取りが実施されながら顧客管理機能から顧客情報管理DBに登録情報を削除し、その数秒後に、顧客サポート管理機能からサポート管理DBの登録情報を削除し、請求・決済管理機能から決済情報管理DBも同様となるシーケンスを実行することになります。顧客サポート管理機能や、請求・決済管理機能は、退会リクエストを処理して、数秒後にリクエストの処理が完了したリプライの確認応答を送信します。
オーケストレーションのアプローチには、応答性よりもデータの整合性を優先するというトレードオフが存在します。オーケストレーションサービスを追加すると、API機能呼び出しなどのサービスコール数が増える上に、オーケストレーターが呼び出す部分がシーケンシャルで行うと、通信にかかる追加が伸びていきレスポンス応答時間の許容も必要になります。
先ほど記載したバックグラウンド同期パターンとは異なり、リクエストベースのオーケストレーションパターンでは、ビジネス要求の間にマイクロサービス全体の分散トランザクションを処理しようとするため、全体のトランザクションを管理するオーケストレーターが必要です。オーケストレーターは、指定されたビジネスプロセスの実行、エラー処理を処理するのに必要な機能を持つ必要があります。
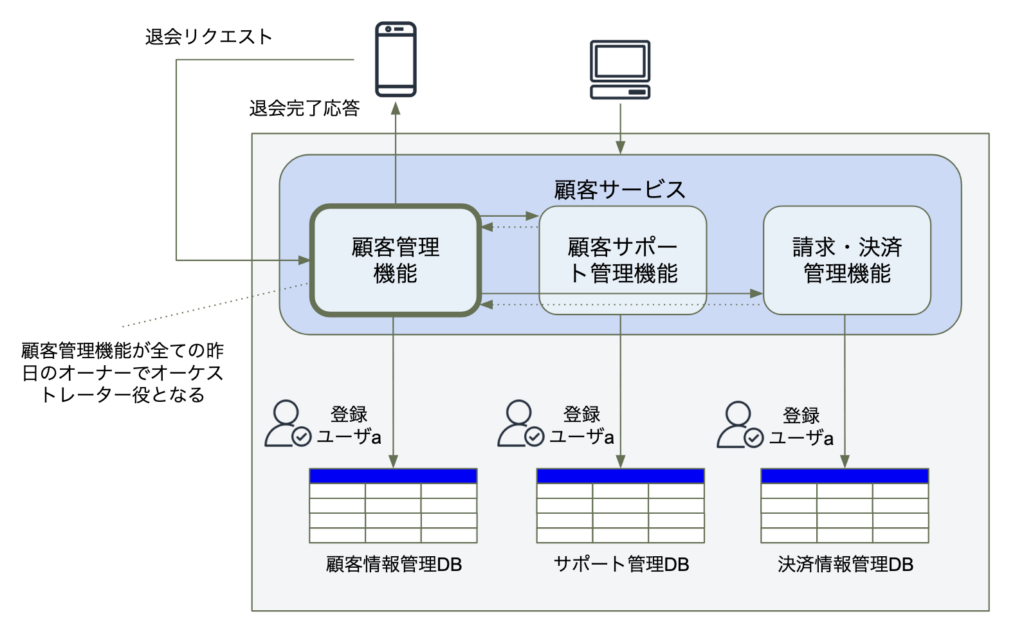
イベントベースパターン
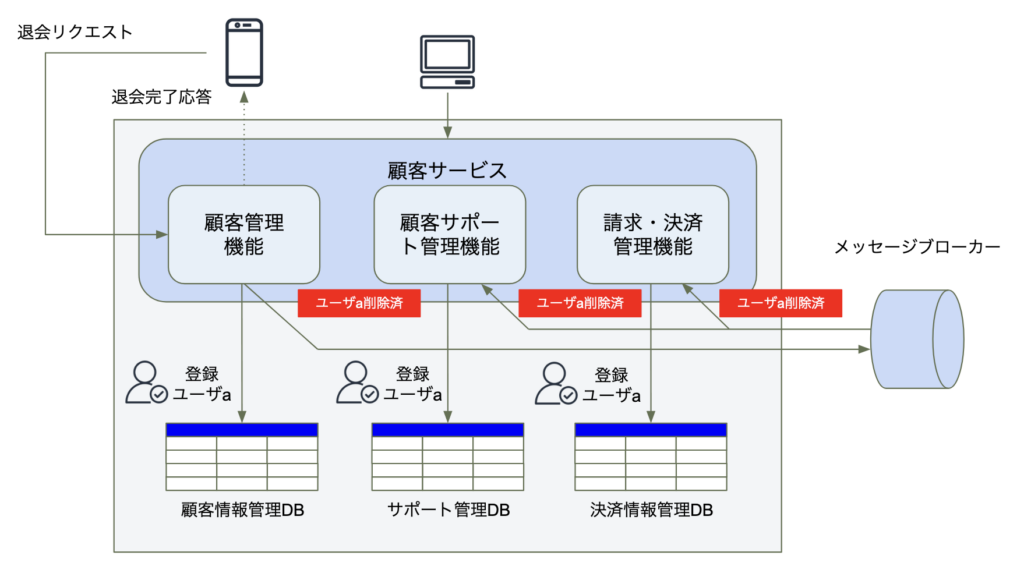
イベントベースパターンは、マイクロサービス向けの分散アーキテクチャのパターンの1つです。このパターンでは、非同期のパブリッシュ/サブスクライブ(pub/sub)メッセージングモデルが採用され、イベント(「登録ユーザa退会」など)やコマンドメッセージ(「登録ユーザaの退会」など)をトピックやイベントストリームにパブリッシュ(投稿)します。分散トランザクションに関わるサービスは、特定のイベントをサブスクライブ(待ち受け)し、イベント発生時に処理を行います。
非同期のメッセージ処理は並列かつ分離されているため、通常データが結果的に整合するまでの時間はほぼリアルタイムに近くなります。このパターンでは、サービスは互いに切り離し独立することができます。
結果整合性のビジネスインパクト
ここまでは整合性のパターンや、データベース分割の重要性などに触れてきましたが、ここでは結果整合性のビジネスインパクトについて考えていきます。
マイクロサービスアーキテクチャをイベントドリブンアーキテクチャにしていく過程で、業務システムの役割の明確化や、結果整合性における不都合や、不整合について洗い出し、ビジネスインパクトが許容できるかを検討する必要があります。例えば、在庫管理システムなどでの不整合について、以下の例を元に考えてみたいと思います。ここでは、一旦それぞれを仮に、許容できないもの、できるものと分類していますが、実際にはどうでしょうか。
許容できないものは、ビジネスインパクトが本当にあるでしょうか。中には、時間的制約を短時間にすれば許容できるものが出てくるものもあるのではないでしょうか。
許容できない不整合(高優先度)例:
- 在庫の負数表示: 在庫管理システムが負の在庫数を表示し、実際には在庫がない場合。これは在庫切れの商品が注文可能と表示され、顧客に不満をもたらす。
- 在庫更新の遅延: 在庫が減少したにもかかわらず、システムが在庫数を適切に更新しない場合。これにより、商品が実際には売り切れているにもかかわらず、顧客が注文を受け付けられる可能性がある。
- 複数の注文での在庫競合: 同じ商品に対して複数の注文が同時に入る場合、在庫が不足しているにもかかわらず、すべての注文が受け付けられる不整合。これにより、商品が顧客に提供できなくなり、信頼性が低下する。
- 在庫品目の混同: 在庫管理システムが似た名前の商品を混同する場合。これにより、顧客が誤った商品を受け取る可能性があり、返品や不満が生じる。
- 出荷と在庫の同時更新: 在庫が出荷処理と同時に更新されず、商品が重複して発送される不整合。これはコストの増加と顧客の混乱を引き起こす。
- 在庫の二重処理: 在庫管理システムが同じ商品に対して複数回の在庫減少処理を実行し、実際の在庫よりも多くの在庫が減少する不整合。これは在庫数が過度に減少し、実際には在庫がある商品が表示されなくなったり、顧客に誤った情報が提供されたりする可能性があります。
許容できる不整合(低優先度)例:
- 在庫更新の一時的な遅延: 在庫数の更新に一時的な遅延があるが、顧客にはほとんど影響を与えない。在庫情報は遅れて表示されるが、商品は利用可能。
- 一部の在庫情報の非同期更新: 在庫管理システムの一部の部分が同期されない場合。一部の商品の在庫情報が遅れて更新されるが、主要な商品は正確に表示される。
- 在庫変動の一時的な不一致: 在庫数が一時的に変動するが、最終的に正確に反映される。顧客は一時的に在庫切れの表示を見るが、後で更新される。
- 複数の在庫更新ソース: 在庫情報が複数のソースから更新され、同期にわずかな遅延がある場合。商品の在庫情報がやや不安定だが、適切な処理で更新される。
- 在庫数の細かい不一致: 在庫数が一時的にわずかに不一致があるが、実際の在庫との差異は小さく、一般的には無視できる。
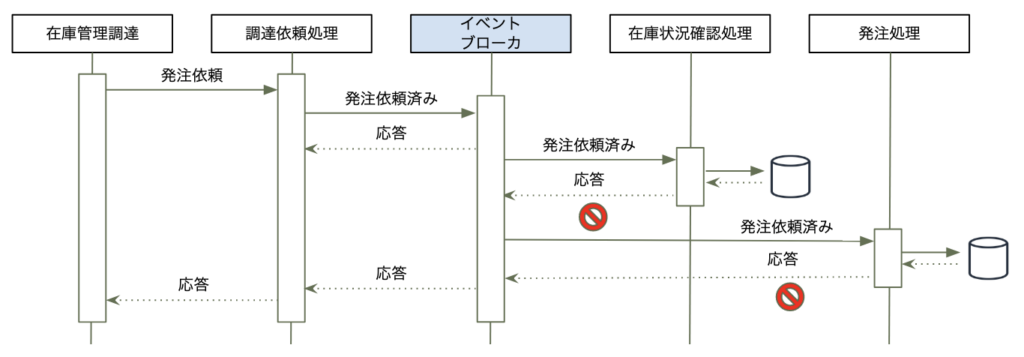
許容できない不整合の中に記載した在庫の二重処理に目を向けると以下の原因が挙げられます。
在庫の二重処理の一般的な原因 例:
- イベントの重複発生:
- 原因: イベントの送信や受信中にネットワークの遅延やエラー、システムの再起動などが発生すると、同じイベントが複数回発生する。
- 詳細: 例えば、在庫の減少を示すイベントが送信されたが、送信完了の確認が受信側に返却されず、再送信された場合などが考えらる。この結果、同じ在庫減少のイベントが複数回処理され、在庫数が過度に減少してしまう可能性がある。
- 並行処理による競合:
- 原因: イベント駆動アーキテクチャでは、複数のスレッドやプロセスが同時にイベント処理を試行することがあります。これにより、競合状態が発生し、同じ在庫アイテムに対する操作が同時に実行される。
- 詳細: 例えば、複数の注文が同時に在庫アイテムを減少させようとする場合、在庫が足りない状況でも、競合が発生してしまうことがあります。その結果、在庫数が実際よりも少なくなり、品切れの可能性が高まります。
- 非同期通信のタイミング問題:
- 原因: イベント駆動アーキテクチャでは、非同期通信が一般的です。送信側と受信側のイベント処理のタイミングが異なると、予期せぬ順序でイベントが処理されることがあります。
- 詳細: 例えば、在庫数を確認するイベントが在庫減少のイベントよりも早く到着し、在庫数を確認した段階では十分な在庫があったと判断しても、後から到着した在庫減少のイベントにより在庫が不足してしまうことが考えられます。
上記の内容は、いずれも類似してますが、このような障害などに起因して重複してイベントを受信した場合の対応と検出方法などを導入する仕組みも一緒に構築しておくことで対応できます。
二重処理の原因については、排除できないケースも多いため、イベント駆動アーキテクチャにしていく中でも、冪等性の担保と、順序性を排除する方法、また、その検出方法も一緒に検討していく必要があります。
冪等性の担保については、記載の通り、イベントが複数回発生する可能性があることを前提としてアプリケーションの実装を行う必要があります。例えば、既に生成するデータが存在していないかのチェックだったり、処理の状態を管理してチェックする処理を入れるなどです。
在庫の二重処理を検出する方法:
- イベントの重複発生:
- 検出方法:
- イベントIDの利用: イベントに一意のIDを割り当て、処理済みのイベントIDを記録します。同じIDが既に処理された場合、重複として検出し、処理をスキップします。
- 重複チェック: 例えば、各受信者が受け取る前に、イベントを一時的にバッファリングし、同じイベントが再度届かないようにチェックします。
- 検出方法:
- 並行処理による競合:
- 検出方法:
- バージョン管理: 各在庫アイテムにバージョン番号を導入します。更新ごとにバージョン番号が増加し、競合が発生した場合、バージョン番号を比較して競合を検出します。バージョン番号が異なる場合、競合と見なし、適切な処理を行います。
- イベントストリームのタイムスタンプ: イベントにタイムスタンプを含め、競合が発生した場合、最新のタイムスタンプを持つイベントを優先し、他のイベントを無視します。
- 検出方法:
- 非同期通信のタイミング問題:
- 検出方法:
- タイムスタンプの比較: イベントのタイムスタンプを比較して、古いイベントを無視するか、新しいイベントを選択します。
- ウィンドウ処理: イベントを一時的にウィンドウ内にバッファリングし、適切なタイムウィンドウ内のイベントのみを処理します。
- 検出方法:
これらの実装方法は、二重処理を検出するための有効な手段で、システムの要件や特定のビジネスケースに応じて調整できますし、設計段階で適切な検出メカニズムを導入すれば、重複処理を最小限に抑えることが重要になってきます。
結果整合性とどのように向き合うか?
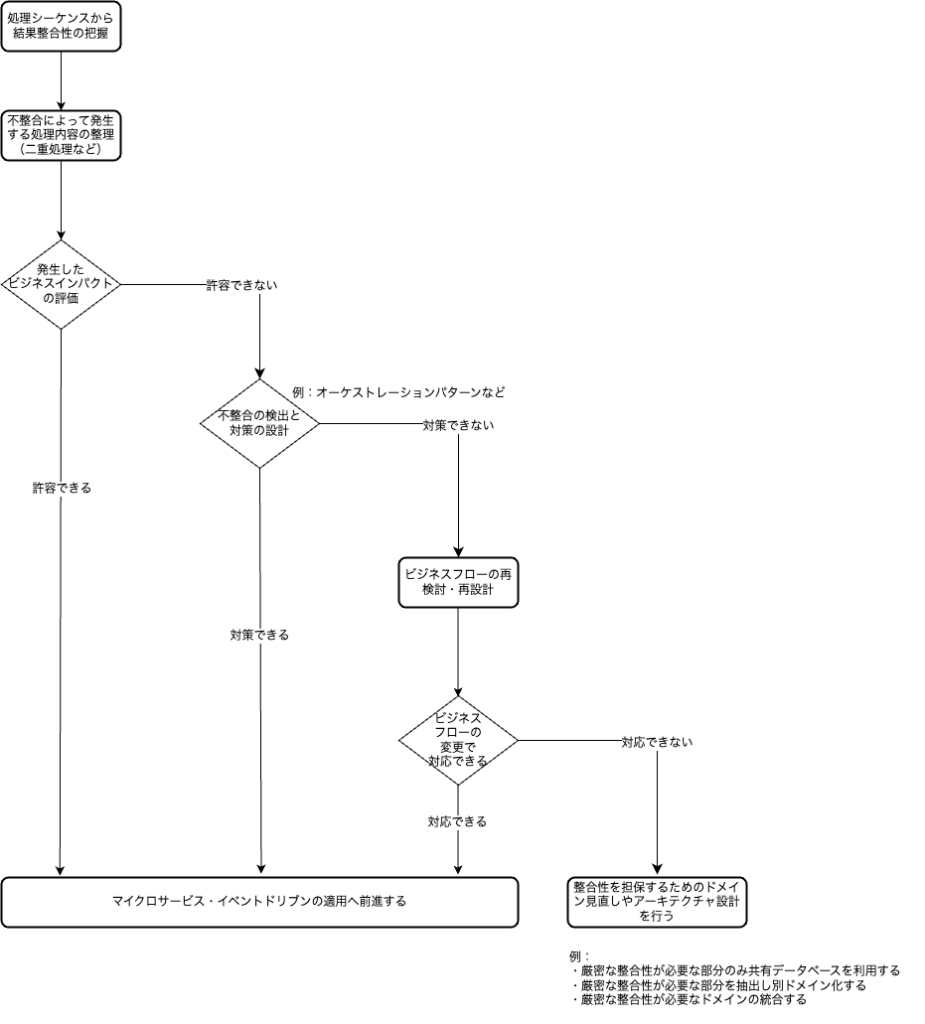
ここまで述べたようにイベントドリブンアーキテクチャの適用は結果整合性の影響の整理や二重処理のような不整合の発生ケースとビジネスインパクトを整理し、対処していくかが重要となります。以下のフローチャートで示すように、ビジネスインパクトの評価、不整合の検出と対策の設計、ビジネスフローの再検討・再設計も含めてアプローチすると良いでしょう。
まとめ
今回の記事では、マイクロサービスアーキテクチャの結果整合性に焦点を当て、バックグラウンド同期、リクエストベースのオーケストレーション、イベントベースの結果整合性パターンを説明しました。また、データベースの分割とその課題についても触れ、結果整合性への対応は分散システム設計において重要であり、適切なパターンとデータベース設計が必要なことを記載しました。
結果整合性のビジネスインパクトについては、許容できない不整合(高優先度)と許容できる不整合(低優先度)に整理し対策を立てる必要があります。例として記載した在庫の二重処理のようなケースが特に注目すべき不整合であり、イベントの重複発生、並行処理による競合、非同期通信のタイミング問題などの原因に対してそれらを検出する対策を取り入れながら、イベントドリブンアーキテクチャを取り入れていくことが可能であることを記載しました。
結果整合性とどのように向き合うかはイベントドリブンアーキテクチャ導入の肝になる部分とも言えます。ビジネスインパクトの評価、不整合の検出と対策の設計、ビジネスフローの再検討・再設計など対策を整理して対応していくことで、導入の検討を円滑に進めることができるのではないでしょうか。
今回の記事が皆さんの「Event-Driven Architecture」の導入につながれば大変幸いです。
Author
クリエーションライン株式会社 取締役 兼 最高技術責任者(CTO)
クラウド黎明期からオープンなクラウド技術に取り組み、実際に大規模クラウドのアーキテクチャ設計・実装・運用なども行う。2018年からはクリエーションラインのお客様と一緒にチームを立ち上げ Factory IoTのデータ基盤、MaaSデータ基盤、5G IoT基盤、ロジスティックのアプリ・データ基盤などなど多数のアジャイル開発プロジェクトを立ち上げ・推進。
現在はモバイルアプリ開発やAI/機械学習、MLOps基盤、トレーニング開発、お金の計算、交通整理など幅広く関わる。
将来的にはウェアラブル、メタバース、ブレインマシンインターフェイス等のヒューマンインターフェイスに携わりたい。



