
[資料ダウンロード]TigerGraphを徹底検証してみた #tigergraph

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
1.グラフDB(GraphDB)の仲間、TigerGraphが気になって検証してみました。
https://www.tigergraph.com/
https://docs.tigergraph.com/
同タイプのDBランキングではトップ10にも入っていないですが、何人かに「良いかも」と言われ、かつ、Neo4jユーザー会や社内チャネルでもキーワードとして登場したので、実態が知りたくなりました。
同タイプトップのNeo4jと比較するつもりはなく、淡々とTigerGraphを使ってみることにします。
以下、検証結果をまとめたレポートです。
2.概要
2.1,グラフDBとは
グラフDBとは、リレーショナルデータベースでは処理困難な、非常に複雑なネットワーク状のデータ処理に特化したデータベースです。グラフDBのデータモデルは、文字通り、グラフ(頂点と辺)です。RDBと違って結合関係を永続化します。辺(WRITE)の前後に始点と終点のIDを持たせて、インデックスのような働きをさせています(トラバーサルと言います)。
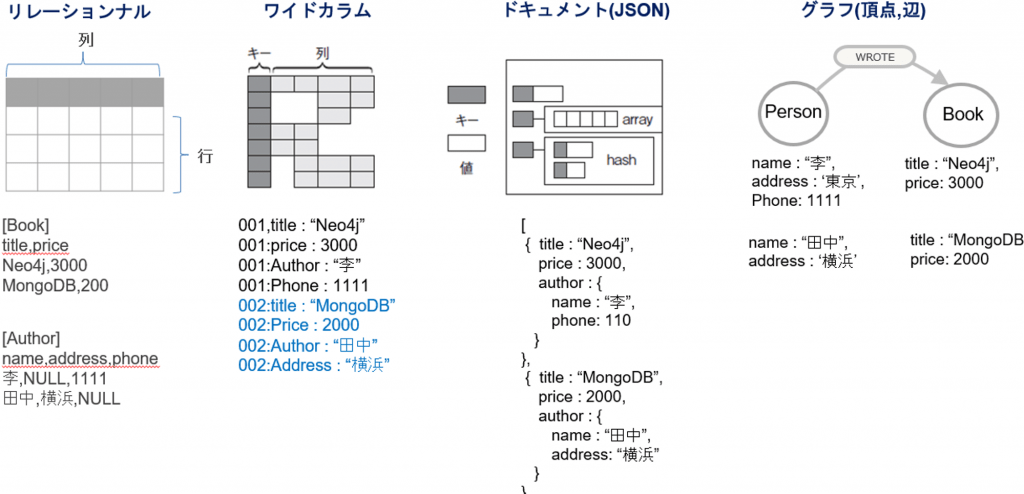
RDBのように結合関係を紐解く必要がないために、とても複雑な処理を簡明な構文で書け、高速処理も可能です。
データモデルがグラフであるために自由自在にデータが持て、データベース設計がとても簡単です。
エンジニアでなくても、自分が担当している業務のフローは書けると思います。
それが、そのままデータベースのスキーマになります。
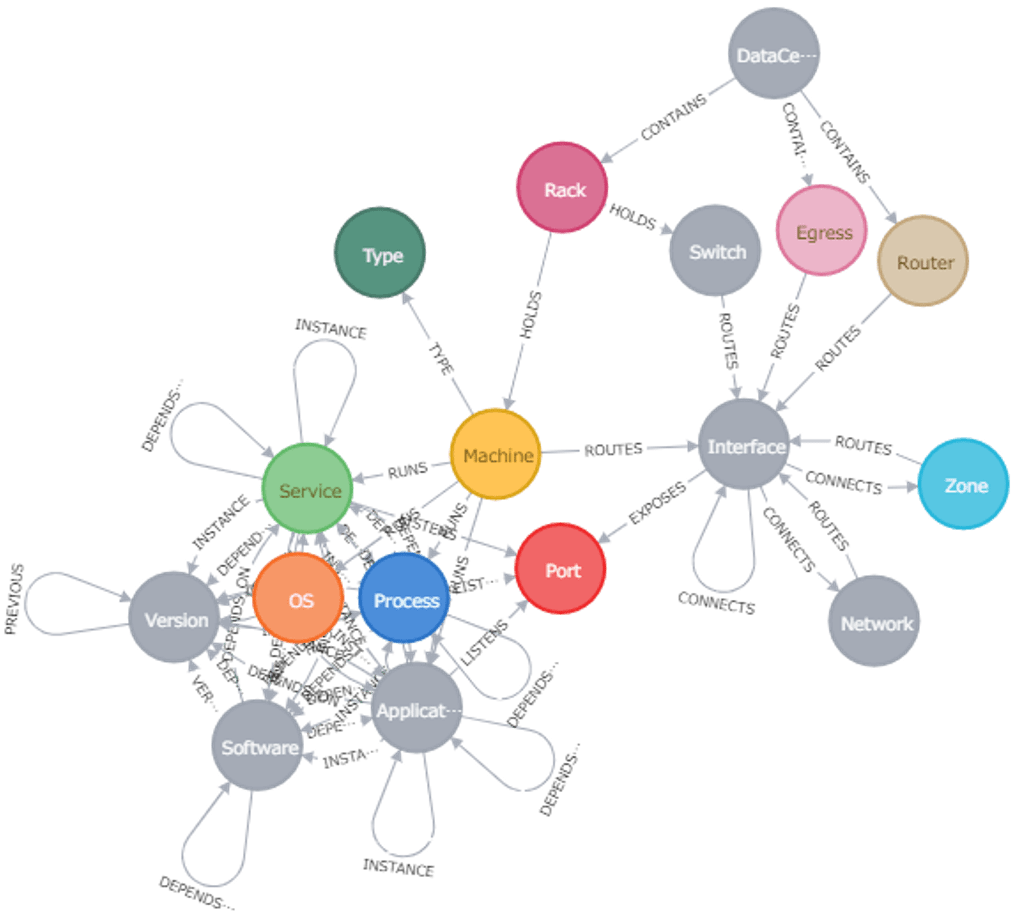
・このスキーマは、「ネットワーク&ITマネジメント」のデータモデルです。
・出所→https://neo4j.com/sandbox/
グラフDBは、全てのデータが本質的にネットワーク構造であるという思想に基づいています。そこにあるのは、データ間の繋がりの密度が高いか低いか、階層か深いか浅いか、だけの問題です。そのなかでグラフDBは、データ間の繋がりが細かく、階層が深いデータ処理に向いています。
今世紀に入って、非常に複雑なネットワーク状のデータが急激に増えつつあります。従来のリレーショナルデータベースで、そのようなデータ処理に当たると、いわゆる正規化ではデータベース設計が困難だったり、SQLではパフォーマンスが出ない、そもそもSQLでは書ききれないなどの問題が発生します(join-bombの問題)。グラフDBはそのような複雑なネットワーク状のデータ処理に最適化されています。
・1つのSQL文で結合が10個以上発生するような処理
・SQLでは書き切れないような処理(遅くて困っているようなクエリ含めて)
・そもそも、複雑すぎてデータベース設計自体が困難
但し、この内容はグラフDBのトップランナーであるNeo4jに基づく記述です。
資料の続きは、こちらからご覧頂けます。


|
目次
|
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



