
Cypher Query Language(QL)-初級編 2015 #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本記事は、「Cypherクエリの基礎 2020」にリニューアルしました。
Neo4jでグラフ構造のデータ処理を行う時は、SQLライクなCypher QL(Cypher:サイファーと読む)を利用します。今回は、Cypher QLを利用したデータの登録、更新、検索、削除など、最も基本的なデータ操作方法を紹介します。
関連記事-CL-Lab
Neo4j-グラフデータベースとは
Cypher Query Language(QL)-構成要素編
Cypher Query Language(QL)-初級編
Neo4j-大量データの読み込み
関連記事-Qiita
WindowsでNeo4jを使ってみる
MacでNeo4jを使ってみる
SoftLayerでNeo4jを使ってみる
AWSでNeo4jを使ってみる
Neo4jウェブインターフェースを使い倒す
Cypher QLとは
Cypher QLは、Noe4jのグラフ構造のデータ処理を行うために開発されたSQLライクなクエリ言語です。前回の記事で、Cypher QLの多様な構成要素を紹介していますが、おそらく、それを見ただけでは、他のNoSQL系のクエリ言語と違ってジョインも出来るし、SQLライクなことが色々出来そうだが、その本当の実力のほどは?、というのが正直な感想かも知れません。 しかし、これから紹介するCypher QLは、あらゆるクエリ言語系で最高頭脳であると言っても過言ではありません。Cypher QLは、関係型データベースとドキュメント型データベースのデータ処理能力を合わせた以上の多能性を持っています。スキーマレスでデータを扱い、SQLを超えるデータ処理能力を待ち、トランザクション処理などのデータ管理能力をも備えているのがCypher QLです。
Cypher QLの実行ツール
Cypher QLを実行する方法は、以下のように多様です。今回の演習では、手軽に利用できるNeo4jウェブインターフェースを使っています。
Neo4jウェブインターフェース:Neo4j標準のWebアプリケーションです。強力なGUIでグラフ表現ができるのが特徴です。インタラクティブな利用のために提供しています。
Neo4jシェル:LinuxやMacで使えるインターフェースです。bin/neo4j-shellを実行すると起動します。これは、Neo4jでバッチ処理を行うときに有効に利用できます。
REST API:Neo4jサーバは、REST APIを提供しています。Curlや様々な言語を利用してCypher QLを実行できます。
Neo4jドライバー:Java/.NET/JavaScript/Python/Ruby/PHP/R/Go/Clojure/Perl/Haskellなどの言語でCypher QLを操作できます。
Cypher QLからみたNeo4jのデータ構造
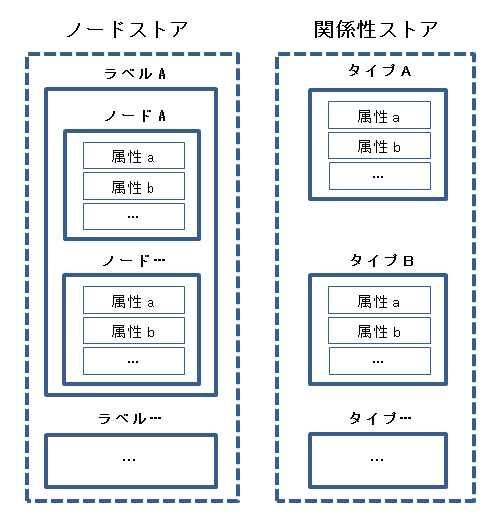
以下の図は、Cypherクエリの理解を助けるために、Cypher QLがどのような論理単位でデータ処理を行っているのか、筆者の洞察をイメージ化したものです。Neo4jは、データとデータ間の関係性を明確に分離しています。ノードストアの構成は、関係型データベースで言えば、同じラベルを持ったノード群がテーブルのような役割をし、ノードが持っている属性がレコードのような役割をします。関係性ストアは、タイプという名称を持ち、さらにタイプが属性をもつことで関係の多様性を表現します。このようにNeo4jでは、実体になるデータと実体との関係を表すデータを明確に分離することで、とても複雑なデータパターンの表現でも上手に扱えるようにしています。なお、事前にいかなる構造の定義も必要ありません。機能的には、関係型データベースやドキュメント型データベース、キーバリュー型データベースの長所を合わせ持っています。単独のデータとして扱う最小単位はノードであり、関係性はノードとノードの間でのみ存在します。波線で取り囲んでいるノードストアと関係性ストアは、テーブルスペースのようなものですが、Cypher QLのシンタックスには登場しません。これは、Neo4j DBMS(DataBase Management System)で自動管理してくれます。
Cypher QL演習
これから紹介するCypherクエリは、初めてNeo4jを使う人のために、Neo4jマニュアルを参考にしながらも、筆者独自の構成をしています。
参考資料
http://neo4j.com/docs/milestone/tutorials.html
http://neo4j.com/docs/milestone/cypher-query-lang.html
基本書式
データパターンの登録、更新、削除
CREATE [DELETE]:ノードや関係性の登録、削除を行います。
SET[REMOVE] :ノードや関係性に対する属性の登録、更新、削除を行います。
MERGE:データパターンが存在すれば更新し、存在しなければ追加します。
データパターンの検索、フィルター
MATCH:ノードや関係性の組み合わせのなかで、ある種のデータパターンが存在するのか、問い合わせを行います。
WHERE: 問い合わせの結果値に対して条件文を書き、データパターンのフィルターを行います。
RETURN:CREATEやMARGE、MATCHなどの最終的な結果値を返す文です。
事前に知っておくと便利なCypherクエリ
以下の構文を知っておく、Cypher QLの習得に非常に役に立ちます。
すべてのノードを検索
次のCypherクエリは、すべてのデータバターンを表示します。
MATCH (n) OPTIONAL MATCH (n)-[r]-()
RETURN n,r
MATCH (n): すべてのノードという意味になります。(n)は、すべてのノードを意味する識別子です。識別子はCypherクエリのなかでデータの受け渡しに使います。
OPTIONAL MATCH:この文を付けることで、関係性を持つノードと関係性持たないノードの両方が対象になります。この文を省略すると、関係性を持たないノードは、検索対象外になってしまいます。
(n)-[r]-() : (ノード)-[関係性]-(ノード)の意味で、方向を問わず、ノードとノードの間で何等かの関係性を持つすべてのデータパターンという表現です。
RETURN n, r:検索したデータパターンを識別子を通して返します。識別子であるnとrの中身はJSON形式のリストやマップです。
すべてのノードと関係性の検索は、簡単に次のようなCypherクエリを使うこともできます。
MATCH n RETURN n
すべてのノード削除
次のCypherクエリは、すべてのノードを削除します。色々試しているうちにすべてを削除する必要性が度々出てきます。
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
DELETE:データパターンを返さずに削除します。
属性を持たないノードの検索と削除
次のようなCypherクエリでノードを作った場合、属性が存在しないノードが作られてしまいます。このようなノードは、ノードの名称を示す属性が存在しないために、Cypher QLの初心者には、とても扱いにくいです。
CREATE (person:Person)
RETURN person
Added 1 label, created 1 node, returned 1 row in 254 ms
次のように検索すると、「:Person」というラベルのすべてのノードが結果値として返ってきます。ノード数が多い場合には、どれなのか特定が難しいです。
MATCH (person:Person)
RETURN person
同ラベル(:Person)のなかの他のノードに属性が存在する場合、その属性を利用して検索します。上記のように存在しない属性キーの値は、NULLが返ってくるので対象のノードが特定できます。
MATCH (person:Person) WHERE person.name IS NULL
RETURN id(person), person.name, person.name IS NULL

id(person):内部情報であるノードのIDを表示します。
person.name:存在しない属性キーの値は、NULLが返ってきます
person.name IS NULL:結果値が正しいですから、TRUEとなります。
上記のCypherクエリには、思わぬ落とし穴があります。次のようにNAMEの変わりにNAMAEのように、本来(:Person)ラベルのどこにも存在しないはずの属性キーで検索しても、NULLが返ってきます。Cypher QLは、存在することに対して、存在しないことも一つのパターンとして扱っているためです。これは決して困ったことではありません。特徴を理解していると、色んな場面で有効に活用することができます。
MATCH (person:Person) WHERE person.namae IS NULL RETURN id(person), person.namae, person.namae
削除は、RETURNの代わりにDELETEを使います。
ラベルも属性も持たないノードの検索と削除
次のようなCypherクエリでノードを作ってしまった場合、ラベルも属性が存在しないノードが作られてしまいます。
CREATE n RETURN n
Created 1 node, returned 1 row in 225 ms.
このようなノードは、ラベルのヘッダがNULLのデータパターンとして検索します。
MATCH n WHERE {label:head(labels(n))}={label:null}
RETURN id(n), {label:head(labels(n))}

{label:head(labels(n))}={label:null}:ラベルのヘッダがNULLであるデータパターンをフィルターしています。
削除は、RETURNの変わりにDELETEを使います。
ノードの処理
ここでは、ノードの登録と削除、ノード属性の追加、変更、検索、削除などをやってみます。
ノードの登録
ハリウッド映画の大ヒット作であるマトリックスをノードとして登録してみます。
CREATE (movie:Movie { title:"The Matrix",released:1997 })
CREATE (movie:Movie{}):CREATE (識別子:ラベル{ })は、ノード登録の基本書式です。英語で表記するときは、ラベルの先頭の文字を大文字にします。同ラベルが付いているノードグループは、テーブルのような役割を果たします。
{ title:"The Matrix",released:1997 }:{キー:バリュー}は、属性の基本書式です。複数登録するときは、コンマで区切ります。「"The Matrix"」、「released:1997」のように文字タイプ、数字タイプなどを設定できます。属性は、ノードの名称だけではなく、一意性の制約やインデックス、ノードが持つべき様々な情報を「キー:バリュー」の書式で持つことができます。
ノードの検索
上記のCypherクエリは、RETURN文を指定していないので、戻り値が表示されないはずです。次のようなCypherクエリで結果を検索してみます。
MATCH (movie:Movie { title:"The Matrix"})
RETURN movie
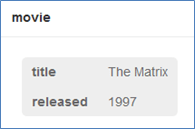
MATCH (m:Movie { title:"The Matrix"}):データパターンが一致するものを検索します。これは、SQLで言えば、SELECT文にWHEREで映画名をフィルターしたような結果です。
データパターンが1個のときは、次のようなCypherクエリでも結果は同じです。しかし、ノードが多くなると、「Movieというラベルが付いたノードすべて」という結果になってしまいます。
MATCH (movie:Movie)
RETURN movie
ノード属性の更新
上記で登録したノードの属性を更新してみます。ここでは、タイトルを大文字にしてみます。
MATCH (movie:Movie {title:"The Matrix"})
SET movie.title="THE MATRIX"
RETURN movie.title, movie.released
結果は、次のとおりです。

SET:ノードの属性を更新するか、追加するときに使います。キーが一致すれば上書きし、一致するキーが存在しなければ追加します。
このCypherクエリは、次のように書くこともできます。今回は、データパターンが一致するものを上書きしてみます。大文字のタイトルを元に戻します。
MATCH (movie:Movie)
WHERE movie.title="THE MATRIX"
SET movie.title="The Matrix"
RETURN movie.title, movie.released
次のように、タイトルが元に戻りました。

WHERE movie.title="THE MATRIX": WHERE文では、「識別子.属性」の書式でデータパターンをフィルターするために様々な演算子が使えます。
ノード属性の追加
現在、映画マトリックスには、「titleとreleased」の2つの属性しか存在しません。ここに属性を追加してみます。
MATCH (movie:Movie {title:"The Matrix"})
SET movie.japanese="マトリックス"
RETURN movie.title, movie.japanese, movie.released

日本語のタイトルが追加されました。すでに説明しているように、SET文では属性のキーが存在しなければ追加します。
ノード属性の削除
前項で追加した日本語のタイトルを削除してみます。
MATCH (movie:Movie {title:"The Matrix"})
REMOVE movie.japanese
RETURN movie
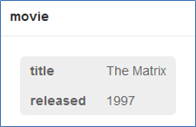
日本語のタイトルが消えました。
「識別子.属性」の書式ではなく、「識別子」で戻り値をみると、ノードに存在しているすべての属性が確認できます。「識別子.属性」の書式を使うと、CypherクエリはマッチしないパターンということでNULLを返してきます。属性が存在しなくても、怒られるのではなく、NULLが返ってくるために、キーは残っているのか、という疑問に落ちいてしまいます。
関係性の処理
関係性のタイプ登録
まず、ノードを用意します。次は、1構文のCypherクエリとして処理されます。
CREATE (person:Person { name:"Keanu Reeves", born:1964 })
CREATE (movie:Movie { title:"The Matrix", released:1997 })
RETURN person,movie

俳優と映画を登録しましたが、関係性は定義されていません。グラフ表現としては、次のようなパターンになります。

「RETURN 識別子」に表現することと、「RETURN 識別子.属性」に表現することの間では、大きな差があります。グラフの表現ができるのは、「RETURN 識別子」の書式にした場合のみです。
関係性を設定してみます。関係性を設定するということは、実体との間で、関係のタイプ(名称)と方向を決めることです。
MATCH (person:Person { name:"Keanu Reeves"}),(movie:Movie { title:"The Matrix" })
MERGE (person)-[roles:ACTED_IN]->(movie)
RETURN person, movie
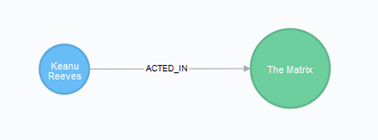
MATCH (person:Person { name:"Keanu Reeves"}),(movie:Movie { title:"The Matrix" }):MATCH (ラベル{属性})が書式。同ラベルのノードで属性が一致するデータパターンを検索します。このようにコンマ区切りで、複数のラベルを並べることができます。
MERGE (person)-[roles:ACTED_IN]->(movie):MATCHで検索したデータパターンのノード間で「出演した」というタイプ、方向は「人から映画」です。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



