
【初級者向け】ネイティブと非ネイティブのグラフデータベースの違いとは #neo4j

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本ブログは、Neo4j社のブログで2018年12月18日に公開された「Graph Databases for Beginners: Native vs. Non-Native Graph Technology」の日本語翻訳です。

「多芸は無芸」というよく知られたことわざがあります。
その意味するところは、あらゆる事柄で一流になろうと試みれば、結局は多くの事柄で二流にしかなれないのが普通であり、特に何一つ極められない、というものです。ソフトウェア、テクノロジー、そしてグラフデータベースも例外ではありません。
バッチやトランザクションのワークロードの処理、メモリやディスクの利用、SQLやXMLの利用、グラフデータやドキュメントデータの保存など、種類の異なるさまざまな用途にデータベースは対応します。
データベース管理システム(DBMS)を開発する場合、どのようなケースを対象にデータベースを最適化するべきか、開発チームは早期に判断する必要があります。それは、そのDBMSがさまざまな種類のタスクをどれほどうまく扱えるのかを決めることを意味します。(それぞれのDBMSが何が得意で、何に対応でき、何が不得意なのかを決めるのです。)
結果として、グラフデータベースの世界には、ネイティブのグラフテクノロジーとして知られる、「グラフファースト」に設計されたテクノロジーと、非ネイティブのグラフテクノロジーに分類される、後付けでグラフを付与したデータベースが存在します。
ネイティブのグラフデータベースの場合、グラフデータの保存と処理のアーキテクチャがそうでないデータベースと大きく異なります。当然ながら、ネイティブのテクノロジーは、比較的クエリの処理スピードが速く、大規模な拡張が可能であり、(つまりは、データセットのサイズが大きくなってもクエリの処理速度が変わらない)、処理が効率的で、必要なハードウェアが少なくて済みます。一方で、非ネイティブのグラフデータベースでは、そのようなメリットはあまり期待できません。
このような違いを理解することが、きわめて重要です。データベースのライセンスの購入を新たに検討している場合はなおさらです。
このブログでは、ネイティブのグラフデータベーステクノロジーを非ネイティブのグラフデータベーステクノロジーと区別する主な特性と、データベースのパフォーマンスにおいて、それらが重要な役割を果す理由について取り上げます。
概要:ネイティブのグラフテクノロジーで「グラフファースト」が意味すること
ネイティブのグラフテクノロジーをそうでないグラフテクノロジーと区別する要素が主に2つ存在します。データの保存(ストレージ)と処理手法(プロセス)です。
データ保存に使うグラフストレージとは通常、グラフデータを保存するデータベースの基盤を意味します。グラフ型のデータを保存することに特化した開発が行われている場合、そのグラフストレージは、ネイティブのグラフストレージと呼ばれます。ネイティブのグラフストレージを使用するグラフデータベースは、あらゆる点でグラフ処理のための最適化がなされており、ノードとリレーションシップを近接してストレージに書き込むことで効率的なデータの保存を可能にしています。
リレーショナルデータベース、ワイドカラムデータベース、他のNoSQLデータベースなどの外部ソースをストレージとして利用している場合、そのグラフストレージは非ネイティブのグラフストレージに分類されます。これらのデータベースもノードとリレーションシップのデータを保存しますが、それらのデータは遠く引き離されて書き込まれる可能性があります。このような非ネイティブのアプローチでは、ストレージレイヤーがグラフ処理のために最適化されていないため、遅延が発生します。
ネイティブのグラフ処理プロセスもまた、グラフテクノロジーにおいて重要な役割を果す要素の1つです。これは、グラフデータベースがデータの保存やクエリなどのデータベース操作を処理する際の処理の仕方を表します。ネイティブのグラフ処理を差別化するカギを握っているのが、インデックスフリーの隣接性の機能です。
この機能のおかげで、データの書き込み時に個々のノードは、隣接するノードやリレーションシップに直接保存されるため、処理のスピードが向上します。そして、クエリの処理時(すなわちデータの読み込み時)には、インデックスに大きく依存することのない、非常に高速の検索が可能になるのです。非ネイティブのグラフ処理では多くの場合、トランザクションの読み取りや書き込みをするのに、大量のインデックスを使用します。このため、処理のスピードが大幅に低下します。
考慮すべきもう1つの重要な要素として、ACID特性があります。つながりのあるデータでは、データの整合性に関し、通常より厳しい要件が求められます。これは、他のNoSQLモデルの比ではありません。2つのノード間のリレーションシップを更新する場合、リレーションシップのレコードを更新するだけでなく、リレーションシップで結ばれる双方のノードの情報をも更新する必要があります。これら3つのデータに対するいずれの書き込み操作が失敗しても、グラフは壊れてしまいます。まさに最悪のケースです。
時間が経過してもグラフが壊れないようにする唯一の方法は、ACIDに完全に準拠したトランザクションとして、データを書き込む方法です。ネイティブのグラフ処理を備えたシステムには、ネットワークの一時的な機能低下やサーバーの障害、トランザクションの競合などに影響されずにデータの品質を維持できる、適切な保護の仕組みが組み込まれています。
それでは、ネイティブのグラフストレージとネイティブのグラフ処理プロセスがきわめて重要になる理由を、もう少し詳しく見ていきましょう。
ネイティブのグラフストレージ
グラフストレージのネイティブ性を際立たせているのは、グラフデータベースのアーキテクチャです。ネイティブのグラフストレージを備えたグラフデータベースには、グラフの保存と管理に特化して設計されたストレージ基盤が存在します。グラフデータベースは、任意のグラフアルゴリズムを実行する際にトラバーサル(データアクセス)のスピードを最大化するように設計されています。
ネイティブのグラフデータベースであるNeo4jで、ネイティブのグラフストレージを実現するためにどのような構造が採用されているのかを、具体例として見てみましょう。Cypherクエリ言語からディスク上のファイルに至る、このアーキテクチャのすべてのレイヤーが、グラフデータの保存に最適化されており、非グラフテクノロジーから何かを間に合わせで取り込んだ部分は1つもありません。
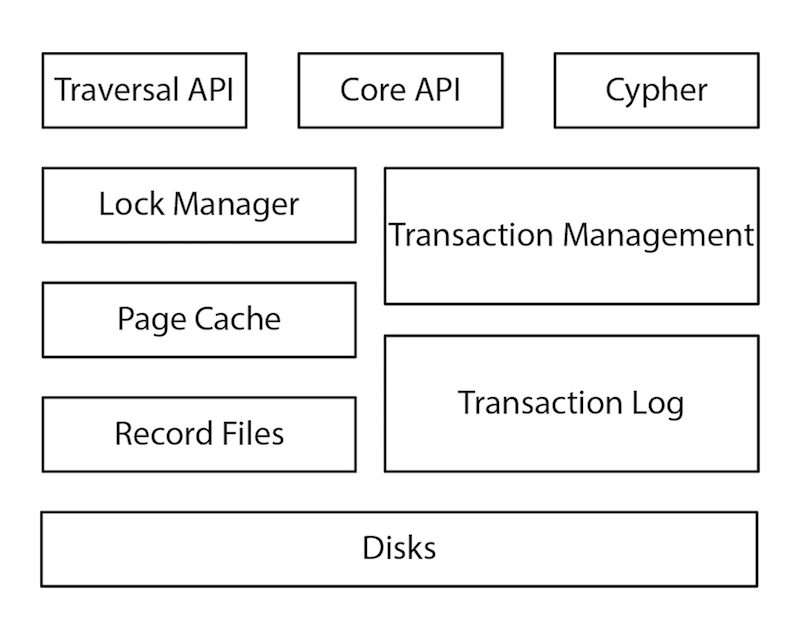
グラフデータはストアファイルに保存されます。個々のストアファイルには、ノード、リレーションシップ、ラベル、プロパティをはじめとする、グラフの固有の要素を表すデータが格納されています。すでに説明したように、グラフデータベースでは、トラバーサルの処理能力を高めていますが、それに役立っているのが、このような手法でのストレージの分割です。
ネイティブのグラフデータベースにおいてノードのレコードを使用する目的は主として、リレーションシップ、ラベル、プロパティのリストをシンプルにポイントすることであり、これによって処理が軽量化されます。
それでは、非ネイティブのグラフストレージとネイティブのグラフデータベースのストレージの違いは何でしょうか。
非ネイティブのグラフストレージでは、リレーショナルデータベースやカラム型のデータベースなどの汎用データストアを使用し、グラフデータの独自性を考慮して専用の設計をすることはありません。運用チームは、MySQLやCassandraなどの非グラフバックエンドのほうに馴染みがあるかもれしれませんが、グラフデータを非グラフストレージと連携できない状況は、パフォーマンスやスケーラビリティの面で数多くの問題を招きます。
非ネイティブのグラフデータベースは、グラフを保存するよう最適化されていないため、データの書き込みに使用するアルゴリズムは、断片化してノードやリレーションシップのデータを保存する可能性があります。この結果、クエリを実行するたびに、ノードとリレーションシップのデータすべてを再構築しなければならないため、検索時にパフォーマンスの問題が生じます。24時間365日、運用環境を運用しなければならないシナリオでは、1分間に数千のクエリが実行される可能性があります。
一方、ネイティブのグラフストレージは、お互いが緊密に関係付けられたデータセットを処理できるようにゼロから開発されているため、グラフデータを保存、検索する際の効率が大変高いのです。
ネイティブのグラフ処理
インデックスフリーの隣接性がある場合、グラフデータベースには、ネイティブのグラフ処理の能力が備わっています。これは、どのノードも隣接するノードを直接参照できることを意味します。ノードはどれも、隣接するすべてのノードのマイクロインデックスとして機能するのです。インデックスフリーの隣接性を活用する方法は、インデックスを使用する方法よりも効率が良く、コストもかかりません。クエリの処理にかかる時間は、データ全体のサイズが大きくなるかどうかに関係なく、検索するグラフの数に比例するためです。
インデックスフリーの隣接性を使用しないと、データセットが大きくなるにつれてクエリの実行に時間がかかるようになるため、大容量のグラフデータセットは自身の重さに耐えられず、クラッシュします。一方、ネイティブのグラフクエリは、データのサイズに関係なく一定のパフォーマンスを発揮します。
グラフデータベースは、リレーションシップのデータを第1級エンティティ※として保存するため、ネイティブのグラフ処理では、どの方向にもリレーションシップをトラバースするのが比較的容易です。グラフデータセットに特化して開発された処理を活用することで、インデックスに過度に依存せず、リレーションシップを利用して、トラバーサルの効率を最大限に高められます。
※第1級オブジェクト:ノードや変数などと同じように扱えるもの
以下の図は、基本的なソーシャルネットワークを表しています。ネイティブに処理されたリレーションシップのデータに基づき、誰が誰とつながっているのかを調べるクエリが実行されています。このクエリを実行する際、インデックスを経由する必要はありません。
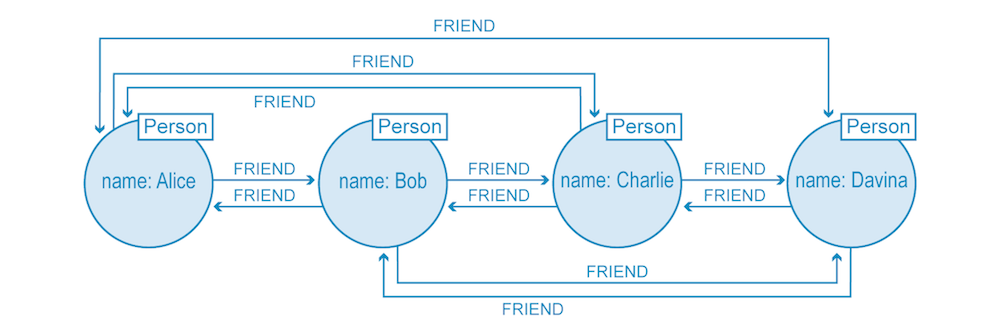
一方、非ネイティブのグラフデータベースでは、ノードを関連付けるのに、数多くのタイプのインデックスを使用します。このモデルの場合、読み取りと書き込みのそれぞれが必要なレイヤーがインデックスによって増えるため、ネイティブのデータベースよりもコストがかかり、処理のスピードが大幅に低下します。
非ネイティブのグラフ処理では、コネクションのレイヤーが複数存在するクエリ(まさにグラフデータベースで必要なタイプのクエリ)の場合、さらにトラバーサルのパフォーマンスが低下します。
以下の図には、1つのコネクションレイヤーだけを検索する非ネイティブのグラフクエリの例を示します。クエリのホップ数が増えるに従い、どれほど処理の時間が長くなるか想像がつくでしょう。
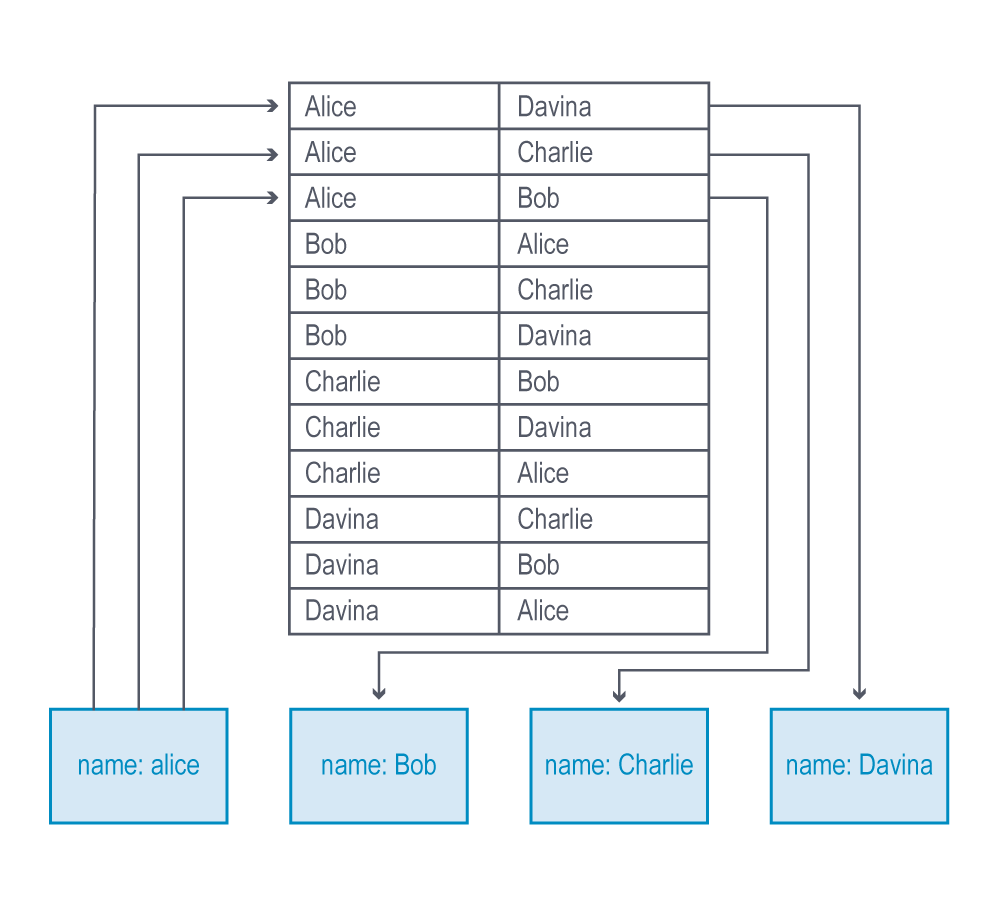
さらに、非ネイティブのグラフ処理の場合は、トラバーサルの方向を反転するのが非常に難しくなります。
クエリの方向を反転するには、コストをかけてトラバーサルごとに逆引きのインデックスを作成するか、ハードの処理能力を頼りに力づくでオリジナルのインデックスを検索する必要があります。どちらの対応策でも、最終的には、求めていた結果を得られるでしょう。しかし、データの関係性を効率的に検索するという、グラフデータベース導入の当初の目的を果すことはできなくなってしまいます。
まとめ:ネイティブと非ネイティブのグラフテクノロジーの違いが重要である理由
ネイティブと非ネイティブのグラフデータベースのどちらを選ぶのか決める場合、それぞれのデータベースのトレードオフを理解することが重要です。
非ネイティブのグラフテクノロジーの場合、パーシステンス層は、CassandraやMySQL、リレーショナルデータベースのような、開発チームが慣れ親しんだものになる可能性が高いと考えられます。そして、データセットが小さかったり、データセット同士の関係性があまりなかったりすれば、非ネイティブのグラフテクノロジーを選択しても、アプリケーションのパフォーマンスに大きな影響が出ることはないでしょう。
ただし、データはいつまでも小さいままでしょうか?データ同士の関係性が少ないままでしょうか。おそらく、そうではないでしょう。
データセットは時間の経過とともに増大する傾向があります。データセットは非構造化が進み、データセット同士の結び付きが複雑になります。当初はデータセットが小さなものであったとしても、事業の拡大に伴い、データは増大すると考えるならば、将来を見据えて計画を立てることが重要になります。そのようなケースでは、長期的な観点から見て、ネイティブのグラフデータベースのほうが有用です。非ネイティブのグラフ処理では、データセットが大きくなると、パフォーマンスが低下するからです。
ネイティブのグラフアーキテクチャへの移行を後押しする大きな要素の1つにスケーラビリティがあります。データベースに追加するデータの数が増えると、非ネイティブのグラフデータベースでは、規模の問題で、多くのクエリを実行したときに処理速度が低下してしまいますが、ネイティブの環境なら、柔軟性とスピードが維持されます。
ネイティブのグラフデータベースのスケーリングでは、データの保存と処理の面で多数の最適化を行い、効率的なアプローチを実現します。一方、非ネイティブのグラフデータベースの場合は、力づくで問題を解決するので、ネイティブのグラフデータベースよりも多くのハードウェアが必要になり、その数は通常、2倍から4倍以上にもなります。グラフの規模が大きいほどこの傾向が顕著になります。
すべてのアプリケーションに対して、低遅延性や効率的な処理性能が必要とは限りません。ユースケースによっては、非ネイティブのグラフデータベースが適している場合もあります。(そもそもそのような用途にグラフデータベースを使う理由があるでしょうか。)
一方で、相互に関連付けられた大容量のデータセットを対象に保存、照会、トラバーサルを、24時間365日常時稼働しているミッションクリティカルなアプリケーションでリアルタイムに実行する場合は、大規模なグラフデータを扱えるよう特別に設計されたデータベースアーキテクチャが必要になります。
結論:ネイティブと非ネイティブのグラフテクノロジーを比較する際に重要になるポイントは、アプリケーションの個々のニーズによって異なります。しかし、データの関係性を十分に利用しようと考えているのであれば、ネイティブのグラフデータベーステクノロジーが必須になります。





