
Neo4j v4.0のハイライト #neo4j

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
2020年1月15日、Neo4j v4.0がリリースされました。
https://community.neo4j.com/t/latest-neo4j-major-release-4-0-available/13747
次が今回のリリースのハイライトです。
- スタンドアロンおよび大規模分散クラスター(Causal Cluster)で利用可能な複数のデータベース
- スタンドアロンおよび大規模分散クラスターで利用可能なメタデータリポジトリ「システム」データベース
- スキーマベースのセキュリティとロールベースのアクセス制御
- ロールおよびユーザー管理機能
- サイファー管理コマンド
- データベースファブリックを使用したデータベースへのシャーディング&フェデレーション
- サーバーからクライアントへのフロー制御を備えたJava、Javascriptおよび.NET Reactiveドライバー
- キープアライブ信号を備えたBoltプロトコル
- ネイティブインデックスの新しいインデックス作成アルゴリズム
- 複数のデバイスでI / Oワークロードを簡単に分散するトランザクションログフォルダー
- トランザクションのメモリ制約の制御
- すべてのエディションとインストールで利用可能な、Boltおよびルーティングプロトコルを含む新しいneo4j://スキーム
- リアクティブドライバー(SDN / RX)に基づくSpring Data Neo4jの新しい実験バージョン
次は機能の強化などを除く、v3.5から4.0へバージョンアップする際の重大な変化です。
| 区分 | V3.5 | V4.0 | コメント |
|---|---|---|---|
| Java | sdk 8 | sdk 11 | |
| Multi databases | - | New | CREATE DTABASE |
| System database | - | New | |
| Fabric | - | New | データベース越しのシャーディング&フェデレーション(水平分散&統合) |
| Sub Query | - | New | |
| HA Cluster | 〇 | ✖(廃止) | 機能的に大規模分散クラスターのコア(レプリケーションセット)と同等であるために存在意味が無くなっていました。今後、HAクラスターの機能は大規模分散クラスターのコアが担うことになります |
Java11
Neo4j Server4.0を利用するためには、JDK11をインストールする必要があります。
Neo4j Desktopの場合、JDK11の上でv1.2.4以降を利用してください。
Open JDK11は、次のURLからダウンロードできます。
http://jdk.java.net/java-se-ri/11
エンタープライズ向けのOracle JDKは有償化の流れになっているようなのでライセンスポリシーを確認してください。
ただ、個人利用は従来通り無償らしいです。
サブクエリ
CALL { Cypher構文 }のようにネストしたクエリを実行し、そのリターン値を上位のクエリブロックから利用できます。
CALL {
CALL {
MATCH (p:Person) WHERE p.name = 'Tom Hanks' RETURN p
}
RETURN p
}
RETURN p.name
p.name
"Tom Hanks"
マルチデータベース
デフォルトデータベースとシステムデータベース
データベースにログインすると、デフォルトデータベース(neo4j)に接続されます。
初期状態では、2つのデータベースが存在しています。
neo4j$ :dbs

[説明]
| neo4j | Defaultのデータベース |
|---|---|
| system | システム情報を保存するリポジトリデータベース |
データベースの作成
1DBMS上で複数のデータベースを作成し、それぞれ異なる内容のグラフが運用できるようになりました。
CREATE DATABASE database_name1;
CREATE DATABASE database_name2;
CREATE DATABASE database_name3;
データベース間のスイッチは「:useコマンド」を使います。
neo4j$ :use system system$ show databases name address role requestedStatus currentStatus error default "neo4j" "localhost:7687" "standalone" "online" "online" "" true "system" "localhost:7687" "standalone" "online" "online" "" false
SYSTEMデータベース上でMOVIEとNORTHWINDを作成してみます。
system$ CREATE DATABASE movie (1 system update, no records) system$ CREATE DATABASE northwind (1 system update, no records) system$ show databases name address role requestedStatus currentStatus error default "neo4j" "localhost:7687" "standalone" "online" "online" "" true "system" "localhost:7687" "standalone" "online" "online" "" false "movie" "localhost:7687" "standalone" "online" "online" "" false "northwind" "localhost:7687" "standalone" "online" "online" "" false
このように1DBMS上で全く異なる複数のデータベースを運用できるようになりました。
データベースファブリック(シャーディング&フェデレーション)
データベースファブリックはNeo4j v4.0リリースの花と言ってもいいでしょう。
Neo4jはマスタータイプのアーキテクチャーです。
このタイプのデータベースでは通常スケールアップしかできないのですが、シャーディングという手法でデータを複数のシャードというパーティションに水平分散します。
MySQLやMongoDBがこの方式を利用しています。
データベースファブリックでは複数のデータベースをシャード(パーティション)のように扱い、巨大グラフをサブグラフに分割し、それぞれのデータベースに分散して格納します。
そして、Cypherで複数のデータベースを統合して読み書きします。
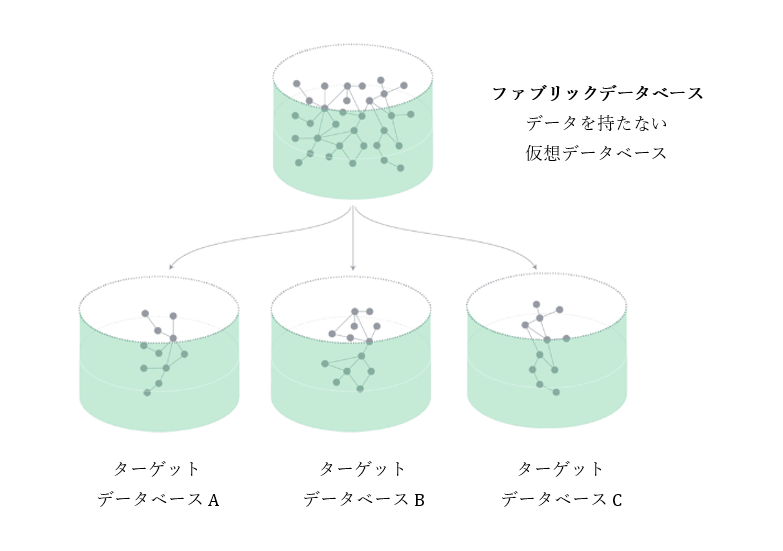
データベースファブリック
- 一連の繋がりを持つグラフを複数のデータベースにパーティション化して分散し、統合して問い合わせを行う方式のことです
- 全く繋がりを持たない複数のグラフをファブリックで運用しても無意味かも知れません
ファブリックデータベース
- 分散されているグラフを統合する仮想データベースです
- ファブリックデータベースは明示的にデータを持ちません
- ファブリックデータベースは明示的に作成しません(neo4j.confに設定)
- Cypherはファブリックデータベース上で実行します
ターゲットデータベース
- サブグラフを持っているデータベースです
- シングルインスタンス中の複数のデータベース、マルチインスタンス中のシングルデータベース、クラスターどちらでも構いません
ファブリックデータベースとターゲットデータベースの構成について
- ファブリックデータベースとターゲットデータベースは1DBMS上で構築できます
- ファブリックデータベースとターゲットデータベースは別々のDBMSに分離することもできます
- ターゲットデータベースはシングルDBMS、マルチDBMS、大規模分散クラスターのどちらの構成でも構いません
次はCypherの例示です。
サブクエリを書くようなイメージで複数のデータベースにまたがる問合せを実行します。
構文を見ると、サブクエリと酷似しています。
example$
CALL {
USE example.graphA
MATCH (p:Person)
WHERE p.name = 'Tom Hanks'
RETURN p.name AS names
}
CALL {
USE example.graphB
WITH names
MATCH (a:Person { name: names} )-[r:ACTED_IN]->(m:Movie)
RETURN a,r,m
}
RETURN a,r,m
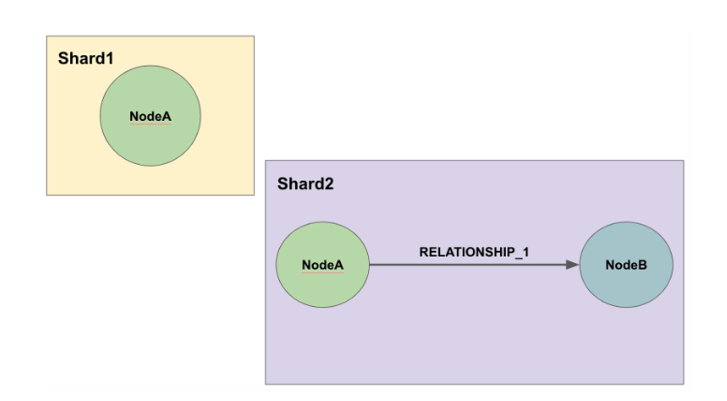
大規模分散クラスター(Causal Cluster)との差
大規模分散クラスターはスケールアップのアーキテクチャーです。
いくら大規模になっても、リードレプリカーを多数持っていても、基本的に同じデータの塊です。
これでNeo4jは水平分散ができないという汚名は返上ですね。
HAクラスター廃止
HAクラスターはv4.0で廃止となりました。
そもそもHAクラスターは大規模分散クラスター(Causal Cluster)の登場により機能が被っていました。
大規模分散クラスターはレプリケーションセットとリードレプロードの運用で高可用性と性能拡張の機能を兼ねていました。
まとめ
Neo4j v4.0が発表された時に最も驚いたのはデータベースファブリックでした。
はじめはサブクエリの一種だと勘違いしてましたが、理解出来てからはとても嬉しかったです。
さすがNeoj4は期待を裏切ったりしません!
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



