
Neo4jとRDBとの分岐点 #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
グラフDBは、RDBで対応困難なとても複雑なネットワーク状のデータ処理に特化したデータベースです。
その中でも、Neo4jは特定のジャンルに偏らず、データ処理の汎用性がとても優れています。
ネットワーク状のデータとは、特別なデータを意味しているわけではありません。そもそも、すべてのデータはなにかしらの繋がりを持ち、本質的にネットワーク構造です。Neo4jは「Graphs are everywhere」と言っていますが、かつてRDBでは「Relations are everywhere」と言っていました。言い換えると、すべてのデータベースはデータの繋がり(ネットワーク)を扱っています。ただ、データ間の繋がりの密度が高いか低いか、階層が深いか浅いかの差はあります。
では、どのくらい複雑なデータ処理になると、RDBよりNeo4jが効率的なのでしょうか。
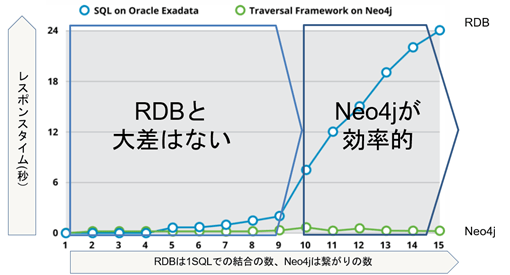
次のチャートは、Neo4jとRDBを比較したベンチマークの結果です。
1クエリで結合が10個以上になったあたりから、RDBは遅延が激しくなりますが、Neo4jは殆ど遅延が発生しません。
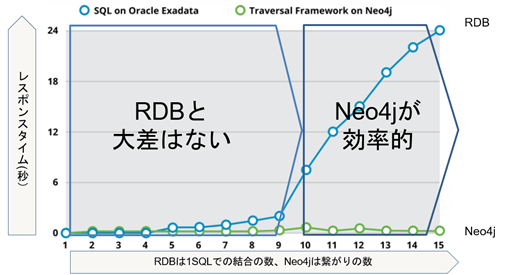
[出所:https://neo4j.com/blog/oracle-rdbms-neo4j-fully-sync-data/]
そもそも、Neo4jはRDBの遅延問題を解決するために開発が始まったと言われています。
とても複雑なデータ処理では、次のような側面でRDBとの分岐点が訪れます。
- データが複雑すぎてRDBではデータベース設計自体が困難
- SQLで書くと、結合の数が非常に多く、遅延が激しい(ジョインボムの問題)
Neo4jではRDBと違って繋がりを永続化しています。
SQLのようにデータ処理が始まってから結合関係を紐解く必要がないために、複雑な関係性を持つデータの探索を高速に行うことができます。
ここでは、とても複雑なデータワーク状のデータの事例を「グラフモデル」でご紹介します。
パナマ文書(Panama Paper by ICIJ)
これは、一時期話題になった「パナマ文書」のデータモデルです。
なんと、わずか4ノードで322のリレーションシップ(繋がりのタイプ)が存在します。
リレーションシップが密集している部分は黒く塗りつぶされています。
リレーショナルモデルでこのようなデータのデータベース設計が可能でしょうか。もしできたとしても、ジョインボム(join bomb)の問題に悩まされるはずです。
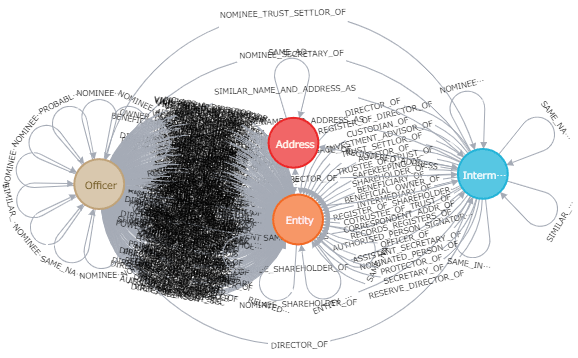
Displaying 4 nodes, 322 relationships
[出所: https://neo4j.com/sandbox/]
ネットワーク&ITマネジメント(Network and IT Management)
テレコムサービスやクラウドサービスでは、複雑に繋がっている膨大な数のネットワーク機器を管理する必要があります。そして、障害が起きたポイントから影響を受ける範囲を速やかに割り出す必要もあります。
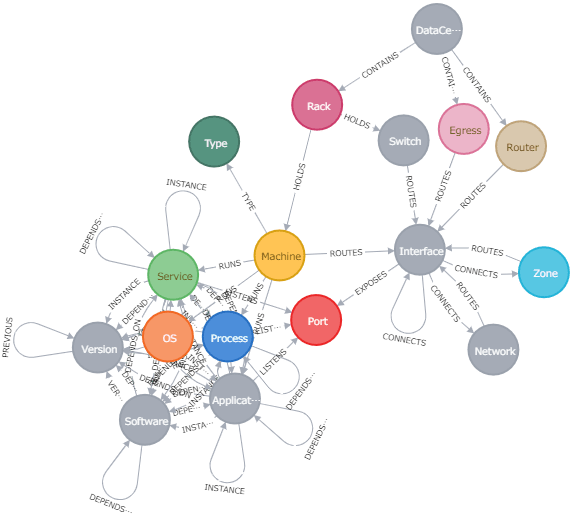
Displaying 17 nodes, 63 relationships.
[出所: https://neo4j.com/sandbox/]
犯罪捜査(Crime Investigation)
組織的な犯罪の摘発においては、異常パターンの形成を適切なタイミングで瞬時に捉える必要があります。
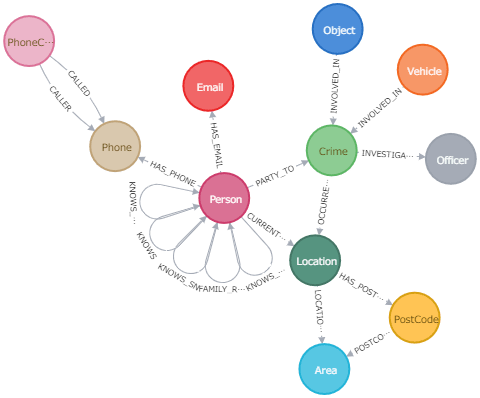
Displaying 11 nodes, 18 relationships.
[出所: https://neo4j.com/sandbox/]
グラフデータサイエンス(Graph Data Science)
Neo4jグラフデータサイエンス(GDS)ライブラリには、Cypherプロシージャを通じて公開される一連のグラフアルゴリズムが含まれています。たとえば、中心性と類似性のスコア計算によるコミュニティの検出などです。サンプルデータセットは、「Game of Thrones」の様々な関係性を描いています。
このようなケースもリレーショナルモデルではデータベース設計自体が困難でしょう。
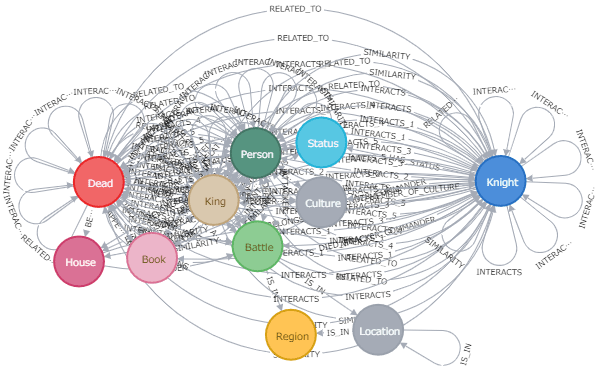
Displaying 12 nodes, 164 relationships.
[出所: https://neo4j.com/sandbox/]
RDBでは明らかに非効率なデータ処理の解決策として、既に様々なNoSQLが登場しています。
その中で、Neo4jはとても複雑なデータ処理に向いているデータベースエンジンです。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



