
Neo4j v3.0メジャーバージョンアップグレードのまとめ #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
2016年4月26日、NoSQLグラフデータベースNeo4jのメジャーバージョンアップグレード(v3.0)の発表がありました。今回のアップグレードでは、次の3点において飛躍的な進展がありました。
スケールとパフォーマンスの抜本的な見直し
- データストアのフォーマットを再設計
- データサイズ制限の撤廃
- インデックスなしの隣接性の適用範囲を拡張
- コストベースの実行計画の適用範囲を拡張
開発者の生産性の向上
- 標準SDKの発表
- 新しい関数の発表
操作性の向上
- オンプレミス、Cloud、Dockerなどのプラットフォームをサポート
- 標準ブラウザ機能の向上
今回のアップグレードの内容をまとめながら感じたことですが、原型はあまり変わっていませんが、中身では本当に思い切ったことをやったなあ~と思いました。
これを車に例えるなら、新しいモデルの発表で、エンジンを別のタイプに載せ替えて推進力を抜本的にアップし、
不評だったドアの数を変えて、人の出入りも楽にしたというようなことを聞いたような印象でした。
では、その詳細をなるべく平易な言葉で解説していきます。
Neo4j開発の歴史
ここまでのNeo4jの開発の歴史とバージョンとの関係を簡略に紹介します。
| 年度 | 内容 | 備考 |
| 2000 | RDBのパフォーマンス問題解決のためのにNeo4jプロタイプ開発(プロパティグラフモデル) | |
| 2003 | 初の現代的なグラフデータベースの製品発表 | v1.x |
| 2007 | オープンソース版配布開始 | v1.x |
| 2011 | グラフデータベース業界初のCypher Query言語発表 | v1.x |
| 2012 | ラベルなどグラフデータモデルの拡張 | v1.x |
| 2013 | スケールとパフォーマンス、Cypher Queryの充実化 | v2.x |
| 2015 | Cypher Queryのオープンソース化 | |
| 2016 | スケールとパフォーマンスの抜本的な見直し 開発者の生産性の向上 操作性の向上 |
v3.x |
Neo4j v2.xでは、データストアやデータ処理のためのAPI、ユーザーインターフェースなどでグラフデータベースとしての原型が完成された時期ではないかと思います。この時期では、より大量のデータを処理することが可能になり、パフォーマンスも飛躍的に向上しています。特にCypher Queryは、バージョン1で発表されていますが、バージョン2になって、開発者は本当にSQLを書くような感覚でQueryが書けるようになりました。
スケールとパフォーマンスの抜本的な見直し
Neo4j v3.0では、データストアのフォーマットを再設計することによって、データのスケールとグラフデータ処理のパフォーマンスを飛躍的に向上させています。
インデックスフリーの隣接性の適用範囲を拡張
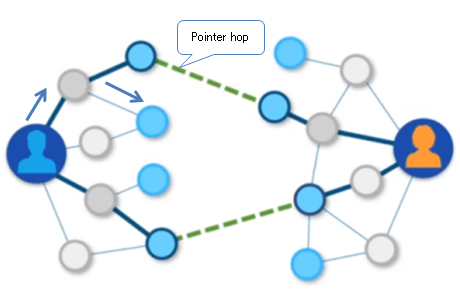
一般的にグラフデータ処理は、インデックスが存在しなくてもノード間のリレーション(下の右図の矢印のような構造)を辿って走査するためにインデックスが存在しなくても高速のデータ処理が可能です。
しかし、実際のグラフデータ処理では、下の図の破線のようにリレーションが存在しないノード間でのデータ処理が必要なシチュエーションが頻繁に発生します。このような処理では、インデックスに依存する、あるいは該当の属性のみをリストに入れて処理する、アプリを書くなど回避策を工夫するしかありませんでした。それで、どうしてもデータ処理のレスポンスも、開発者の生産性も落ちていきます。
Neo4j v3.0からは、リレーションが存在しないようなグラフデータ処理でも最適化されます。まるでポイント間を飛び越えるような最適化のアルゴリズムが働き、Cypher Queryのパフォーマンスは飛躍的に向上します。

Neo4jは10億人規模のソーシャルネットワークで実証検証を行ったそうです。興味をある方はこちらを参考にして下さい。
Tackling a 1 Billion Member Social Network – Fast Search on a Large Graph (英語)
ノード数の制限を撤廃
Neo4j v2.xまで、ノードとリレーションの数の制限は、それぞれ340億件、属性は2740億件でした。
Neo4j v3.0からデータストアに格納できるノードやリレーション、プロパティ、インデックスの数などのすべての制限がなくなりました。Neo4jは、そのためにデータストアのフォーマットを再設計し、インデックスの構造にも手を入れています。

但し、これはNeo4jのアーキテクチャーがスケールアウトできるようになったことではありません。依然として、Neo4jはマスター型のアーキテクチャーであり、格納できるデータサイズは1台のサーバーが持つリソースの限界までという制限が存在します。しかし、その制約はもはやNeo4jの制約ではなくサーバーリソースの制約です。
コストベースの実行計画の適用範囲を拡張
Neo4j v3.0からは読み込みと書き込みの両方でコストベースの実行計画を導入しました。実は、v2.xでは読み込みはコストベース、書き込みはルールベースの実行計画でした。
| 区分 | Read | Write |
| 2.X | ◎ | × |
| 3.X | ◎ | ◎ |
一般的にクエリの実行計画を立てるときにコストベースの方がパフォーマンス面で有利です。ルールベースでは、インデックスのみを考慮しますが、コストベースではインデックスだけではなく、データの数や分布などより多くの要素を取り入れて実行計画を作成するからです。
但し、データサイズ制限の撤廃やインデックスなしの隣接性の拡張によるスケールやパフォーマンス向上の恩恵が得られるのはエンタープライズ版のみです。
開発者の生産性の向上
公式言語ドライバーの提供
Neo4j 2.xまでもAPIは提供していましたが、使い勝手が良いとは言えない状況でした。GitHubに散在しているサンプルコードのなかから開発者が自分のケースに適したものを検証して使うような有様でした。
| 2000-2010:0.x | Embedded Java API |
| 2010-2014:1.x | REST |
| 2014-2015:2.x | Cypher |
| 2016 :3.x | Bolt+Offical Language Drivers |
しかし、Neo4j v3.0からは、BoltバイナリプロトコールをNeo4jの標準ドライバーとして採用し、開発者はJavaScript, Java, .NET, Python, Community Driversなど、それぞれの開発現場の状況に応じて適した言語を選んで使えるようになりました。
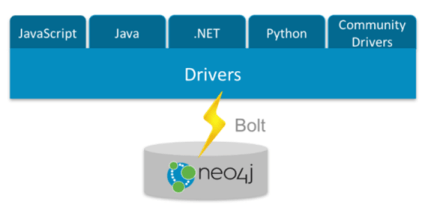
以下、言語別のスニペットです。
Java Script
var driver = Graph.Database.driver("bolt://localhost");
var session = driver.session();
var result = session.run("MATCH (u:User) RETURN u.name");
Python
driver = Graph.Database.driver("bolt://localhost")
session = driver.session()
result = session.run("MATCH (u:User) RETURN u.name")
Java
Driver driver = GraphDatabase.driver( "bolt://localhost" );
try ( Session session = driver.session() ) {
StatementResult result = session.run("MATCH (u:User) RETURN u.name");
}
.NET
using (var driver = GraphDatabase.Driver("bolt://localhost"))
using (var session = driver.Session())
{
var result = session.Run("MATCH (u:User) RETURN u.name");
}
Javaストアドプロシャーの提供
Neo4j v3.0からJavaで開発したコード(xxxxxxx.jar)をサーバー側の既定のフォルダにデプロイしておいてストアドプロシャーのような感覚で呼び出し(実行)することが可能です。従来のJavaフラグインの開発と同じような要領です。
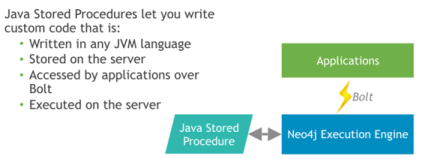
それで何かできるのかというと、例えば、公式のBoltドライバーと連携するような形でMySQLからSQLで検索したデータをCypher QueryでNeo4jに取り込むような処理の開発が可能です。

Spatial Functionの提供
Neo4j v3.0から座標情報(緯度と経度)から距離を算出するdistance(point(a), point(b))という関数が追加されました。
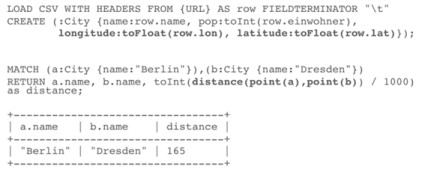
最短経路の予測(shortestPath)の強化
shortestPath()は従来から存在したものですが、それに条件を付けるようにしてさらに様々なシチュエーションに対応できるようにしています。

Neo4j v3.0の発表で、このような関数の追加や機能の強化が含まれたのは、非常に面白いです。これからNeo4jのマイナーバージョンの発表で、次々と新しい関数が発表される兆しではないかと、期待しております。
操作性の向上
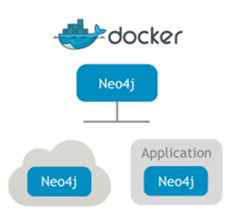
マルチプラットフォームのサポート
Neo4j v3.0になってデータストアやインデックスフォーマットの再設計、コンフィグレーションの統合などがありましたが、クラウド、Docker、オンプレミスのおける操作性は変わることなくサポートしています。
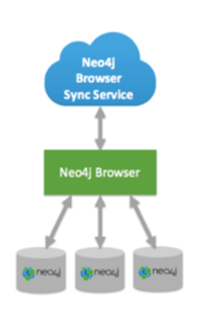
Neo4j Browser Sync
今回のアップグレードでは、GitHub、Google、TwitterなどのOpenIDによる認証が可能になりました。それによって、複数のNeo4j のデータベースを利用する際にも、Webブラウザーのスタイルシートや設定など操作性に関わるものは変わることなく、共有できるようになりました。
Upgrading to 3.0
Neo4j v3.0になって色々変更点が沢山ありますがアップグレードに置いては、ファイルフォーマットの変更やインデックスの再作成などの問題をNeo4j v3.0が吸収してくれます。
- Java 8
- Store format
- Lucene upgrade - indexes rebuilt
- Directory structure and config
- Migration configuration tool
そのマジックの一つは、Neo4jの起動時に環境ファイルのなかでdbms.allow_format_migrationをtrueにすることです。
dbms.allow_format_migration=true
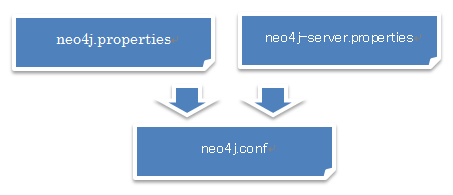
但し、Neo4j v3.0になって環境ファイルが2つから1つに統合されたことに注意してください。neo4j.propertiesとneo4j-server.propertiesの内容をneo4j.confにまとめる作業が必要です。これは手動で行う必要があります。あまりに難しく考える必要ありません。パラメーターの名称を見て識別できます。
なお、一度v3.0になってデータベースを元のバージョンに戻すことはできません。気になる方は、データベースをバックアップしておいてください。Neo4jのデータベースバックアップは実に簡単です。データストアのフォルダをどこかにコピーしておけばいいです。
さらに詳しいことは、以下のNeo4jの公式ドキュメントを参照してください。環境ファイルをマージするツールもあるようです。
http://neo4j.com/guides/upgrade/#neo4j-3-0
その他
Neo4j v3.0から、次のような処理のパフォーマンスも改善されました。
- ラベルでのノード数のカウントなどが速くなりました。
- リレーションが存在しないグラフ間のジョインが速くなりました。
以上、Neo4j v3.0メジャーバージョンアップグレードの解説でした。
【参考資料】
本家
http://neo4j.com
公式ドキュメント
http://neo4j.com/docs/
Neo4jのインストール
http://neo4j.com/download/
SlideShare
http://www.slideshare.net/neo4j/introducing-neo4j-30
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



