
婚活支援プロジェクト(2/4): データ処理と問題点 #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
前回の「婚活支援プロジェクト:構想からデータモデル設計まで」では、婚活に必要な基礎情報を収集し、理想的な相手を予測する方式の決定、データモデリングまでを行いました。今回は、前回のデータモデルに基づいてグラフデータベースを作成し、実際に候補者を予測してみたいと思います。
第1回目:構想からデータモデル設計まで
第2回目:データ処理と問題点
第3回目:どのように改善したらいいのか
第4回目:改善したデータモデルによるデータ処理
事前準備
Neo4jサーバのインストール
Neo4jが初めてという方は、次のサイトを参照してNeo4jサーバーをインストールしてください。OSは、WindowsやMac、Linuxが対応しています。今回の記事ではWindows版を使用しています。以下のページが参考になると思います。
Cypher Query Language(QL)-初級編
qitta.com/awk256
データストアのフォルダー作成
今回のグラフデータベース(以下、GDB:Graph Data Base)を格納するための空のフォルダーを用意してください。
今回の記事では以下のフォルダーを作成しています。作成後、Neo4jを起動する際にGDB用のフォルダーを選択して実行します。
C:¥Users¥Documents¥Neo4j¥konkatu.db
Mac/Linuxの場合は、次のようにフォルダーを作成してください。その後にNeo4jサーバを起動、又は再起動してください。
data/konkatu.db
ただし、Linux版の場合は起動前にconf/neo4j-server.propertiesを編集する必要があります。
org.neo4j.server.database.location=data/konkatu.db
Neo4jへのデータロード
これから、前回調査した婚活関連情報とデータモデル設計に基づいてGDBにデータをロードする過程を説明します。
GDBにデータをロードする方法
前回の調査で理想的な相手を予測するためのデータのモデリングを行いましたが、それらのデータを GDBに登録しなければなりません。GDBにデータを登録する方法は複数あり、データのサイズや状況に応じて使い分けることができます。今回は CypherクエリーとLOAD CSV文を利用します。また参考のために、Neo4jImportを使う方法、APIを利用する方法を合わせて紹介しています。
- Cypherクエリーを利用する方法
少量のデータを稼働中のGDBに登録する場合は、ダイレクトにCypherクエリーを書いて実行する方法が簡単です。Cypherクエリーは、Webブラウ ザーやNeo4jShell(neo4j-shell)から実行できます。勿論、プログラムに埋め込んで大量データを扱うことも可能です。
- LOAD CSV文を利用する方法
比 較的大量のデータを稼働中のGDBに登録する場合は、LOAD CSV文を利用します。LOAD CSV文は、第1行目がカラム名になっているCSVファイルを入力データとして使います。一旦、CSVファイルからデータを読み込んだ後に、Cypher クエリーでデータ操作を行います。
- Neo4jImport(neo4j-shell)を利用する方法
Neo4jImport(neo4j- import)は、大量のデータを最も高速にGDBに登録できる方法です。入力データは、若干書式は異なりますが、LOAD CSV同様のCSVファイルを利用します。Neo4jImportは、常に新しいデータベースファイルを作成するため、既存のGDBに対して追加や更新な どの用途では使えません。さらに、関係性のリンクなどを事前に定義しておく必要があるなどの手間が掛かります。但し、既存のリレーショナルデータベースな どからNeo4jへの移行の場合は、SQLで関係性を作成できるためとても有効な手段の一つになります。勿論、少量のデータに使っても問題はありません。
- APIを利用する方法
Neo4j は、JavaのNative APIとREST APIでプログラムを開発し、グラフデータを操作することが可能です。これは、なにかしらのサービスシステムとしてNeo4jを組み込んで利用する場合は 必須の機能になるでしょう。REST APIを使う場合は、Java, .NET, PHP, JavaScript, Ruby, Pythonなど、多様な言語が利用できます。
候補者のオリジナルデータをダウンロード
今回は、男女、それぞれ30人分のデータを用意しています。データをダウンロードし、「C:/temp/data/Man2.csv」、「C:/temp/data/Woman2.csv」のように格納してください。
男性データ:Man2.zip
女性データ:Woman2.zip
このような作業が面倒くさいという方は、完成版のGDBをダウンロードして利用してください。完成版のGDBを利用する方は、「Neo4jへのデータロード」は内容を把握する程度にし、「分析及び予測シナリオの作成と実行」へ進んでください。絶対、完成版のGDB(konkatu.gdb)の上にデータをロードしては行けません。すべてのノードが2重になり、Cypherクエリーから正しい結果を期待できなくなります。
完成版のGDBのダウンロード:konkatu.gdb.zip
プライマリドメインのノード作成
まず候補者のノードを作成します。次のLOAD CSV文をWebインターフェースでそれぞれ実行してください。
男性
LOAD CSV WITH HEADERS FROM "file:///C:/Temp/data/Man2.csv" AS line
CREATE (:Person:Man { name:line.name})
女性
LOAD CSV WITH HEADERS FROM "file:///C:/Temp/data/Woman2.csv" AS line
CREATE (:Person:Woman { name:line.name})
サブドメインのノード作成
次は候補者の属性を表す20種のサブドメインのノードを登録するCypherクエリーをWebインターフェースで実行してください。Neo4jShellを使う場合は、構文の末尾にセミコロン(;)を付けてください。
WITH ["野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","その他"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (a1:Sport {title: list[i]}))WITH ["土日祝日","平日","不定期"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (b1:Holiday {title: list[i]}))WITH ["聞くタイプ","話すタイプ","とちらでも良い"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (c1:Talk {title: list[i]}))WITH ["積極的","消極的","とちらでもない"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (d1:Meeting {title: list[i]}))WITH [140,150,160,170,180,190,200] as list
FOREACH(i IN range(0, length(list)-1) |
CREATE (e1:Height {title: list[i]}))WITH ["外向的","内向的"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (f1:Personality {title: list[i]}))WITH ["読書","映画感想","音楽感想","TV感想","ゲーム","寝る","友たちとお喋り","料理を作る","その他"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (g1:Indoor {title: list[i]}))WITH ["吸う","吸わない"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (h1:Smoking {title: list[i]}))WITH ["飲む","飲まない"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (j1:Alcohol {title: list[i]}))WITH ["好き","嫌い"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (k1:Karaoke {title: list[i]}))WITH ["信じる","信じない"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (m1:Fortunetelling {title: list[i]}))WITH ["意識して運動する","特に意識していない"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (n1:Healthcare {title: list[i]}))WITH ["海","山","川","公園","遊園地","どちらでもいい"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (o1:Outdoor {title: list[i]}))WITH [100,200,300,400,500,600,700,800,900] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (p1:Income {title: list[i]}))WITH ["北海道","青森県","岩手県","宮城県","秋田県","山形県","福島県","茨城県","栃木県","群馬県","","埼玉県","千葉県","東京都","神奈川県","新潟県","富山県","石川県","福井県","山梨県","長野県","岐阜県","静岡県","愛知県","三重県","滋賀県","京都府","大阪府","兵庫県","奈良県","和歌山県","鳥取県","島根県","岡山県","広島県","山口県","徳島県","香川県","愛媛県","高知県","福岡県","佐賀県","長崎県","熊本県","大分県","宮崎県","鹿児島県","沖縄県"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (q1:Location {title: list[i]}))WITH ["有り","無し"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (r1:Maritalhistory {title: list[i]}))WITH ["犬派","猫派"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (s1:Pet {title: list[i]}))WITH ["義務教育","高等学校","各種専門学校","短大・高専","大学","大学院"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (t1:Education {title: list[i]}))WITH ["公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","学生","家事手伝","その他"] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (u1:Job {title: list[i]}))WITH [1995,1994,1993,1992,1991,1990,1989,1988,1987,1986,1985,1984,1983,1982,1981,1980,1979,1978,1977,1976,1975,1974,1973,1972,1971,1970] AS list
FOREACH(i IN range(0, length(list)-1) |
CREATE (v1:Born {title: list[i]}))
実行が終了したら、左のメニューバーを開いて「Node Labels」のラベル名をクリックし、それぞれのノードを確認してください。
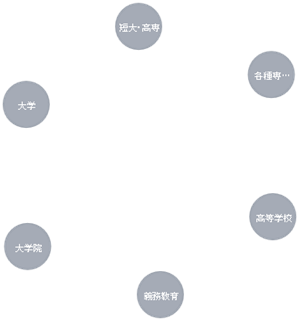
以下は、「Education」をクリックした時の例です。
候補者とサブドメインのノードとの関係性作成
今回のデータは、それぞれの男女に対して20種類のサブドメインの要素をランダムに割り振っています。このようなデータの関係性の作成は、とても難しいように思われるかも知れませんが、Cypherではとても簡単に記述できます。
LOAD CSV文のテストをしてみたい場合は、「RETURN * LIMIT 25」文までを実行してみてください。名称の不一致やデータの不在などは、ここで検知できます。Webインターフェースで以下のクエリーをそれぞれ実行してください。
男性
LOAD CSV WITH HEADERS FROM "file:///C:/Temp/data/Man2.csv" AS line
MATCH
(man:Person:Man { name: line.name }),
(sport:Sport { title: line.sport}),
(holiday:Holiday { title: line.holiday}),
(talk:Talk { title: line.talk}),
(meeting:Meeting { title: line.meeting}),
(height:Height { title:toInt(line.height)}),
(personality:Personality { title: line.personality}),
(indoor:Indoor { title: line.indoor}),
(smoking:Smoking { title: line.smoking}),
(alcohol:Alcohol { title: line.alcohol}),
(karaoke:Karaoke { title: line.karaoke}),
(fortunetelling:Fortunetelling { title: line.fortunetelling}),
(healthcare:Healthcare { title: line.healthcare}),
(outdoor:Outdoor { title: line.outdoor}),
(income:Income { title:toInt(line.income)}),
(born:Born { title:toInt(line.born)}),
(location:Location { title: line.location}),
(maritalhistory:Maritalhistory { title: line.married}),
(pet:Pet { title: line.pet}),
(education:Education { title: line.education}),
(job:Job { title: line.job})
//RETURN * LIMIT 25
CREATE
man-[:MY_SPORT]->sport,
man-[:MY_HOLIDAY]->holiday,
man-[:MY_TALK]->talk,
man-[:MY_MEET]->meeting,
man-[:MY_HEIGHT]->height,
man-[:MY_PERSONALITY]->personality,
man-[:MY_INDOOR]->indoor,
man-[:MY_SMOKING]->smoking,
man-[:MY_ALCOHOL]->alcohol,
man-[:MY_KARAOKE]->karaoke,
man-[:MY_FORTUNETELLING]->fortunetelling,
man-[:MY_HEALTHCARE]->healthcare,
man-[:MY_OUTDOOR]->outdoor,
man-[:MY_INCOME]->income,
man-[:MY_BORN]->born,
man-[:MY_LOCATION]->location,
man-[:MY_MARRIAGE]->maritalhistory,
man-[:MY_PET]->pet,
man-[:MY_EDUCATION]->education,
man-[:MY_JOB]->job
女性
LOAD CSV WITH HEADERS FROM "file:///C:/Temp/data/Woman2.csv" AS line
MATCH
(woman:Person:Woman { name: line.name }),
(sport:Sport { title: line.sport}),
(holiday:Holiday { title: line.holiday}),
(talk:Talk { title: line.talk}),
(meeting:Meeting { title: line.meeting}),
(height:Height { title:toInt(line.height)}),
(personality:Personality { title: line.personality}),
(indoor:Indoor { title: line.indoor}),
(smoking:Smoking { title: line.smoking}),
(alcohol:Alcohol { title: line.alcohol}),
(karaoke:Karaoke { title: line.karaoke}),
(fortunetelling:Fortunetelling { title: line.fortunetelling}),
(healthcare:Healthcare { title: line.healthcare}),
(outdoor:Outdoor { title: line.outdoor}),
(income:Income { title:toInt(line.income)}),
(born:Born { title:toInt(line.born)}),
(location:Location { title: line.location}),
(maritalhistory:Maritalhistory { title: line.married}),
(pet:Pet { title: line.pet}),
(education:Education { title: line.education}),
(job:Job { title: line.job})
//RETURN * LIMIT 25
CREATE
woman-[:MY_SPORT]->sport,
woman-[:MY_HOLIDAY]->holiday,
woman-[:MY_TALK]->talk,
woman-[:MY_MEET]->meeting,
woman-[:MY_HEIGHT]->height,
woman-[:MY_PERSONALITY]->personality,
woman-[:MY_INDOOR]->indoor,
woman-[:MY_SMOKING]->smoking,
woman-[:MY_ALCOHOL]->alcohol,
woman-[:MY_KARAOKE]->karaoke,
woman-[:MY_FORTUNETELLING]->fortunetelling,
woman-[:MY_HEALTHCARE]->healthcare,
woman-[:MY_OUTDOOR]->outdoor,
woman-[:MY_INCOME]->income,
woman-[:MY_BORN]->born,
woman-[:MY_LOCATION]->location,
woman-[:MY_MARRIAGE]->maritalhistory,
woman-[:MY_PET]->pet,
woman-[:MY_EDUCATION]->education,
woman-[:MY_JOB]->job
ロードが終了したら、左のメニューを開いて関係性の作成をチェックしてみてください。(うまく見えない場合はページをリロードしてみてください)
以下は、[MY_EDUCATION」をクリックした場合の例です。表示するノード数は、自動的に25件に制限してくれます。
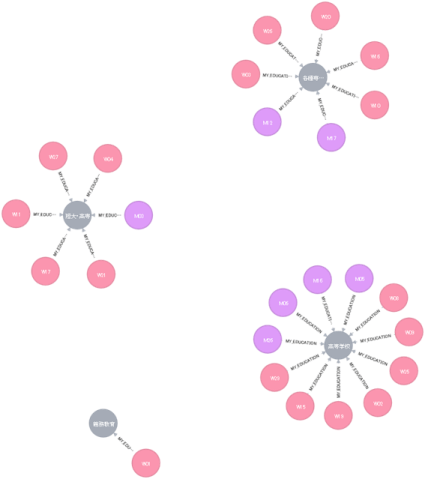
成立及び不成立のカップル作成
ここでは、リアリティを与えるために、成立したカップルを3組作っておきます。Webインターフェースで以下のクエリーをそれぞれ実行してください。
MATCH (man1:Person:Man { name:"M19"}),
(woman1:Person:Woman { name:"W01"}),
(man2:Person:Man { name:"M11"}),
(woman2:Person:Woman { name:"W09"}),
(man3:Person:Man { name:"M03"}),
(woman3:Person:Woman { name:"W23"})
//RETURN * LIMIT 25
CREATE man1-[:SUCCESS]->woman1,
man2<-[:SUCCESS]-woman2,
man3-[:SUCCESS]->woman3
さらに、不成立のカップルも1組作っておきます。
MATCH (man:Person:Man { name:"M04"}),
(woman:Person:Woman { name:"W04"})
//RETURN man, woman
CREATE woman-[:DISAGREE]->man
ちなみに、これらの男女は、まったく無作為に選んでいます。
ここまでで、GDBの準備が終わりました。これからは、Cypherを書いて様々な分析や候補者の予測をしてみます。
分析及び予測シナリオの作成と実行
成立カップルのグラフ出力
グラフを出力してみましょう。まず、成立したカップルのグラフを出力してみます。(PCのスペックによっては10秒~20秒ほど時間がかかります)
MATCH (item1)<--(p1)-[r:SUCCESS]-(p2)-->(item2)
RETURN *
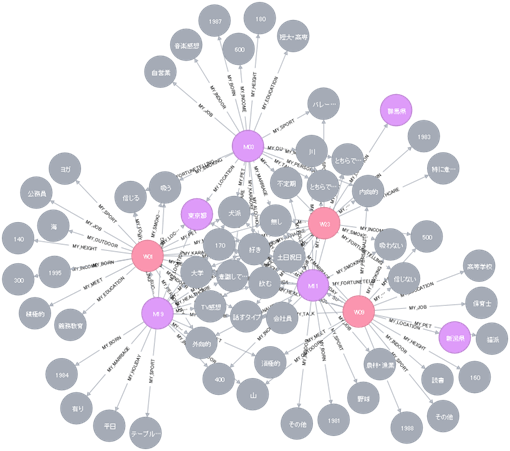
いかがでしょうか。グラフから何かの縁を感じられますか?
不成立のカップルのグラフ出力
次は、不成立のカップルのグラフを出力してみます。
MATCH (item1)<--(p1)-[r:DISAGREE]-(p2)-->(item2)
RETURN *
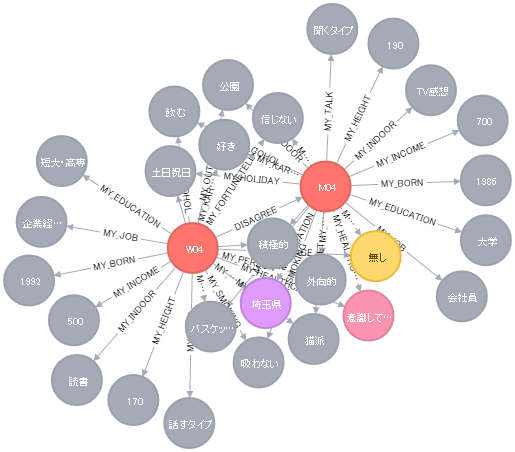
「運命の赤い糸」と言いますが、少なくともグラフ上ではすべて繋がっているように見えます。線の色が良くないのでしょうか。
成立及び不成立のカップルの方向
ここでは、今回成立及び不成立のカップルが、男女のどちらから申し込みをし、結果がどうなったのか検索しています。
MATCH (a:Man)-[r:SUCCESS|DISAGREE]->(b:Woman)
RETURN a.name+"--"+type(r)+"-->"+b.name AS result
UNION ALL
MATCH (a:Man)<-[r:SUCCESS|DISAGREE]-(b:Woman)
RETURN a.name+"<--"+type(r)+"--"+b.name AS result
成立したカップルの2組は、男性から女性に、1組は女性から男性に申し込みをしています。そして、不成立の1組は、女性から男性に申し込みをしています。
M03--SUCCESS-->W23
M19--SUCCESS-->W01
M04<--DISAGREE--W04
M11<--SUCCESS--W09
成立したカップルのプロファイル出力
ここでは、男性から女性に申し込みをして、成立したカップルのプロファイルを出力してみます。
MATCH
(a:Man)-[r:SUCCESS]->(b:Woman),
(a)-[*]->(things1),
(b)-[*]->(things2)
RETURN
a.name AS 男性 ,
b.name AS 女性,
collect(distinct things1.title) AS 男性の属性,
collect(distinct things2.title) AS 女性の属性
しかし、今回のように20種、合計158項目のプロファイルを目視で確認することは、とても困難です。どうしたら良いでしょうか。
男性 女性 男性の属性 女性の属性
M03 W23 [自営業, 短大・高専, 犬派, 無し, 東京都, 1987, 600, 川, 意識して運動する, 信じる, 好き, 飲む, 吸う, 音楽感想, 内向的, 180, とちらでもない, とちらでも良い, 不定期, バレーボール] [会社員, 大学, 犬派, 無し, 群馬県, 1983, 500, 川, 特に意識していない, 信じない, 好き, 飲む, 吸わない, TV感想, 内向的, 170, とちらでもない, 話すタイプ, 土日祝日, バレーボール]
M19 W01 [会社員, 大学, 犬派, 有り, 東京都, 1984, 400, 山, 意識して運動する, 信じる, 好き, 飲む, 吸う, TV感想, 外向的, 170, 消極的, 話すタイプ, 平日, テーブルテニス] [公務員, 義務教育, 犬派, 無し, 東京都, 1995, 300, 海, 意識して運動する, 信じる, 好き, 飲む, 吸う, TV感想, 外向的, 140, 積極的, 話すタイプ, 土日祝日, ヨガ]
成立したカップルの類似性の分析
次のCypherクエリーは、男性のプロファイルをベースに女性のプロファイルとの類似性を分析しています。
MATCH
(a:Man)-[r:SUCCESS]->(b:Woman),
(a)-[*]->(things1),
(b)-[*]->(things2)
WITH
a.name AS mName, b.name AS wName, collect(distinct things1.title) AS mans, collect(distinct things2.title) AS womans
WITH mName, wName, filter( x IN mans WHERE x IN womans) AS shared, mans
RETURN mName AS 男性, wName AS 女性, shared AS 共有プロファイル, 1.0 *length(shared)/length(mans) AS 類似性
ORDER BY 類似性 DESC
今回は、男女間の共有プロファイルの表示と共に類似性の比率まで分析しています。M19さんとW01さんのカップルは、互いのプロファイルの50%が一致し、M03さんとW23さんのカップルは40%が一致するという結果です。
男性 女性 共有プロファイル 類似性
M19 W01 [話すタイプ, 外向的, TV感想, 吸う, 飲む, 好き, 信じる, 東京都, 犬派, 意識して運動する] 0.5
M03 W23 [バレーボール, 内向的, 飲む, 好き, 川, 犬派, とちらでもない, 無し] 0.4
では、お互いに半分ぐらい似ている要素があればカップルになりやすいのでしょうか。このデータがリアルのデータで、標本として十分な数であれば、そうとも言えるかも知れません。しかし、今回の結果は、ランダムに生成したデータで、しかも、無作為にカップルにした2組の分析結果だということを忘れないでください。
今回、Cypherクエリーに取り入れている類似性分析のアルゴリズムは「Jaccard Similarity」と呼ばれるものです。実は、Cypherクエリーは、このようなアルゴリズムを組み立てることがとても得意な言語です。本題ではないので、詳しいことはWebなどを参照してください。(【参考1】Jaccard Similarity and Shingling(PDF))(【参考2】Jaccard係数とMin Hash(PDF))
成立していないカップルの類似性の分析
今回は、成立していないカップルの類似性を分析してみます。
MATCH
(a:Man)<-[r:DISAGREE]-(b:Woman),
(a)-[*]->(things1),
(b)-[*]->(things2)
WITH
a.name AS mName, b.name AS wName, collect(distinct things1.title) AS mans, collect(distinct things2.title) AS womans
WITH mName, wName, filter( x IN mans WHERE x IN womans) AS shared, mans
RETURN mName AS 男性, wName AS 女性, shared AS 共有プロファイル, 1.0 *length(shared)/length(mans) AS 類似性
結果は、65%で意外にも成立したカップルよりも類似性が高いことが分かりました。つまり、要素の類似性だけではカップルの成立・不成立を予測できない、ということになります。
男性 女性 共有プロファイル 類似性
M04 W04 [積極的, 土日祝日, バスケットボール, 飲む, 好き, 信じない, 意識して運動する, 外向的, 吸わない, 無し, 猫派, 公園, 埼玉県] 0.65
では、何がカップルの成立・不成立を決めているのでしょうか。それを探求するため、これからの分析は、M04さんにフォーカスを合わせてみます。
M04さんの理想の候補者を予測してみよう
M04さんのリクエストプロファイル
第1回の記事にて、問題点として挙げていますが、婚活をしている人には、オリジナルプロファイル(自分が持っている属性)とリクエストプロファイル(相手に求める属性)の2つのプロファイルがあります。当然、候補者を予測するなら、リクエストプロファイルを利用すべきです。前項の分析は、オリジナルプロファイルのみを利用しています。
ここで、M04さんのプロファイルをまとめてみましょう。当然ですが、オリジナルプロファイルとリクエストプロファイルには差があります。そして、必須の条件が付く場合もあります。
| カテゴリ | オリジナルプロファイル | リクエストプロファイル | 必須 |
| Alcohol | 飲む | 飲む | |
| Born | 1986 | 1981-1989 | ◎ |
| Education | 大学 | 短大以上 | ◎ |
| Fortunetelling | 信じない | 信じない | |
| Healthcare | 意識して運動する | 意識して運動する | |
| Height | 190 | 140-160 | ◎ |
| Holiday | 土日祝日 | 土日祝日 | |
| Income | 700 | 気にしない | |
| Indoor | TV感想 | 映画感想,ゲーム | |
| Job | 会社員 | 無職,学生,家事手伝は駄目 | ◎ |
| Karaoke | 好き | 好き | |
| Location | 埼玉県 | 埼玉県,千葉県,東京都,神奈川県 | ◎ |
| Maritalhistory | 無し | 無し | |
| Meeting | 積極的 | 積極的 | |
| Outdoor | 公園 | 海,川 | |
| Personality | 外向的 | 気にしない | |
| Pet | 猫派 | 猫派 | |
| Smoking | 吸わない | 吸わない | |
| Sport | バスケットボール | 気にしない | |
| Talk | 聞くタイプ | 話すタイプ |
今回のデータモデルには、リクエストプロファイルが反映されていません。そこで、パターンマッチを行うCypherクエリーを調整することで擬似的にリクエストプロファイルを反映した状態を再現してみます。
M04さんのプロファイルの調整
今回のデータモデルでM04さんのリクエストプロファイルを反映したCypherクエリーを書くためには、若干の調整が必要です。例えば、M04さんは、相手の収入(Income)を「気にしない」としているので、これはすべての金額のパターンで表現します。以下はパターンの例です。
[100,200,300,400,500,600,700,800,900]
そして、「1981-1989」の年齢のようなリクエストプロファイルは、範囲を指定し、その範囲以内であることを必須条件にしています。これは、次のように1981から1989まで範囲を一連のパターンとして表現します。
[1981,1982,1983,1984,1985,1986,1987,1989]
このようにし、最終的に完成したM04さんのリクエストプロファイルは、次のようなパターンになります。これを後のCypherクエリーの一部として組み込みます。
["飲む",1981,1982,1983,1984,1985,1986,1987,1989,"短大・高専","大学","大学院","信じない","意識して運動する",140,150,160,"土日祝日",100,200,300,400,500,600,700,800,900,"映画感想","ゲーム","公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","好き","埼玉県","千葉県","東京都","神奈川県","無し","積極的","海","川","外向的","内向的","猫派","吸わない","野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","話すタイプ"]
M04さんが断った女性との類似性
前項で調整したパターンを組み込んで、再び、M04さんとW04さんの類似性を分析してみます。
WITH ["飲む",1981,1982,1983,1984,1985,1986,1987,1989,"短大・高専","大学","大学院","信じない","意識して運動する",140,150,160,"土日祝日",100,200,300,400,500,600,700,800,900,"映画感想","ゲーム","公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","好き","埼玉県","千葉県","東京都","神奈川県","無し","積極的","海","川","外向的","内向的","猫派","吸わない","野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","話すタイプ"] AS list
MATCH (man:Man{name:"M04"})<-[:DISAGREE]-(woman),(woman)-[*]->(things)
WITH COLLECT(things.title) AS wlist, list
WITH filter( x IN list WHERE x IN wlist) AS shared
RETURN shared AS 共有要素, 1.0 * length(shared) / 20 AS パーセント
意外なことに、W04さんは、M04さんのリクエストを80%も満たしていることが分かりました。
共有要素 パーセント
[飲む, 短大・高専, 信じない, 意識して運動する, 土日祝日, 500, 企業経営・役員, 好き, 埼玉県, 無し, 積極的, 外向的, 猫派, 吸わない, バスケットボール, 話すタイプ] 0.8
M04さんが断った理由を探ってみる
一体なにが良くなかったんでしょうか。M04さんは、自分と共通性があまりない人を望んでいたのでしょうか。リクエストプロファイルを見る限り、そうでもありません。次のCypherクエリーでは、M04さんのリクエストを満たしていない要素と数を分析しています。
WITH ["飲む",1981,1982,1983,1984,1985,1986,1987,1989,"短大・高専","大学","大学院","信じない","意識して運動する",140,150,160,"土日祝日",100,200,300,400,500,600,700,800,900,"映画感想","ゲーム","公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","好き","埼玉県","千葉県","東京都","神奈川県","無し","積極的","海","川","外向的","内向的","猫派","吸わない","野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","話すタイプ"] AS list
MATCH (man:Man{name:"M04"})<-[:DISAGREE]-(woman),(woman)-[*]->(things)
WITH COLLECT(things.title) AS wlist, list
WITH filter( x IN wlist WHERE NOT(x IN list)) AS unshared, list
RETURN unshared AS 不一致, length(unshared) AS 数
身長(170)とインドアの趣味(読書)、アウトドアの趣味(公園)、年齢(1992)の4つのポイントでM04さんのリクエストプロファイルと異なるという結果になりました。そのなかでも、年齢(Born)と身長(Height)は、M04さんが必須条件として挙げていたことです。ここが、決定的な理由になったのかも知れません。
不一致 数
[170, 読書, 公園, 1992] 4
| アイテム | オリジナルプロファイル | リクエストプロファイル | 候補者 |
| Born | 1986 | 1981-1989 | 1992 |
| Height | 190 | 140-160 | 170 |
| Indoor | TV感想 | 映画感想,ゲーム | 読書 |
| Outdoor | 公園 | 海,川 | 公園 |
必須条件をクリアし、類似性が高い候補者を探してみよう
M04さんは、明確なリクエストを持っているので、まずは類似性が高い候補者を分析し、レコメンドしてみることにします。さらに、必須条件に強いこだわりをもっているようなので、今回は必須条件を徹底してフィルターすることにします。
WITH ["飲む",1981,1982,1983,1984,1985,1986,1987,1989,"短大・高専","大学","大学院","信じない","意識して運動する",140,150,160,"土日祝日",100,200,300,400,500,600,700,800,900,"映画感想","ゲーム","公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","学生","家事手伝","好き","埼玉県","千葉県","東京都","神奈川県","無し","積極的","海","川","外向的","内向的","猫派","吸わない","野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","話すタイプ"] AS list
MATCH (woman:Person:Woman)-[*]->(things)
WHERE NOT woman-[:DISAGREE|SUCCESS]-()
WITH woman, COLLECT(things.title) AS wlist, list
WITH woman, filter( x IN list WHERE x IN wlist) AS shared, [1995,1994,1993,1992,1991,1990,1980,1979,1978,1977,1976,1975,1974,1973,1972,1971,1970,170,180,190,200,"dummy"] AS list2
WHERE NONE ( x IN shared WHERE x IN list2)
RETURN woman.name AS 女性, shared AS 共有, 1.0 * length(shared) / 20 AS 類似性
ORDER BY 類似性 DESC
LIMIT 10
このCypherクエリーでは、M04さんがこだわりをもっている必須条件を満たす人のみを抽出しています。
以下のパターンがこのCypherクエリーの肝です。M04さんが望んでいない年齢と身長のパターンです。dummyを入れているのは、文字と数字が混ざっているリストと同条件(型="Any")にするためです。数字ばかりのリスト(型="Int")にすると、エラーになります。
[1995,1994,1993,1992,1991,1990,1980,1979,1978,1977,1976,1975,1974,1973,1972,1971,1970,170,180,190,200,"dummy"]
以下の構文は、上記のCypherクエリーの一部の抜粋です。shared(ある女性のプロファイル) にlist2(M04さんこだわりのパターン)の要素が1個でもあれば、sharedを丸ごとフィルターします。
WITH woman, filter( x IN list WHERE x IN wlist) AS shared, [1995,1994,1993,1992,1991,1990,1980,1979,1978,1977,1976,1975,1974,1973,1972,1971,1970,170,180,190,200,"dummy"] AS list2
WHERE NONE ( x IN shared WHERE x IN list2)
実行結果は、以下の通りです。M04さんのこだわりの条件をすべてクリアし、類似性が最も高い女性トップ10です。
女性 共有 類似性
W24 [1982, 大学, 意識して運動する, 140, 600, ゲーム, 自営業, 好き, 埼玉県, 無し, 積極的, 海, 外向的, 猫派, 吸わない, バレーボール] 0.8
W13 [飲む, 1984, 大学, 信じない, 意識して運動する, 150, 700, ゲーム, 自営業, 好き, 埼玉県, 無し, 海, 外向的, 吸わない, バスケットボール] 0.8
W12 [飲む, 1985, 大学, 意識して運動する, 160, 土日祝日, 600, 会社員, 好き, 無し, 積極的, 外向的, 猫派, 吸わない, バレーボール, 話すタイプ] 0.8
W16 [飲む, 1981, 信じない, 意識して運動する, 140, 土日祝日, 300, 映画感想, 医師, 好き, 東京都, 内向的, 猫派, 吸わない, バレーボール] 0.75
W05 [飲む, 大学, 意識して運動する, 150, 土日祝日, 400, 映画感想, 教師, 好き, 千葉県, 無し, 外向的, 吸わない, テーブルテニス, 話すタイプ] 0.75
W14 [飲む, 1983, 大学, 信じない, 160, 土日祝日, 400, 企業経営・役員, 好き, 神奈川県, 海, 内向的, 猫派, 野球, 話すタイプ] 0.75
W10 [飲む, 1987, 意識して運動する, 土日祝日, 400, 映画感想, 農林・漁業, 好き, 東京都, 無し, 海, 外向的, 猫派, 吸わない, 話すタイプ] 0.75
W18 [飲む, 大学, 意識して運動する, 160, 400, 保育士, 好き, 東京都, 積極的, 海, 内向的, 猫派, テーブルテニス, 話すタイプ] 0.7
W20 [飲む, 意識して運動する, 土日祝日, 600, パート・アルバイト, 好き, 東京都, 無し, 海, 外向的, 猫派, 吸わない, 散歩, 話すタイプ] 0.7
W17 [飲む, 短大・高専, 信じない, 150, 土日祝日, 700, 医療関係, 好き, 神奈川県, 無し, 川, 外向的, 吸わない, バスケットボール] 0.7
M04さんの候補者でリクエストと異なる要素をみる
上記のCypherクエリーで算出された、必須条件をすべて満たしている女性の方は、M04さんのリクエストプロファイルと異なる要素も持っています。では、リクエストプロファイルと異なる要素に対してM04さんはどのような判断をするのでしょうか。
WITH ["飲む",1981,1982,1983,1984,1985,1986,1987,1989,"短大・高専","大学","大学院","信じない","意識して運動する",140,150,160,"土日祝日",100,200,300,400,500,600,700,800,900,"映画感想","ゲーム","公務員","会社員","自営業","企業経営・役員","教師","医師","医療関係","保育士","農林・漁業","パート・アルバイト","好き","埼玉県","千葉県","東京都","神奈川県","無し","積極的","海","川","外向的","内向的","猫派","吸わない","野球","サッカー","バレーボール","バスケットボール","テーブルテニス","ヨガ","散歩","ダンス","話すタイプ"] AS list
MATCH (woman:Person:Woman)-[*]->(things)
WHERE NOT woman-[:DISAGREE|SUCCESS]-()
AND woman.name IN ["W24","W13","W12","W16","W05","W14","W10","W18","W20","W17"]
WITH woman, COLLECT(things.title) AS wlist, list
WITH woman,filter( x IN wlist WHERE NOT(x IN list)) AS unshared
RETURN woman.name AS 女性, unshared AS 不一致, length(unshared) AS 数
ORDER BY 数
M04さんのリクエストプロファイルと異なる要素は以下の通りです。M04さん頑張ってください!
女性 不一致 数
W12 [TV感想, 信じる, 遊園地, 群馬県] 4
W24 [平日, とちらでも良い, 飲まない, 信じる] 4
W13 [不定期, とちらでも良い, 消極的, 犬派] 4
W14 [とちらでもない, 寝る, 吸う, 特に意識していない, 有り] 5
W16 [とちらでも良い, 消極的, 山, 有り, 各種専門学校] 5
W05 [消極的, 信じる, 遊園地, 1991, 犬派] 5
W10 [その他, 消極的, 170, 信じる, 各種専門学校] 5
W18 [平日, TV感想, 吸う, 信じる, 1979, 有り] 6
W20 [とちらでもない, 180, 音楽感想, 信じる, 1977, 各種専門学校] 6
W17 [聞くタイプ, とちらでもない, 音楽感想, 特に意識していない, 1980, 犬派] 6
今回の婚活候補者の予測シナリオは、ここまでです。ここまで来ると、データさえ充実すれば様々なことにトライできることが想像できるでしょう。
前向きの発見と新たな問題点
第2回目の記事を進めながら、新たな発見と問題点を感じました。
前向きの発見
- リクエストプロファイルをデータモデルに反映せずに分析を行いましたが、Cypherクエリーで上手く分析することができた。今後、データモデルを検討する上でも、かなり役に立ちそうです。
新たな問題点
- 人の様々なパーソナリティを表す言葉に重複や曖昧な表現が存在すると、結果の数や意味の解析に影響があるように思われました。例えば、「その他」、「どちらでもよい」、「どちらでもない」のような言葉は避けるべきかもしれません。
- ある種類のサブドメインの要素の数が非常に多い場合、グループを表す言葉を検討すべきかもしれません。例えば、スポーツの場合は、全種目の名称を並べるより、種目自体(例えば球技など)を要素にしたほうが良いかもしれません。
- パターンマッチの結果値のカラム名の特定が困難。
まとめ
今回のデータモデルの実行では、手作業で候補者のリクエストプロファイルを反映するような形で、Cypherクエリーのパターンマッチを実行しましたが、候補者の問題点を探り出したり、理想の候補者のリストをランク付けで予測してみるなど、予想以上の有意義な結果を得ることができました。次回は、いままでにわかった問題点の解決に取り組んでみたいと思います。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



