
MongoDBに大量のテストデータ(数百万件)を挿入する #mongodb #mgodatagen

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
MongoDBテクニカルサポート担当の山森です。9月に入って少し暑さが和らいできました。
さて、MongoDBと戯れていると、数百万件程度のテストデータが欲しい時があります。以前はプログラムを作って実現しましたが、調べてみると、MongoDBにテストデータを生成して挿入したいという需要はそれなりにあるようです。今回の記事は、GitHub上で良さそうなオープンソースのツールを見つけたので、それを実際に使ってみたという内容です。
mgodatagenとは
https://github.com/feliixx/mgodatagen
数百万件のランダムなBSONドキュメントを生成し、MongoDBインスタンスに挿入するツールです。golangで実装されています。CLIで動作するので、mongoshが使用できる環境であれば導入可能です。
使用する際の注意点
こちらはMongoDB公式のツールではありません。有志の方々が作成&メンテナンスされています。最新のバージョンは2024/4/15リリースのの0.12.0です(2024/09/06現在)。MIT licenseが適用されています。
世の中にあふれるツールを使う時すべてに言えることですが、「定期的なメンテナンスが続くとは限らないこと」「適用されているライセンスの範囲で使用すること」を意識して導入する必要があります。今回はブログでの紹介という形で執筆・掲載していますが、弊社ではこのツールを使って発生したトラブルの責任を負いません。自己責任の範囲でご利用ください。
導入~とりあえず動かすところまで
GitHubのREADMEの「Installation」に従って進めます。git cloneしてgo buildするだけなので非常にシンプルです。golangがない場合は事前にインストールしておきます。
今回は以下の環境で動作を確認しています。nikaはユーザ名(一般)、rep1svはサーバのホスト名です。「rs0」という名前のレプリカセットのプライマリとして動作していて、セカンダリが2台います。
nika@rep1sv ~ $uname -a
Linux rep1sv 5.10.0-23-amd64 #1 SMP Debian 5.10.179-1 (2023-05-12) x86_64 GNU/Linux
nika@rep1sv ~ $cat /etc/debian_version
11.9
nika@rep1sv ~ $mongod --version
db version v6.0.14
Build Info: {
"version": "6.0.14",
"gitVersion": "25225db95574916fecab3af75b184409f8713aef",
"openSSLVersion": "OpenSSL 1.1.1w 11 Sep 2023",
"modules": [
"enterprise"
],
"allocator": "tcmalloc",
"environment": {
"distmod": "debian11",
"distarch": "x86_64",
"target_arch": "x86_64"
}
}
nika@rep1sv ~ $mongosh --version
2.2.1
git cloneでダウンロードしmgodatagenのディレクトリ配下でgo buildします。mgodatagenの実行ファイルが出来ていればOKです。
nika@rep1sv ~ $git clone https://github.com/feliixx/mgodatagen.git Cloning into 'mgodatagen'... remote: Enumerating objects: 2029, done. remote: Counting objects: 100% (308/308), done. remote: Compressing objects: 100% (149/149), done. remote: Total 2029 (delta 158), reused 226 (delta 148), pack-reused 1721 (from 1) Receiving objects: 100% (2029/2029), 2.13 MiB | 9.95 MiB/s, done. Resolving deltas: 100% (1337/1337), done. nika@rep1sv ~/mgodatagen $go build go: downloading github.com/jessevdk/go-flags v1.4.0 go: downloading github.com/gosuri/uiprogress v0.0.1 go: downloading github.com/iancoleman/orderedmap v0.3.0 go: downloading github.com/olekukonko/tablewriter v0.0.5 go: downloading go.mongodb.org/mongo-driver v1.15.0 go: downloading github.com/MichaelTJones/pcg v0.0.0-20180122055547-df440c6ed7ed go: downloading github.com/brianvoe/gofakeit/v6 v6.2.2 go: downloading github.com/google/uuid v1.6.0 go: downloading github.com/gosuri/uilive v0.0.4 go: downloading github.com/mattn/go-runewidth v0.0.9 go: downloading github.com/golang/snappy v0.0.1 go: downloading golang.org/x/crypto v0.17.0 go: downloading golang.org/x/sync v0.1.0 go: downloading golang.org/x/text v0.14.0 nika@rep1sv ~/mgodatagen $ls -l total 14496 -rw-r--r-- 1 nika nika 1057 Sep 6 14:52 LICENSE -rw-r--r-- 1 nika nika 25839 Sep 6 14:52 README.md -rw-r--r-- 1 nika nika 245 Sep 6 14:52 codecov.yml drwxr-xr-x 4 nika nika 4096 Sep 6 14:52 datagen/ -rw-r--r-- 1 nika nika 61461 Sep 6 14:52 demo.gif -rw-r--r-- 1 nika nika 1176 Sep 6 14:52 go.mod -rw-r--r-- 1 nika nika 6727 Sep 6 14:52 go.sum -rw-r--r-- 1 nika nika 882 Sep 6 14:52 main.go -rwxr-xr-x 1 nika nika 14710414 Sep 6 14:52 mgodatagen* -rwxr-xr-x 1 nika nika 274 Sep 6 14:52 test.sh*
これですぐに使えます。使用する際はJSONで書かれたコンフィグデータが必要です。今回はすでに用意されているコンフィグデータを使用してみます。mgodatagen/datagen/testdata配下にいくつか用意されているので、使ってみましょう。
https://github.com/feliixx/mgodatagen/tree/master/datagen/testdata
今回はその中の1つのindex_text.jsonを使ってみます。使い方は非常にシンプルです。
今回はMongoDB Serverがインストールされているサーバ上で実行しているため、オプションの指定は不要です(指定がないとlocalhostの27017ポートにアクセスします)。オプションでホスト名・ユーザ名・パスワード・認証方式の指定が可能です。詳しくはREADMEを参照してください。
nika@rep1sv ~/mgodatagen $./mgodatagen -f datagen/testdata/index_text.json connecting to mongodb://127.0.0.1:27017 MongoDB server version 6.0.16 Using seed: 1725861090 collection index_text: done [====================================================================] 100% +------------+-------+-----------------+------------------+ | COLLECTION | COUNT | AVG OBJECT SIZE | INDEXES | +------------+-------+-----------------+------------------+ | index_text | 32 | 48 | _id_ 4 kB | | | | | word_text 20 kB | +------------+-------+-----------------+------------------+ run finished in 30ms
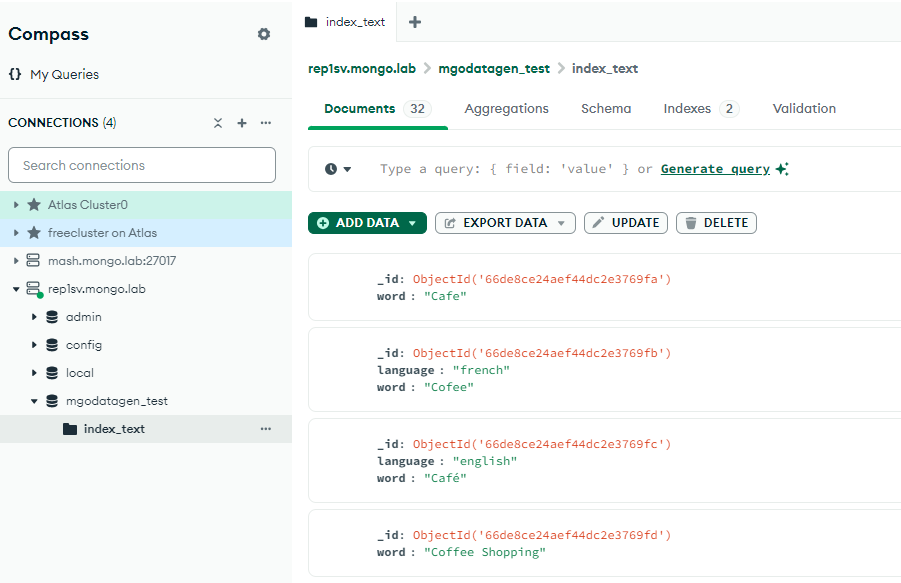
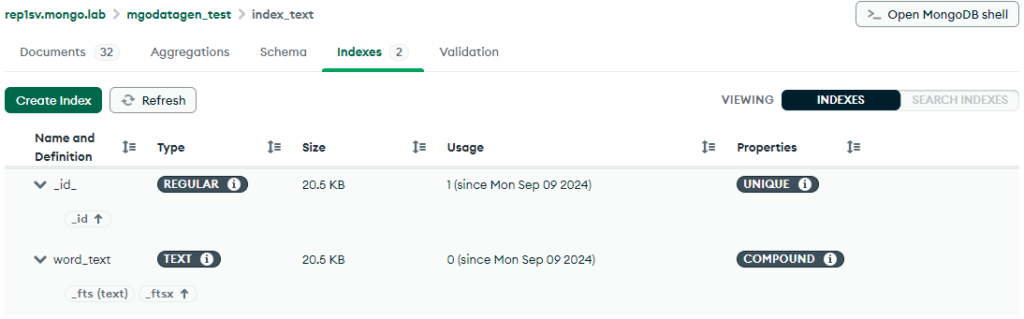
あっというまに実行が終わりました。結果表示を見ると「index_text」というコレクションが1つ、インデックスが2つ作られたようです。実際のデータをCompass(MongoDB公式GUIツール)を使って見てみます。
mgodatagen_testというデータベースが作られ、その配下にコレクションとインデックスが作られていますね。
では、index_text.jsonの中身はどうなっているのでしょうか。設定ファイルの中身を見てみます。
Optionsに設定ファイルの項目について解説されているので、照らし合わせて見ていきましょう。database,collectionはそのままデータベース名とコレクション名の定義です。countはドキュメントを何件挿入するかの値になっています。今回は32となっています。contentの下にデータのフィールドと、データの詳細を定義しています。
nika@rep1sv ~/mgodatagen/datagen/testdata $jq . index_text.json
[
{
"database": "mgodatagen_test",
"collection": "index_text",
"count": 32,
"content": {
"word": {
"type": "enum",
"values": [
"Cafe",
"Cofee",
"Café",
"Coffee Shopping",
"coffee and cream",
"Cafe con Leche"
]
},
"language": {
"type": "enum",
"nullPercentage": 80,
"values": [
"french",
"english"
]
}
},
"indexes": [
{
"name": "word_text",
"key": {
"word": "text"
},
"weights": {
"text": 1
},
"defaultLanguage": "french",
"languageOverride": "language",
"textIndexVersion": 3
}
]
}
]
これを読み解くと、なんとなく自分でも設定ファイルが書けそうですね。
カスタマイズしたテストデータを作る
それではテストデータを作っていきます。私がやりたい検証では、とにかく件数(1000万件程度)が欲しくてテストデータの中身はあまり重要ではなかったので、中身は自分の趣味で作りました。完成した設定ファイルは以下の通りです。
nika@rep1sv ~/mgodatagen $jq . personalKOJAKEdata_jp.json
[
{
"database": "サーモンラン従業員",
"collection": "コジャケ",
"count": 10000000,
"content": {
"_id": {
"type": "objectId"
},
"firstname": {
"type": "faker",
"method": "FirstName"
},
"lastname": {
"type": "faker",
"method": "LastName"
},
"phone": {
"type": "faker",
"method": "Phone"
},
"email": {
"type": "faker",
"method": "Email"
},
"workplace": {
"type": "enum",
"values": [
"アラマキ砦",
"ムニ・エール海洋発電所",
"シェケナダム",
"難破船ドン・ブラコ",
"すじこジャンクション跡",
"トキシラズいぶし工房",
"どんぴこ闘技場"
],
"randomOrder": true
},
"future course": {
"type": "enum",
"values": [
"ドスコイ",
"タマヒロイ",
"シャケコプター",
"オオモノシャケ",
"カタパッド",
"コウモリ",
"タワー",
"ダイバー",
"テッキュウ",
"テッパン",
"ナベブタ",
"バクダン",
"ハシラ",
"ヘビ",
"モグラ",
"キンシャケ"
],
"randomOrder": true
}
}
}
]
余談:JSONファイルはコード補完が入るVSCodeで作成しましたが、もっと効率の良い方法があったら教えてください。m(__)mペコッ
いったいなんのデータかというと、コジャケの個人情報です。
つまりこういうことです(スプラトゥーン内のサーモンランで登場するキャラクター。たくさんいる。)

設定ファイルをもとにデータを挿入していきます。さすがに1000万件は時間がかかりました(3分13秒)。MongoDB Serverを乗っけているサーバのRAMが4GBなので、ここを増設したらもっと早いかもしれません。
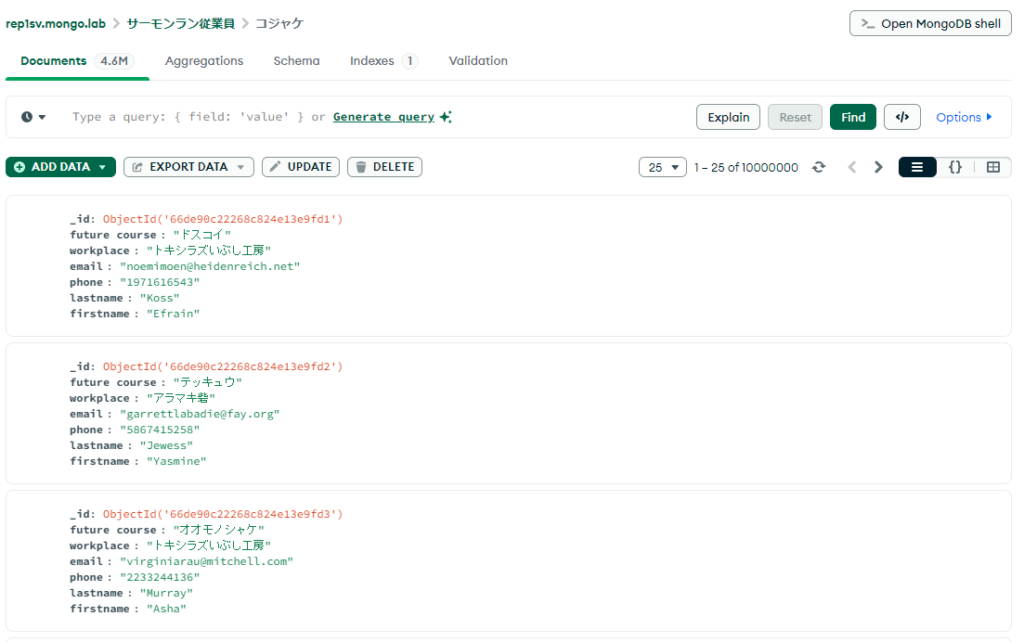
nika@rep1sv ~ $mgodatagen/mgodatagen -f personalKOJAKEdata_jp.json connecting to mongodb://127.0.0.1:27017 MongoDB server version 6.0.16 Using seed: 1725862082 collection コジャケ: done [====================================================================] 100% +------------+----------+-----------------+-----------------+ | COLLECTION | COUNT | AVG OBJECT SIZE | INDEXES | +------------+----------+-----------------+-----------------+ | コジャケ | 10000000 | 197 | _id_ 274084 kB | +------------+----------+-----------------+-----------------+ run finished in 3m13.24s
Compassで実際のデータが作成されたか見てみましょう。1000万件作成されたことも確認できました。
さいごに
JSONを書くのに少し手間取りましたが、慣れればインデックスやシャードを含めた、いろいろな形式なテストデータを作れるので、ある程度データモデルが決まっていてテストデータが欲しい…という場面で使えるかと思いました。



