
MongoDB Atlasで全文検索を行う:アナライザーと日本語の検索 #MongoDB #NoSQL
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
アナライザーとは
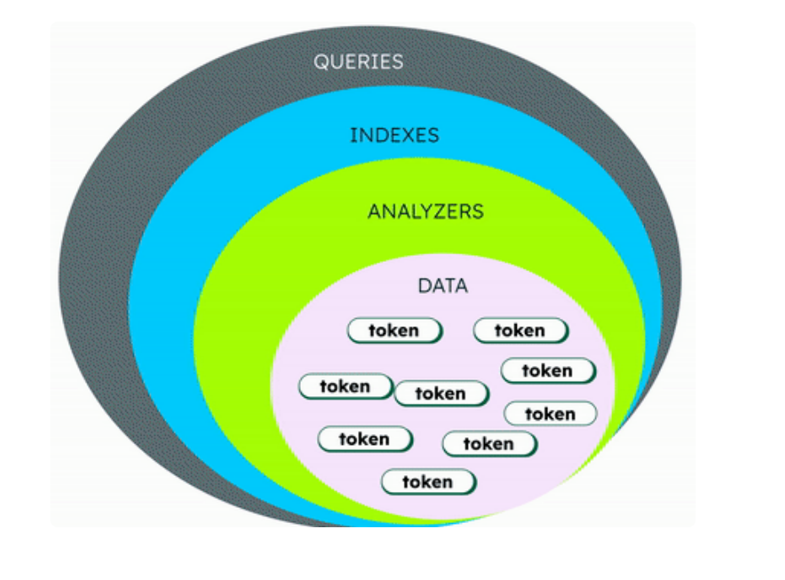
MongoDB Atlas上で日本語を含む多言語の全文検索が可能になりましたので使い方などを連載しています。一連の記事は、[関連記事]を参照してください。今回は、アナライザーと日本語の検索について紹介します。アナライザーは、テキストからトークンを抽出するトークナイザーとフィルターを組み合わせたポリシーであり、Atlasサーチがフィルドの内容を検索可能な用語に変換する方法を制御します。アナライザーはテキストを様々な構成の文字にトークン化し、抽出および文字の違いの修正などを行い、インデックス可能な用語にします。そのデータをどのような格納するかはデータタイプのマッピングで決めます。このようにアナライザーは、全文検索のクエリでテキストのなかの特定の文字が効率的にヒットできるようにします。
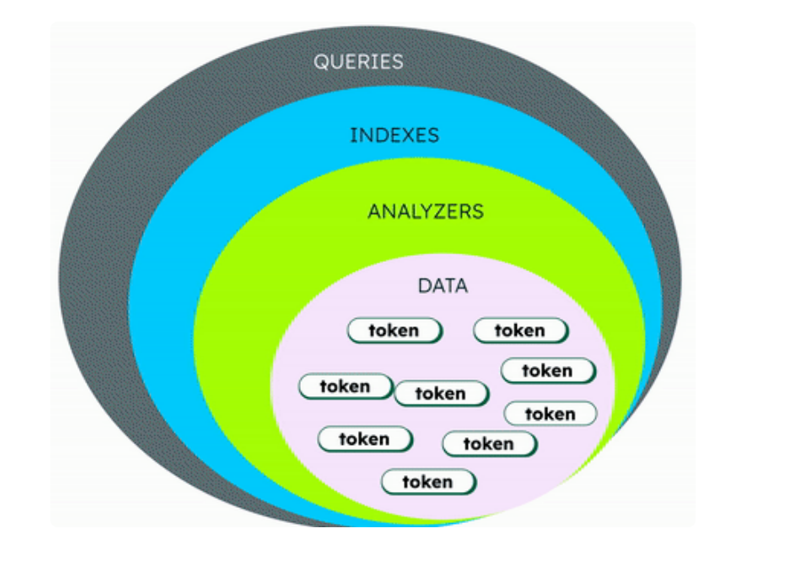
[トークン]
テキストや文字列などをインデックス可能な単位に分割することであり、「東京都と神奈川県」をトークン化すると、次ようになります。# 形態素解析
東京/都/と/神奈川/県# 2-gram
東京/京都/都と/と神/神奈/奈川/川県
[関連記事]
アナライザーのタイプ
Atlasサーチでは、次のようなタイプのアナライザーを提供しています。
| スタンダード | すべてのインデックスとクエリにデフォルトのアナライザー |
| シンプル | 文字以外の文字が見つかった場合に、テキストを検索可能な用語に分割 |
| ホワイトスペース | 空白文字が見つかった場所で、テキストを検索可能な用語に分割 |
| ランゲージ | 言語固有のテキスト アナライザーのセットを提供 |
| キーワード | テキストフィールドを単一の用語としてインデックス付け |
カスタムアナライザー
既定のアナライザーでは十分な効果が期待できない場合、ユーザーが最適化したアナライザーを作ることもできます。これをカスタムアナライザーと呼びます。カスタムアナライザーは、特定のインデックス作成のニーズに合わせて、フィルターやトークナイザー、トークンフィルターを指定して定義します。
"analyzers": [
{
"name": "",
"charFilters": [ ],
"tokenizer": {
"type": ""
},
"tokenFilters": [ ]
}
]
| 属性 | タイプ | 説明 | 指定 |
| name | ストリング | 任意の名称を指定 | 必須 |
| charFilter | オブジェクトリスト | 0個以上の文字フィルターを含む配列 | オプション |
| tokenizier | オブジェクト | トークン作成に使用する既定のトークナイザー | 必須 |
| tokenFilter | オブジェクトのリスト | 0個以上のトークンフィルターを含む配列 | オプション |
さらに詳しいことは、マニュアルを参照してください。
トークナイザー
Atlasサーチでは、次のトークナイザーオプションをサポートしています。トークナイザーは、Atlasサーチがインデックス作成のためにテキストを個別のチャンク (n-gram)に分割する方法を決定します。
| edgeGram | テキスト入力の左側または「エッジ」からの入力を所定のサイズの n-gram にトークン化 |
| keyword | 入力全体を単一のトークンとしてトークン化 |
| nGram | 指定されたサイズのテキスト チャンク (n-gram) にトークン化 |
| regexCaptureGroup | 正規表現パターンを照合してトークンを抽出 |
| regexSplit | 正規表現ベースの区切り文字でトークンを分割 |
| standard | ワードブレークルールに基づいてトークン化 |
| uaxUrlEmail | 電子メールアドレスをトークン化 |
| whitespace | 単語間の空白の発生に基づいてトークン化 |
さらに詳しいことは、マニュアルを参照してください。
マルチアナライザー
アナライザーは、"multi":{...}のように代替アナライザーを設定することができます。KeywordAnalyzerは、フィールド全体を 1 つの用語としてインデックス付けするため、検索用語と指定されたフィールドが完全に一致する場合にのみ結果を返します。アナライザーを指定しなかった場合、Altasサーチは標準アナライザーを使用します。
{
"mappings": {
"dynamic": false,
"fields": {
"title": {
"type": "string",
"analyzer": "lucene.standard",
"multi": {
"keywordAnalyzer": {
"type": "string",
"analyzer": "lucene.keyword"
}
}
}
}
}
}
さらに詳しいことは、マニュアルを参照してください。
日本語のデータのアップロード
日本語のデータのダウンロード
日本語のデータ(eventdata.zip)をダウンロードしてください。
このデータは、総務局から東京都のイベント一覧を入手し、英字のヘッダーをつけてUFT8に変換しています。
MongoDBデータベースツールのインストール
東京都のイベント一覧は、CSV形式であるためにmongoimportでアップロードします。
MongoDBデータベースツールをインストールしてください。インストールパッケージは MongoDBデータベースツールからダウンロードできます。お手許のOSに合わせてインストールしてください。ここでは、Windowsをベースにしていま(mongodb-database-tools-windows-x86_64-100.6.1.msi).
インストールパッケージは、次のようなツールが含まれています。
- mongodump/mongorestore
- bsondump
- mongoimport/mongoexport
- mongostat
- mongotop
日本語のデータのインポート
eventdata.csvを配置したディレクトリから、次のようにインポートを実行してください。
mongoimport --uri mongodb+srv://dbadmin:xxxxxxxx@cluster0.xxxxxx.mongodb.net/test --collection=events --type=csv --file=.\eventdata.csv --headerline 2022-10-21T18:43:18.877+0900 connected to: mongodb+srv://[**REDACTED**]@cluster0.xxxxxx.mongodb.net/test 2022-10-21T18:43:19.882+0900 29 document(s) imported successfully. 0 document(s) failed to import.
MongoDB Shellにログインし、結果を確認してください。
mongosh "mongodb+srv://dbadmin:xxxxxxxx@cluster0.xxxxxx.mongodb.net/test" --apiVersion 1 Current Mongosh Log ID: 6396fa30df09fa0e33aba025 Connecting to: mongodb+srv://@cluster0.xxxxxx.mongodb.net/test?appName=mongosh+1.1.9 Using MongoDB: 5.0.14 (API Version 1) Using Mongosh: 1.1.9 For mongosh info see: https://docs.mongodb.com/mongodb-shell/ Atlas Cluster0-shard-0 [primary] test>
例示では、ドキュメント数をカウントし、1行のドキュメントを表示しています。
Atlas Cluster0-shard-0 [primary] test> db.events.count()
DeprecationWarning: Collection.count() is deprecated. Use countDocuments or estimatedDocumentCount.
29
Atlas Cluster0-shard-0 [primary] test> db.events.findOne()
{
_id: ObjectId("635274122ab930d7e24d5c27"),
no: 1700000003,
code: 130001,
todohuken: '東京都',
shikumachi: '',
event_name: '東京消防出初式',
event_name_kana: 'トウキョウショウボウデゾメシキ',
event_name_en: '',
start_day: '2019/1/6',
start_time: '9:30',
end_day: '2019/1/6',
end_time: '11:50',
start_memo: '開場8:00',
desc: '東京消防出初式とは、消防車両分列行進、消防演技、音楽隊とカラーガーズ隊による演奏演技、江戸消防記念会による木遣り、はしご乗りなどを披露する新春恒例の防火・防災行事とし て、毎年多くの方々に親しまれています。屋内展示場では、消防車両の乗車体験、VR防災体験車、起震車による地震体験など、皆様に楽しみながら防災を理解していただけるコーナーも設けています。',
tax: 0,
basic_fee: '',
fee_memo: '',
contact_name: '東京消防庁',
contact_phone: '03-3212-2111',
sponsor: '東京消防庁',
co_sponsored: '',
location: '東京ビッグサイト',
postno: '135-0063',
addresss: '東京都江東区有明3-10',
formula: '東京ビッグサイト 東展示場東側埋立地',
latitude: 35.633223,
longitude: 139.800744,
access: 'りんかい線国際展示場駅徒歩7分・ゆりかもめ国際展示場正門駅徒歩3分',
…中略…
日本語のサーチインデックスを作成
MongoDB AtlasのDatabaseからインデックスを作成してみましょう。インデックス名を入力し、データベース(test)とコレクション(events)を設定し、Nextをクリックしてください。
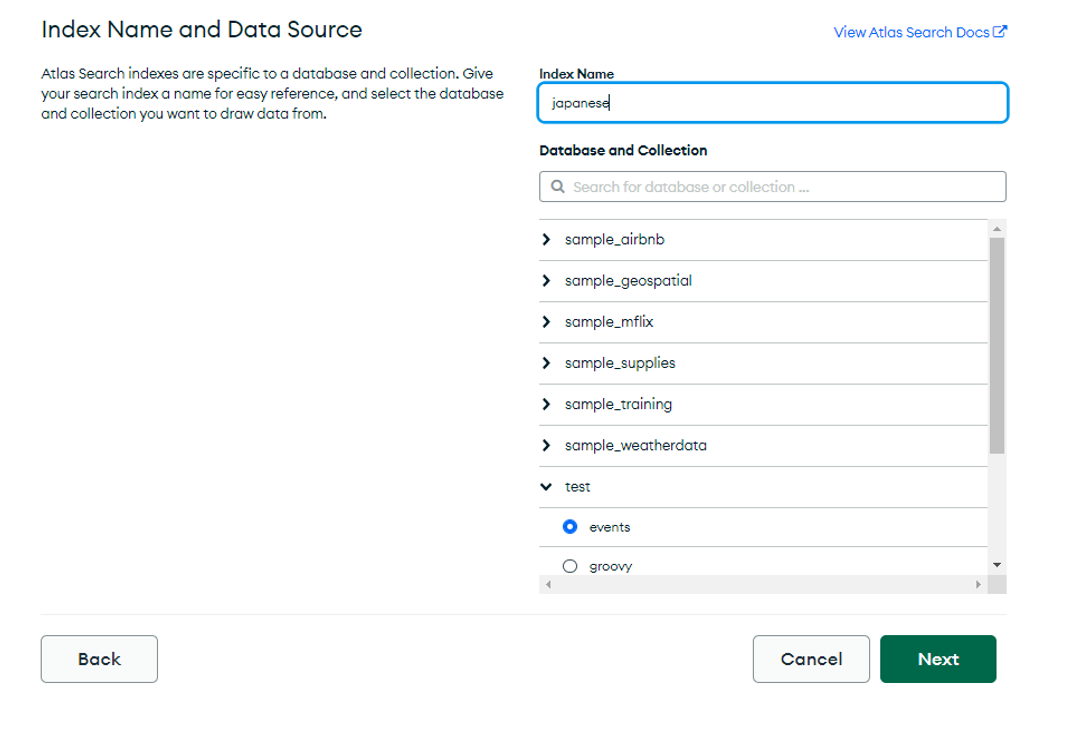
コレクションレベルのマッピングは、スタティックマッピング(dynamic:false)にしてください。
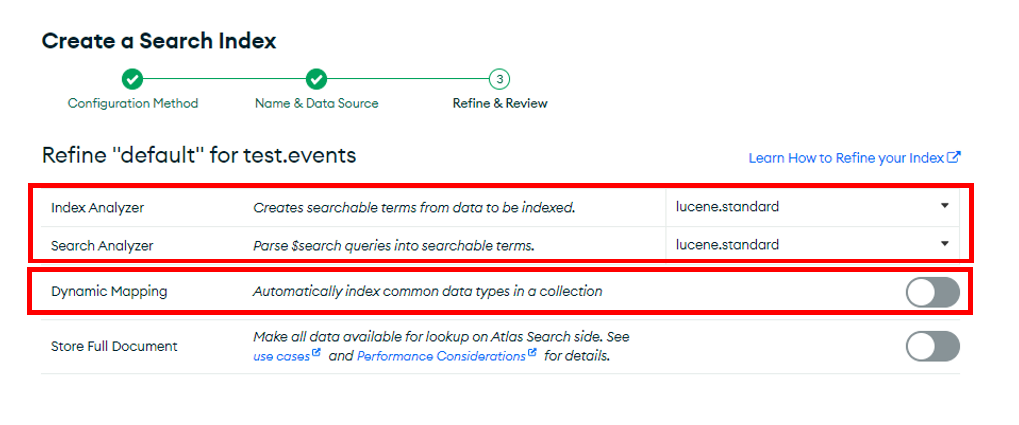
フィルドはイベントの説明(desc)を選定し、マッピングはスタティックマッピング(dynamic:false)にしてください。
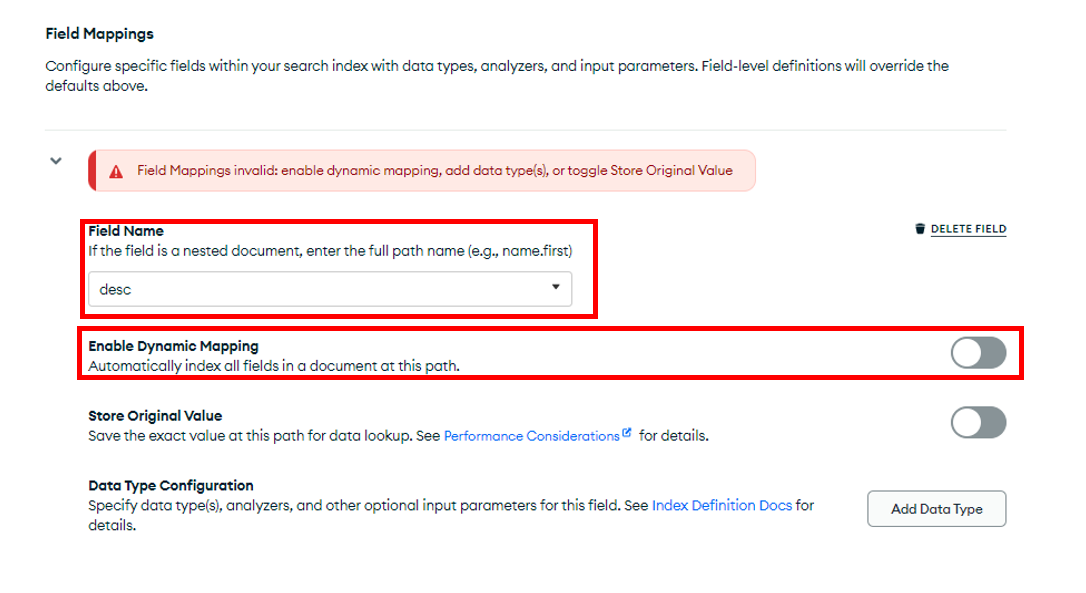
最後に、データタイプはストリン(String)、アナライザーは、lucene.languageからlucene.kuromojiを設定してください。
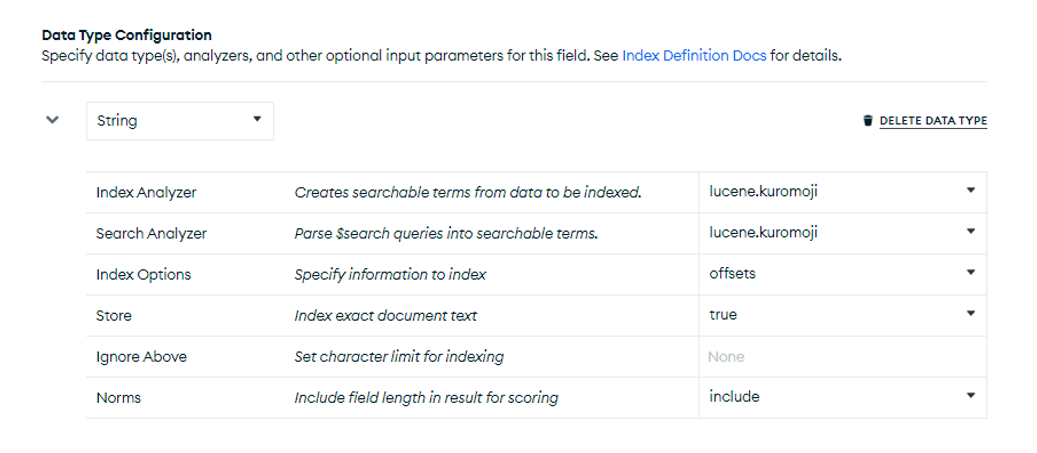
[lucene.japaneseとlucene.kuromojiのとちらを利用すべきか]
Altasサーチのlucene.languageでは、lucene.japaneseとlucene.kuromojiの二つのアナライザーを提供しており、とちらにすべきか迷います。Kuromojiは広く知られていますが、Japaneseはググってみても全く情報が得られません。全文検索に詳しい方に聞いてみると、Luceneはjapaneseからkuromojiに名称変更したような記憶があると言われました。MongoDBのサポートに確認してみると、テストの結果では機能の差がないという返事でした。ということで、lucene.kuromojiで問題ないと思います。
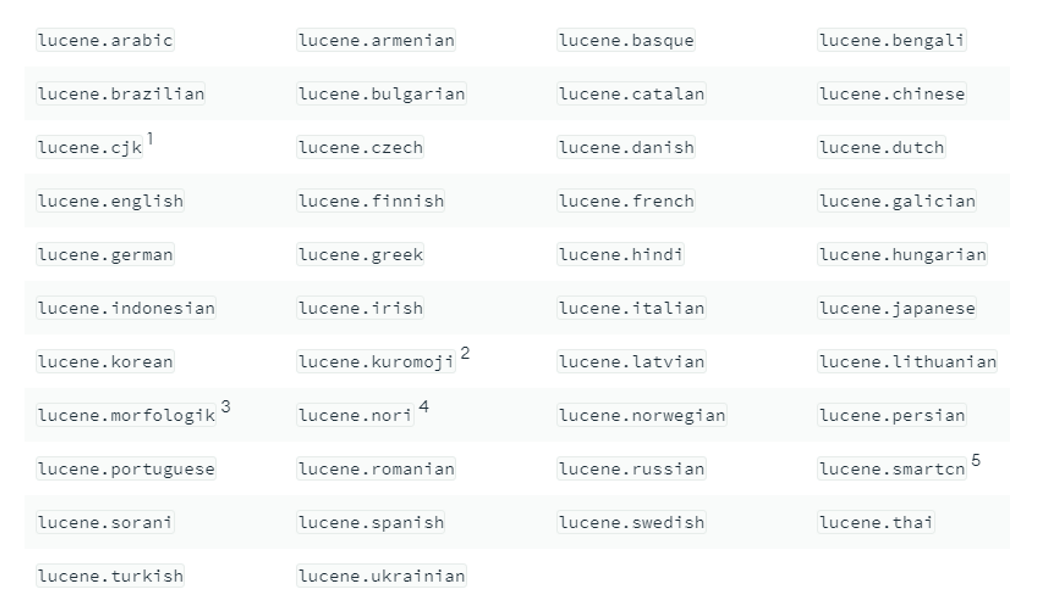
現在、Atlasサーチでは、次のような言語アナライザーを提供しています。
日本語の全文検索を実行
MongoDB Shellから、次のようなクエリを実行してみてください。このクエリでは、パス(desc)から[ "東京", "消防", "車両"]という文字が含まれているドキュメントを検索しています。これは、"*東京*" or "*消防*" or "*車両*"のようにワイルドカードを使ったような結果になります。
イメージしてみてください。検索対象のデータは、次ようなテキストです。
東京消防出初式とは、消防車両分列行進、消防演技、音楽隊とカラーガーズ隊による演奏演技、江戸消防記念会による木遣り、はしご乗りなどを披露する新春恒例の防火・防災行事と して、毎年多くの方々に親しまれています。屋内展示場では、消防車両の乗車体験、VR防災体験車、起震車による地震体験など、皆様に楽しみながら防災を理解していただけるコーナーも設けています。
db.events.aggregate([
{
$search: {
"index": "japanese",
"text": {
"query":[ "東京", "消防", "車両"],
"path": "desc"
}
}
},
{
$limit: 5
},
{
$project: {
"_id": 0,
"event_name": 1,
"desc":1
}
}
])
[
{
event_name: '東京消防出初式',
desc: '東京消防出初式とは、消防車両分列行進、消防演技、音楽隊とカラーガーズ隊による演奏演技、江戸消防記念会による木遣り、はしご乗りなどを披露する新春恒例の防火・防災行事と して、毎年多くの方々に親しまれています。屋内展示場では、消防車両の乗車体験、VR防災体験車、起震車による地震体験など、皆様に楽しみながら防災を理解していただけるコーナーも設けています。'
},
{
event_name: '第19回東京都障害者スポーツ大会 バレーボール競技(精神部門)',
desc: 'この競技は6人制バレーボールとほぼ同じルールで、ボールはソフトバレーボールを使用して実施します。また、東京都障害者スポーツ大会だけでなく、全国障害者スポーツ大会の正 式競技としても実施されています。普段からバレーボールを楽しまれている方だけでなく、これを機にチーム作りをして、東京の1番を目指してみませんか?多くの方のご参加、ご来場をお待ちしています。'
},
{
event_name: '平成30年度 東京都特別支援学校 アートキャラバン展(第4期)',
desc: '昨年度、東京都の全特別支援学校に通う子供たちの応募作品813点の中から、審査会を経て選ばれた50点の作品を、「第3回 東京都特別支援学校アートプロジェクト展」で展示しまし た。本キャラバン展は、その50点の作品の中から、東京藝術大学の監修の下、それぞれの会場の雰囲気などに合わせて、20~30点の作品を選んで展示している展覧会です。平成30年7月から平成31 年1月まで、都内の4会場で実施します。子供たちの創造力が生み出す、芸術の世界を御堪能ください。'
},
{
event_name: '第4回 東京都特別支援学校アートプロジェクト展 未来へ 心ゆさぶる色・形',
desc: '東京都教育委員会は、「第4回 東京都特別支援学校アートプロジェクト展 未来へ 心ゆさぶる色・形」を開催しますので、お知らせします。 都内特別支援学校に在籍する児童・生 徒の芸術活動への意欲喚起や才能の早期発見と伸長を図るとともに、広く都民に障害者への理解を促進するため、児童・生徒が制作した優れた作品を展示します。'
},
{
event_name: '<4月のイベントクルーズ>食文化クルーズ・つきぢ田村「五味調和と和食の話」と特別ランチ',
desc: '「五味調和」を掲げ現在の日本料理界を牽引してきた「つきぢ田村」、その三代目である田村隆氏から「五味調和と和食の話」を聴く。つきぢ田村で「東京水辺ライン特別ランチ」の 昼食。解散後は築地界隈を自由散策。(築地観光マップを配布)'
}
]
上手く、結果が得られましたか?
「東京消防/東京消/消防/消防車両/消防車/車両/防災体験/防災体/防災/体験」のように検証対象の文字列が多少揺れても問題なくヒットするはずです。
まとめ
今回は、日本語の全文検索におけるアナライザーの設定方法について簡略に紹介しました。日本語だから特別に難しくなるようなことはありません。既定のアナライザーが要件を満たすことが出来ない場合は、カスタムアナライザーを定義することも可能です。次回では、CLIによるマッピング定義などについてご紹介します。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



