
Apache Mahoutでレコメンドエンジン(Correlated Cross-Occurrenceアルゴリズム)を試作

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
こんいちは、クリエーションラインの朱です。
久しぶりに記事を書きますが、今回はレコメンドエンジンを試してみたいと思います。
レコメンデーションとは、相手に価値があると思われるコンテンツを提示することです。
例えばファミリーマートで会計時に店員さんは「ご一緒にファミチキもいかがでしょうか」と商品を勧めてくれます。これは店員さんが店及び個人の主観「このお客様はファミチキが好きそう」、「ファミチキの売上を上げたい」等に基づいたレコメンデーションです。
人間の主観ではなく、データから客観的なレコメンデーションをしたいという要望が多く存在します。この目的を叶える一つの手法としてレコメンドエンジンが使えます。
レコメンドエンジンには様々な手法が存在しますが、一般的に協調フィルタリング(Collaborative Filtering)が広く使われていて、いわゆるコンテンツベースフィルタリングの採用実績が一番多いです。今回は同じ協調フィルタリングではありますが、コンテンツベースフィルタリングの弱点を克服したアイテムベースフィルタリングを紹介したいと思います。
アイテムベースフィルタリング:Correlated Cross-Occurrenceとは
コンテンツベースフィルタリング、例えばALS(Alternating Least Squares)アルゴリズムはユーザの単一行動に対してのレコメンドしかできません。
それに対してアイテムベースフィルタリングは単一行動だけではなく、複数の行動に対応できます。例えば、行動1「ユーザAがある広告Xをクリックしました」が発生しました。アイテムベースフィルタリングはユーザの行動1に基づいて別の広告をレコメンドするのではなく、ユーザの別の行動、例えば行動2「ユーザAが商品を買う可能性がある」を予測することができます。
今回はアイテムベースフィルタリングの中のCorrelated Cross-Occurrenceアルゴリズムを紹介したいと思います。数学が苦手な方は予測モデルの数式だけを覚えれば十分だと思います。ではCorrelated Cross-Occurrenceを探検していきたいと思います。マトリクスの内積等の記号の説明はしませんのでご了承ください。
まずは単一ユーザ行動の例を見て行きたいと思います。
例)
ユーザがあるウェブサイトを閲覧した履歴
| User | Action | Item |
|---|---|---|
| User1 | view | iPad |
| User1 | view | Surface |
| User2 | view | iPad |
| User2 | view | Galaxy |
| User2 | view | Oppa |
| User2 | view | Huawei |
| User3 | view | Surface |
| User3 | view | Galaxy |
| User3 | view | Huawei |
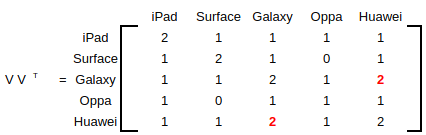
上記を整理すると、以下のUser-viewのマトリクスが作れます:

上記単一行動のレコメンド予測モデルは以下で表すことができます:
recommendation = (VT V) hv
VT V はco-occurrenceマトリクスと呼ばれていますが、アイテム間の関連が計算されています。
この例ですと、GalaxyとHuaweiの両方を閲覧したユーザが二人(赤文字のところ)いたことが分かります。またGalaxyとHuaweiの関連度が高いと考えられるため、Galaxyを閲覧したユーザがHuaweiも閲覧する可能性が高いというような分析ができます。
※上記は擬似データですので、スマホマーケットの調査結果を示しているものではありません。
hv はユーザの行動履歴と呼ばれていますが、分かりにくにので、queryとして考えてください。
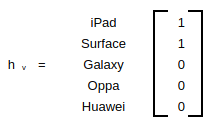
上記の例でいうと、「私はiPadとSurfaceが好きなので、商品を勧めてくれ」というqueryになります。
このように商品のおすすめ度のベクトルrecommendationを計算できます。
またここでは省略しますが、良い結果を得るためにはVT VにLLR(Log Likelihood Ratio)を適用する必要があります。正規化のようなものと考えれば良いと思います。LLRはApache Mahoutがやってくれますので、特に実装する必要がありません。
単一ユーザ行動のレコメンドが分かったところで、次に複数ユーザ行動に拡張します。
以下ユーザが広告をクリックした履歴があるとします。
| User | Action | Item |
|---|---|---|
| User1 | click | 広告A |
| User1 | click | 広告B |
| User1 | click | 広告C |
| User1 | click | 広告D |
| User2 | click | 広告A |
| User2 | click | 広告B |
| User3 | click | 広告C |
| User3 | click | 広告D |
前と同様にUser-clickのマトリクスCができます:
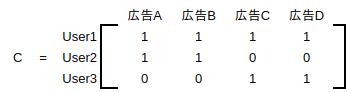
マトリクスCをrecommendationの数式に加えることで複数行動に基づいて、おすすめの商品を予測するモデルが出来上がります:
recommendation = (VT V) hv + (VT C) hc
今回queryを実行するために、hvの他にhcが必要になります。

上記のようにユーザの複数の行動にについて分析することができます。
Apache Mahout
アイテムベースフィルタリングを紹介しましたので、Correlated Cross-Occurrenceアルゴリズムを実装済みのApache Mahoutを紹介したいと思います。今回の実験もApache Mahoutを利用して実施します。
Apache Mahoutは本来無料で使用できるスケーラブルな機械学習アルゴリズムを作成することが目的でした。Apache MahoutはApache Hadoopライブラリーを使うことで、クラウドの中で Mahoutを効果的にスケーリングできるようにしていました。昔はHadoop+Mahoutが有名でしたが、現在のMahoutは拡張され、Mahoutベースで別プロジェクトとしてApache PredictionIOが存在します。Mahout自身はScala用の分散線形代数(Distributed Linear Algebra)計算ライブラリとなり、バックエンドもSparkに変わっています。Mahoutを使うとSpark RDDの間でスケーラブルな線形代数の計算ができます。特にデータ量が多く、自分でアルゴリズムを実装してPoCを行いたい時は強力なツールになると思います。またApache MahoutはScalaしかサポートしませんので、プロダクトを開発の場合はApache PredictionIOを選択したほうが良いでしょう。
因みにSpark2.xは全面的にDataframeのAPIを使うことを勧められていますが、MahoutはSparkのDataframeに対応する予定がないそうです。またgithub repositoryのコミットが活発ではないので、Apache PredictionIOがベターな選択かもしれません。
実験:
Apache Mahoutは分散線形代数(Distributed Linear Algebra)計算ライブラリということで、今回の目的をCorrelated Cross-Occurrenceプログラムを作成しSpark Clusterで動すことにしました。
作成しましたプログラムの紹介とSparkの紹介は一つの技術記事になりますので、割愛します。
実験環境:
Docker 18.06.1-ce
Spark 2.3.1
Scala 2.11
Mahout 0.13.0
Java 1.8
※Mahout 0.13.0はScala 2.11でコンパイルされたものを利用しました。
クラスタ構成は以下の通り:
| ノード | IPアドレス |
|---|---|
| masterノード | 172.17.0.2 |
| workerノード1 | 172.17.0.4 |
| workerノード2 | 172.17.0.5 |
※上記クラスタはPC一台にてDockerコンテナで作成しました仮想環境です
データ・セットについて
今回扱うデータはデータサイエンスコンペサイトkaggleから取ってきました。
https://www.kaggle.com/CooperUnion/anime-recommendations-database
データ・セットには2つファイルがあります。
-anime.csv
-rating.csv
73,516 ユーザが 12,294 アニメに対してのレイティングデータです。
アニメのレコメンドを作ることが考えられますが、今回はアニメではなく、自分の趣味と合うユーザをレコメンドできるようなレコメンドエンジンを作りたいと思います。
ではCorrelated Cross-Occurrenceアルゴリズムに合わせて、上記データ・セットから2つのユーザ行動を作成します。
ユーザが好きなアニメを抽出し、ユーザ行動1とします。
例:
| user_id | anime |
|---|---|
| 1 | Pokemon |
ユーザが好きなジャンルを抽出し、ユーザ行動2とします。
例:
| user_id | genre |
|---|---|
| 1 | Action |
| 1 | Drama |
| 1 | Sci-Fi |
※anime.csvのgenre列を利用していますが、「Action,Drama,Sci-Fi」のような複数ジャンルが混ざっている状態なので、「Action,Drama,Sci-Fi」を縦軸に展開しました。
※「ユーザが好き」というのはrating.csvのratingカラムの値が7以上であることを定義しています。その逆で例えば値が3以下のみを抽出すると、ユーザが嫌いなものも分析することができます。
モデルの評価について
Correlated Cross-Occurrenceアルゴリズムで作成したレコメンドモデルを評価するためにMAP@Kがよく使われる手法です。但し今回の場合、予測結果と比較するための観測値の取得が難しいため、評価はしません。本当に評価したい場合は別のレコメンドアルゴリズムで予測した結果を観測値と仮定し、モデルを評価する方法も考えられます。
Correlated Cross-Occurrenceアルゴリズムの実行結果
前述の通り、ユーザ行動を「好きなアニメと好きなジャンル」の2つに設定しましたので、今回のqueryを以下としていました。
私が好きなアニメ:
Cowboy Bebop
Witch Hunter Robin
Monster
Neon Genesis Evangelion
Ghost in the Shell
71 = Full Metal Panic!
Final Fantasy VII: Advent Children
Pokemon
Vampire Hunter D
Detective Conan Movie 05: Countdown to Heaven
Pokemon: Pikachu Tankentai
私が好きなジャンル:
Action
Fantasy
Adventure
Shounen
SuperPower
Comedy
Supernatural
Drama
私と同じ趣味のユーザIDを勧めてください。
実行結果として、Correlated Cross-Occurrenceアルゴリズムが以下のユーザをおすすめ度付きで勧めてくれました。(上位5ユーザのみを表示しています)
(3766,2247.687221864471), (4995,2108.613998122746), (6228,2050.3316726509947), (5698,1957.2375063486397), (2762,1954.221073256107))
上記結果はkey-valueのリストですが、keyがuser_idを示しており、valueはおすすめ度を示しています。
user_id=3766のおすすめ度が一番高くなっていますので、実際にuser_id=3766のユーザを確認しましょう。
※前述の通り、今回はアニメのratingが7以上が好きであることを前提で行っていますので、rating > 7のレコードのみを抽出しました。
SELECT anime.anime_id, anime.name, anime.genre, rating.user_id, rating.rating FROM anime INNER JOIN rating on rating.anime_id = anime.anime_id WHERE rating.user_id = 3766 AND rating.rating > 7;
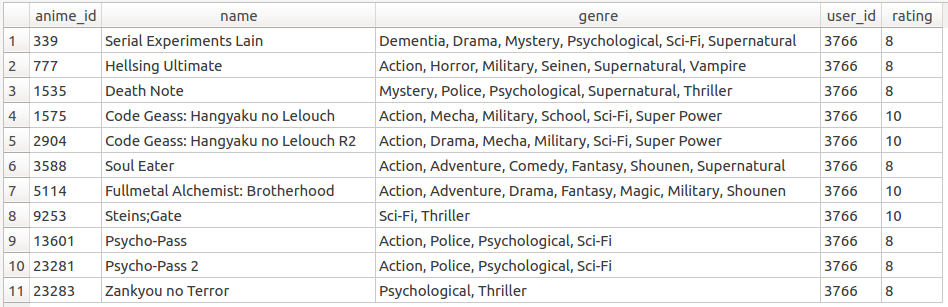
上記テーブルの通り、queryで設定したジャンルと大体一致していますが、queryで設定したアニメ名はuser_id=3766とあっていないようですね。実はレコメンドエンジンは類似したアイテムを予測してくれるので、queryと同じものを探すわけではありません。正確に結果を検索するのが絞り込み検索で、類似したアイテムを検索するのがレコメンドエンジンです。
anime.csvファイルのgenre列(ジャンル)は複数のジャンル名が混ざっていますが、queryにはない類似ジャンルが入っていることが分かります。
上記によって、私が鑑賞しそうなアニメは上記テーブルの通りであることが分かります。
また、Apache Mahoutのドキュメントを確認すると、できる限り履歴を集める必要があるようです。つまり、単純なqueryではなく、queryに好きなアニメとジャンルをできるだけ増やすとより良い結果を得られるということです。
最後Mahoutのマトリクス計算はクラスタ上で上手く分散できたかを確認します。
下図の通り、2つのWorkerノード(172.17.0.4と172.17.0.5)にそれぞれ62個のタスクがアサインされ、処理されました。
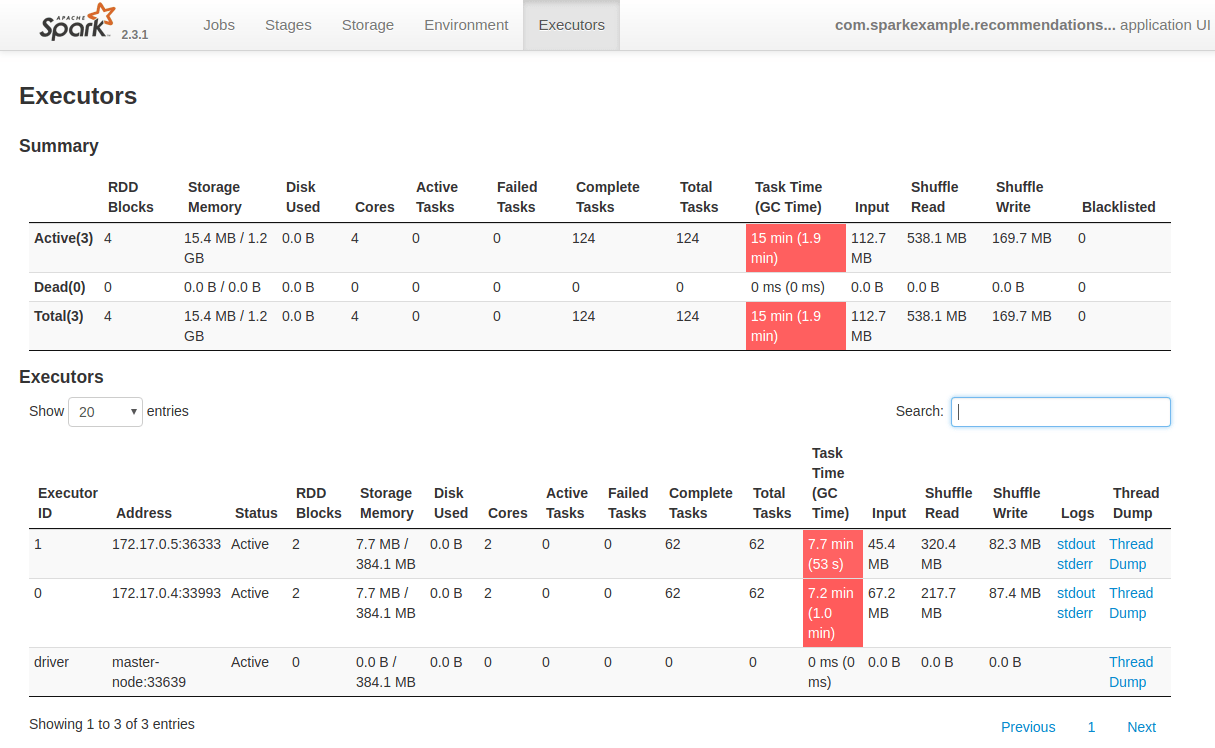
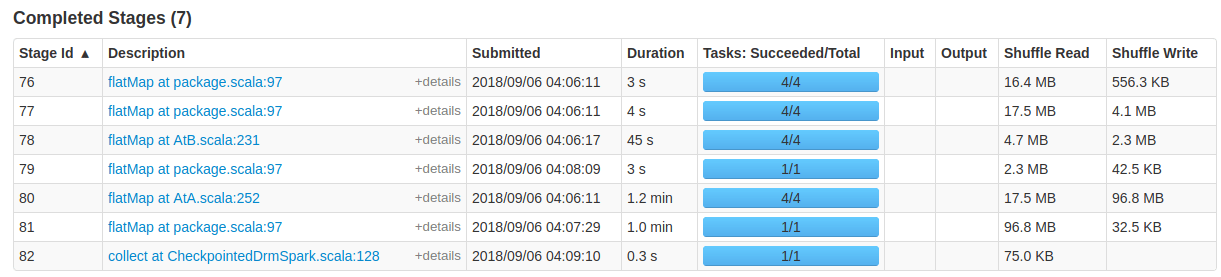
ではタスクを確認すると、さきほど、ご紹介しました、recommendation式の計算が見れます。下図のStage Idが78と80が前述のco-occurrenceマトリクスの計算になります。
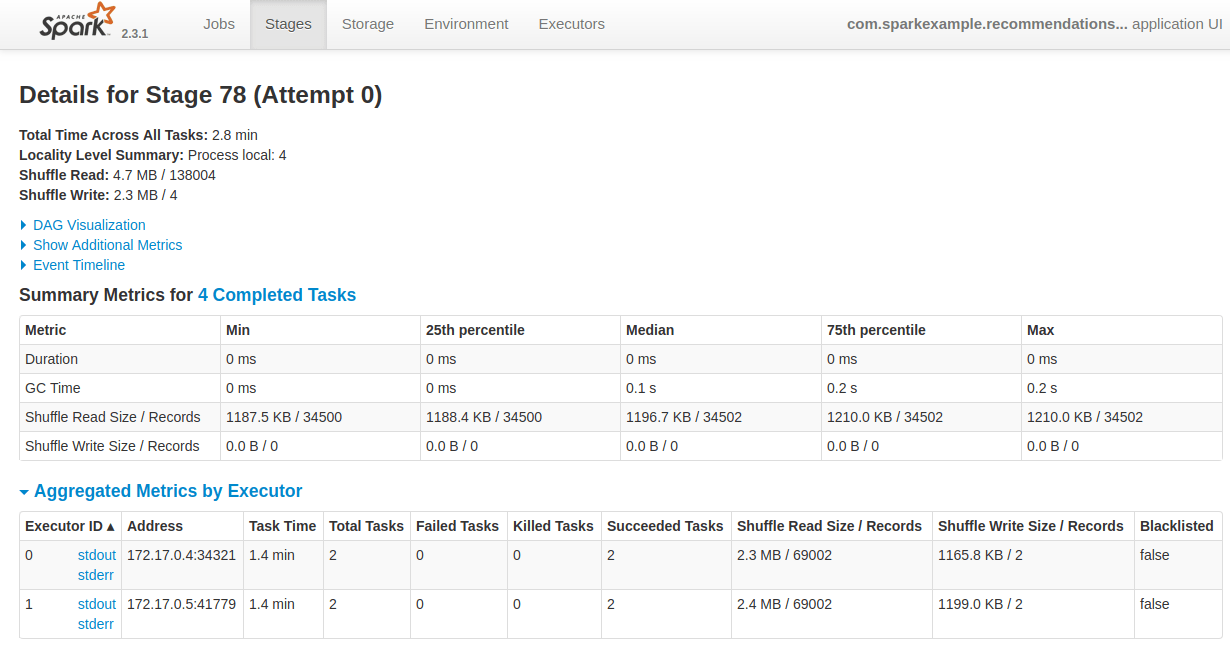
では、Stage Idの78を内容を見て行くと、下図の通り、Stage内の4タスクが2個つづWorkerノードに分散して処理されたことが分かります。但し、当り前ですが、Shuffleが発生していました。各ノードのShuffleされたレコード数は69002なので、性能が微妙になりました。今回のデータ・セットは1ノードのメモリに格納できるサイズなので、性能検証はしませんでした。
まとめ
以上で、Apache Mahoutを使ってCorrelated Cross-OccurrenceアルゴリズムをSpark Cluster上で動かして見ました。複数のユーザ行動からレコメンドエンジンを作ることができますので、ユーザの行動分析には使えそうです。但し、Spark Clusterで動くとはいえ、性能はどうなのかは懸念点なので、また検証したいと思います。
今回作成したソースコードはgithubにコミットしてありますので、興味をお持ちの方はご参照ください。
https://github.com/george-j-zhu/Spark2.3.1-Mahout0.13.0-example
今回の内容は以上です。いかがでしたでしょうか。
弊社はレコメンドエンジンの実験検証、実装なども担当しております。
興味をお持ちであれば、お気軽に弊社営業 sales@creationline.com または お問い合わせページ よりお問い合わせください。
参考
[1] https://mahout.apache.org/
[2] http://actionml.com/blog/making_dislikes_predict_likes
[3] https://www.kaggle.com/CooperUnion/anime-recommendations-database
[4] http://actionml.com/docs/ur



