
Apache Spark縛りでKaggleのコンペティションやってみた #Spark

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

こんにちは。木内です。
今回はデータサイエンティストのコンペティションサイトとして有名な kaggle に Apache Spark で挑戦してみたいと思います。
使っている方は知ってはいるのですが、実は kaggle では Apache Spark を使用している人はあまり多くありません。日本でも kaggle の例を見てみると、Python+numpy+pandas+scikit-learn(+TensorFlow)という組み合わせで挑戦している方が多数です。
今回の記事はあえてApache Spark縛りで kaggle のコンペティションに参加してみて、実際 Pandas/numpy/scikit-learnでやっていることをApache Sparkに置き換えることができるのか、置き換えるとしたらどうするのか、というところに着目し、実際に結果を投稿するところまでやってみたいと思います。
Apache Sparkを利用するメリットとしては、処理するPCが比較的大きくなくても、大きなデータセットを扱うことができる点です。つまり時間をかけても構わないのであれば、クラスタ構成でした処理できないような大規模データを手元のパソコンで処理することができるようになります。もちろんクラスタ構成で Apache Spark を使用すれば処理ノード数に応じた性能の向上を期待することができます。
もちろん kaggle のコンペティションは処理速度だけではなく機械学習アルゴリズムそのものの性能や、以下にデータから特徴を引き出せるかによって順位に大きな変動が出るため、Apache Spark で大きなデータセットを扱うことや処理性能を向上させることと Kaggle で competitve かどうかは別の話です。あしからず。
でははじめましょう。
参考にしたサイト
ここでは Qiita の "Kaggleの練習問題(Regression)を解いてKagglerになる" : https://qiita.com/katsu1110/items/a1c3185fec39e5629bcb を参考に、できるだけ Apache Spark の機能を使って同じことをすることにします。
従って行うコンペティションは練習用の "House Prices: Advanced Regression Techniques" とします。処理用のデータセットは予め手元にダウンロードしておきます。
データのロード、表示
Pandas では CSV データのロードは非常にかんたんで、 "read_csv" を呼ぶだけです。読み込んだ CSV は Pandas の Dataframe になります。
python
import pandas as pd
df = pd.read_csv("train.csv.gz")
Apache Spark は少し前までは CSV の読み込みを標準でサポートしていなかったのですが、最近ではそのまま読み込むことができます。以下のようにすれば CSV ファイルを読み込み、Apache Spark の Dataframe になります。
python
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").getOrCreate()
# CSVのデータファイルを読み込み
df = spark.read.format("csv") \
.options(header="true", \
nanValue="NA", \
nullValue="NA", \
inferSchema=True) \
.load("train.csv.gz")
Jupyter Notebook(あるいはJupyterLab) を使用している場合、Pandas Dataframeの表示は非常にかんたんです。きれいな表で表示され、列の数が多い場合でも適宜省略したり、スクロールして内容をかんたんに把握することができます。
python from IPython.core.display import display display(df.head(5))
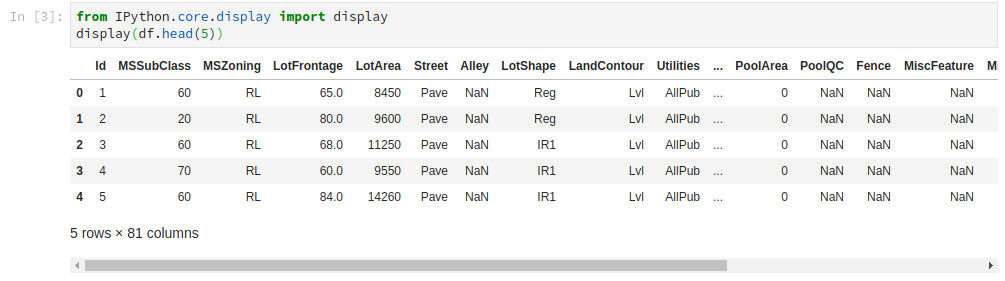
Apache Spark では Dataframe の "show()" メソッドで表示することができるのですが、全てテキストで表示されてしまうため、列の数が多くなると内容の確認がやりづらくなってしまいます。これではデータの確認だけでげんなりしてしまいそうです。
python df.show(5)

分析においてはデータの状況をざっと見ることができることも重要な点です。しかしこれではざっと内容を確認することが難しく、実用には適しません。そこで Spark Dataframe の内容を Pandas Dataframe に変換して表示するように、お助け関数を作成します。
python
def printDf(sprkDF):
# format Spark Dataframe like pandas dataframe
# sparkのdataframeをpandasのdataframeのように整形して出力する
newdf = sprkDF.toPandas()
from IPython.core.display import display, HTML
return HTML(newdf.to_html())
display(printDf(df.limit(5)))
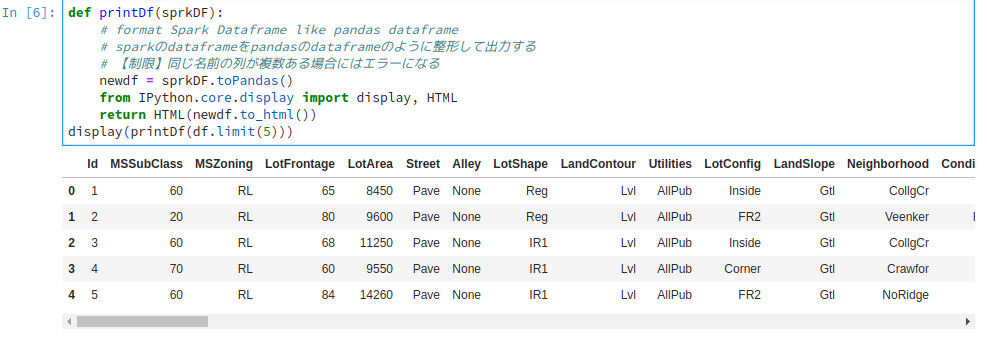
これでだいぶ見やすくなりました!データも見やすくなり、やる気が出てきますね!
ラベルエンコーディング
次は文字列で構成されている列を機械学習アルゴリズムに与えやすいよう数字に置き換えます。
scikit-learn の "LabelEncoder" ライブラリは文字列で構成されたカラムを読み込み、数値に置き換えてくれます。これは非常に便利なライブラリです。
[cc lang="python"]python
from sklearn.preprocessing import LabelEncoder
for i in range(train.shape[1]):
if train.iloc



