
Docker Swarmマネージャの障害復旧 #mirantis #docker #swarm

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本稿ではDocker Swarmマネージャの障害復旧について、
- 定足数(Quorum; クォーラム)を満たした状態での復旧
- 定足数を満たさない状態からの復旧
- マネージャをすべて喪失した状態からの復旧
の3パターンについて見ていきます。
前提条件
- VirtualBox/Vagrantで環境を準備。
- CentOS 7
- Docker CE 20.10.10
- Swarmマネージャ3台のHA構成とSwarmワーカー2台の、計5台のクラスタ。
Swarmクラスタの準備
次のVagrantfileでゲストOSを準備します。IPアドレスやメモリは必要に応じて変更してください。
nodes = {
'manager01' => '192.168.123.101',
'manager02' => '192.168.123.102',
'manager03' => '192.168.123.103',
'worker01' => '192.168.123.201',
'worker02' => '192.168.123.202',
}
Vagrant.configure("2") do |config|
config.vm.box = "centos/7"
config.vm.box_check_update = false
nodes.each do |node_name, ipaddr|
config.vm.define node_name do |cf|
cf.vm.hostname = node_name
cf.vm.network "private_network", ip: ipaddr
cf.vm.provision "docker"
cf.vm.provider "virtualbox" do |vb|
vb.memory = 3072
end
end
end
end
manager01, manager02, manager03をSwarmマネージャ、worker01, worker02をSwarmワーカーとしてクラスタを構築します。
まず manager01 でSwarm初期化を実行します。
[vagrant@manager01 ~]$ docker swarm init --availability=drain --advertise-addr 192.168.123.101 Swarm initialized: current node (i2cylwqkd2jtppmickcz38wr1) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-8emzlfehglbpjcrfzw706ys4g 192.168.123.101:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
初期化オプションとして--availability=drainを付与して、ワークロードコンテナをマネージャ上に起動しないようにしています。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i2cylwqkd2jtppmickcz38wr1 * manager01 Ready Drain Leader 20.10.10
マネージャ参加トークンを払い出します。
[vagrant@manager01 ~]$ docker swarm join-token manager To add a manager to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377
manager02 と manager03 でこれを実行し、マネージャとしてクラスタに参加させます。またこの際もオプションとして--availability=drainを付与して、ワークロードコンテナを起動しないようにします。
[vagrant@manager02 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377 This node joined a swarm as a manager.
[vagrant@manager03 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377 This node joined a swarm as a manager.
これで3台によるHA構成のSwarmマネージャが構築できました。これにより、3台のうち1台までのクラッシュや停止が許されます。詳細は Add manager nodes for fault tolerance をご覧ください。
次に worker01 と worker02 で、Swarm初期化時に表示されたワーカー参加コマンドを実行します。
[vagrant@worker01 ~]$ docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-8emzlfehglbpjcrfzw706ys4g 192.168.123.101:2377 This node joined a swarm as a worker.
[vagrant@worker02 ~]$ docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-8emzlfehglbpjcrfzw706ys4g 192.168.123.101:2377 This node joined a swarm as a worker.
これでHA構成のSwarmマネージャ3台とSwarmワーカー2台の計5台のクラスタが構築できました。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i2cylwqkd2jtppmickcz38wr1 * manager01 Ready Drain Leader 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Ready Drain Reachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
簡単な図にすると次のようになります。
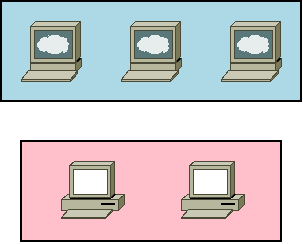
これにMirantis社公認Dockerトレーニングで用いられているサンプルアプリDockerCoinsをデプロイしてみましょう。ただしこのままだと各サービスのコンテナが1つずつしか起動しないので、少し手を加えて多くのコンテナが起動するようにします。
[vagrant@manager01 ~]$ curl -LO https://raw.githubusercontent.com/docker-training/orchestration-workshop/ee3.0/dockercoins/docker-compose.yml [vagrant@manager01 ~]$ cp -a docker-compose.yml docker-compose.yml.orig [vagrant@manager01 ~]$ vi docker-compose.yml
[vagrant@manager01 ~]$ diff -u docker-compose.yml.orig docker-compose.yml --- docker-compose.yml.orig 2021-11-17 02:17:18.923986228 +0000 +++ docker-compose.yml 2021-11-17 02:18:49.958987464 +0000 @@ -7,6 +7,8 @@ - dockercoins ports: - "8001:80" + deploy: + mode: global hasher: image: training/dockercoins-hasher:1.0 @@ -31,6 +33,9 @@ image: training/dockercoins-worker:1.0 networks: - dockercoins + deploy: + mode: replicated + replicas: 4 networks: dockercoins:
デプロイします。
[vagrant@manager01 ~]$ docker stack deploy -c docker-compose.yml dc Creating network dc_dockercoins Creating service dc_hasher Creating service dc_webui Creating service dc_redis Creating service dc_worker Creating service dc_rng
次のようになりました。先にSwarmマネージャではワークロードコンテナを起動しないようにしたため、worker01 と worker02 のみでコンテナが起動しています。
[vagrant@manager01 ~]$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS i2hbj25s8k3l dc_hasher replicated 1/1 training/dockercoins-hasher:1.0 *:8002->80/tcp mghdfsmtcc9l dc_redis replicated 1/1 redis:latest pvfzzcjy61kd dc_rng global 2/2 training/dockercoins-rng:1.0 *:8001->80/tcp quxlyqf9kjem dc_webui replicated 1/1 training/dockercoins-webui:1.0 *:8000->80/tcp rid41xkrfzzl dc_worker replicated 4/4 training/dockercoins-worker:1.0 [vagrant@manager01 ~]$ docker service ps $(docker service ls -q) ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS zuudxvy4ncuw dc_hasher.1 training/dockercoins-hasher:1.0 worker01 Running Running about a minute ago mpb2anujjlsj dc_redis.1 redis:latest worker02 Running Running about a minute ago fo059jo0q6nb dc_rng.uwhi7yqd7ir3oqy6r32bkz513 training/dockercoins-rng:1.0 worker01 Running Running about a minute ago h05fo90aracw dc_rng.ykhntr9vgpdkibgacbjapj8xz training/dockercoins-rng:1.0 worker02 Running Running about a minute ago jh6v6pu7tzcc dc_webui.1 training/dockercoins-webui:1.0 worker02 Running Running about a minute ago dei0olkvs9dx dc_worker.1 training/dockercoins-worker:1.0 worker02 Running Running about a minute ago uhwoak1etcsh dc_worker.2 training/dockercoins-worker:1.0 worker01 Running Running about a minute ago 9oxd0nnr3ekq dc_worker.3 training/dockercoins-worker:1.0 worker02 Running Running about a minute ago q3sv0jh1t3ep dc_worker.4 training/dockercoins-worker:1.0 worker01 Running Running about a minute ago
ブラウザで http://192.168.123.101:8000/ http://192.168.123.102:8000/ http://192.168.123.103:8000/ http://192.168.123.201:8000/ http://192.168.123.202:8000/ にアクセスし、次のDockerCoinsのWebUIが表示されれば正常に動作しています。
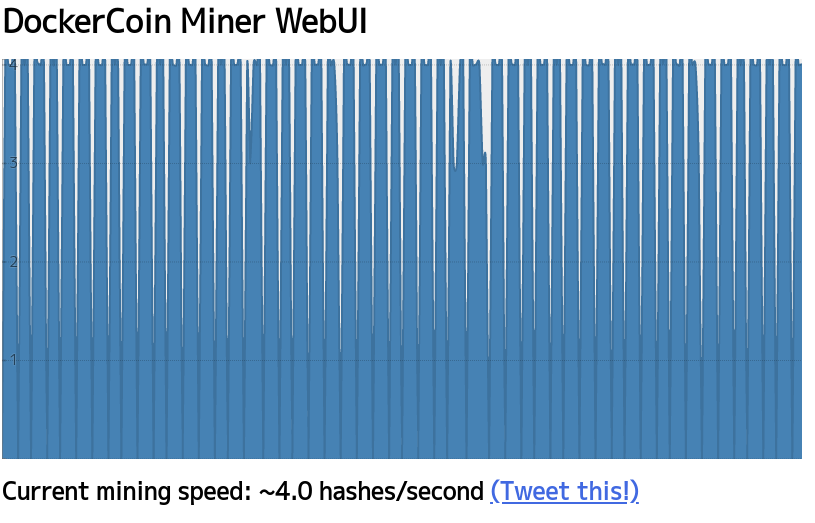
これで準備ができました。
Swarmマネージャが1台クラッシュ
突然 manager01 がクラッシュしてしまいました!
% vagrant destroy manager01 manager01: Are you sure you want to destroy the 'manager01' VM? [y/N] y ==> manager01: Forcing shutdown of VM... ==> manager01: Destroying VM and associated drives...
バックアップも何も取っていない状態で、マネージャのリーダーだった manager01 が消滅してしまいました…。
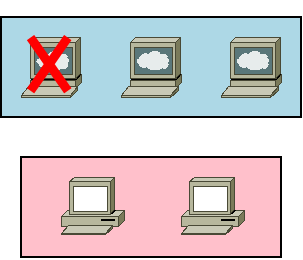
しかし、心配しないでください。前述の通り、マネージャ3台のHA構成なので、マネージャ1台までのクラッシュは許容されます。
manager02 で状態を確認してみましょう。
[vagrant@manager02 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i2cylwqkd2jtppmickcz38wr1 manager01 Down Drain Unreachable 20.10.10 3vlwv4nymq4gism039a1xhwxm * manager02 Ready Drain Leader 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
自動的にリーダーが manager02 に移っているので、Swarmマネージャとしての機能は損なわれていません。
[vagrant@manager02 ~]$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS i2hbj25s8k3l dc_hasher replicated 1/1 training/dockercoins-hasher:1.0 *:8002->80/tcp mghdfsmtcc9l dc_redis replicated 1/1 redis:latest pvfzzcjy61kd dc_rng global 2/2 training/dockercoins-rng:1.0 *:8001->80/tcp quxlyqf9kjem dc_webui replicated 1/1 training/dockercoins-webui:1.0 *:8000->80/tcp rid41xkrfzzl dc_worker replicated 4/4 training/dockercoins-worker:1.0 [vagrant@manager02 ~]$ docker service ps $(docker service ls -q) ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS zuudxvy4ncuw dc_hasher.1 training/dockercoins-hasher:1.0 worker01 Running Running 21 minutes ago mpb2anujjlsj dc_redis.1 redis:latest worker02 Running Running 21 minutes ago fo059jo0q6nb dc_rng.uwhi7yqd7ir3oqy6r32bkz513 training/dockercoins-rng:1.0 worker01 Running Running 21 minutes ago h05fo90aracw dc_rng.ykhntr9vgpdkibgacbjapj8xz training/dockercoins-rng:1.0 worker02 Running Running 21 minutes ago jh6v6pu7tzcc dc_webui.1 training/dockercoins-webui:1.0 worker02 Running Running 21 minutes ago dei0olkvs9dx dc_worker.1 training/dockercoins-worker:1.0 worker02 Running Running 21 minutes ago uhwoak1etcsh dc_worker.2 training/dockercoins-worker:1.0 worker01 Running Running 21 minutes ago 9oxd0nnr3ekq dc_worker.3 training/dockercoins-worker:1.0 worker02 Running Running 21 minutes ago q3sv0jh1t3ep dc_worker.4 training/dockercoins-worker:1.0 worker01 Running Running 21 minutes ago
アプリも正常に動作しています。ブラウザでも確認してみてください。
繰り返しとなりますが、3台のHA構成であれば1台のクラッシュまでは許容されます。しかし、この状態でさらに1台、計2台がクラッシュすると大変なので、manager01 を急いで復旧させましょう。バックアップも取っていないのに、どうすればよいのでしょうか? 実は簡単です。新しく用意した manager01 をSwarmマネージャに再参加させるだけでよいのです。
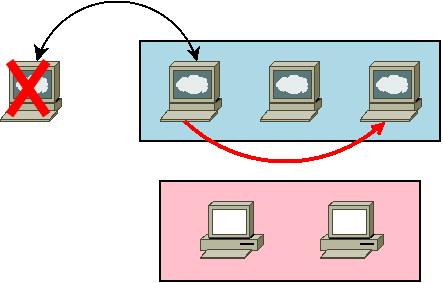
% vagrant up manager01 (省略) % vagrant ssh manager01 [vagrant@manager01 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.102:2377 This node joined a swarm as a manager.
以前使ったマネージャ参加コマンドで、参加先を起動中のSwarmマネージャのもの、ここでは manager02 のIPアドレスに変更して実行するだけでOKです。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION i2cylwqkd2jtppmickcz38wr1 manager01 Down Drain Reachable 20.10.10 s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Reachable 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Ready Drain Leader 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
このように manager01 がSwarmマネージャとして復帰しました。バックアップを取らずとも、マネージャに参加した際にクラスタのデータが自動的に同期されるので特に作業は必要ありません。強いて言えば、まぎらわしいのでクラッシュした古い manager01 を削除しておくくらいです。
[vagrant@manager01 ~]$ docker node demote i2cylwqkd2jtppmickcz38wr1 Manager i2cylwqkd2jtppmickcz38wr1 demoted in the swarm. [vagrant@manager01 ~]$ docker node rm i2cylwqkd2jtppmickcz38wr1 i2cylwqkd2jtppmickcz38wr1 [vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Reachable 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Ready Drain Leader 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
Swarmマネージャのバックアップ
先ほどはマネージャ1台のクラッシュだったので比較的復旧が簡単に済みましたが、安心・安全のために Backup Swarmの手順に従い、マネージャのバックアップを取っておきましょう。本稿では使っていませんが、Swarmのautolockを使っている場合はキーを別途バックアップしてください。
まずは、現時点でマネージャリーダーではない manager01 からバックアップを始めます。バックアップ対象は /var/lib/docker/swarm ディレクトリです。バックアップを取る前に、クラスタデータに変動が起きないように manager01 の docker を停止します。
[vagrant@manager01 ~]$ ENGINE=$(docker version -f '{{.Server.Version}}')
[vagrant@manager01 ~]$ sudo systemctl stop docker.service docker.socket
[vagrant@manager01 ~]$ ps auxwwwf | grep '[ d]ocker'
[vagrant@manager01 ~]$
クラッシュ時と同様、マネージャもアプリも正常に動作を続けているので心配しないでください。ただし、この状態で manager02 と manager03 のどちらかクラッシュするとマネージャが止まってしまうため、クリティカルな本番環境では2台までの停止が許容される5台のHA構成が良いでしょう。
ではバックアップを行います。
[vagrant@manager01 ~]$ sudo tar cvzf "/tmp/swarm-${ENGINE}-$(hostname -s)-$(date +%s%z).tgz" /var/lib/docker/swarm/
tar: Removing leading `/' from member names
/var/lib/docker/swarm/
/var/lib/docker/swarm/state.json
/var/lib/docker/swarm/docker-state.json
/var/lib/docker/swarm/certificates/
/var/lib/docker/swarm/certificates/swarm-root-ca.crt
/var/lib/docker/swarm/certificates/swarm-node.key
/var/lib/docker/swarm/certificates/swarm-node.crt
/var/lib/docker/swarm/worker/
/var/lib/docker/swarm/worker/tasks.db
/var/lib/docker/swarm/raft/
/var/lib/docker/swarm/raft/snap-v3-encrypted/
/var/lib/docker/swarm/raft/wal-v3-encrypted/
/var/lib/docker/swarm/raft/wal-v3-encrypted/0000000000000000-0000000000000000.wal
バックアップが取れていることを確認し、問題なければこのファイルを manager01 外の安全な場所に退避しておきましょう。
[vagrant@manager01 ~]$ tar tvfz /tmp/swarm-20.10.10-manager01-1637120105+0000.tgz drwx------ root/root 0 2021-11-17 03:22 var/lib/docker/swarm/ -rw------- root/root 211 2021-11-17 03:22 var/lib/docker/swarm/state.json -rw------- root/root 198 2021-11-17 03:07 var/lib/docker/swarm/docker-state.json drwxr-xr-x root/root 0 2021-11-17 03:07 var/lib/docker/swarm/certificates/ -rw-r--r-- root/root 554 2021-11-17 03:07 var/lib/docker/swarm/certificates/swarm-root-ca.crt -rw------- root/root 317 2021-11-17 03:07 var/lib/docker/swarm/certificates/swarm-node.key -rw-r--r-- root/root 826 2021-11-17 03:07 var/lib/docker/swarm/certificates/swarm-node.crt drwxr-xr-x root/root 0 2021-11-17 03:07 var/lib/docker/swarm/worker/ -rw-r--r-- root/root 32768 2021-11-17 03:31 var/lib/docker/swarm/worker/tasks.db drwx------ root/root 0 2021-11-17 03:07 var/lib/docker/swarm/raft/ drwx------ root/root 0 2021-11-17 03:07 var/lib/docker/swarm/raft/snap-v3-encrypted/ drwx------ root/root 0 2021-11-17 03:31 var/lib/docker/swarm/raft/wal-v3-encrypted/ -rw------- root/root 64000000 2021-11-17 03:31 var/lib/docker/swarm/raft/wal-v3-encrypted/0000000000000000-0000000000000000.wal
バックアップが取れたら、dockerを起動します。
[vagrant@manager01 ~]$ sudo systemctl start docker [vagrant@manager01 ~]$ ps auxwwwf | grep '[ d]ocker' root 2833 3.0 2.6 1153808 78536 ? Ssl 03:38 0:00 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock [vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Reachable 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Ready Drain Leader 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
同様の手順で、リーダーではない manager03 でバックアップを取得します。作業ログは省略します。
最後に、リーダーである manager02 でバックアップを取得します。まず docker を停止します。
[vagrant@manager02 ~]$ ENGINE=$(docker version -f '{{.Server.Version}}')
[vagrant@manager02 ~]$ sudo systemctl stop docker.service docker.socket
[vagrant@manager02 ~]$ ps auxwwwf | grep '[ d]ocker'
[vagrant@manager02 ~]$
リーダーの docker を停止してしまいましたが大丈夫でしょうか? 他のマネージャ、ここでは manager01 で確認してみましょう。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Leader 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Down Drain Unreachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
自動的にリーダーが manager01 に移っているため、マネージャもアプリも正常に動作を続けています。安心して manager02 のバックアップ作業を行いましょう。詳細な作業ログは省略します。
すべてのマネージャのバックアップが取れました。これで2台以上のクラッシュが発生してもひとまずは安心です。
swarm-20.10.10-manager01-1637120105+0000.tgz swarm-20.10.10-manager02-1637120862+0000.tgz swarm-20.10.10-manager03-1637120446+0000.tgz
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Leader 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Ready Drain Reachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
Swarmマネージャが2台クラッシュ
今度は manager01 と manager02 が同時にクラッシュしてしまいました!
% vagrant destroy manager01 manager02 manager02: Are you sure you want to destroy the 'manager02' VM? [y/N] y ==> manager02: Forcing shutdown of VM... ==> manager02: Destroying VM and associated drives... manager01: Are you sure you want to destroy the 'manager01' VM? [y/N] y ==> manager01: Forcing shutdown of VM... ==> manager01: Destroying VM and associated drives...
リーダーだった manager01 を含め、マネージャが2台も消滅してしまいました…。
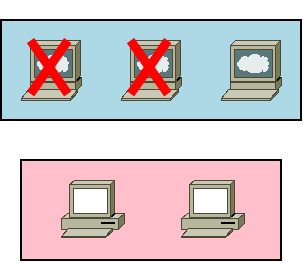
生き残ったマネージャである manager03 でSwarm管理コマンドを実行しても、定足数を満たしていないために受け付けられない状態となってしまっています。
[vagrant@manager03 ~]$ docker node ls Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
ただ、ワーカーで起動済みのアプリは正常に動作し続けています。ブラウザでも確認してみてください。
[vagrant@worker01 ~]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 42c2372fb05d training/dockercoins-worker:1.0 "python worker.py" 2 hours ago Up 2 hours dc_worker.2.uhwoak1etcshf7augszho198z 2c023c5d0f30 training/dockercoins-worker:1.0 "python worker.py" 2 hours ago Up 2 hours dc_worker.4.q3sv0jh1t3ep68wgx6gbpqopx 2f3cda11b088 training/dockercoins-rng:1.0 "python rng.py" 2 hours ago Up 2 hours 80/tcp dc_rng.uwhi7yqd7ir3oqy6r32bkz513.fo059jo0q6nbc6j39av0chk3c 783bf01fa525 training/dockercoins-hasher:1.0 "ruby hasher.rb" 2 hours ago Up 2 hours 80/tcp dc_hasher.1.zuudxvy4ncuw73fmkhq08lwi0
[vagrant@worker02 ~]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fb30066aa37c training/dockercoins-webui:1.0 "node webui.js" 2 hours ago Up 2 hours 80/tcp dc_webui.1.jh6v6pu7tzccxq5raou01gsi4 f80358a4c8ef redis:latest "docker-entrypoint.s…" 2 hours ago Up 2 hours 6379/tcp dc_redis.1.mpb2anujjlsjzstjncp4tevix 7dcf9f26e740 training/dockercoins-worker:1.0 "python worker.py" 2 hours ago Up 2 hours dc_worker.1.dei0olkvs9dx7e57qtfhot1yz f3853a139326 training/dockercoins-worker:1.0 "python worker.py" 2 hours ago Up 2 hours dc_worker.3.9oxd0nnr3ekq75l824urcqta9 bfdec753d424 training/dockercoins-rng:1.0 "python rng.py" 2 hours ago Up 2 hours 80/tcp dc_rng.ykhntr9vgpdkibgacbjapj8xz.h05fo90aracwf12zm23yy1u9x
起動済みのアプリは動作し続けていますが、管理コマンドを受け付けないため、アプリに問題が発生しても復旧作業が行えません。急いでマネージャを復旧させる必要があります。
Recover from losing the quorum の手順に従い、生き残った manager03 をリーダーとしてクラスタを作り直し、manager01 と manager02 を置き換えます。
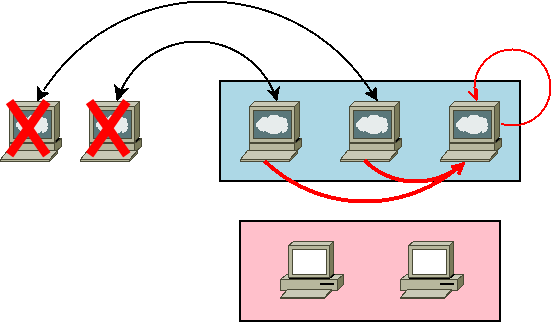
manager03 にて、manager03 にある既存のクラスタデータを用いて、manager03 を唯一のマネージャとする --force-new-cluster オプションを付与してクラスタの初期化を行います。
[vagrant@manager03 ~]$ docker swarm init --availability=drain --force-new-cluster --advertise-addr 192.168.123.103 Swarm initialized: current node (ufxoq2m2bewz4aujbdqzm5w27) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-8emzlfehglbpjcrfzw706ys4g 192.168.123.103:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
ひとまずクラスタ管理コマンドを受け付けるようになりました。
[vagrant@manager03 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 manager01 Down Drain 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Down Drain 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 * manager03 Ready Drain Leader 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10 [vagrant@manager03 ~]$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS i2hbj25s8k3l dc_hasher replicated 1/1 training/dockercoins-hasher:1.0 *:8002->80/tcp mghdfsmtcc9l dc_redis replicated 1/1 redis:latest pvfzzcjy61kd dc_rng global 2/2 training/dockercoins-rng:1.0 *:8001->80/tcp quxlyqf9kjem dc_webui replicated 1/1 training/dockercoins-webui:1.0 *:8000->80/tcp rid41xkrfzzl dc_worker replicated 4/4 training/dockercoins-worker:1.0
新しく manager01 と manager02 を用意します。
% vagrant up manager01 manager02
manager03 でクラスタ参加トークンを払い出します。
[vagrant@manager03 ~]$ docker swarm join-token manager To add a manager to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.103:2377
これにワークロードコンテナをマネージャ上で起動しないよう--availability=drainを付与して、manager01 と manager02 で実行します。
[vagrant@manager01 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.103:2377 This node joined a swarm as a manager.
[vagrant@manager02 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.103:2377 This node joined a swarm as a manager.
これで無事マネージャが復旧しました。
[vagrant@manager03 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 manager01 Down Drain 20.10.10 s6nh1jx2rls2ryfvfvkdhrc45 manager01 Ready Drain Reachable 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Down Drain 20.10.10 woftntblwmor5i7o36px8hyat manager02 Ready Drain Reachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 * manager03 Ready Drain Leader 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
古い manager01 と manager02 を削除しておきましょう。
[vagrant@manager03 ~]$ docker node rm s4bm4um4k88nzqc6avq55e012 3vlwv4nymq4gism039a1xhwxm s4bm4um4k88nzqc6avq55e012 3vlwv4nymq4gism039a1xhwxm [vagrant@manager03 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s6nh1jx2rls2ryfvfvkdhrc45 manager01 Ready Drain Reachable 20.10.10 woftntblwmor5i7o36px8hyat manager02 Ready Drain Reachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 * manager03 Ready Drain Leader 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
この間、既存のアプリは動作中のままでした。
Swarmマネージャが3台クラッシュ
今度はマネージャが全滅してしまいました…。最悪のパターンです。
% vagrant destroy manager01 manager02 manager03 manager03: Are you sure you want to destroy the 'manager03' VM? [y/N] y ==> manager03: Forcing shutdown of VM... ==> manager03: Destroying VM and associated drives... manager02: Are you sure you want to destroy the 'manager02' VM? [y/N] y ==> manager02: Forcing shutdown of VM... ==> manager02: Destroying VM and associated drives... manager01: Are you sure you want to destroy the 'manager01' VM? [y/N] y ==> manager01: Forcing shutdown of VM... ==> manager01: Destroying VM and associated drives...
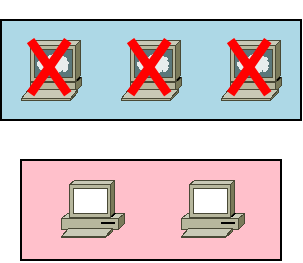
依然としてアプリは動作し続けていますが、当然ながら管理コマンドなどを受け付ける先がありません。
[vagrant@worker01 ~]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 42c2372fb05d training/dockercoins-worker:1.0 "python worker.py" 3 hours ago Up 3 hours dc_worker.2.uhwoak1etcshf7augszho198z 2c023c5d0f30 training/dockercoins-worker:1.0 "python worker.py" 3 hours ago Up 3 hours dc_worker.4.q3sv0jh1t3ep68wgx6gbpqopx 2f3cda11b088 training/dockercoins-rng:1.0 "python rng.py" 3 hours ago Up 3 hours 80/tcp dc_rng.uwhi7yqd7ir3oqy6r32bkz513.fo059jo0q6nbc6j39av0chk3c 783bf01fa525 training/dockercoins-hasher:1.0 "ruby hasher.rb" 3 hours ago Up 3 hours 80/tcp dc_hasher.1.zuudxvy4ncuw73fmkhq08lwi0
[vagrant@worker02 ~]$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fb30066aa37c training/dockercoins-webui:1.0 "node webui.js" 3 hours ago Up 3 hours 80/tcp dc_webui.1.jh6v6pu7tzccxq5raou01gsi4 f80358a4c8ef redis:latest "docker-entrypoint.s…" 3 hours ago Up 3 hours 6379/tcp dc_redis.1.mpb2anujjlsjzstjncp4tevix 7dcf9f26e740 training/dockercoins-worker:1.0 "python worker.py" 3 hours ago Up 3 hours dc_worker.1.dei0olkvs9dx7e57qtfhot1yz f3853a139326 training/dockercoins-worker:1.0 "python worker.py" 3 hours ago Up 3 hours dc_worker.3.9oxd0nnr3ekq75l824urcqta9 bfdec753d424 training/dockercoins-rng:1.0 "python rng.py" 3 hours ago Up 3 hours 80/tcp dc_rng.ykhntr9vgpdkibgacbjapj8xz.h05fo90aracwf12zm23yy1u9x
Restore Swarmの手順に従い、マネージャを復旧しましょう。幸い、先にバックアップを取得しているのでそれからリストアします。
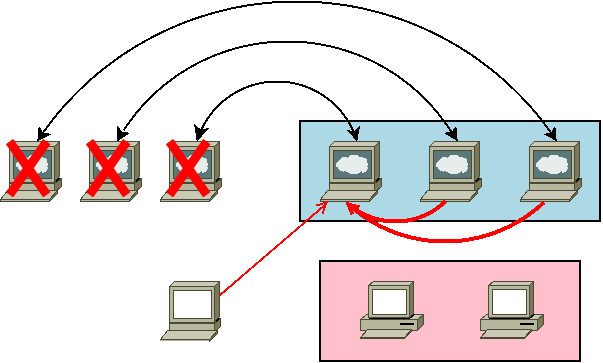
manager01, manager02, manager03 を用意します。この際、以前の manager01, manager02, manager03 と同じIPアドレスであるようにします。
% vagrant up manager01 manager02 manager03
manager01 から復旧しましょう。manager01 にバックアップファイル swarm-20.10.10-manager01-1637120105+0000.tgz を設置します。
[vagrant@manager01 ~]$ ls swarm-20.10.10-manager01-1637120105+0000.tgz swarm-20.10.10-manager01-1637120105+0000.tgz
docker を停止します。
[vagrant@manager01 ~]$ sudo systemctl stop docker.service docker.socket [vagrant@manager01 ~]$ ps auxwwwwf | grep '[ d]ocker' [vagrant@manager01 ~]$
バックアップデータをリストアします。
[vagrant@manager01 ~]$ sudo tar xvf swarm-20.10.10-manager01-1637120105+0000.tgz -C / var/lib/docker/swarm/ var/lib/docker/swarm/state.json var/lib/docker/swarm/docker-state.json var/lib/docker/swarm/certificates/ var/lib/docker/swarm/certificates/swarm-root-ca.crt var/lib/docker/swarm/certificates/swarm-node.key var/lib/docker/swarm/certificates/swarm-node.crt var/lib/docker/swarm/worker/ var/lib/docker/swarm/worker/tasks.db var/lib/docker/swarm/raft/ var/lib/docker/swarm/raft/snap-v3-encrypted/ var/lib/docker/swarm/raft/wal-v3-encrypted/ var/lib/docker/swarm/raft/wal-v3-encrypted/0000000000000000-0000000000000000.wal
docker を起動します。
[vagrant@manager01 ~]$ sudo systemctl start docker [vagrant@manager01 ~]$ ps auxwwwwf | grep '[ d]ocker' root 2056 1.3 2.2 1088016 64196 ? Ssl 05:49 0:00 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
クラスタデータは戻ったようですが、管理コマンドは依然として受け付けられません。
[vagrant@manager01 ~]$ docker system info --format '{{json .Swarm}}' | jq . -
{
"NodeID": "s4bm4um4k88nzqc6avq55e012",
"NodeAddr": "192.168.123.101",
"LocalNodeState": "pending",
"ControlAvailable": true,
"Error": "rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.",
"RemoteManagers": [
{
"NodeID": "ufxoq2m2bewz4aujbdqzm5w27",
"Addr": "192.168.123.103:2377"
},
{
"NodeID": "3vlwv4nymq4gism039a1xhwxm",
"Addr": "192.168.123.102:2377"
},
{
"NodeID": "s4bm4um4k88nzqc6avq55e012",
"Addr": "192.168.123.101:2377"
}
],
"Cluster": {
"ID": "",
"Version": {},
"CreatedAt": "0001-01-01T00:00:00Z",
"UpdatedAt": "0001-01-01T00:00:00Z",
"Spec": {
"Labels": null,
"Orchestration": {},
"Raft": {
"ElectionTick": 0,
"HeartbeatTick": 0
},
"Dispatcher": {},
"CAConfig": {},
"TaskDefaults": {},
"EncryptionConfig": {
"AutoLockManagers": false
}
},
"TLSInfo": {},
"RootRotationInProgress": false,
"DefaultAddrPool": null,
"SubnetSize": 0,
"DataPathPort": 0
}
}
[vagrant@manager01 ~]$ docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
[vagrant@manager01 ~]$ docker service ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
マネージャが2台クラッシュしたときと同様に、この既存のクラスタデータを用いて、manager01 を唯一のマネージャとする --force-new-cluster オプションを付与してクラスタの初期化を行います。
[vagrant@manager01 ~]$ docker swarm init --availability=drain --force-new-cluster --advertise-addr 192.168.123.101 Swarm initialized: current node (s4bm4um4k88nzqc6avq55e012) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-8emzlfehglbpjcrfzw706ys4g 192.168.123.101:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions. [vagrant@manager01 ~]$ docker swarm join-token manager To add a manager to this swarm, run the following command: docker swarm join --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377
管理コマンドを受け付けるようになりました。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Leader 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Down Drain 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Unknown Drain 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10 [vagrant@manager01 ~]$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS i2hbj25s8k3l dc_hasher replicated 1/1 training/dockercoins-hasher:1.0 *:8002->80/tcp mghdfsmtcc9l dc_redis replicated 1/1 redis:latest pvfzzcjy61kd dc_rng global 2/2 training/dockercoins-rng:1.0 *:8001->80/tcp quxlyqf9kjem dc_webui replicated 1/1 training/dockercoins-webui:1.0 *:8000->80/tcp rid41xkrfzzl dc_worker replicated 4/4 training/dockercoins-worker:1.0
manager02 と manager03 をマネージャとしてクラスタに再参加させましょう。
[vagrant@manager02 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377 This node joined a swarm as a manager.
[vagrant@manager03 ~]$ docker swarm join --availability=drain --token SWMTKN-1-3y5wa7xcsxavdyfibx58qr0g5ln2joui3fjxmjtet7sp67o04b-763hohmtxmxrr9zhu67y05pyj 192.168.123.101:2377 This node joined a swarm as a manager.
無事、3台のマネージャによるHA構成が復旧しました。
[vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Leader 20.10.10 3vlwv4nymq4gism039a1xhwxm manager02 Down Drain 20.10.10 frvz22bn7rd0uyxdawe9vn6cv manager02 Ready Drain Reachable 20.10.10 nf4yl2jsatypawskypd77kgqt manager03 Ready Drain Reachable 20.10.10 ufxoq2m2bewz4aujbdqzm5w27 manager03 Down Drain 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10
古い manager02 と manager03 を削除しておきましょう。
[vagrant@manager01 ~]$ docker node rm 3vlwv4nymq4gism039a1xhwxm ufxoq2m2bewz4aujbdqzm5w27 3vlwv4nymq4gism039a1xhwxm ufxoq2m2bewz4aujbdqzm5w27 [vagrant@manager01 ~]$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION s4bm4um4k88nzqc6avq55e012 * manager01 Ready Drain Leader 20.10.10 frvz22bn7rd0uyxdawe9vn6cv manager02 Ready Drain Reachable 20.10.10 nf4yl2jsatypawskypd77kgqt manager03 Ready Drain Reachable 20.10.10 uwhi7yqd7ir3oqy6r32bkz513 worker01 Ready Active 20.10.10 ykhntr9vgpdkibgacbjapj8xz worker02 Ready Active 20.10.10 [vagrant@manager01 ~]$
まとめ
本稿ではDocker Swarmマネージャ3台のHA構成で、
- マネージャ1台の喪失 = 定足数(Quorum; クォーラム)を満たした状態
- マネージャ2台の喪失 = 定足数を満たさない状態
- マネージャ3台の喪失 = 全滅状態
の3パターンの障害からの復旧方法を見てきました。
Swarmマネージャは障害に対して堅牢かつ比較的容易に復旧できるようになっており、さらにSwarmワーカーで既に起動しているワークロードには極力影響を与えないようになっています。
しかしそれは十分な定足数を持つHA構成を取っていること、定期的にバックアップを取っていること、そしてリストアの予行演習などの準備ができていることといった、非常時への備えが平常時からできていることが大前提です。Swarmクラスタの設定・状態や、動作中のアプリによっては本稿で記載した通りに復旧が行えない可能性もありえます。是非皆様のクラスタの場合において、万が一の障害に備えた準備を日頃から行っておくようにしてください。本稿がその一助となれば幸いです。
Author
Chef・Docker・Mirantis製品などの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



