
[和訳]Dockerビルトインオーケストレーション製品版が完成 #docker

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本稿は Docker Built-In Orchestration Ready For Production: Docker 1.12 Goes GA(2016/7/28) の和訳記事です。
Docker1.12製品版が完成したことは、我々の大きなマイルストーンであり、これを実現するために多大なご協力をいただいたコミュニティの皆さまに感謝申し上げます。Docker1.12のリリースは、Dockerプロジェクト全体でみても最も多くの機能、最も洗練された機能を盛り込んだものになります。バージョン1.12のオーケストレーションのすべてにおいて、コア・アルゴリズム、Docker エンジンへの統合、ドキュメンテーション、テストに至るまで、Docker社内外の多数の技術者の方々が素晴らしい貢献をしてくれました。
コミュニティの皆さまにはフィードバック、バグ報告、新しいアイデアのご提案などでサポートいただき、心から感謝申し上げます。特に6月のDockerCon以来、1.12の機能をテストして下さった数万人にも昇るDocker for Mac and Windows ベータ版ユーザーの皆さまのご協力なしではこのリリースを実現できませんでした。例えばBash tab の完成やUX up-and- down 投票等により、ユーザーから求められているのは何かを知ることができました。我々がDockerConでご紹介したものと比べて、swarm ノードのジョインワークフロー(より簡単になりました)、エラー報告(より簡単に閲覧することができるようになりました)、UX改善(よりロジカルになりました)、ネットワーク(信頼性の問題を解決しました)等の分野で大幅な改善を加える事ができました。
また、コア・チームは外部保守管理者の方々およびDocker キャプテンであるChanwit Kaewkasiさんにも感謝申し上げます。 彼らには、コミュニティ全体で実施したDockerSwarm2000 においてイニシアチブを取っていただき、swarm mode 1.12RCを利用し、2,400 ノードにおける100,000コンテナのスケーリングを見せてくれました。
これはグローバルコミュニティの皆さまが、ベアメタル、ラズベリーパイ、様々なクラウド、x86アーキテクチャーやARMベースのVM等、手持ちの多種多様なマシンへのアクセスを許可していただいたおかげで達成できました。ライブデータを使用したこの評価では、Docker ビルトインオーケストレーションがほんの半年間でDockerオーケストレーション・スケールの2倍になったことを確認しました。これでアーキテクチャーのスケーラビリティは検証できましたが、今後の更なるパフォーマンス最適化の余地はあります。
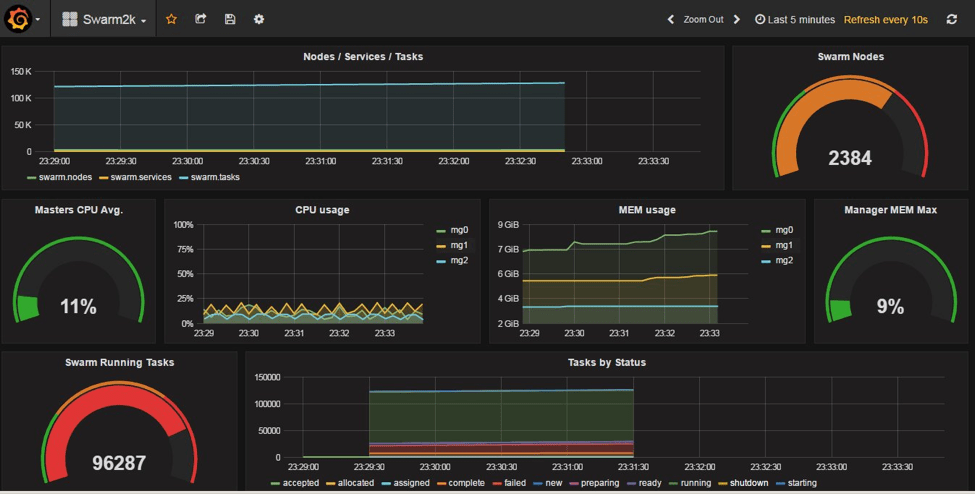
それではビルトインオーケストレーションを詳しく見ると共に、コンテナオーケストレーションを実現するためになぜ我々が他と全く異なったアーキテクチャー・アプローチを取ったのかご説明しましょう。
Swarm modeアーキテクチャートポロジーについて
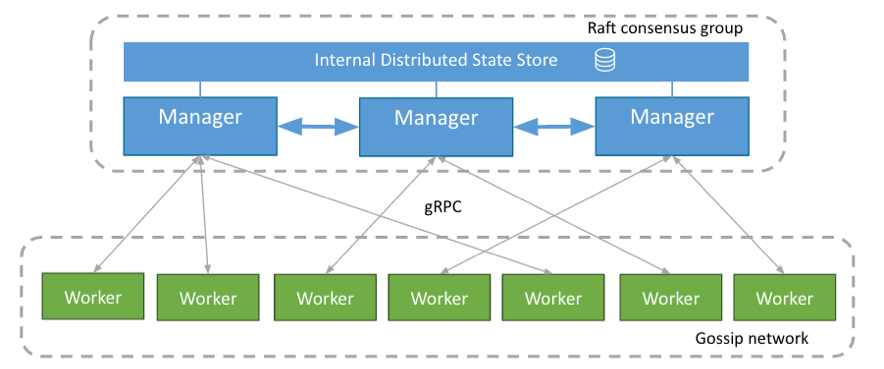
Docker 1.12のビルトインコンテナオーケストレーションはオプションの機能セットであり、Swarm modeとして知られる機能を有効にするものです。Swarmとは、非集中かつ可用性の高いDockerノードグループです。各ノードは独立したオーケストレーション・サブシステムであり、Docker化されたサービスをスケジュールするために固有の共通リソースプールを生成する能力を持っています。
Dockerノードの集合はプログラム可能なトポロジーを作成し、それによってオペレーターはどのノードが管理者でどのノードが作業者なのか選択できます。これはMultiple availability zones に管理者を配布するといった共通の構成を含みます。これらの役割は動的であるため、APIもしくはCLIを通じていつでも変更可能です。
管理者はクラスターのオーケストレーションの責任を担い、ServiceAPIを提供したり、タスク(コンテナ)のスケジュール管理をしたり、ヘルスチェックに失敗したコンテナを特定したりします。それと対照的に、作業者ノードはさらにシンプルな機能を持ちます。 それは、コンテナの生成のタスクを実行する機能と、特定のコンテナ向けのデータ・トラフィックをルーティングする機能です。本番環境においては、ノードを「管理者」もしくは「作業者」として指定して保持することを強く推奨します。このモードでは、管理者はコンテナを実行しないため、負荷および攻撃対象領域が減少します。それとは別にSwarmモードのセキュリティの進化点としてもう一点挙げるとすれば、作業者ノードはデータストアもしくはServiceAPIの情報にアクセスすることができません。 作業者ノードは作業を受け付けて状況を報告するだけなので、作業者ノードが感染してもシステムへ与える損害はより限定的になります。
管理者 と作業者間のコミュニケーションのアーキテクチャーに我々はかなり注力しました。管理者 と作業者では必要とするコミュニケーション要件、例えば、一貫性、スピード、ボリュームが違います。従ってコミュニケーション手法として2つのものを使用しています。Raftは(書き込みスピードとボリューム制限を犠牲にしながら)強度な一貫性を目的として管理者 間のデータ共有に利用されます。Gossipは(最終的にはConsistencyが取れるのですが)作業者間での素早いやり取り・大容量の処理に使われます。さらに、管理者 と作業者の間には別のコミュニケーション要件もあります。これら全てに共通する点は、コミュニケーションをmTLSを使ってデフォルトで暗号化している点です。
Manager間のコミュニケーション:常に定数を満たすために
ノードが管理者の役割を与えられた際には、情報共有やリーダー選出のためにRaftコンセンサス・グループに参加します。リーダーは中央権限的な存在であり、状況を監視しています。スケジュール決定に加えて、Swarm全域のノード、サービス、タスクの各リストの管理を行っています。この状況は、ビルトインRaftストアを通じて各作業者ノードに配布されます。これは管理者がetcdやConsulといった外部KVSに依存しない設計であり、運用部門が管理しなければならないコンポーネントが一つ減ることを意味します。リーダーではない管理者はホットスペアとして機能し、APIリクエストを現状のリーダーに転送します。従って、本システムはフォールト・トレラントであり、可用性が高いといえます。
一般的なデータストアではなく、統合された分散データストアを保持することにより、多くの最適化が図れます。その結果、我々のビルトインオーケストレーションシステムが大変高速になります。全てのSwarmの状態 がメモリ上で保持され、瞬時に読み込めるようになったことが最適化の一例です。この読み込みの最適化は、読み込み負荷が高いワークフローである状態の照合を必要とするクリティカルなオーケストレーションにとって大変有益です。例えばスケジューラーは、ノードリストを読んだり、各ノード上でどんなタスクが走っているかを読んだり、大量の読み込みが発生します。読み込みの最適化によって、外部データベースへ何百という読み込みに必要なネットワークでのラウンドトリップが不要となり、速度が増します。
書き込みもオーケストレーションに取ってクリティカルです。書き込みの最適化として、Swarm modeではバッチ処理1回のネットワーク・ラウンドトリップで書き込みをできるようになりました。良くある書き込みの例として、サービスをスケールアップする際に、オーケストレーターがユーザー・リクエストの全てのインスタンスに対して新たにオブジェクトを作らなくてはならない件を取り上げてみましょう。外部ストアを利用する場合、作成するオブジェクト一つ一つについてネットワークリクエストをストアに送り書き込みを保存するのを待つという作業を繰り返さなくてはなりません。これは、一つのリクエストごとに数秒かかり、合計すると大変な時間がかかります(特に新インスタンスを数百件追加する場合など)。我々のモデルでは、それらの数百のオブジェクトを1件の書き込みとしてバッチ化することができます。
また、同様の書き込み最適化によって回復力も大幅に向上します。例えば、100コンテナを有するノード一つがダウンした場合、別のノードに移動させるために100件書き込みをするのではなく、1件の書き込みで済むのです。
データに関していえば、サイズ的に(プロトコルバッファ)、パフォーマンス的に(ドメインに特化したインデックス化)等をいかに効率的に保持できるか、という面で最適化を図りました。ある特定のサービスに不向きなコンテナについては、マシン上で動いているコンテナのメモリから即座にクエリすることも可能です。
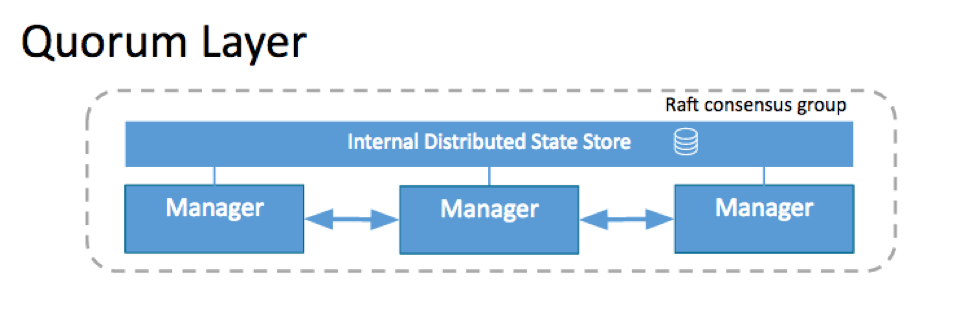
管理者から作業者へのコミュニケーション
作業者ノードはgRPCを使用して管理者ノードと会話します。gRPCは厳しいネットワーク条件下で大変よく機能する高速プロトコルであり、インターネット・リンクを通じてのコミュニケーションを可能にし、バージョニング機能を内蔵しています(それにより、それぞれ異なるバージョンのエンジンを実行している複数の作業者ノードが、同一の管理者ノードと会話できます。)管理者は実行すべきタスクを作業者に送ります。作業者は、一連のタスク割り当ての状況および作業者が生存している証しとしてハートビートを管理者に送ります。
以下の図が示すように、作業者とコミュニケーションを取るのは管理者コードのディスパッチャー・コンポーネントです。つまり、管理者コードのディスパッチャー・コンポーネントが、各作業者へタスクをディスパッチする責任を負っています。一方、作業者は(エグゼキューター・コンポーネントを通じて)これらのタスクをコンテナに対して翻訳し、コンテナを作成する役割を担っています。
ノードの構成図
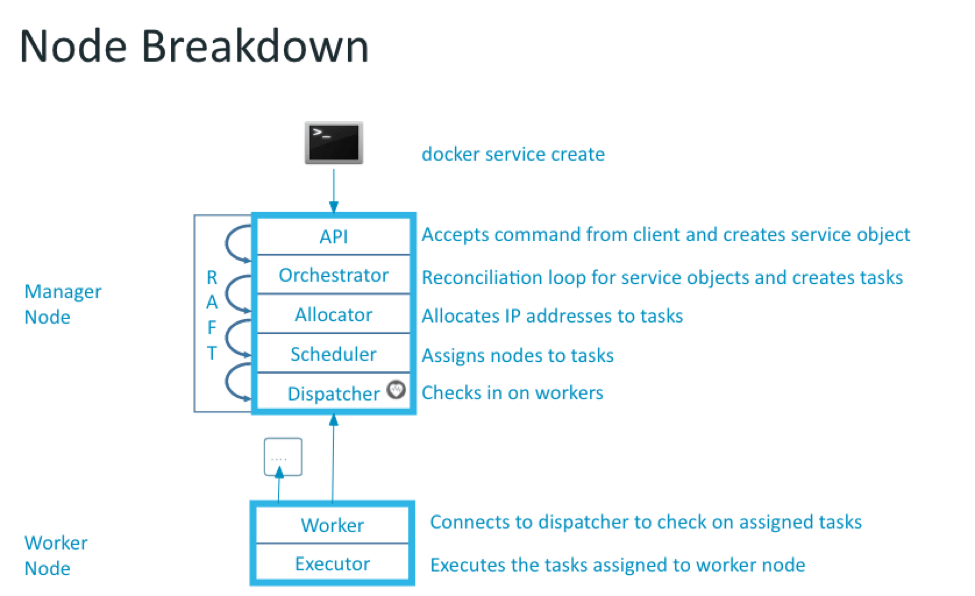
上記の図をもとに、Dockerサービスが作成される時、および最終的なコンテナセットの生成の際に何が起きているか簡単にご紹介します。
・サービス・クリエーション
・ユーザーがAPIにサービス定義を送る、APIが受理し保管する。
・オーケストレーターが(ユーザーが定義した)望ましい状態と実際の状態(Swarm上で今何が実行されているか)を照合する。APIによって作られた新しいサービスをピックアップし、タスクを作成することにより応答する。(今回はユーザーがサービスのインスタンスを一件だけリクエストしたと仮定。)
・アロケーターがタスク用のリソースを付与する。アロケーターは新しいサービス(APIが作ったもの)・新しいタスク(オーケストレーターが作ったもの)を検知し、それぞれにIPアドレスを付与する。
・スケジューラーは作業者ノードにタスクを割り当てる。スケジューラはノードがアサインされていないタスクを検知し、スケジューリングを開始する。制約やリソースをベースとしてベストな組み合わせを探し、最終的に一つのノードにタスクを割り当てる。
・ディスパッチャーとは作業者の接続先であり、作業者はディスパッチャーに接続すると、指示を待つ状態となる。これにより、スケジューラーに割り当てられたタスクは最終的に作業者に送られる。
・サービス・アップデート
・ユーザーがAPIを通じてサービス定義を更新(例:1インスタンスを3インスタンスへ変更)し、APIはその更新を承認し保管する。
・オーケストレーターは望ましい状態と現状を照合する。オーケストレーターは、ユーザーが3インスタンスを望んでいるのに対して現状は1インスタンスしか実行されていないことを検知し、新しいタスクを追加する。
・アロケーター、スケジューラー、ディスパッチャーが上記と同様の処理を行い、2つの新しいタスクが作業者ノードに追加される。
・ノードの失敗
・ディスパッチャーが、自分に接続されたNodeが失敗したことをハートビートによって検知し、そのNodeに「DOWN」のフラグを立てる。
・オーケストレーターが照合を行う。3インスタンスが実行されていなければならないが、1インスタンスしか実行されていないため、新しいタスクを作成する。
・アロケーター、スケジューラー、ディスパッチャーが上記と同様の処理を行い、2つの新しいタスクが作業者に追加される。
・作業者はオーバーレイ・ネットワークの情報交換にGossipネットワークを利用します。 Gossipは大容量、高スケーラビリティなP2Pネットワークです。ノードがタスクを受け付け、コンテナを開始し、他のノードに対してオーバーレイ・ネットワーク上でコンテナを開始した事を伝えます。このブロードキャスト・コミュニケーションは作業者のティアで行われます。Swarmのサイズにかかわらず、Gossipはある一定数のランダムなノードにのみ伝えられ、すべてのノードには伝えないため、これによりスケーリングは達成される事になります。
これはいったい何を意味するのでしょうか。
開発者やオペレーターにとって、Docker 1.12オーケストレーションは結局どういう意味を持つのでしょうか? このリリースには、上述のような様々なアーキテクチャーによって可能となった重要なテーマが3つあります。
・フォールト・トレラントなアプリケーション・ディプロイ・プラットフォーム:
昨今のアプリケーションは、マイクロサービス・アーキテクチャー・パターンで設計されることが多くなっており、ユーザーへバックデータを提供するプロセスにおいて、複数の別のサービスを呼び出す必要があります。実際のマシンは障害が発生するものです。不測の障害発生時においても、マイクロサービスは利用可能な状態を保持しなければなりません。Docker 1.12 では、管理者の定数を活用することや、ホストを失った際にサービスの抽象化により複数のレプリカを作成し、すぐにリスケジュールすることで単一障害点(SPOF)のない設計を可能にしています。
・スケールとパフォーマンス: Docker 1.12のSwarm modeオーケストレーションはスケーラビリティとパフォーマンスを念頭に設計されました。例えば、内部のRaft分散ストアは、イン・メモリのキャッシュ・レイヤーで素早い読み込みを行うために最適化されています。キャッシングは素早い読み込みを可能にしますが、書き込みが発生したら何が起きるでしょうか。当然、各マシンのキャッシュは無効化されアップデートされるべきです。この問題に対して我々のソリューションは、オーケストレーション・システムの残りの部分を、読み込みに重点を置きつつ、本当に必要なときのみRaftストアに書き込むよう設計するというものです。この設計方針によって、一般的なKVSに基づくオーケストレーターよりも優れたパフォーマンスが発揮できるオーケストレーション・システムとなります。
・安全なネットワーク: 多くのシステムにおいてセキュリティは「かける」ものです。TLS証明書を作成したり、違うポートでシステムを実行したり、暗号化されていないネットワークでパケットがトラバースしないようトラフィックを分析したりすることでセキュリティをかけています。Docker 1.12では、これらはすぐに利用できる状態です[*]。システムは「デフォルトで安全」であり、セキュリティのプロでなくても安全なアプリケーション・マネジメント・プラットフォームが確立できるのです。
[*] これに少々の例外があります。現在のDocker のバージョンでは、オーバーレイ・ネットワークのトラフィックの暗号化をするためには、手動でフラグを特定しなくてはなりません。 -o encrypted ( docker network create -d overlay)。それ以外の全てのトラフィックは、デフォルトで暗号化されます。
Docker 1.12 Swarm modeのより詳しい情報は以下です。
Docker 1.12 Swarm Mode ディープ・ダイブ Part 1:トポロジー
Docker 1.12 Swarm Mode ディープ・ダイブ Part 2: オーケストレーション
Dockerに関してさらに学ぶには
・Docker初心者は、10分のオンラインチュートリアルをご覧ください。
・画像、自動構築などを無料のDocker Hubアカウントでシェアしてみましょう。
・Docker 1.12リリースノートを読んでみましょう。
・Docker Weeklyを購読してみましょう。
・次に予定されているDockerオンラインMeetupに登録してみましょう。
・次に予定されているDocker Meetupに参加してみましょう。
・DockerCon 2016に登録してみましょう。
・DockerCon EU 2015のビデオを見てみましょう。
・Dockerコミュニティへの貢献を始めましょう。



