
[和訳] Chef High Availability #opschef_ja #getchef_ja
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
この記事は High Availability の 2014/11/20 時点での和訳です。
高可用性 (High Availability, HA)
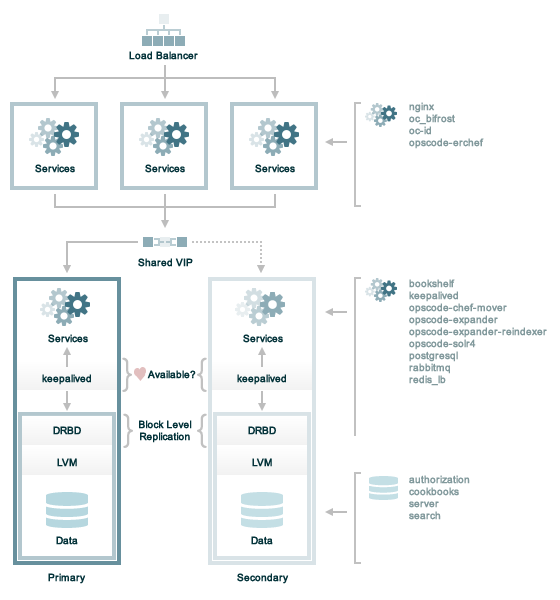
Chef Server は、システムアーキテクチャにおけるステートフルなコンポーネントの自動ロードバランシングとフェイルオーバーを提供する、HA構成で運用することができます。
通常、この形式の構成ではマシンをフロントエンドとバックエンドの2つのセグメントに分割します。
フロントエンドマシンはChef Server APIへのリクエストとウェブユーザインターフェイスへのアクセスをを取り扱います。フロントエンドマシンはロードバランシングされ、リクエストを取り扱うサーバの数を増やすことによる水平スケーリングされているべきです。
バックエンドマシンは、データの保管と取得、メッセージング、ルーティング、統計処理、検索を取り扱います。バックエンドマシンはブロックレベルのレプリケーションを用いたフェイルオーバーに構成されているべきです。
Chef Server 12では、次をHA構成としてサポートしています。
- DRBD
- AWS
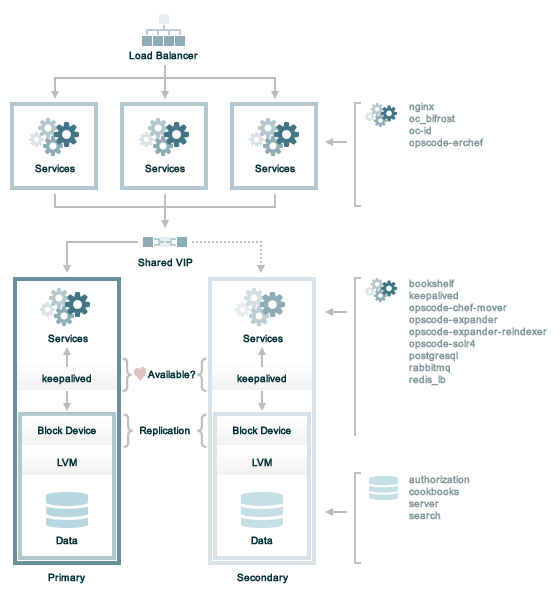
DRBD
Chef ServerのHA構成オプションとしてDRBDをサポートしています。

フロントエンドマシンはハードウェアロードバランサ、SSLオフローディング、ロードバランシングアルゴリズムに基いたラウンドロビンを用いてロードバランシングで水平スケーリングされます。
バックエンドマシンは、スループットを増加させるためにメモリ、CPUパワー、より早いディスクの追加、DRBDの信頼性とChef Serverの応答性を増加させるためにより早いディスクや専用のネットワークインターフェイスカードの追加といった垂直スケーリングされます。フェイルオーバは次のように行われます。
- 2つのバックエンドマシン間での、論理ボリュームマネージャ(LVM)の非同期ブロックレベルのレプリケーション
- ユニキャストTCP/IP上のVRRPとKeepalivedを用いたプライマリとバックアップクラスタの選択
- Keepalivedによる選択結果に基いて保持される、プライマリサーバへの仮想IPアドレス
クラスタのプライマリChef Serverに障害が発生したら、VRRPハートビートが停止します。この時点でバックアップサーバは次のようにプライマリ状態への移行を開始します。
- 仮想IPアドレスを割り当て、proxy-arpを送出します。この手順によって仮想IPアドレスの移行が行われ、プライマリChef Serverへの移行が行われている間、トラフィックがバックエンドサーバに流れることを意味します。
- DRBDデバイスのプライマリChef Serverとしてテイクオーバーを試みます。
- バックエンドサーバのすべてのサービスを開始します。
DRBDについて詳しくは公式ウェブサイト http://www.drbd.org/ を参照してください。
緩やかな移行
KeepalivedサービスはVRRPとクラスタ移行を管理します。Keepalivedはプライマリとセカンダリの両方のサーバで動作している必要があります。プライマリからセカンダリに移行するには、単純に次のコマンドをプライマリで実行します。
$ chef-server-ctl stop keepalived
これでプライマリChef ServerからセカンダリChef Serverへのフェイルオーバーを開始します。これは、現在のプライマリChef Serverから仮想IPアドレスを削除し、すべてのサービスを停止し、DRBDデバイスをアンマウントし、そしてセカンダリChef ServerのDRBDデバイスとします。この間、バックアップではこれと同じような処理を行います。
移行の進捗を確認するには、次のコマンドを実行します。
$ watch -n1 sudo chef-server-ctl ha-status
スプリットブレイン (split-brain)
split-brain は、クラスタがハートビートの通信路を失って2つの接続されていない要素になるというクラスタコンピューティングシステムでの概念です。split-brain からのリカバリはとても複雑な問題で、クラスタリングソフトウェアパッケージごとに方法が異なります。
障害が起きた場合、split-brain を完全に防ぐことは絶対に可能というわけではありません。しかし、ハートビートネットワークの帯域の最大化と転送プロトコルの最適化によって、split-brain のシナリオにおいて発生する問題のいくつかは軽減できます。
DRBDはシェアードナッシングなシステムです。データをすべてのホストに接続したNASやSANに中央集権的に保存するのではなく、専用ネットワークによって接続されたホスト間で複製します。HAトポロジのストレージにおけるもっとも致命的な問題は、データの喪失や破損です。すべてのシステムが起動し正常に動作している間にネットワークを通るデータ量を最大化しておくことは、ホストがダウンした際に何かが失われたり回復不能になる可能性を最小化します。
いかなる時でも、1つだけのDRBDホストがデータにアクセスする userland を持ち、このホストがプライマリノードとして参照されます。DRBDデーモンを起動している他のホストは、ストレージをファイルシステムにマウントできません。セカンダリノードはプライマリノードから情報を受け取り、ローカルストレージコピーにディスクに対する動作を複製します。パーティションがファイルシステムを持っていないように見えるとしたら、mount コマンドが送られます。
DRBDが split-brain 状態になると、DRBDはまだ生きているすべてのパートナーをセカンダリ状態にデグレードし、手動による修復を待ちます。これはオートフェンシングと呼ばれ、データ損傷の可能性を最小にすることを目的としています。HAトポロジにおいてパートナーの1つを失ったら、ディスク異常を取り除いてバックアップを取るための手動修復が必要になります。このようなシナリオについては、診断や復旧方法の提案を含んだ以降の検討事項を見てください。
カスタムハンドラ
DRBDには split-brain が発生した際のカスタムハンドラが設定できます。基本ハンドラは設定した宛先にメールを送信でき、それによって問題の発生を知ることができます。
Chef Serverが用いている drbd.conf ファイルには、特定の障害シナリオで実行される次のような組み込み動作があります。
after-sb-0pri discard-younger-primary;
after-sb-1pri discard-secondary;
after-sb-2pri call-pri-lost-after-sb;
これらは次のような意味になります。
- after-sb-0pri: split-brain を検知したら、そうでないノードがプライマリノードです。discard-younger-primary は、プライマリノードだった最後のホストに行われたすべての変更をロールバックします。
- after-sb-1pri: split-brain を検知したら、ただ1つのノードが発生時にそれがプライマリノードだったとみなします。discard-secondary はプライマリノードで処理を続け、セカンダリノードが失われたと仮定します。
- after-sb-2pri: split-brain を検知したら、両方がプライマリノードだったとみなします。call-pri-lost-after-sb は、プライマリノードであるべきホストを決定するために、0pri 設定から discard-younger-primary を適用します。決定したら、他のホストはセカンダリノードになるよう処理を行います。
例
次はHAトポロジでChef Serverをデプロイした例です。
- バックエンドプロセスは BE1 と BE2 の 2つのホストで動作している。BE1 はDRBDプライマリでマスターChef Server、BE2 はDRBDセカンダリでバックアップChef Server。
- バックエンドはKeepalivedと、ハートビート用に専用ネットワークインターフェイスを用いている。
- バックエンドはファイル冗長性のためにDRBDを用いている。
各ホストは自身の状態を先に報告し、それからリモートのパートナーの状態を報告します。
プライマリノードとセカンダリノードの両方が期待通りに動作しているとき、プライマリノードの /proc/drbd は次のようになります。
version: 8.4.0 (api:1/proto:86-100)
GIT-hash: 28753f559ab51b549d16bcf487fe625d5919c49c build by root@localhost.localdomain, 2012-02-06 12:59:36
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:4091788 nr:64 dw:112 dr:4092817 al:3 bm:252 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
セカンダリノードでは次のようになります。
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by dag@Build64R6, 2011-12-21 06:08:50
0: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:48 dw:48 dr:0 al:0 bm:2 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
このファイルについて詳しくはDRBDのウェブサイト http://www.drbd.org/users-guide/ch-admin.html を参照してください。
障害シナリオ
4つのよくあるシナリオを検討してみます。
- バックエンドサーバ #2 が緩やかに障害 (全データが同期)
- バックエンドサーバ #2 がひどい障害 (データが非同期)
- バックエンドサーバ #1 が緩やかに障害 (全データが同期)
- バックエンドサーバ #1 がひどい障害 (データが非同期)
- 両方のホストがセカンダリで起動し、Chef Serverが不適切な状態に
シナリオ 1 と 2
バックアップサーバに障害が発生した際、セカンダリのDRBDが緩やかに停止するか予期せぬ停止が起きたかに関わらず、マスターのDRBDはプライマリモードとして機能し続けます。プライマリで drbdadm role pc0 を実行することで、DRBDが機能していることを検証します。
[root@be1 opscode]# drbdadm role pc0
Primary/Unknown
[root@be1 opscode]#
cat /proc/drbd を実行することで、完全な状態を確認できます。
version: 8.4.0 (api:1/proto:86-100)
GIT-hash: 28753f559ab51b549d16bcf487fe625d5919c49c build by root@localhost.localdomain, 2012-02-06 12:59:36
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r-----
ns:672 nr:0 dw:24 dr:1697 al:2 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:130760
ディスクパーティションはファイルシステムに依然としてマウントされていて、通常通りに利用できます。
セカンダリが再び利用可能になったら、次の2点が起こります。
- セカンダリの状態が手動修復なしで Inconsistent か UpToDate である場合、すべて問題ありません。
- DUnknown のままの場合、セカンダリのDRBDは手動で再起動でき、同期を開始できるでしょう。DUnknown はDRBDがパートナーに対するネットワーク接続を見つけられないことを示しています。
/prod/drbd ファイルの最後の項目 (oos) は、プライマリがパートナーとどれだけ同期がずれているかを示します。セカンダリがダウンしてプライマリに多くの書き込みがある場合、この数値は増え続けます。
version: 8.4.0 (api:1/proto:86-100)
GIT-hash: 28753f559ab51b549d16bcf487fe625d5919c49c build by root@localhost.localdomain, 2012-02-06 12:59:36
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r-----
ns:5205048 nr:64 dw:1466728 dr:4180125 al:354 bm:261 lo:1667 pe:0 ua:0 ap:1665 ep:1 wo:b oos:361540
ディスクが同期済の状態に戻ると、この項目は 0 に戻ります。セカンダリが同期している間、同期の進行状況は両方のホストで表示されます。セカンダリでは次のようになります。
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by dag@Build64R6, 2011-12-21 06:08:50
0: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
ns:0 nr:1263008 dw:1257888 dr:0 al:0 bm:60 lo:6 pe:8 ua:5 ap:0 ep:1 wo:f oos:1670512
[======>.............] sync'ed: 36.3% (1670512/2613068)K
finish: 0:00:47 speed: 35,152 (18,124) want: 44,520 K/sec
プライマリでは次のようになります。
version: 8.4.0 (api:1/proto:86-100)
GIT-hash: 28753f559ab51b549d16bcf487fe625d5919c49c build by root@localhost.localdomain, 2012-02-06 12:59:36
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:7259268 nr:64 dw:4279364 dr:5721317 al:949 bm:360 lo:5 pe:0 ua:5 ap:0 ep:1 wo:b oos:1121600
[==========>.........] sync'ed: 57.3% (1121600/2613068)K
finish: 0:00:32 speed: 34,328 (21,304) K/sec
結果としてホストは安定状態の ds:UpToDate/UpToDate となります。セカンダリがどれだけダウンしていたか、その間にプライマリにどれだけデータが書き込まれたか、共有ネットワークがどれだけの速度かに依存して、このプロセスは瞬間的に完了するか数分かかるかします。この復旧の間、Chef Serverのプロセスに対して手動で何かする必要はありません。
セカンダリホストが完全に失われた場合、新しいホストをインストールし、デバイスを構築し、DRBDを起動します。新しいホストは既存のプライマリと組になり、データを同期し、必要なら切り替える準備状態となります。
シナリオ 3
DRBDプライマリが利用不可能になったときから発生する障害です。セカンダリのDRBDプロセスは、drbd.conf ファイルのスプリットブレイン設定に基いて、自動的に切り替わるべきかそうでないかを仮定できません。
基本的に、明示的な切り替えの開始がないままプライマリがセカンダリに対して利用不可能になるという状態が意味することは、セカンダリは自分自身が問題のある split-brained ホストであり、接続されておらず正確でないと仮定します。自動的な動作は行われません。
セカンダリの状態は次のようになります。
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by dag@Build64R6, 2011-12-21 06:08:50
0: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r-----
ns:0 nr:3505480 dw:4938128 dr:0 al:0 bm:290 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
ds:UpToDate/Unknown が重要です。これはセカンダリがプライマリにあるすべてのデータを保持していて、昇格しても何も失われないことを示しています。
プライマリホストがしばらくの間ダウンすると確認されているなら、セカンダリをプライマリに昇格します。
$ drbdadm primary pc0
この時点で状態は次のように変わります。
version: 8.4.1 (api:1/proto:86-100)
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by dag@Build64R6, 2011-12-21 06:08:50
0: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r-----
ns:0 nr:3505480 dw:4938128 dr:672 al:0 bm:290 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
ro が ro:Primary/Unknown になったことに注目してください。これで次のコマンドを実行することでChef Serverを復旧できます。
$ chef-server-ctl master-recover
設定されたサービスを起動し、Chef Serverはこのホストでマスターになります。
元々のプライマリがオンラインに復帰したら、Keepalivedによって起動されるクラスタ管理スクリプトが、そのホストの元々のプライマリChef Serverマスターの状態に基き、DRBDの切り替えを試みます。
まずは自身をDRBDプライマリに昇格しようと試みますが、ホストがダウンしている間に完全にディスクに書かれているなら昇格は失敗し、Keepalivedは元々のマスターへ戻すことができません。第2バックエンドマシンはDRBDプライマリChef Serverマスターとして、サーバ群はよい状態に置かれます。
第1バックエンドサーバのDRBDは第2バックエンドサーバに同期し、クリーンなセカンダリFQDNとなります。
シナリオ 4
これまでのシナリオはデータロスがありませんでした。HA構成のホストのペアが同期されている場合、どちらか一方が失われてもデータは保持されます。
プライマリホストが失われて復旧不可能という状況になり、DRBDペアの最新状態にてセカンダリノードが Inconsistent の状態となっている場合、何らかのデータが失われた可能性が非常に高いです。残ったホストのDRBD状態は次のようになります。
version: 8.4.0 (api:1/proto:86-100)
GIT-hash: 28753f559ab51b549d16bcf487fe625d5919c49c build by root@localhost.localdomain, 2012-02-06 12:59:36
0: cs:WFConnection ro:Secondary/Unknown ds:Inconsistent/DUnknown C r-----
ns:0 nr:210572 dw:210572 dr:0 al:0 bm:13 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:40552
chef-repoにおけるCookbookやその他のファイルが十分にソースコード管理されている場合に限り、クラスタが復旧した後で何か欠けてしまったものは再アップロードできます。ただしいくつかの場合において、新しく作成したUserやOrganizationは再作成の必要があります。クラスタが Inconsistent 状態の間に行われた、その他のChefの動作やアップロードは失敗していますが、クラスタが復旧した後は成功するでしょう。
プライマリバックエンドサーバが失われてしまい、その間にセカンダリバックエンドサーバが Inconsistent 状態となり、早急に復旧できない場合、最善策は他のホストにプロビジョニングを行い、セカンダリバックエンドサーバの新しいChef Serverクラスタのパートナーとして構築することです。新しいホストがプライマリバックエンドサーバと異なるIPアドレスを持つ場合、セカンダリバックエンドサーバの設定の変更してから、再設定の必要があります。
この状況ではChef Serverが異常動作を起こしてしまうので、chef-server-ctl stop コマンドを用いてデーモンを停止します。
一旦新しいホストが認識され、そのホストのDRBDデバイスの準備が整ったなら、DRBDを起動してセカンダリバックエンドサーバとの通信を開始します。セカンダリサーバはプライマリサーバとなるべきではなく、古いプライマリサーバの復帰を待つべきです。新しいホストでDRBDを起動したら、正しいポートで待ち受けしているか、/proc/drbd にてホストが起動しているが WFConnect: waiting for connection 状態を示しているか、確認します。
新しいノードが起動するまで、セカンダリバックエンドサーバは standalone モード、すなわちネットワークポートをもはや待ち受けしていない状態になっています。この状態では、次のコマンドを実行してセカンダリバックエンドサーバが新しいノードと通信するようにします。
$ drbdadm primary --force pc0
$ drbdadm connect pc0
この時点で、新しいホストはセカンダリバックエンドサーバと同期を開始します。セカンダリバックエンドサーバは既に存在しないプライマリバックエンドサーバから失われたデータに関するすべてを忘れて、Chef Serverの復旧プロセスを開始します。
プライマリホストとセカンダリホスト間を高速なネットワークで接続し、DRBDの転送を最高速に保つことが、同期できていないクラスタからプライマリの喪失によるダメージを大いに軽減するでしょう。
シナリオ 5
ときどきDRBDは安全を期して、ペアの両方のノードをセカンダリモードとします。この状態になったら、両ホストの /proc/drbd の内容を確認し、どちらかが同期していないかを確認します。両方とも oos:0 の場合、どちらか1つを選んで drbdadm primary pc0 コマンドを用いてプライマリに昇格させます。両方もしくは片方のホストの同期が取れていない場合、oos の数値が低いほうを選び、プライマリに昇格させます。
選んだノードが昇格しない場合、もう片方のホストで次のコマンドを実行してディスクの状態をリセットします。
$ drbdadm wipe-md pc0
$ drbdadm create-md pc0
これは DRBD にノードのデータを放棄して最初からやり直し、プライマリに同期するよう指示します。
AWS
Chef ServerのHA構成オプションとしてAmazon Web Servicesをサポートしています。
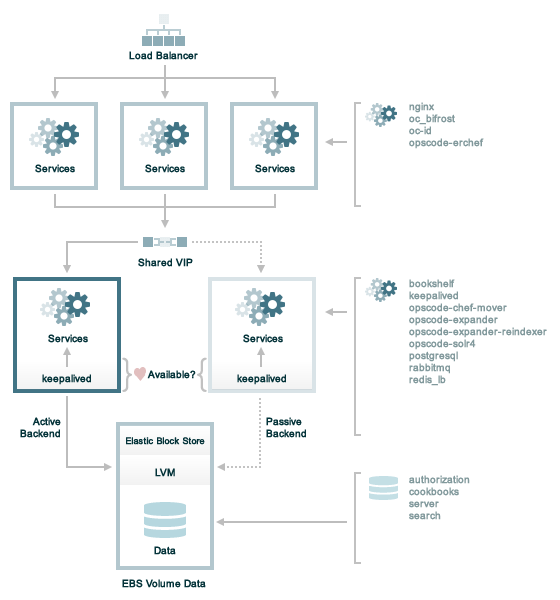
マシンはAmazon Elastic Block Storeのボリュームとして格納されます。パッシブノードがアクティブノードの有効性を監視し、必要があればテイクオーバーします。
Amazon Elastic Block Storeについて詳しくは http://aws.amazon.com/ebs/ を参照してください。
Amazon Web ServicesにHA構成のChef Serverを設定するにはどうしたらよいかの詳しい情報は High Availability: AWS (訳注: 和訳) を参照してください。
HAステータスの確認
/_status エンドポイントは、フロントエンドサーバとバックエンドサーバの通信状態の確認に利用できます。このエンドポイントはフロントエンドサーバの /_status にあります。
リクエスト
api.get("https://chef_server.front_end.url/_status")
このメソッドはリクエストボディを持ちません。
レスポンス
レスポンスは次のようになります。
{
"status" => "pong",
"upstreams" =>
{
"service_name" => "pong",
"service_name" => "pong",
...
}
}
レスポンスコード
| レスポンスコード | 説明 |
|---|---|
| 200 | すべての通信が正常 |
| 500 |
1つ以上のサービスが停止。例: |



