
[和訳] Habitatのサービスディスカバリを深く掘り下げる #getchef #habitat
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本稿は Habitat Service Discovery: A Deep Dive (2018/08/08) の和訳です。
すべてのアプリを、場所を問わず同じ方法でデプロイおよび管理できるHabitatを魔法のようだと感じる人もいるでしょう。Habitatは魔法ではありませんが、考え抜かれた技術です。
Habitatにおいて、アプリケーションとは自動化の単位です。
Widget World -- 私たちのアプリケーション
サンプルアプリケーションを見てみましょう。このサンプルアプリケーションを作る上で私たちは、"Widget World"という会社で働いていると仮定します。私たちは今、自分たちのウィジェットを公開し、人々に閲覧してもらえるようカタログの概要を作成しようとしています。
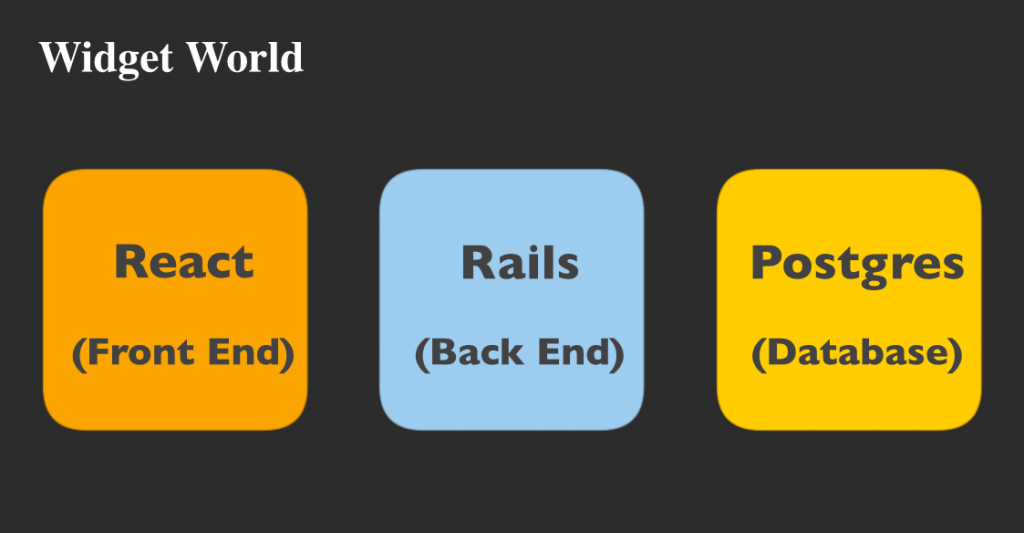
このカタログを、3つのマイクロサービスとして運用することにしました。アプリケーションのフロントエンドはReact、バックエンドはRails、そして永続データはPostgreSQLデータベースで作成します。
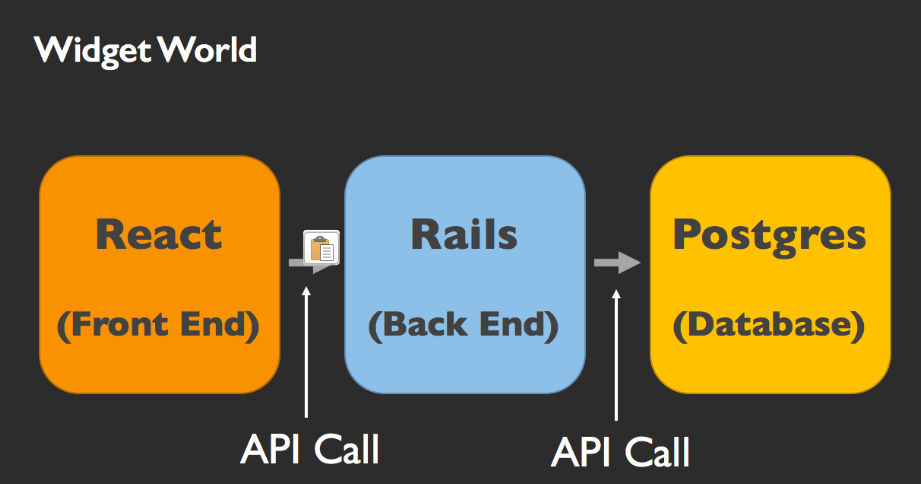
ユーザがサイトを訪れた際、最初に目にするのはReactがレンダリングしたフロントエンドです。ウィジェットの一覧を要求すると、Reactのフロントエンドは、RailsのバックエンドへAPI呼び出しを行います。そしてRailsのバックエンドはPostgreSQLデータベースに生のデータを要求し、受け取った生データを整形したのちReactのフロントエンドへ戻し、Reactがレンダリングしたデータをユーザは目にします。
コンテナでReactおよびRailsサービスを実行しましょう。これらはステートフルである必要がないため、コンテナ内で実行することで得られるスピードと柔軟性を活用できます。
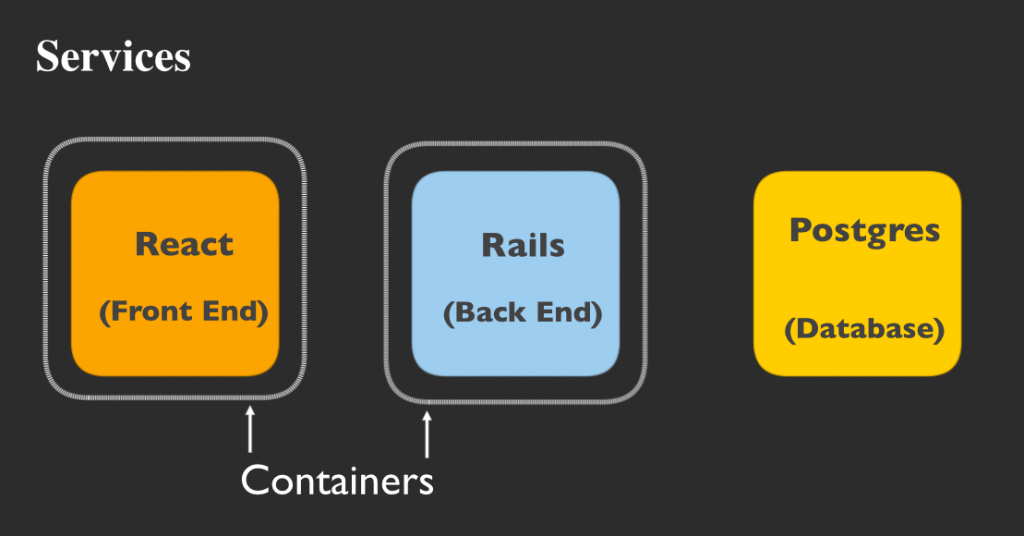
PostgreSQLデータベースはVMで実行しましょう。分離したボリュームに永続データを保存しない限り、PostgreSQLデータベースはステートフルです。デプロイを繰り返してもデータの永続性を維持したいので、PostgreSQLデータベースはコンテナではなくVMで実行しましょう。
各サービスごとに1つずつインスタンスは、しばらくの間はうまく動くかもしれません。しかしこのウェブサイトへトラフィックが増大していくにつれて、トラフィックをさばくためにサービスの複製が必要になるでしょう。React、Rails、PostgreSQLの各サービスをそれぞれ3つに増やします(PostgreSQLサービスはLeader/Followerクラスタなどで実行することになるでしょう)。これらのサービスをHabitatで実行(各サービスにつき、それぞれのHabitatパッケージを使用)している場合、"3つのサービスグループがある" ということになります。
サービスグループ
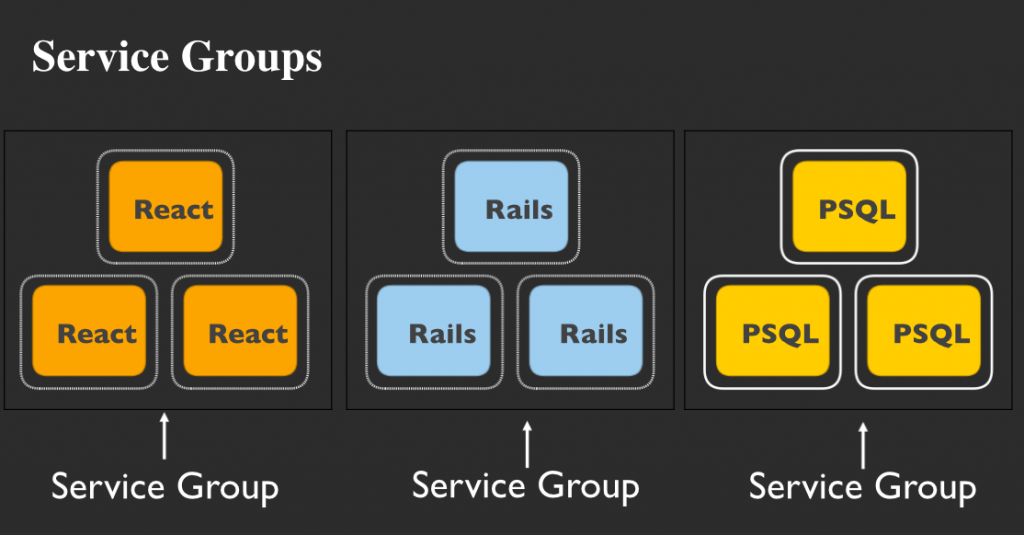
これらサービス(サービスとは、スーパーバイザー下で実行しているHabitatパッケージのこと)の集合を、サービスグループと呼びます。サービスグループのメンバーは、それぞれで同じパッケージを実行します。
そして、これらすべてのサービスが共同で1つのスーパーバイザーリングを作り上げます。
スーパーバイザーリング
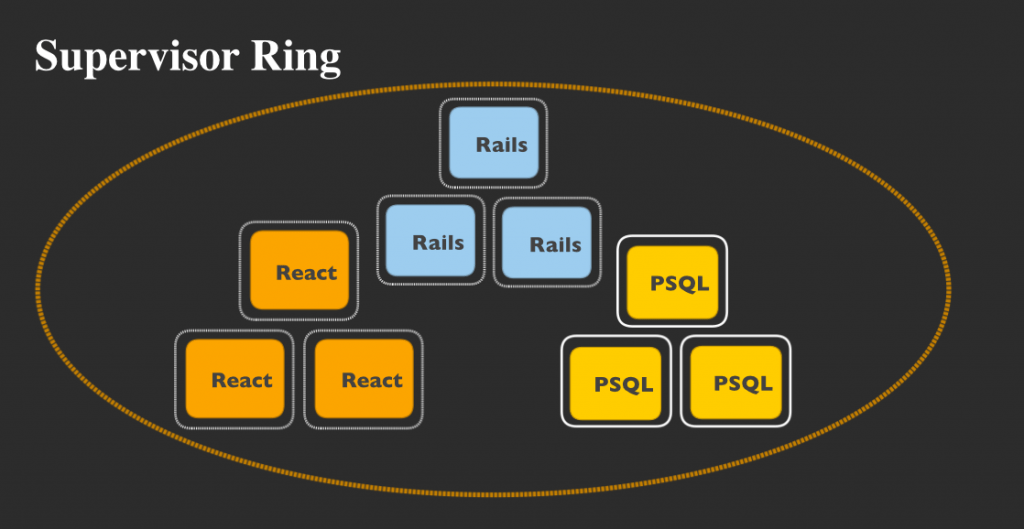
スーパーバイザーリング内のすべてのサービスは(たとえ異なるサービスグループのものであっても)、他のすべてのサービスと通信が可能です。新しいサービスが追加されるたびに、既存の各サービスは新規サービスの存在を認識するようになります。そしてサービスに障害が出るたびに、他のすべてのサービスにその障害を通知します。どのような仕組みで、このようなことが可能になっているのでしょうか?サービスディスカバリを通じて可能になっています。
サービスディスカバリ
サービスディスカバリは、あるサービスが他のサービスを探し出す方法、サービスを追跡し続ける方法、そして有効なサービスの変更を通知する方法を提供する仕組みです。サービスディスカバリはもはや一般的なものです。インフラストラクチャの異なる部分同士がお互いの存在を認識できるようにするために常に必要とされています。
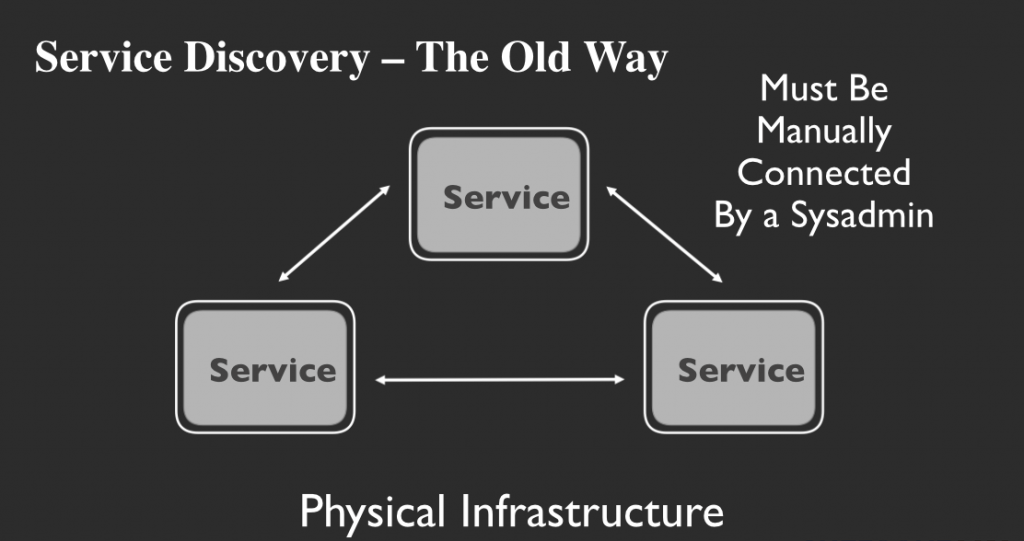
物理的および静的なインフラストラクチャの時代には、このサービスディスカバリを手動で行っていました。新規サービス追加のたびに、システム管理者は既存のすべてのサービスがその新規サービスを認識するように設定する必要があり、各サービスの設定ファイルをすべて手動で変更していました。この方法は、静的インフラストラクチャの時代には問題ありませんでしたが、素早い対応が必要な動的サービスの時代には適していません。
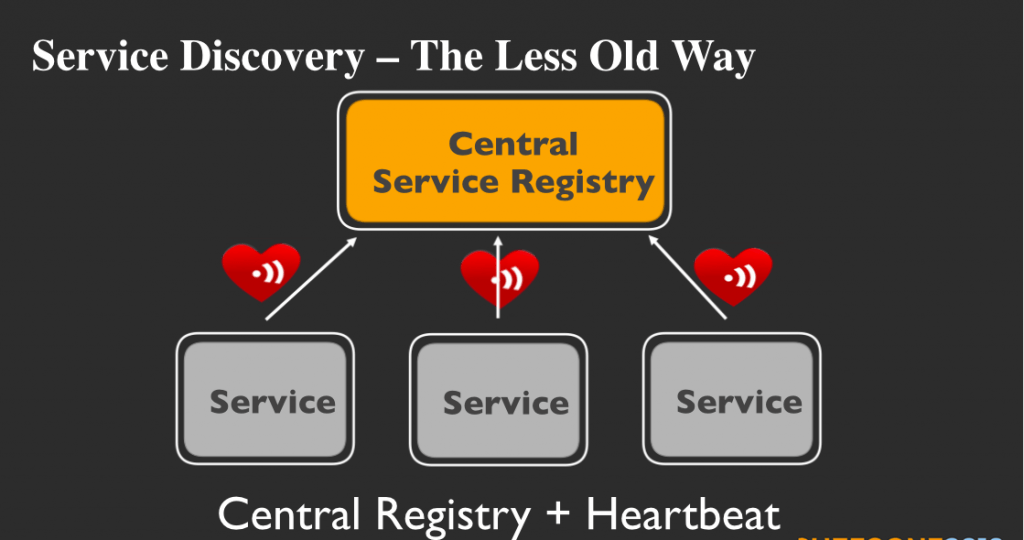
ごく最近までサービスディスカバリのほとんどは、集中型のサービスレジストリが取り扱っていました。各サービスは集中型サービスレジストリとハートビートメッセージで通信し、自身の存在を通知していました。あるサービスが別のサービスと対話する必要があれば、まずは適切な宛て先を教えてくれる集中型サービスレジストリと通信する必要がありました。このアプローチの問題点は、集中型サービスレジストリに大量のネットワーク負荷をかけることです。そのネットワーク負荷はサービス数が増大するにしたがって、管理不可能な域に達します。この課題を解決するために、コーネル大学の研究者たちはSWIMプロトコルと呼ばれる新しいシステムを開発しました。
SWIMプロトコル
SWIMは「Scalable Weakly-consistent Infection-style process group Membership protocol」の略ですが、長く言いにくいので正式名称を覚える必要はありません。
ここではSWIMプロトコルは、2つの主要なコンポーネントから成るということだけを覚えておいてください。
- Failure Detector Component(障害検知コンポーネント)--サービスに障害が起こり要求を受け付けられなくなった際にそれを検知します。
- Dissemination Component(宣伝コンポーネント) -- グループ内の他のサービスに、サービスについての情報を通達します。
掘り下げてみましょう:

あるサービスを仮定します。SWIMプロトコルを使用しているグループ内の各サービスは、当該グループ内の他のサービスのローカルリストを作ります。集中型サービスレジストリに頼るのではなく、各サービスが自分達でグループ内のメンバーを追跡します。
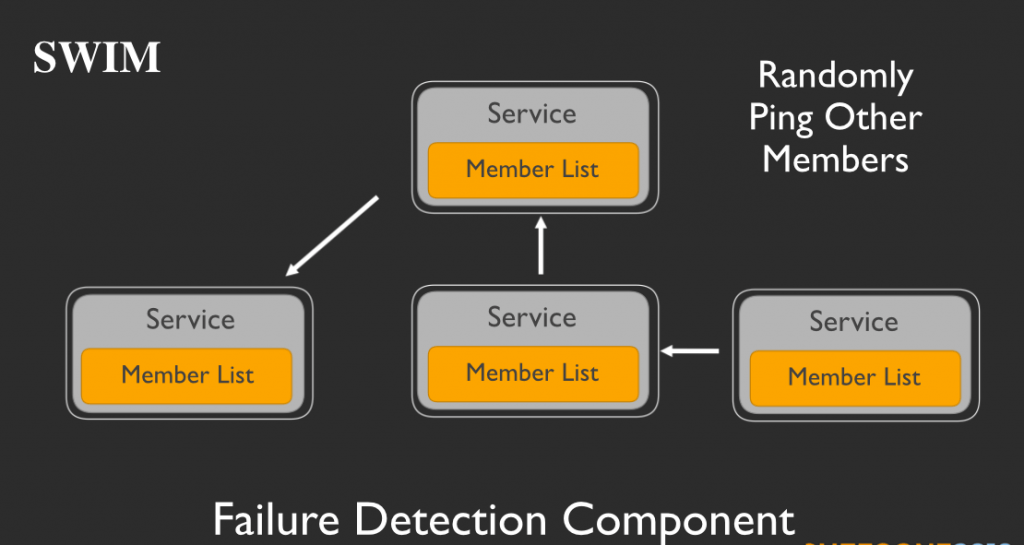
そして、各サービスはそれらのメンバーリストを、グループ内の他のメンバーに対してランダムにpingを打つことで最新の状態に保ちます。このワークフローをもう少し掘り下げてみましょう。
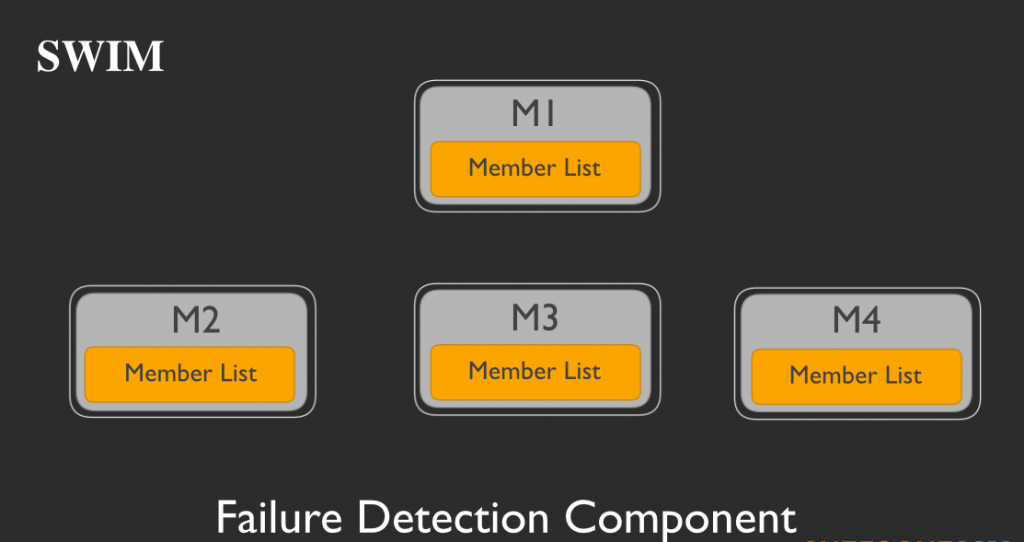
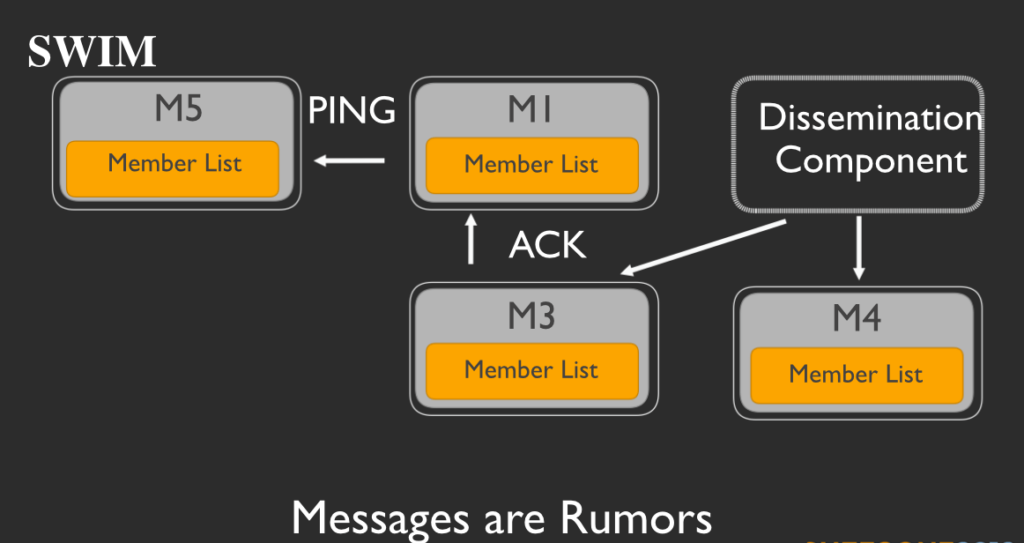
M1、M2、M3、M4という4つのメンバーからなるサービスグループがあると仮定します。それぞれのメンバーは各自でメンバーリストを持っています。定期的に各メンバーは、メンバーリストからランダムに他のメンバーを選択します。ここではM1が、M2を選択したとしましょう。そしてM1がpingをM2に打つことで、M2が健在かを確かめます。
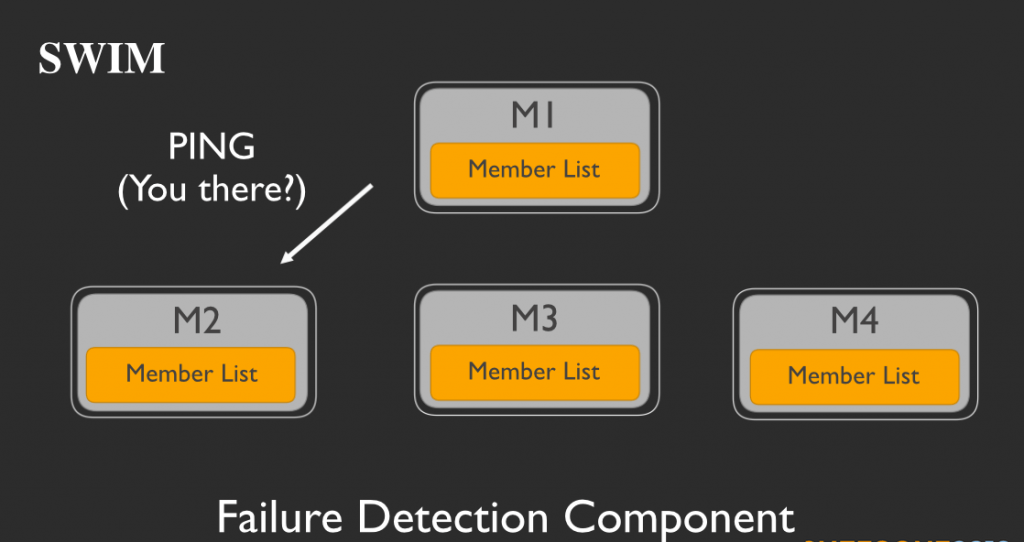
M2はpingを受信すると、pingを受け取ったことを示すACKメッセージを返信し、これによってM1に自らが健在であることとメッセージを受信したことを伝えます。
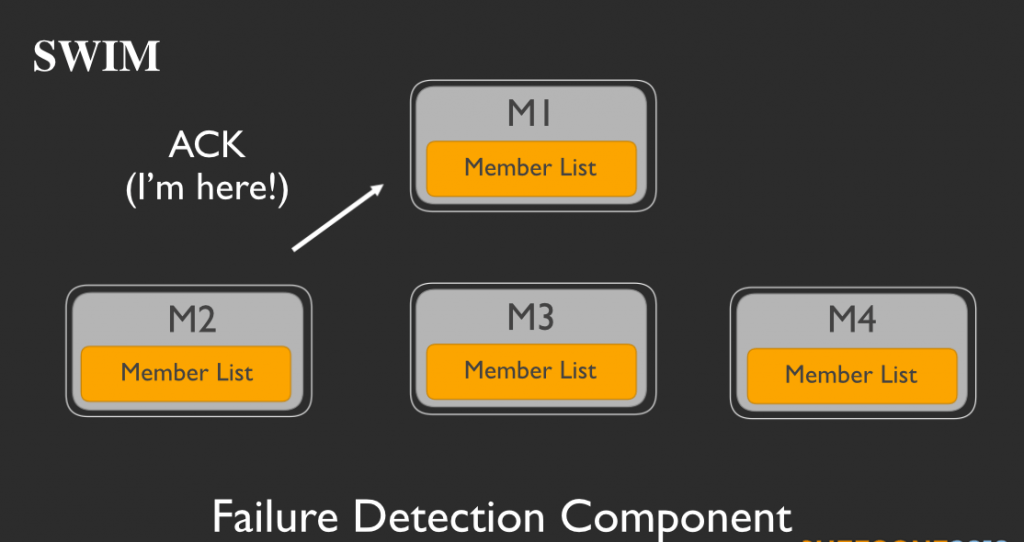
しかし、M2が決められた時間内にACKメッセージを返信しない場合:
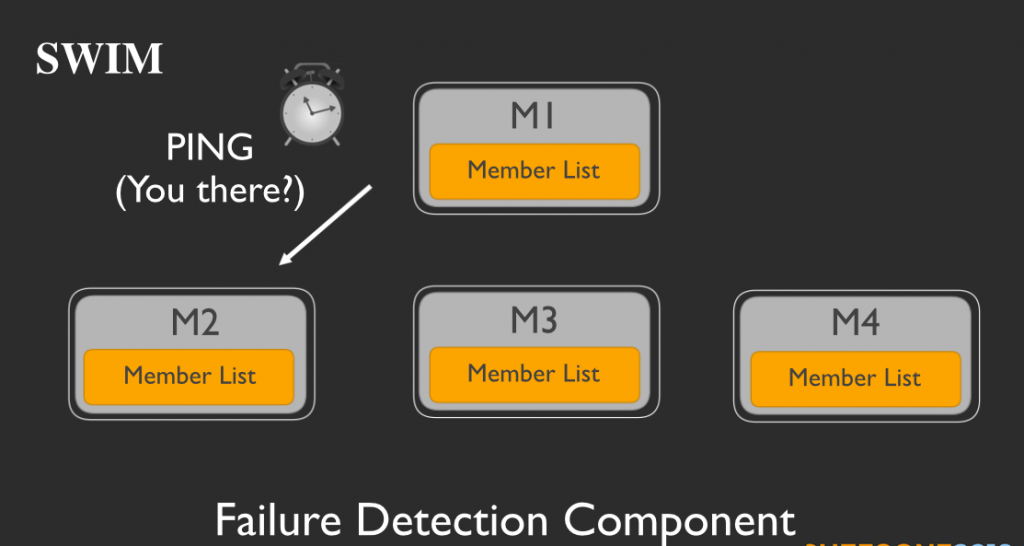
M1はM2の調査を開始します。M1は他のメンバーをランダムに選択します。ここではM3とM4を選択したと仮定しましょう。そしてM1は、M2にpingを打つようにM3とM4にメッセージを送ります。
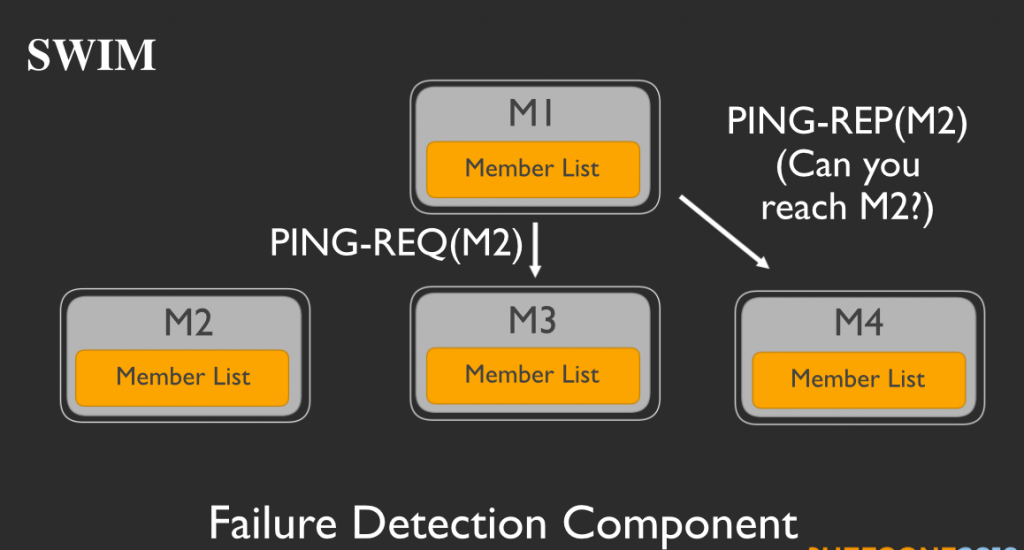
そしてM3とM4はそれに従い、M2にpingを打ちます。
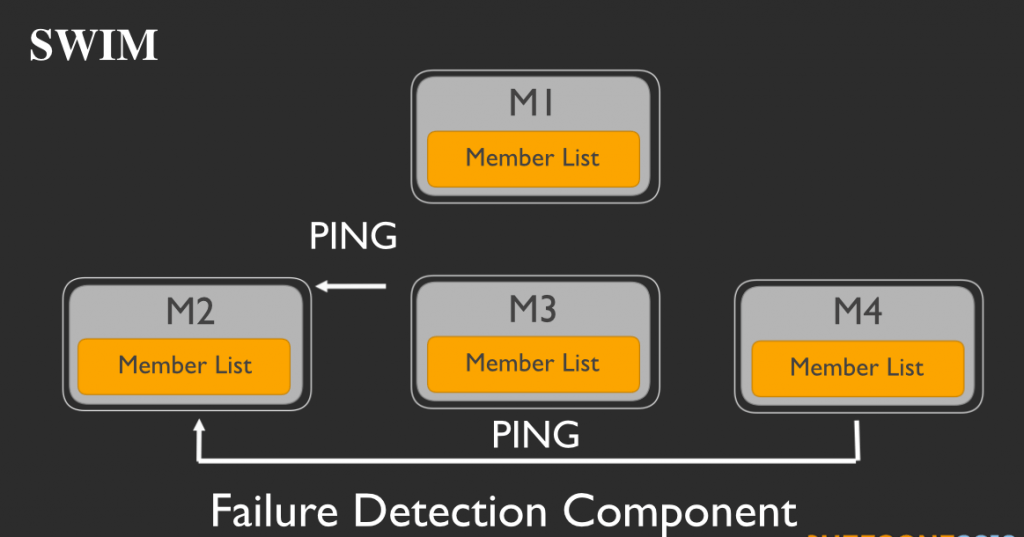
もしM2が応答したら(ここではM3にACKメッセージを返信したとしましょう)、M3はM1にそれを転送します。
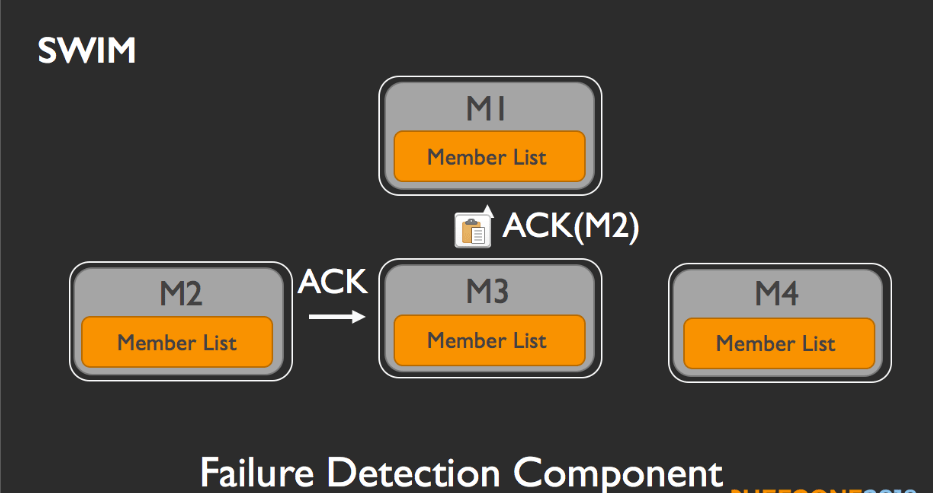
もし、M3とM4の両者から転送メッセージが届かず、M1自身もいまだにM2から何の応答も得られなければ、M1はメンバーリストからM2を削除します。
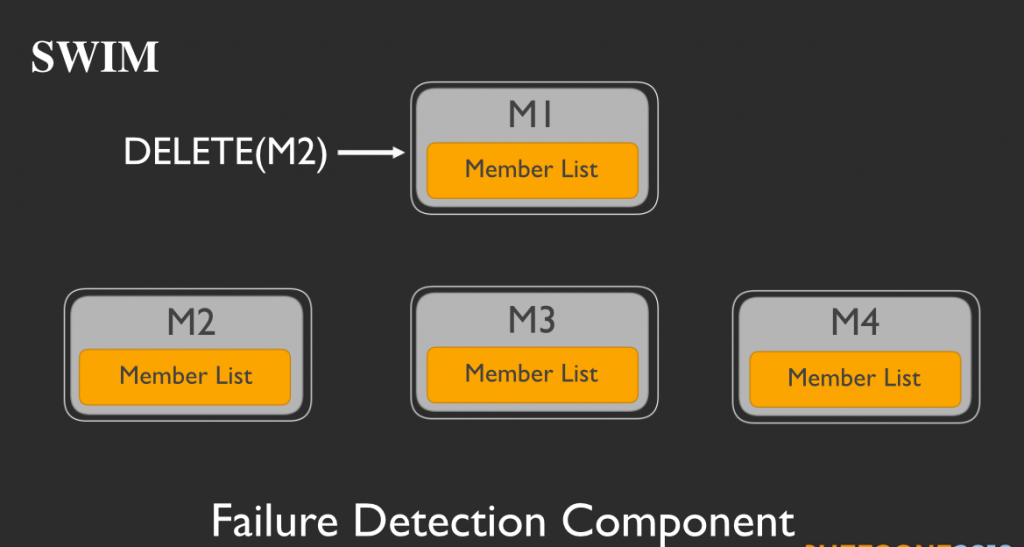
そしてM1は宣伝コンポーネントに削除要請を送ります。次に宣伝コンポーネントが、削除メッセージを他のメンバーに展開します。
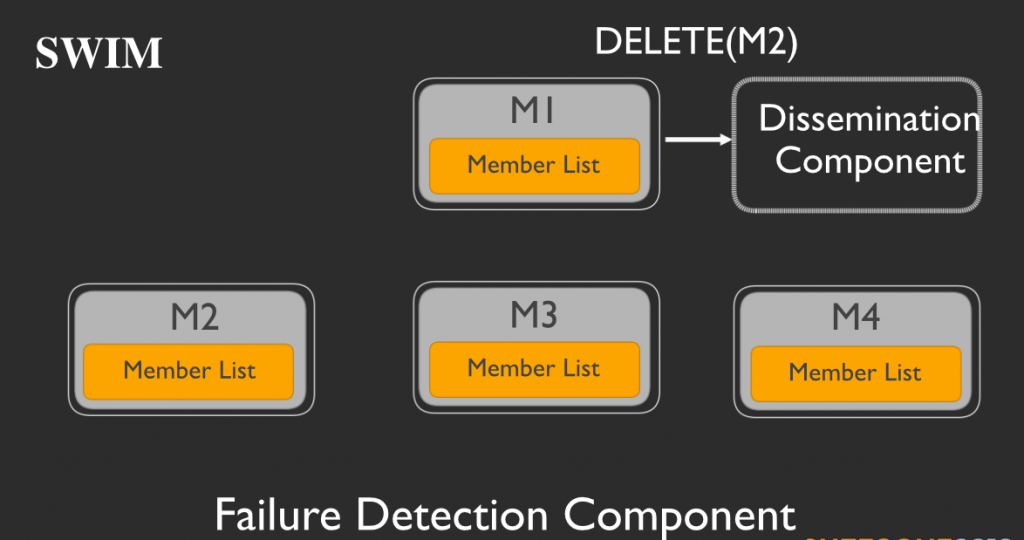
つまり宣伝コンポーネントがM3とM4に、M2を削除するメッセージを送ります。
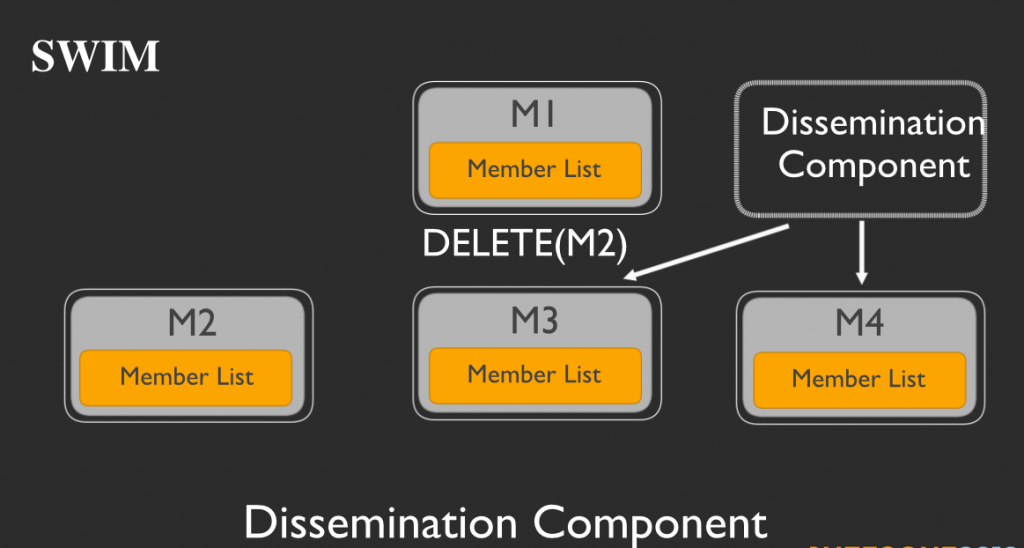
こうしてM3とM4がM2をメンバーリストから削除した後は、M2の存在はリングから消えます。

では次に、このグループに新しいメンバーM5を加えたいと仮定しましょう。ここですべきことは、グループ内の現在のメンバーのうちの1つとM5をピアリングするだけです。

M5とピアリングしたメンバーは、宣伝コンポーネントにM5という新しいメンバーが存在することを伝えます。

そして宣伝コンポーネントはそのメッセージをグル―プ内の他のメンバーに伝え、各メンバーが自身のメンバーリストにM5を加えます。
GOSSIP(ゴシップ)プロトコル
このワークフローは人間社会におけるうわさ話(ゴシップ)の広がり方に似ているので、このプロトコルは ゴシップ型プロトコル として知られています。その流れで、各メンバー間にブロードキャストする情報も rumors(うわさ話) と呼んでいます。
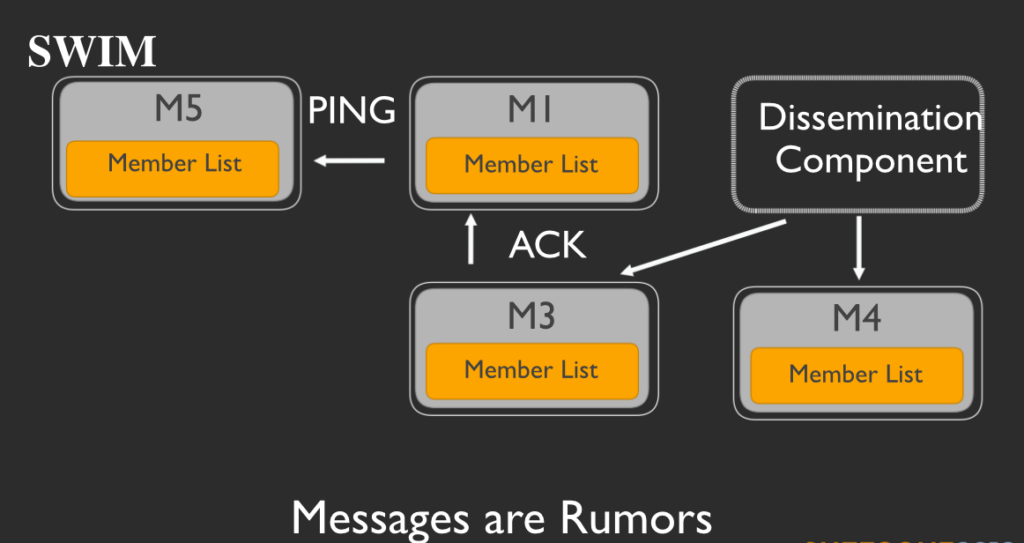
Habitatは Butterfly という独自のゴシッププロトコルを実装しています。
Butterfly
Butterflyは実際には2つのプロトコルの組み合わせです。
- SWIM (メンバーの障害と検知)
- Newscast (宣伝)
Butterflyの実際の動作は こちらの動画 でご覧ください。
ButterflyはSWIMを実装しており、元来のSWIMプロトコルにButterflyが追加しているいくつかの重要な点があります。
- メンバーの障害を確認した際に、メンバーをリストから削除 しない ことです。削除する代わりに 死亡確認 としてマークしてメンバーリストに残します。
- Butterflyでは、メンバーのうちいくつかを 永続メンバー とすることができます。
- Butterflyには、追放 という概念もあります。これはリングから強制的にサービスを追い出すことができる機能です。
死亡確認メンバー
メンバーは、自身の送ったpingに対してACKメッセージを返信しないメンバーに対して、調査を開始します。調査後もやはりACKメッセージを返信しないメンバーを、そのメンバーはリスト上で「死亡確認」とマークします。そして宣伝コンポーネントにその旨を伝えるメッセージを送信します:
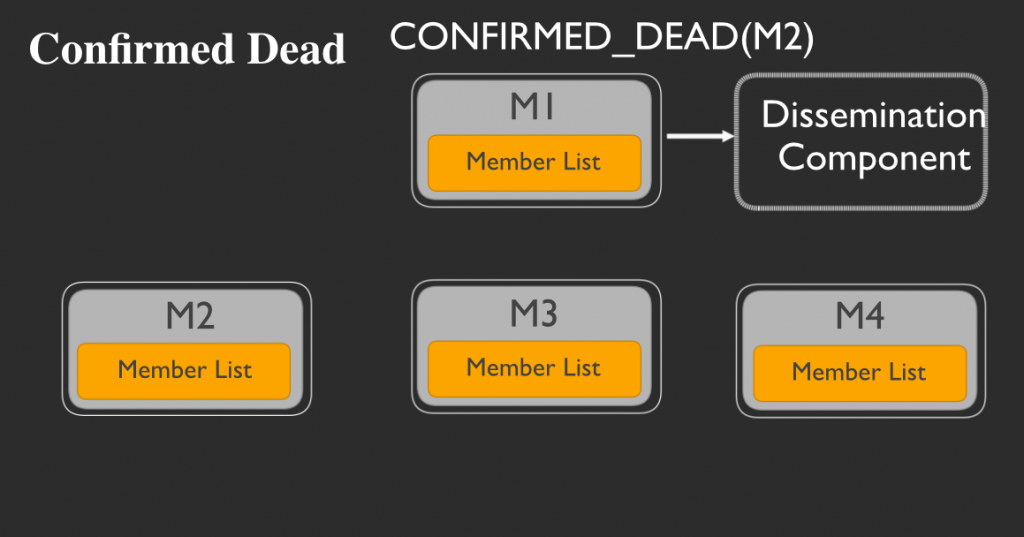
そして宣伝コンポーネントは、他のすべてのメンバーにそのメッセージを展開します。
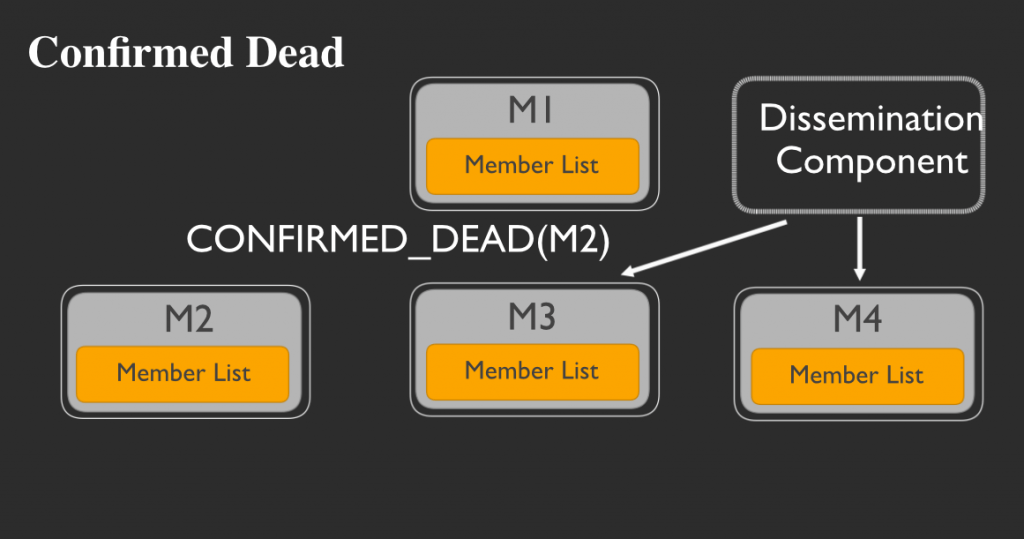
死亡確認されたメンバーの例は、 こちらの動画 でご覧ください。
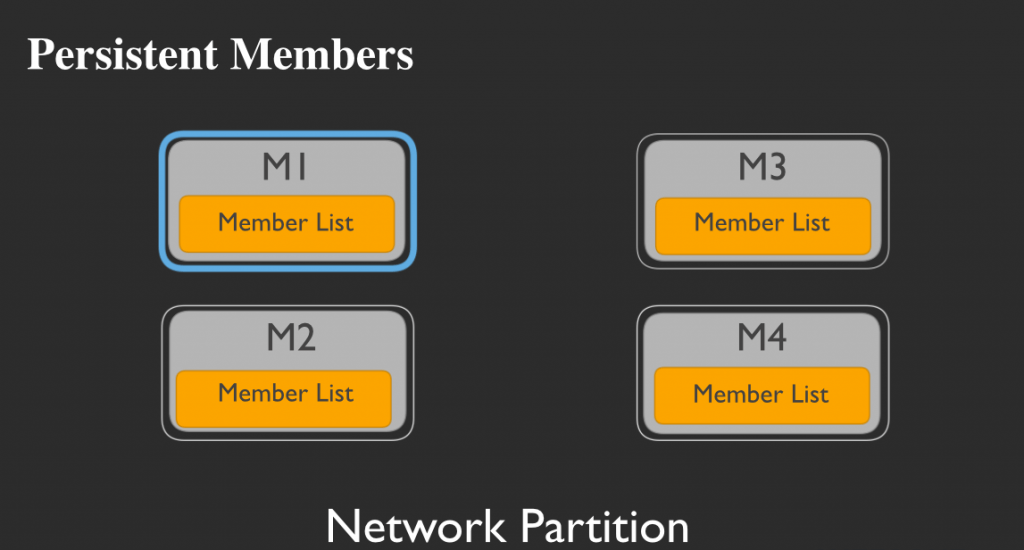
永続メンバー
グループ内に4つのメンバーがいるとします。そのうち1つ(訳注:ここではM1)を永続メンバーに指定すると、他のすべてのメンバーは当該メンバーに対して何があってもいつも通りにpingを打つことが可能となります。
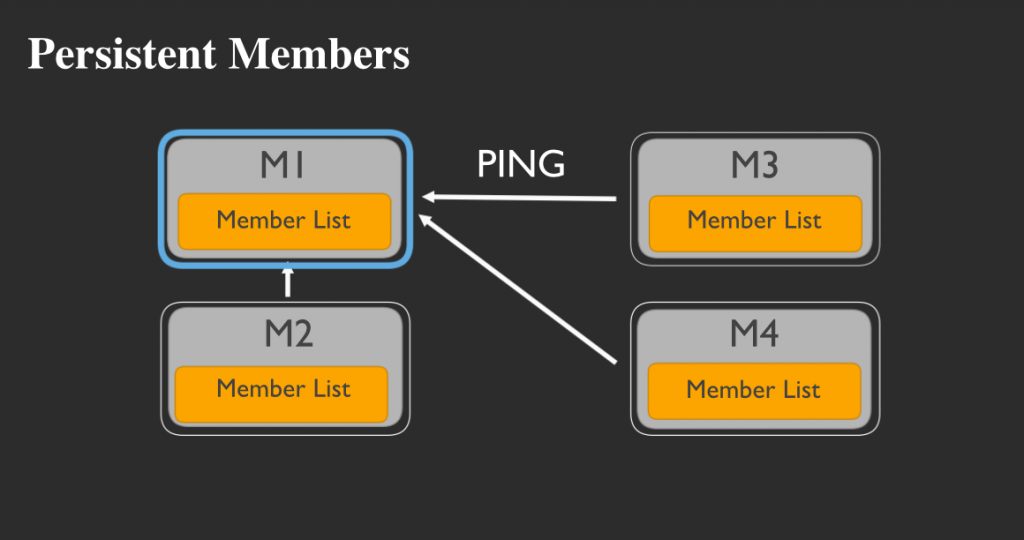
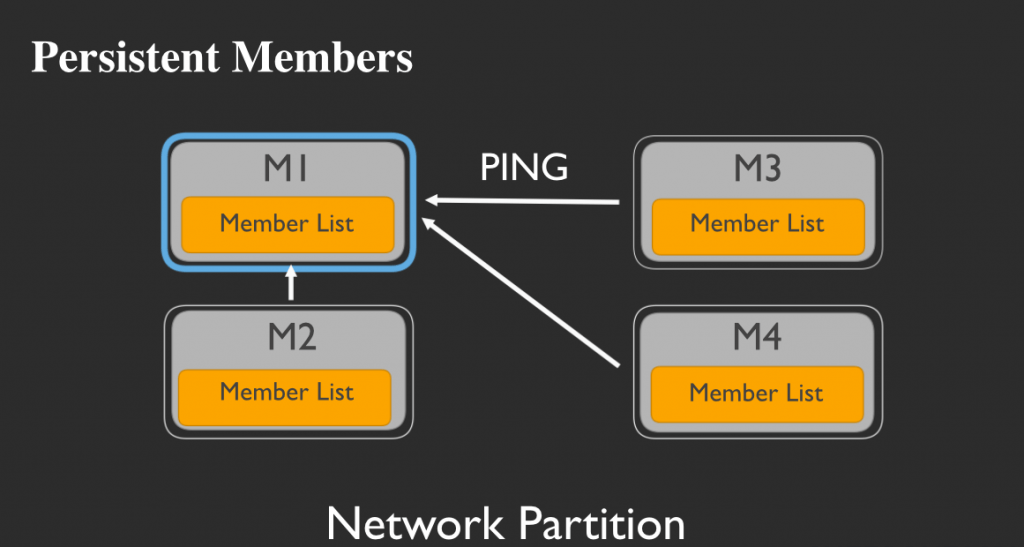
ここで、仮にネットワークが何らかの原因で分断されたと仮定しましょう。

M3とM4にとっては突然、(訳注:永続メンバーである)M1との通信ができなくなってしまった状況です。
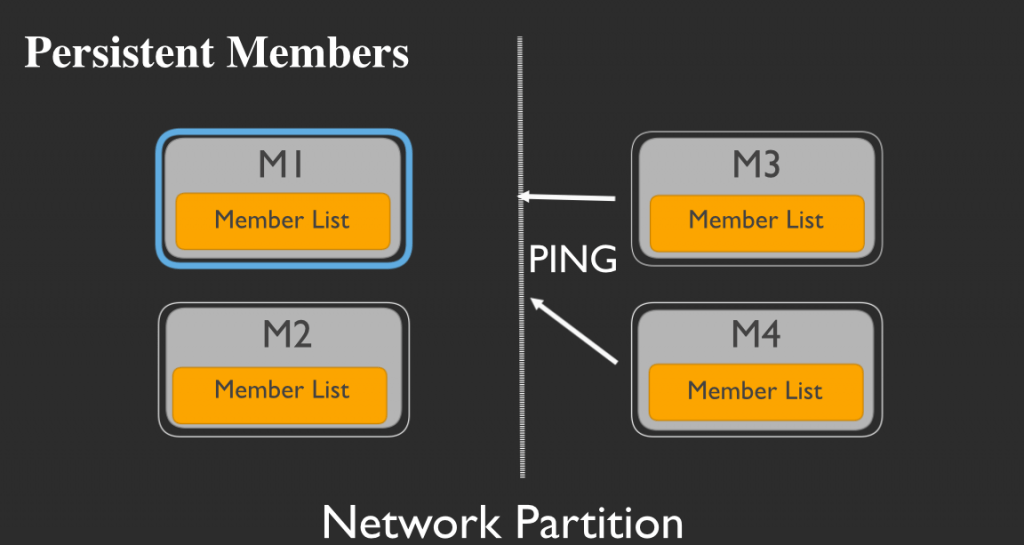
しかし、M3とM4はM1を死んだものとして捜索を取り止めるのではなく、M1を探し続けます。そしてネットワークの分断が解消されたとき:
M3とM4は即座にM1にpingを打つことができるのです。
追放メンバー
Butterflyでは「追放」も可能です。これは人為的にあるメンバーをリングから追い出す操作を可能とするものです。これにより、そのメンバーがリング内に戻ることを防ぎます。スーパーバイザーにふさわしくない動作を確認したときに行う操作です。
どのような経緯で行うか見てみましょう。3つのメンバーから成るスーパーバイザーリングがあるとします:
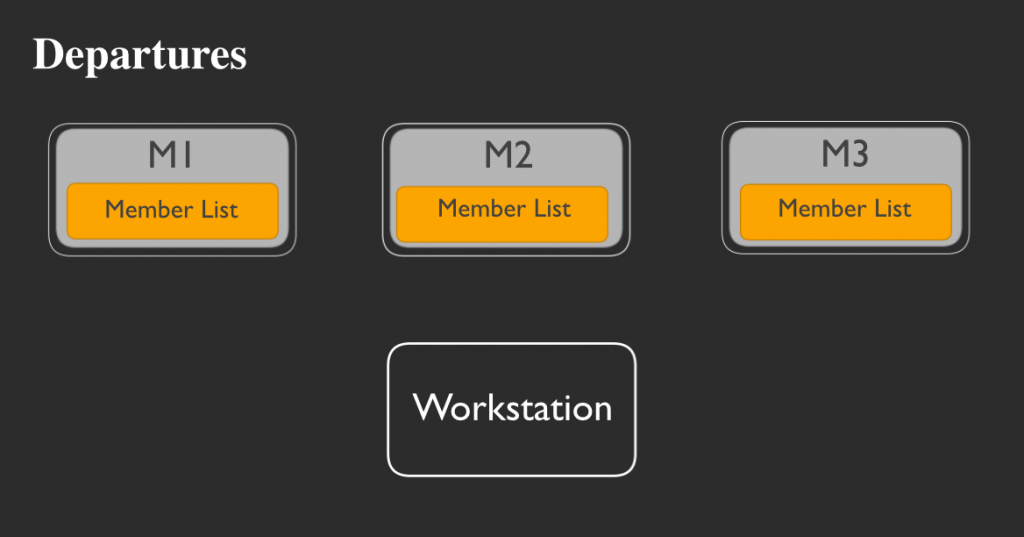
そのうちの1つが不審な動きをし始めました。ヘルスチェックはパスしているのですが、何かがおかしいのです。

ワークステーションから、あるいはSSHでログインしたリングの他のメンバーから、問題のメンバーをリングから追放するHabitatコマンドを発行します。
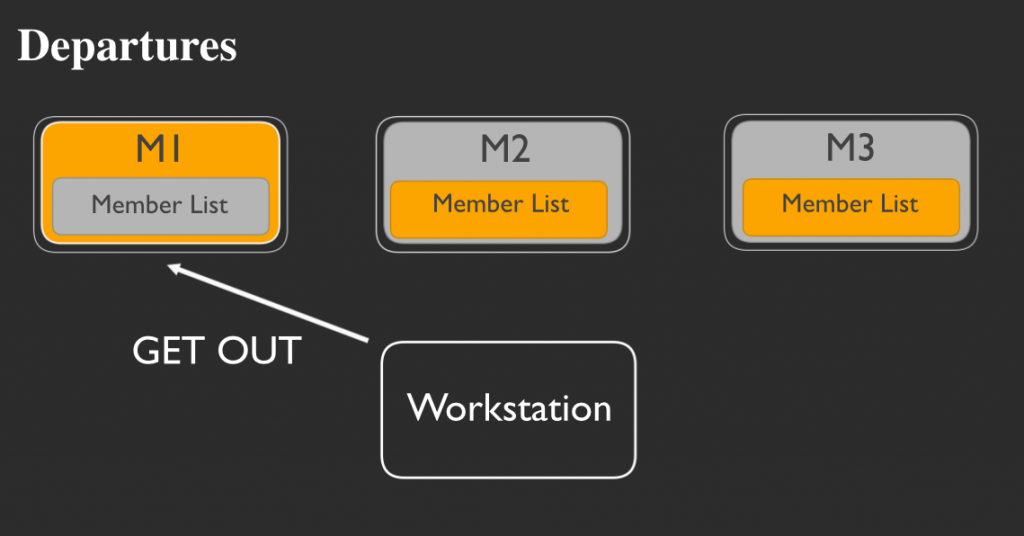
問題のあったメンバーが消えたら、他の生存している各メンバーのリストではそのメンバーを「追放」としてマークします。追放とマークされたメンバーは、その後戻ってきてリングに再度加わろうとしても許可されません。

追放とマークされたメンバーの例は こちら でご覧ください。
まとめ
このブログ記事によって皆さんにご理解いただきたかったことは、Habitatは魔法のように見えても、実際は魔法ではないということです。考え抜かれ、うまく構築された技術なのです。この記事によってHabitatのサービスディスカバリがいかにして機能しているのか、舞台裏をお見せできたなら幸いです。



