
Azure Databricks の紹介 #Microsoft #Azure #DataBricks #spark

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

こんにちは。こちらではご無沙汰しております。木内です。
今日はまだ日本でもあまり知られていない Azure Databricks について簡単にご紹介したいと思います。
Azure Databricks とは?
Microsoft社の公式ページには「迅速、簡単で協調的な Apache Spark ベースの分析プラットフォーム」という説明があります。「はて。Sparkを使いたいのであれば既に HDInsight があるのでは・・・」と思われる方もいると思います。
実際ニュースでも取り上げられているのですが、イマイチ HDInsight との違いがピンとこない方もいたのではないかと思います。
Spark はもともとSQLや機械学習ライブラリなどをビルトインで持っており、一種のソフトウェアスイートになっています。従って Spark に手慣れた人であれば Hadoop ディストリビューションが持っているような Hive や、Mahout といったフレームワークを必要とせず、データサイエンスワークの相当部分を完結させることができます。
また最近ではETL元のデータレイクにAzure Storage Blobのようなオブジェクトストレージを使用する例も多く、Hadoopが自前で用意しているHDFSのようなストレージが不要になるケースもあります。そのような環境ではオブジェクトストレージにアクセスでき、スケールする処理フレームワークを簡単に使用することができれば、Hadoop ディストリビューションが提供する各種フレームワークは却っていろいろ含まれすぎていて、扱いづらいかもしれません。
そもそも
そもそも Azure Databricks はその前身となるサービスがあり、Databricks社(Sparkの開発元のひとつ)が提供していた "Databricks" というサービス(わかりにくい!)がそれになります。必要に応じでAWS上でSparkクラスタを作成して作業をすることができます。Azure Databricks はその Azure 版と言ってよいでしょう。
重要な点ですが、Azure Databricksはまだ日本では提供されていないことを注意してください(2018年4月現在)。今回の記事は東南アジアリージョンを使用して行っています。
Azure Databrick が向いている人
つまり、Azure Databricks が適するのは以下のような人物像になるかと思います。
- データは Storage Blob に入れていて、データマートに Azure Database for MySQL などを使用している
- 日ごろからApache Sparkを使用して業務をしている
- Hadoopの管理がしんどい
- 複数のメンバーで作業していて Notebook の共有などをしたい
では、やってみましょう
Azureポータルから "すべてのサービス" - "Azure Databricks" を選択します
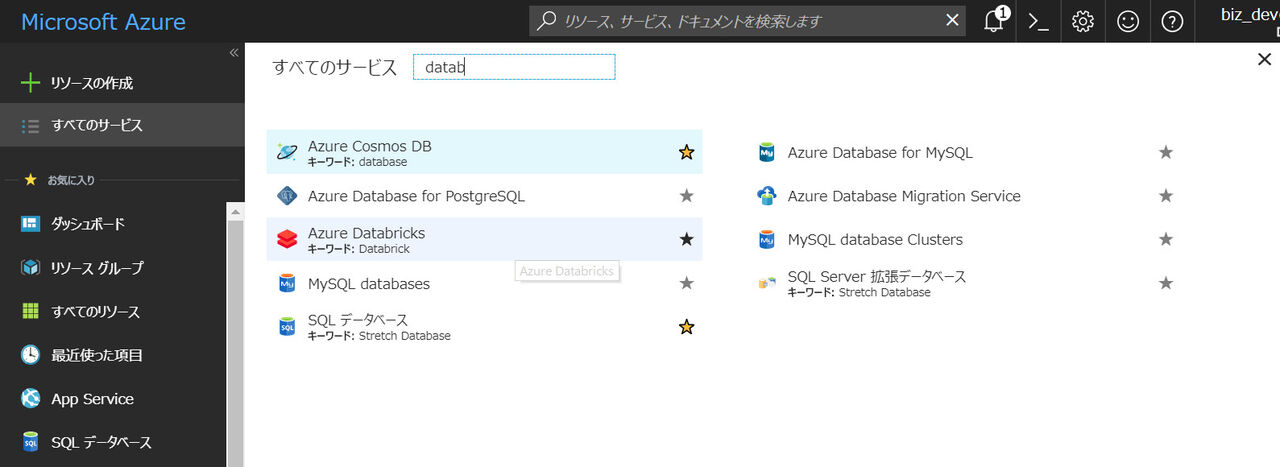
選択直後は何も作成されていないので、 "Azure Databricksの作成" をクリックします。
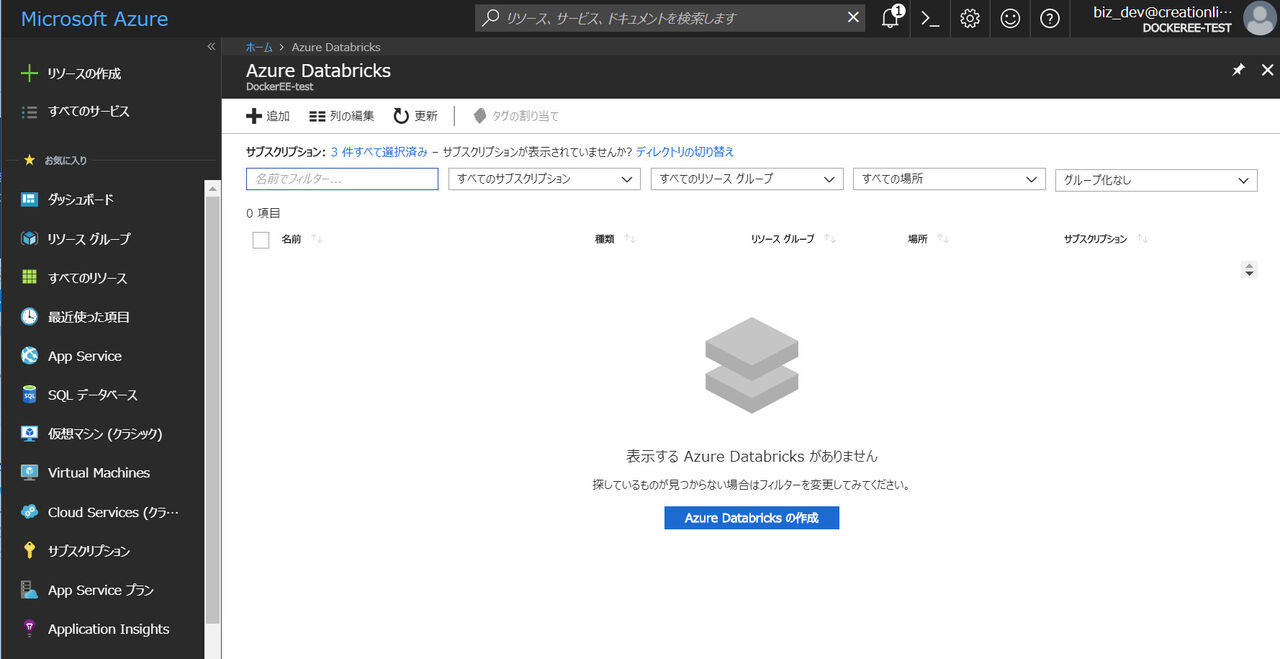
まずワークスペースの作成を行います。今回は Standard レベルのワークスペースを作成します。Premium レベルのワークスペースになると、ODBC/JDBC経由でTableauなどのBIツールと接続してSQLクエリを受け付けられるようになります。
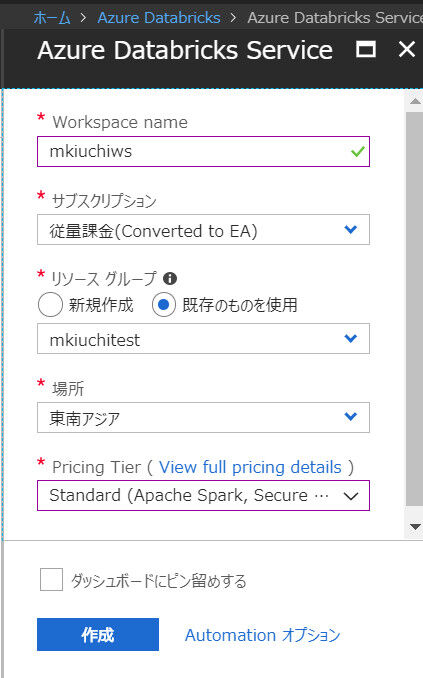
おおよそ3分ほどでワークスペースができました。ワークスペースを作成するだけでは課金は発生しません。実際にSparkクラスタを作成すると課金が発生します。
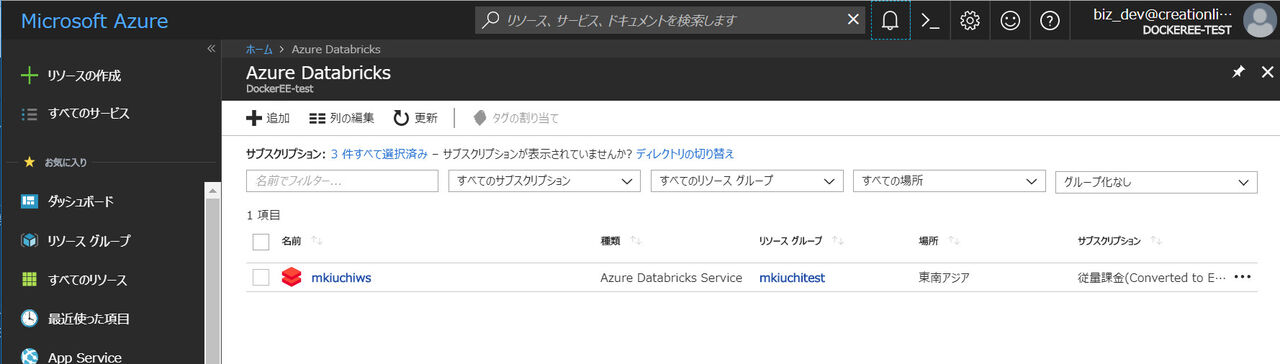
では実際に作成されたワークスペースを開きます。作成したワークスペース名をクリックしてから、 "Launch Workspace" をクリックすると作成されたワークスペースに自動的にリダイレクションされます。
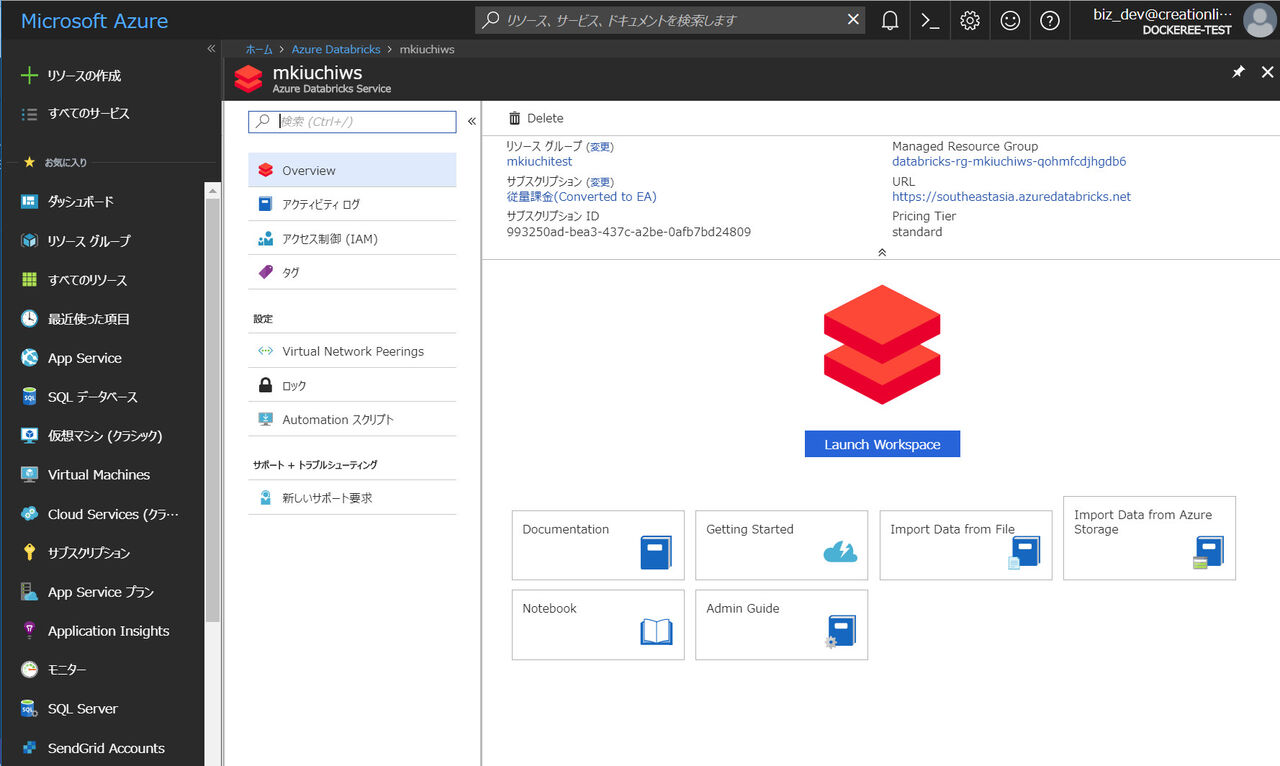

左側のメニューバーから各種機能にアクセスすることができます。いくつかの機能はクラスタを作成しないと有効になりません。
クラスタの作成
では実際に Spark クラスターを作成してみましょう。左側メニューの "Clusters" ボタンをクリックします。
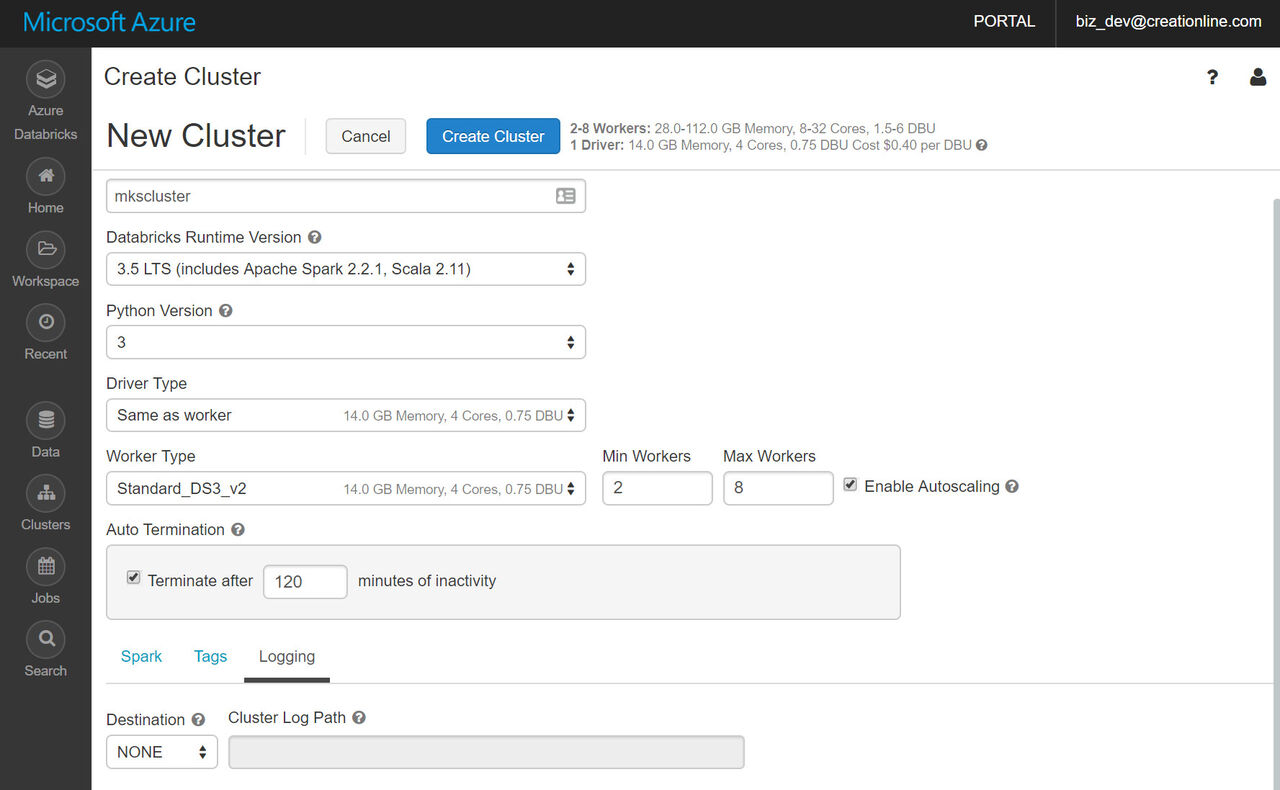
"+Create Cluster" ボタンを押すと、各種設定の入力画面に遷移します。今回は以下のように値をセットしてみました。
| 項目名 | 値 | 備考 |
|---|---|---|
| Cluster Type | Standard | |
| Cluster Name | mkscluster | ここは任意の名前になります |
| Databricks Runtime Version | 3.5 LTS(includes Apache Spark 2.2.1, Scala 2.11) | 2018年4月現在では最新の4.0, Spark 2.3.0 も利用できるようですが、今回はデフォルトの 3.5 LTS, Spark 2.2.1 にしてみました) |
| Python Version | 3 | デフォルトは2ですが、データ分析の世界ではPython3を使用することが一般的ですので3にしました |
| Driver Type | Same as Worker | Spark Driver(詳細はここでは割愛しますが、ジョブを投入する元ホストと思ってください)に割り当てるコア数、メモリ量を指定することができます。Sparkに詳しくない方はデフォルト値を選択しておけば無難でしょう |
| Worker Type | Standard_DS3_v2 | ここは要件に応じて変更します。一般的にはDS3v2が有する14GBのメモリでほとんどのワークロードは効率的に処理することが可能です |
| Min Workers, Max Workers, Enable Autoscaling | Min=2, Max=8, Enable Autoscaling=checked | 処理をオートスケールさせる場合の最小VM数、最大VM数、オートスケールの有効/無効を切り替えます。もしコストが気になるようであれば最大VM数を絞ります |
| Auto Termination | checked(Auto Termination | クラスタの自動破棄)の有効/無効を切り替えます |
| Terminate after | 120 seconds of inactivity | Auto Terminationの閾値に、アイドル秒数を指定します。ジョブの性格によっては時間を長くしてもいいかもしれません。後述しますがクラスタは迅速に起動するため、クラスタを常にライブにしておく必要はあまりありません |
| Spark Config | 空欄 | ジョブ実行時の設定を追加する場合はここに記述します。 |
| Tags | 初期値 | Azureのリソースに割り当てるタグを指定することができます |
| Logging | 初期値 | クラスタのイベントログを保管するストレージを指定することができます |
全てセットしたら "Create Cluster" ボタンを押します。
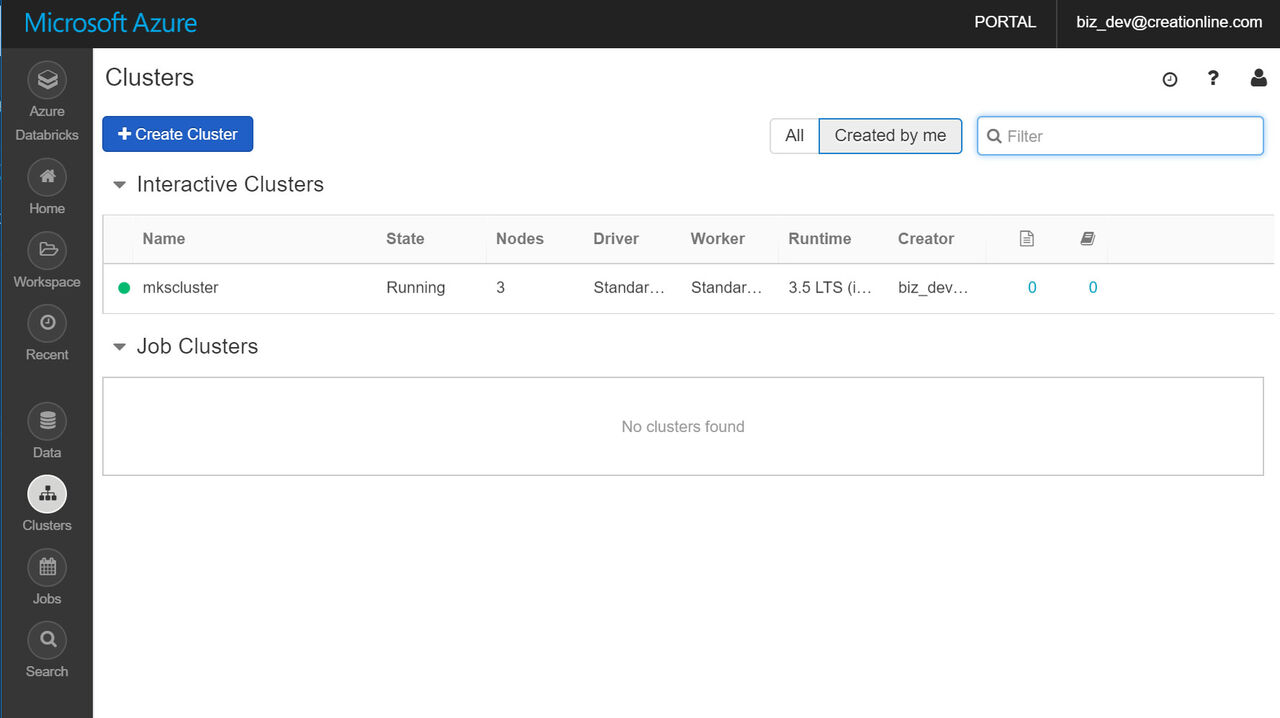
5分程度でクラスタの作成が完了します
1つNotebookを作成してみる
クラスタが作成できると Jupyter Notebook を使用してプログラムを作成できるようになります。1つ作ってみましょう。左側のメニューバーの "Azure Databricks" をクリックしてトップ画面に戻り、左下の "New" - "Notebook" をクリックします。
できました。簡単なものですが少しコマンドを実行してみます。
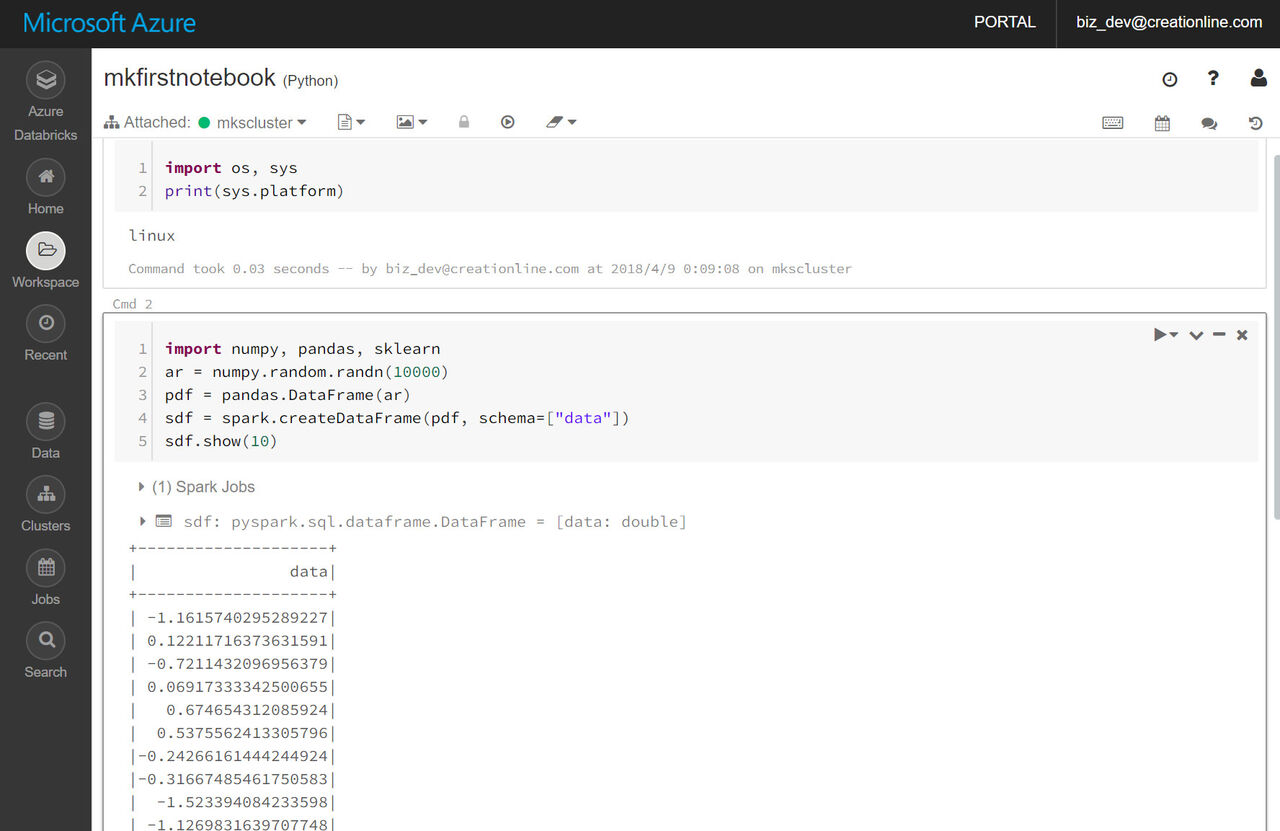
日常的に使いそうなライブラリは既にあるようですね。
価格について
今回はここまでですが、最後に価格について触れておきましょう。Azure Databricksの価格体系はクラスタのVMそのものにかかる費用と、"DBU(Databricks Units)"の費用両方にかかります。詳細は価格に関するページを参照ください。概ねVMそのものの1.5倍ほどの料金になっています。価格を見比べる限り、HDInsightよりも少し高めに設定されているようです。
上記で記述した通り、Azure Databricksクラスタは Auto Termination の機能を持っているため、使用されなくなると自動的に Terminate されます。Azure的な用語でいうと、VMは停止ではなく、削除されます。使用していたストレージアカウントなどは残ります。費用を抑えるために積極的に使っていった方がよいでしょう。
用途としては、ETLのようなバッチ処理に使用するようなユースケースが向いているように思われます。逆にデータサイエンティストチームが共用するような、動かしっぱなしの用途には向かなさそうです。その場合には Data Science VM を使用した方がよいでしょう。
さいごに
簡単に Azure Databricks の内容を見てみました。最後に弊社の独自サービス、千京も Azure Databricks とかなり似た内容ですので、ご興味があればぜひ見てみてください。
Azure Databricksについてもっと知りたい方はぜひフィードバックをお願いします。今後の記事の作成の参考にいたします。
では!



