
AWS Glueを利用してJSONデータの正確性を保証する
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
データ駆動型のビジネス環境において、データの正確性はシステムの信頼性と効率性を左右する重要な要素です。誤ったデータフォーマットや不正確なデータがシステム間で流通すると、エラーやデータの不整合が生じ、結果としてビジネスプロセスに大きな障害をもたらす可能性があります。このような問題を未然に防ぐため、データの形式や構造を定義し、送受信するデータがこれらの定義に適合しているかをシステム間で確認することが極めて重要になります。ここでスキーマレジストリの役割が重要になってきます。
スキーマレジストリは、データのスキーマ(設計図)を一元管理し、データの交換に参加する全てのシステムが正確なデータフォーマットで通信することを保証するための仕組みです。しかし、Amazon MSKなどの一部のサービスでは、直接的なスキーマレジストリ機能を提供していません。そこでAWS Glueのデータカタログ機能が役立ちます。AWS Glueは、複数のフォーマットに対応したスキーマ定義を管理し、データの正確性を確保するための強力なツールを提供します。
この記事では、AWS Glueをスキーマレジストリとして活用する方法を紹介します。AWS Glueのスキーマレジストリ機能を利用することで、Amazon MSKを含むAWS上のサービス間で安全かつ効率的にデータを交換することが可能になります。
概要
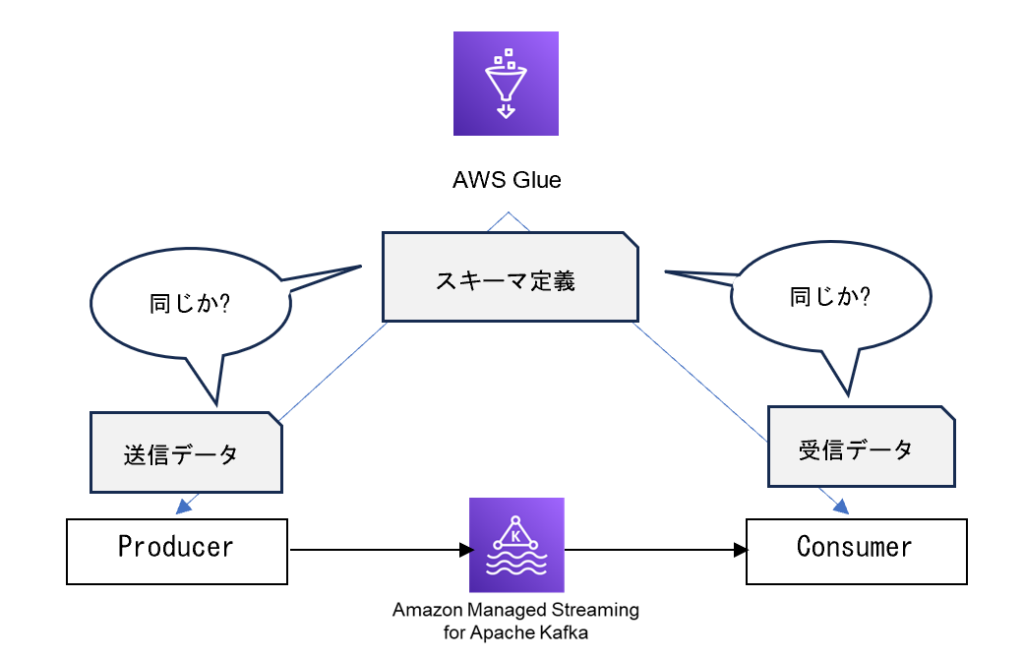
本記事では、Amazon MSKを利用する際に、クライアント(ProducerおよびConsumer)がJSON形式のメッセージに関してスキーマの整合性を確認するシナリオを取り上げます。AWS Glueを活用することで、Avro、JSONといった複数のデータスキーマ形式をサポートし、これによりProducerとConsumerが交換するデータが予め定義されたスキーマに準拠しているかを効果的に検証することが可能となります。このプロセスを通じて、データの品質とシステム間の互換性を確保し、信頼性の高いデータ通信を実現します。
イベントデータ
本記事で取り扱うイベントデータは、次のJSON形式で構成されています。このデータは、あるオンライン書店からの注文情報を表すもので、注文ID、書籍名、注文時刻、価格などの情報を含んでいます。以下のサンプルは、イベントデータの具体的な例を示しており、AWS Glueのスキーマレジストリ機能を用いてこの形式のデータの整合性を検証する方法について説明します。
{
orderId: "uuid",
bookName: "Sample Book",
time: "2011-12-23 13:41:00+09:00",
price: 356
}スキーマフォーマットの種類
AWS Glueのデータカタログでは、データ構造を定義するための3つの主要なフォーマット(Avro, JSON, Protobuf)がサポートされています。これらのフォーマットは、データの設計図を明確に定義するために利用されます。各フォーマットは特有の特徴と利点を持ち、データのシリアライゼーションやデシリアライゼーションにおいて異なるシナリオで適用されます。
- Apache Avro:
- Apache Avroはデータシリアライゼーションフレームワークで、データのシリアライズ(直列化)およびデシリアライズ(逆直列化)を行うためのオープンソースのデータ形式です。スキーマベースのデータ形式で、データの構造をスキーマで定義し、データのバージョン管理や進化をサポートします。AvroはJSONよりもコンパクトで、高速なシリアライゼーションが可能で、多言語間でのデータ交換に適しています。
- JSON (JavaScript Object Notation):
- テキストベースで、キーと値のペアからなるデータオブジェクトを表現します。ウェブアプリケーションやAPIでよく使用され、多くのプログラミング言語でパース(解析)および生成がサポートされています。JSONは階層構造を持つことができ、配列やオブジェクトをネストすることができます。
- Protocol Buffers (Protobuf):
- Protocol BuffersはGoogleによって開発されたバイナリデータシリアライゼーションフォーマットです。バイナリデータ形式なので、JSONやXMLよりもコンパクトで高速なシリアライゼーションが可能です。スキーマベースのデータフォーマットで、データ構造を.protoファイルで定義します。スキーマの進化もサポートされています。Protocol Buffersは主にプログラミング言語間でのデータ通信や永続化に使用され、言語に依存しないデータ交換を実現します。
- Protobufは、主にデータの効率的なシリアライゼーションとアプリケーション間のデータ交換のために設計されており、スキーマ自体の「評価」という概念は直接サポートしていません。
今回の記事は、スキーマの評価を中心としているために、Protobufの利用方法などに関する説明は省いて頂きます。
スキーマの定義
Avro形式
前項のイベントデータのスキーマは、次のように定義できます。
{
"type": "record",
"name": "BookOrder",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "bookName", "type": "string"},
{"name": "time", "type": "string"},
{"name": "price", "type": "int"}
]
}[参照:https://avro.apache.org/docs/1.11.1/specification/]
JSON形式
前項のイベントデータのスキーマは、次のように定義できます。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"orderId": {
"type": "string",
"pattern": "^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$"
},
"bookName": {
"type": "string",
"minLength": 1
},
"time": {
"type": "string",
"format": "date-time"
},
"price": {
"type": "integer",
"minimum": 0
}
},
"required": ["orderId", "bookName", "time", "price"]
}[参照:https://python-jsonschema.readthedocs.io/en/stable/]
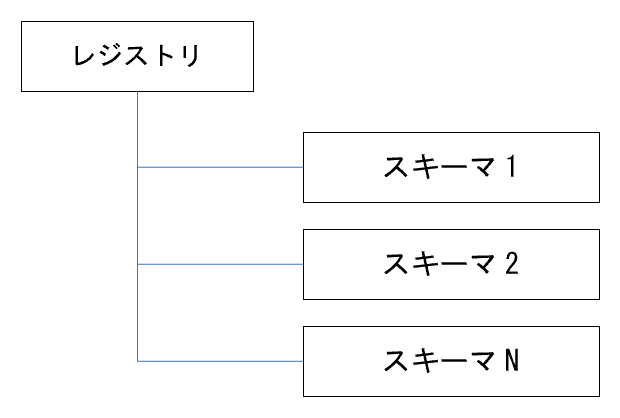
レジストリとスキーマ
前項のスキーマをGlueのデータカタログに登録します。
AWS GlueのDataCatalog→Stream schema registriesからレジストリを登録してから、レジストリの配下にスキーマを登録します。
まず、レジストリは登録してください。レジストリは、スキーマを登録・管理するためのネームスペースの役割を果たします。
それから、レジストリの配下にスキーマを登録します。
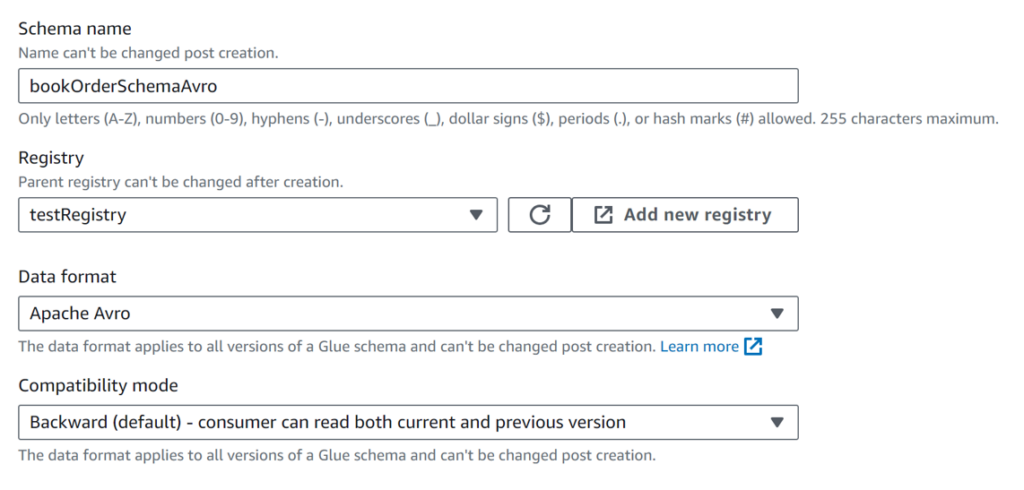
First schema versionにスキーム定義を張り付けてスキーマを作成します。
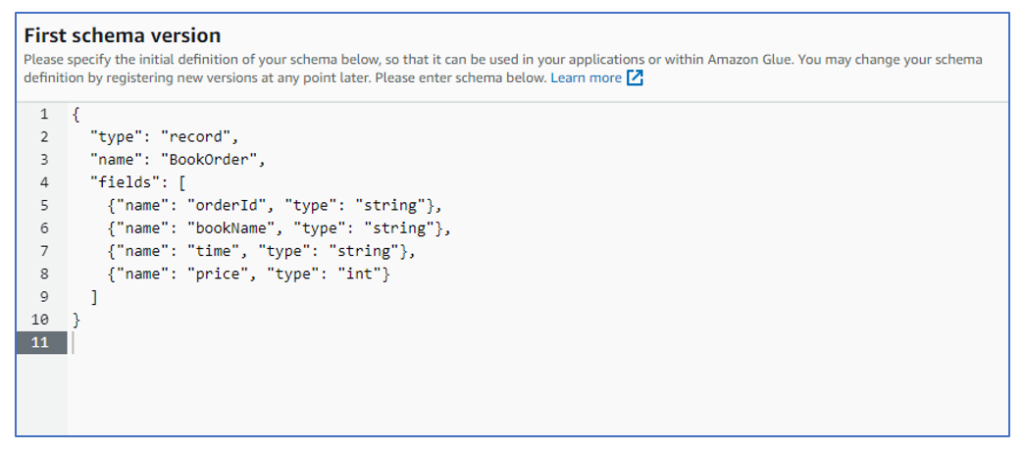
続けてJSONのスキーマを登録してください。
評価プログラムと検証:Avro
Avro形式のスキーマを用いて評価を実行してみましょう。
ここでは、Pythonを使っています。
$ pip install fastavro
$ pip install boto3次のプログラムでは、AWS glueからスキーマを取得し、評価対象のJSONデータと形式が一致するかどうかを評価しています。
validaterAvro.py
import json
import boto3
from fastavro import parse_schema, validate
# 以下はjson_dataの定義です。適切な値に置き換えてください。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "",
"time": "2023-12-23 13:41:00+09:00",
"price": 356
}
# AWS Glueからスキーマを取得する情報
registryName = "testRegistry"
schemaName = "bookOrderSchemaAvro"
schemaVersion = 1
# AWS Glueクライアントを作成
glue_client = boto3.client('glue')
# スキーマのバージョンを取得
response = glue_client.get_schema_version(
SchemaId={'RegistryName': registryName,'SchemaName': schemaName},
SchemaVersionNumber={'VersionNumber': schemaVersion}
)
avro_schema = json.loads(response['SchemaDefinition'])
parsed_schema = parse_schema(avro_schema)
#print(f"`parsed_schema: {parsed_schema}")
# スキーマ検証
try:
validate( json_data, parsed_schema, strict=True)
print("Valid message:", json_data)
except Exception as e:
print(f"Error in validation: {e}")
プログラムを実行してみます。次のように正常であることを示しています。
$ python validaterAvro.py
Valid message: {'orderId': 'a9f31e45-89b0-4bb1-987c-f5795a701380', 'bookName': 'Sample Book', 'time': '2023-12-23 13:41:00+09:00', 'price': 356}[参照:https://fastavro.readthedocs.io/en/latest/validation.html#fastavro._validation_py.validate]
続けて気になるケースを検証してみます。
ケース1:データタイプの違い
価格(price)を文字列にしてみてください。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"price": "356"
}
次のようにBookOrder.priceは、intが期待されているがstrであるとという結果を返しています。$ python validaterAvro.py
Error in validation: [
"BookOrder.price is <356> of type <class 'str'> expected int"
]ケース2:フィルド名の違い
価格のフィルド名を変更してみてください(price→pirces)。
Json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"prices": 356
}次のようにBookOrder.priceは、整数が期待されているが、存在しないという結果を返しています。
$ python validaterAvro.py
Error in validation: [
"Field(BookOrder.price) is None expected int"
]ケース3:フィルドの欠落
priceフィルドが欠けている状態を想定してみます。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00"
}次のようにBookOrder.priceは、整数が期待されているが、存在しないという結果を返しています。
$ python validaterAvro.py
Error in validation: [
"Field(BookOrder.price) is None expected int"
]ケース4:スキーマ定義には存在しないフィルド
スキーマ定義に存在しないフィルドを追加してみます。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"price": 356,
"phone": "090-9999-9999",
}このケースでは、有効という結果になりました。よく考えてみると、データ処理に直接的な影響はないはずですね。
$ python validaterAvro.py
Valid message: {'orderId': 'a9f31e45-89b0-4bb1-987c-f5795a701380', 'bookName': 'Sample Book', 'time': '2023-12-23 13:41:00+09:00', 'price': 356, 'phone': '090-9999-9999'}ケース5:空文字(””)
特定のフィルドに空文字が入って来たと想定してみます。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "",
"time": "2023-12-23 13:41:00+09:00",
"price": 356
}$ python validaterAvro.py
Valid message: {'orderId': 'a9f31e45-89b0-4bb1-987c-f5795a701380', 'bookName': '', 'time': '2023-12-23 13:41:00+09:00', 'price': 356}ありそうなケースですが、Avro形式では問題ないと見なされました。調べてみましたが、AvroやProtobufでは空の文字列("")を特定のケースとして検出する機能が存在しないようです(もし、存在したら、コメントお願い致します)。
評価プログラムと検証:JSON
ここからは、JSON形式のスキーマを用いて評価を実行してみます。
jsonschemaパッケージをインストールしてください。
$ pip install jsonschema次のプログラムでは、AWS glueからスキーマを取得し、評価対象のJSONデータと形式が一致するかどうかを評価しています。
validaterJson.py
import boto3
import json
import jsonschema
from jsonschema import validate
# AWS Glueクライアントを作成
glue_client = boto3.client('glue')
# スキーマレジストリとスキーマ名
registry_name = "testRegistry"
schema_name = "bookOrderSchemaJson"
schema_version = 1
# スキーマバージョンの取得
response = glue_client.get_schema_version(
SchemaId={'RegistryName': registry_name, 'SchemaName': schema_name},
SchemaVersionNumber={'VersionNumber': schema_version}
)
# スキーマ定義の取得
schema_definition = json.loads(response['SchemaDefinition'])
# JSONスキーマの例
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"price": 365
}
#print(f"schema_definition: ${schema_definition}")
# スキーマ検証
try:
validate(instance=json_data, schema=schema_definition)
print("Valid message:", json_data)
except jsonschema.exceptions.ValidationError as e:
print(f"Error in validation: {e.message}")
プログラムを実行してみます。次のように正常であることを示しています。
$ python validater.py
Valid message: {'orderId': 'a9f31e45-89b0-4bb1-987c-f5795a701380', 'bookName': 'Sample Book', 'time': '2023-12-23 13:41:00+09:00', 'price': 365}[参照:https://python-jsonschema.readthedocs.io/en/latest/validate/]
続けて気になるケースを検証してみます。
ケース1:データタイプの違い
価格(price)を文字列にしてみてください。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"price": "356"
}次のように356がintegerではないという結果を返しています。
$ python validaterJson.py
Error in validation: '365' is not of type 'integer'ケース2:フィルド名の違い
価格のフィルド名を変更してみてください(price→pirces)。
Json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"prices": 356
}次のようにprice属性が求められるという結果を返しています。
$ python validaterJson.py
Error in validation: 'price' is a required propertyケース3:フィルドの欠落
priceフィルドが欠けている状態を想定してみます。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00"
}次のようにprice属性が求められるという結果を返しています。
$ python validaterJson.py
Error in validation: 'price' is a required propertyケース4:スキーマ定義には存在しないフィルド
スキーマ定義に存在しないフィルドを追加してみます。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "Sample Book",
"time": "2023-12-23 13:41:00+09:00",
"price": 356,
"phone": "090-9999-9999",
}このケースでは、有効という結果になりました。Avro形式と同じですね。
$ python validaterJson.py
Valid message: {'orderId': 'a9f31e45-89b0-4bb1-987c-f5795a701380', 'bookName': 'Sample Book', 'time': '2023-12-23 13:41:00+09:00', 'price': 356, 'phone': '090-9999-9999'}ケース5:空文字(””)
では、空文字("")が存在する場合はどうでしょうか。
json_data = {
"orderId": "a9f31e45-89b0-4bb1-987c-f5795a701380",
"bookName": "",
"time": "2023-12-23 13:41:00+09:00",
"price": 356
}空文字は駄目だという結果を返しています。Avro形式では、正常だと判定していました。ここが違いますね。
python validaterJson.py
Error in validation: '' should be non-emptyスキーマ評価のポイント
スキーマ評価に関しては、主に次の3つのアプローチが考えられます。
- 送信側(Producer)と受信側(Consumer)の両方で評価する。
- 送信側(Producer)のみで評価する。
- 受信側(Consumer)のみで評価する。
一般に、データの正確性をどの段階で評価するかは重要な考慮事項です。特にEvent Driven Architecture (EDA) においては、MSKのトピックを境界として、データを送信する側と受信する側の間で責務が分かれます。この文脈では、送信側がデータの正確性を保証し、受信側がその正確性を検証することが重要です。不正確なデータが流れると、その後の処理に大きな影響を及ぼします。しかし、既存のプラグイン製品を利用する場合、スキーマの評価を実装することが難しい場合もあります。
まとめ
Amazon MSKが直接スキーマレジストリを提供していない中でも、AWS Glueのデータカタログを活用することで、スキーマ管理の要件を満たすことが可能です。使用するスキーマの形式をどれにするかは、プロジェクトのニーズや機能性を総合的に考慮して選択することになります。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



