
GraphRAGとは?
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
GraphRAGという言葉が注目されています。
RAGでは苦手とされる推測にあたる部分を グラフデータで補うという考え方です。RAG と Graph Node Embeddingの組み合わせについては、弊社のテックブログでも、記事があります(LLM&ナレッジグラフ 〜RAGの精度向上にグラフデータベースを活用する〜 )
該当ブログは
- Graph Node Vector
と - Word Vector
を組み合わせて使うというアイディアで、グラフ作成には Neo4j を使用しています。Neo4j には node2vec API や LangChain Neo4j 用意されているので、喰わせる文書が用意されていれば、(比較的)手軽に試すことができます。
LangChain ブログにある記事(Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs)も類似のアイディアです。
これらの Graph Node Vector と Word Vector の組み合わせも、広義の GraphRAG と呼べるのかもしれませんが、Microsoft の論文(From Local to Global: A Graph RAG Approach to Query-Focused Summarization)を読むと、少しニュアンスが違います。
MicrosoftのGraphRAG
https://microsoft.github.io/graphrag
上記URLは、Microsoft が 2024年7月2日にリリースしたという GraphRAGのページです。巷で、最近のGraphRAGというと、こちらが本丸のようです。
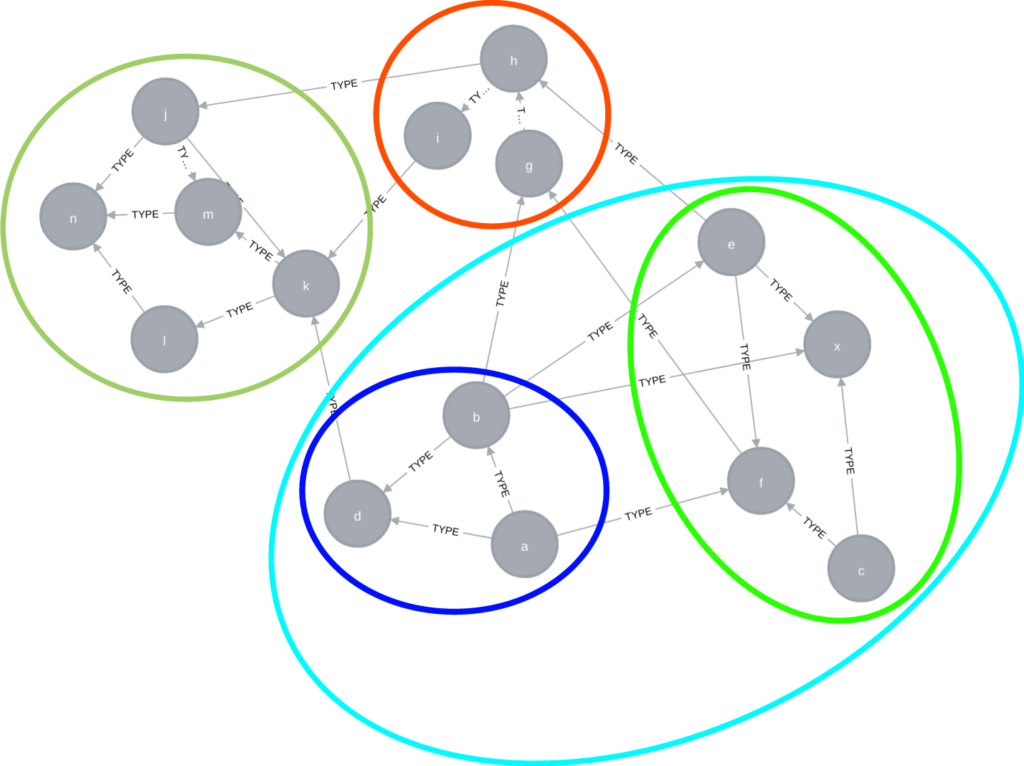
Microsoft が説明に使用している グラフの図がこれです。

グラフデータベースに階層的クラスタリング実施し、communityという塊を抽出する。これらの communityを検索し、文書同士のつながりも検索結果に考慮しようという考えです。communityにはそれぞれsummaryが付与されます。
Microsoft GraphRAGはすぐ動かせる
graphrag.[index|query] コマンド
https://github.com/microsoft/graphrag
GraphRAGの生成については、pythonのCLI が用意されており、CLI がプロジェクトひな形をつくってくれます。文書を喰わせれば、GraphRAGを作成してくれるので、お手軽に試せます。
GraphRAG Solution Accelerator
https://github.com/Azure-Samples/graphrag-accelerator
Azureが使用可能ならば GraphRAG Solution Acceleratorが使用できます。Azureの GraphRAG をデプロイしてくれるセットツールです。
巷には、やってみた系のブログがたくさん公開されているので、日本語での結果など参考にしていただくとよいと思います。ここでは割愛します。
graphrag.indexコマンドが作成してくれたsettings.yml を読む
コマンドで生成されたプロジェクトの中にある settings.yml を読んでみます。
input
input カテゴリをみています。
input: type: file # or blob file_type: text # or csv base_dir: "input" file_encoding: utf-8 file_pattern: ".*\\.txt$"
テキストファイルか csvファイルしか対応していないみたいですね。 file_encoding も指定されているので、入力ファイルは テキストエンコーディングを統一しておく必要があります。
prompt
そういえば、promptチューニングをするようにと説明ページに書いてありました。https://microsoft.github.io/graphrag/posts/prompt_tuning/overview/
$ grep prompt settings.yaml prompt: "prompts/entity_extraction.txt" prompt: "prompts/summarize_descriptions.txt" prompt: "prompts/claim_extraction.txt" prompt: "prompts/community_report.txt"
entity切り出しやcommunity要約生成などのプロンプトテキストが同封されています。
entity extraction
entity_extractionの設定をみてみます。
グラフデータベースのEntityとRelationshipを綺麗に展開するためには、上記プロンプトを変更する必要がありそうです。
settings.yml のentity_extractionのカテゴリをみるとグラフに展開するentityを organization、person、geo、event のみに指定しています。不要なentityはロードしないということですが、ここは用途に併せて、考えるべきところですね。
entity_extraction: ## llm: override the global llm settings for this task ## parallelization: override the global parallelization settings for this task ## async_mode: override the global async_mode settings for this task prompt: "prompts/entity_extraction.txt" entity_types: [organization,person,geo,event] max_gleanings: 1
cluster size
cluster_graph: max_cluster_size: 10
このデフォルト10のclusterとは何を指すのでしょうか。階層的クラスタリングを生成しているときのクラスタリング数のようです。
embedded graph
embedded graph はfalseがデフォルトです。LangChainブログでは、Word Vector と Graph Node Vector を使用しており、Microsoft GraphRAGとは、アプローチが違います。true設定もできるみたいですが、trueにする用途がちょっと不明です。
embed_graph: enabled: false # if true, will generate node2vec embeddings for nodes # num_walks: 10 # walk_length: 40 # window_size: 2 # iterations: 3 # random_seed: 597832
local searchとglobal search
Microsoft GraphRAGには、local searchとglobal searchのふたつの検索モードがあります。
local searchは グラフデータベースの検索、global search は community summary の検索ということです。local search は 詳細な情報を知りたいとき、global search は 関係性を知りたいときというように、漠然とした説明がされています。
deepsetのデモサイト
deepset社が公開してくれているGraphRAGのデモサイトがあります。
- local searchとglobal search結果の比較
local searchとglobal searchの結果が比較できます - graphRAGとRAG結果の比較
RAGで網羅できない質問についてGraphRAGが網羅しているのを確認できます
上記デモサイトについてのブログです。
https://www.deepset.ai/blog/graph-rag
企業の決算報告を読み込ませてあり、RAGが苦手な以下の質問にも答える!と自信ありげです。
"What companies are in the dataset?"
"What are the top 5 themes in the data?"
"Which companies are investing in AI?"
deepsetのデモサイトでいろいろ試してみると、精度の良さに驚きます。個人で大量データを用意するのは難しいので、ありがたく利用させてもらいます。
グラフデータベースの整備
GraphRAG の精度向上は、作成したグラフデータベースのクオリティに左右されます。当たり前のように思うかもしれませんが、いろいろ関数やCLIが用意されていて、一発で動かすことが可能で、手軽すぎて、自分も動かしてから気がつきました。
Neo4jでのアプローチ
From Local to Global: A Graph RAG Approach to Query-Focused Summarization をNeo4jで実現したときの検証ブログがあります。
Implementing ‘From Local to Global’ GraphRAG with Neo4j and LangChain: Constructing the Graph
読み進めていくと、graphragコマンドをデフォルト設定のまま使用してしまって、すみません!という気分になります。用途にあったグラフデータベースをきちんと構築しないとGraphRAGとしては、あまり役に立たないということでしょう。
おわりに
GraphRAGについて調査した内容をまとめてみました。しかしながら、非定型な文書情報などから、綺麗なグラフデータベースを作成するのは、一工夫が必要そうです。既に階層的グラフデータベースを持っているなら、GraphRAGも実装しやすそうです。
グラフデータベースとAIの組み合わせについては、これからも新しいアプローチがでてくると思われますので、また、面白い記事があったら紹介していきたいと思います。



