
【CLくんブログ】Tokyo RAG user group Meetup で弊社エンジニアが講演しました!
今回は企業のAI活用で注目される「RAG」についてのMeetupイベントが4月18日に東京で開催されましたので、その様子をお届けします!

RAGとは

ChatGPTの登場以来、大規模言語モデル(LLM)を企業内で活用する事例が増えています。ChatGPTなどのLLMはインターネットなどの公開情報を学習しているため、アイディア出しや企画の壁打ちなどには有効ですが、特定の情報やデータを使って具体的な回答してほしい、といった企業内での利用を想定した場合には、工夫が必要となります。
そこでLLMに固有の情報を与える仕組みとしてRAG (Retrieval-Augmented Generation) が登場します。一例として、社内ポータルにある就業規則やシステム利用手順を外部データとしてLLMと連携することで、社内情報に関する回答をLLMが行うことが出来るようになります。
クリエーションラインでもプロダクトサポートの自社サービスデスク業務での利用を想定したPoCを進めています。各プロダクトごとの技術仕様に関する情報や過去のFAQ内容を元にした回答文案の生成させるものとなります。(今後事例として公開していきます!)
さて、今回のイベント主催者はLlamaIndexのFounding EngineerをされているDoulcet Pierre-Loicさんとなります。少し話はそれますが、昨年アメリカで行われたAIイベントAI4カンファレンスに弊社米国在住の役員と技術チームが参加した際に、多くのAIスタートアップと情報交換しました。その際、Llamaindex社とも縁ができて今回の参加に繋がりました。
Llamaindexとは
2023年に設立されたサンフランシスコに拠点があるAIスタートアップの一つ。RAG技術 の先進的な企業となり、LLMアプリケーションの開発を容易にする包括的な「データフレームワーク」提供。LLMと外部データを繋ぐための、データ取込み/構造化/アクセスのPythonとTypescriptのライブラリを提供。
会場は楽天AIさんのオフィスにて行われました。テレビで見たことのある楽天さんのASAKAI部屋です。赤いカーペットが敷き詰められた大会場で、気のせいか朝会の熱気を感じます。
イベントはPierreさんのRAGについての説明から始まりました。

Meetup イベント内容
Meetupは5つの講演セッションがあり、RAGに関するナレッジが共有されました。
■講演トピック
- 効果的なRAG評価戦略
- MS Azuredでの拡張性のあるRAGアプリの構築
- LlamaindexとNeo4jを利用したRAG精度向上の試み (クリエーションライン発表)
- 社内RAGツール導入の試行錯誤
- Llamaindexを利用した高度なRAG戦略
「みなさん、どのクラウドベンダーを利用してRAGを構築していますか?」など発表者から参加者への問いかけもあり、インタラクティブで活発に情報交換がされたイベントとなりました。
(ちなみに会場の様子では、若干MS Azure Open AIが多く手が上がった印象ですがAWS/GCPも在り ※真ん中の席から見えた範囲です)

RAGパイプラインの評価プロセス
今回のブログでは各講演の内容をお伝え出来ず残念なのですが、各講演の中で触れられていて印象的だった内容をご紹介します。
一つ目のセッションと各RAG構築事例で評価(Evaluation)をRAGパイプラインに組み込む重要性に触れられていたのが印象的でした。 RAGは色々な実装方法やテクニックがありますが、誤った内容をそれらしく回答するLLMのハルシネーション問題など精度の面での課題があります。企業内で実用的な生成APアプリを作るには、開発段階から評価を行い精度を高めていく事が大切というものです。RAGASやLangSmithといった評価フレームワークのメトリックスの説明もありました。
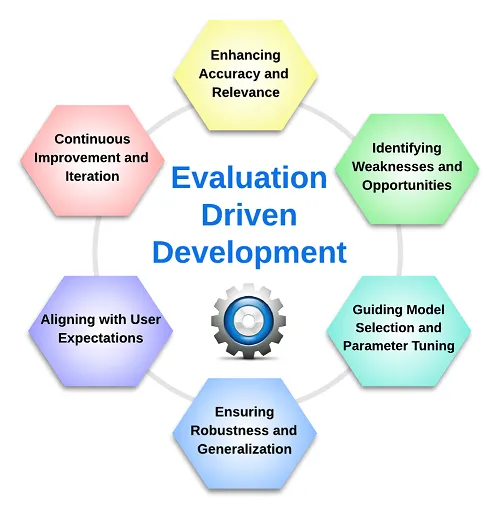
また、「EDD:Evaluation Driven Development」という考え方も講演の中で紹介されていました。講演後に調べた内容になりますが、EDDの紹介記事がありましたので掲載しておきます。
テスト駆動開発(TDD) の考え方と同じようでRAGパイプラインでの評価プロセスを体系的に整理したもののようです。
出典:記事「Evaluation Driven Development, the Swiss Army Knife for RAG Pipelines」
クリエーションラインエンジニアの講演
クリエーションラインからの発表についても紹介します。
弊社データエンジニアの荒井さんにてグラフデータベースをRAGのデータストアとして利用したPoCの内容を発表しました。通常使われるベクターDBとグラフDB、さらにベクターDBとグラフDBのハイブリッドの3つの構成で応答の精度とパフォーマンスを比較した内容となります。

背景にはグラフDBで作るナレッジグラフ(知識データの関係性を持つDB)とLLMの組合せでより実用的なRAGを構築できるのではないか、という想定があります。LLMがもたらす「自然言語、統計、創造性」にナレッジグラフの「知識、事実、文脈」を合わせることでRAGを強化するイメージです。それにより、ハルシネーションの減少、正確性の向上、元データを辿れるという意味での透明性の向上、といった効果が期待されています。
セッション後のPierreさんとの会話でもLlamaIndexでのmemgraphの事例などを共有頂くなど、グラフDBを利用したナレッジグラフと生成AIとの組合せについて意見交換を行いました。
最後に
LlamaIndexのPierreさんや他の講演者の発表を聞いて、グローバルでもRAGの実用化に向けた様々なアプローチが試行錯誤されていることを感じました。
RAG User Groupに入ると講演発表者の内容も紹介されていますので、RAGについての興味のある方は参加を検討してみてはいかがでしょうか。
最後に少し宣伝となりますが、クリエーションラインは2つの分野でAI/LLMに関するサービスを提供しています。AI活用をご検討の方は是非取組みをご紹介させて頂きますのでお声がけ頂ければと思います!
クリエーションライン AI活用支援サービス
・エンタープライズLLM
・AI駆動開発支援
参考情報
ナレッジグラフを利用した生成AIアプリの開発
・Neo4j社 :GenAI, Meet Knowledge Graphs
・Memgraph社 : Knowledge Graphs for Contextual GenAI
LlamaIndex Webサイト https://www.llamaindex.ai/
AI4 カンファレンス https://ai4.io/vegas/ (2024年8月の開催情報が公開されています)
Author
2020年に生まれたCLキャラクター。CL内ではビジネス企画/マーケティングを担当。2024年はCLの取組みや学んだことを中心に発信していきます!アジャイル開発、クラウドネイティブ、AI/機械学習を中心にトレンドを調べたりプロジェクトチームに聞いたりして勉強中!



