
Rabbit r1の発表、Large Action Model (LAM)の登場、そしてLLMとの違いについて

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
CESショーでRabbit社が「r1」と呼ばれる製品を発表し、大きな話題を呼びました。
Rabbit社は、自然言語インターフェースと専用のハードウェアを通じてカスタムオペレーティングシステム(OS)を作成したAI企業です。Rabbitのコア製品はRabbit OSで、自社のプライベートLAMによって運用され、Rabbit r1デバイスがさまざまなテクノロジーインターフェース上で人間の行動を識別し再現し、アプリケーションを通じて自然にナビゲーションを近代化することができます。

手のひらに乗る程度のデバイスで、スクロールとカメラ、そしてマイクを起動するボタンがついてるだけの簡単なデバイスです。
話題を集めたのは、このデバイスが人間の声を聞いて、さまざまなアプリの操作を自動的に行うことができる、という点です。特に画期的なのは、そのアプリに対する操作を一旦学習したら、「応用が効く」という点。学習させたアクションのみならず、人間の音声指示に従って異なる操作もできる様になるAIの機能を備えている、ということです。
人間の音声を認識して求めている情報を収集して音声で回答してくれる機能はLLM(Large Language Model)が提供する機能です。これに対して、受けた命令に基づいて具体的なアクションをとってくれるAI機能を組み合わせることによって上記の機能が実現されます。
この後者のアクションをとってくれるAI機能を、LAM(Large Action Model)と呼びます。
LAMを実際に使った企業がRabbit社が初めてだと思われます。ただ、そのコンセプトについては、HeaP: Hierarchical Policies for Web Actions Using LLMs と呼ばれ、LLMの研究テーマとして論文も出ています。
Large Action Model(LAM)とは何か?
最近は、エージェントというキーワードが話題になってます。エージェントとは、単にクエリ応答を生成するだけでなく、ツールを使用してタスクを完了する能力を持つLLMです。その一例がAutoGPTで、目標をサブタスクに分割し、インターネットや他のツールを使用してこれらをループで完了し、最終目標を達成します。
LAMはエージェントと似てますが、LAMの優れている点は、変化する状況に適応し、複雑なタスクを最初から最後まで次のステップを尋ねることなく完了できる、学習機能を持っている、という事です。
Large Action Models(LAM)とLarge Language Models(LLM)の比較
LAMはLLMと異なり、文字情報では無く、神経記号(Neuro-Symbolic)モデルを使用し、「行動情報」から学習します。人間の意図とインターフェースとの相互作用から学び、それらの行動を模倣します。スマホやPCにおいては、データ入力に加え、スクロール、クリック、メニュー操作などの操作が学習素材です。
LAMとLLMは、タスクを完了する方法がかなり異なるものの、組み合わせると非常にうまく機能します。LLMは、まずユーザーの要求の意味を理解し把握します。その後、LAMがタスクをステップに分け、リアルタイムでそれを実行します。必要に応じてLLM/LAMが交互に機能することもあります。例えばLAMが処理を進める一環で、カスタマーサービスに連絡し、チャットする際、LLMの機能を使用されることが想定されます。
Large Action Models(LAM)の将来
LAMは、AIの比較的新しい開発からの産物です。LAMを使用した自動化において、人間が創造性の高いタスクに集中する一方、繰り返し行う作業をLAMに任せることができる様になります。Rabbit社はCES 2024でrabbit r1を通じて、LAMの能力をプレゼンビデオで示しました。
家庭内でのスマートデバイス管理、オンラインショッピング、さらにはビジネスプロセスの自動化など、さまざまな分野でLAMの活用が期待されています。今後、LAMの技術はさらに進化し、より複雑なタスクや状況に柔軟に対応できるようになると考えられ、AIとの共存のモデルがもう少し具体的なものになっていく様に想定できます。
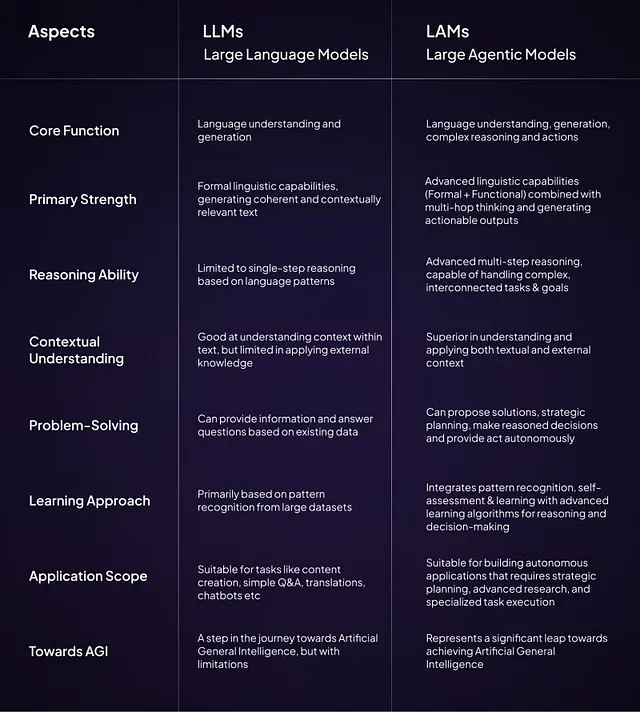
Large Language Models(LLMs)とLarge Agentic Models(LAMs)は、どちらも人工知能モデルのタイプですが、それぞれ異なる目的を持ち、異なる能力を有しています。以下の図は、その核心的な違いを示しています。
※現在、Large Agentic Models が一般的に使われる用語のようですが、今回r1の発表から Rabbit社は Large Action Model (大規模行動モデル)という用語を使用しています。
Rabbit社のRabbitOSの構成要素であるLAMについてもう少し詳しく
OpenAIのモデルに頼る代わりに、Rabbitは自社の基礎モデル、LAM(Large Action Model)を作成しました。「LAMは、コンピュータ上で人間の意図を理解し実行する、新しい基礎モデルです。神経記号システムの研究により、アプリ、API、エージェントが直面する課題に根本的な解決策を見出しました」とRabbit社のCEO、Jesse Lyu氏は述べています。
LAMは、AIシステムが人間と同じ方法でアプリを視覚的に捉え、行動に移すように設計されています。デモンストレーションによって学習し、人間がインターフェースを使用する様子を観察し、インターフェースが変更されてもプロセスを確実に再現します。
LAMは、APIに頼る代わりに、ユーザーが毎日どのようにアプリケーションやサービスを使用しているかを理解します。LAMはインターネット上の消費者向けアプリケーションのほとんどのインターフェースを見ており、それらに対して行われたアクションのデータを供給すればするほど、より能力が高まります。
「LAMは、どのソフトウェアのインターフェースも、それがどのプラットフォームで実行されているかに関わらず学習することができます。要するに、大規模言語モデルはあなたが言うことを理解しますが、大規模行動モデルは仕事を成し遂げます。私たちは、AIを言葉から行動へと進化させるためにLAMを使用します」とLyuは述べています。
LAMがLLMと異なる点は、LAMは言語処理を超え、テキスト指示に基づいて実世界での行動を実行することを目指していることです。指示を受け取り、その言語理解を用いてデジタル環境をナビゲートし、飛行機の予約、食品の注文、スマートホームデバイスの制御などのタスクを完了します。
「ChatGPTのような大規模言語モデルは、AIで自然言語を理解する可能性を示しましたが、私たちの大規模行動モデルはそれを一歩進めます。それは、人間の入力に対してテキストを生成するだけでなく、ユーザーの代わりに行動を生成し、私たちが事を成し遂げるのを助けます」とLyuは言及しました。
LAMはRabbit OSと連携して動作し、セキュアなクラウド上でアプリを操作します。Rabbit Holeは、Rabbit OSおよび付随するデバイスとの関係を管理するために設計された、オールインワンのWEBポータルです。例えば、誰かが音楽を聴きたい場合、Rabbit Hole WEBポータルにアクセスし、Spotifyのようなサードパーティのアプリケーションにログインすることができます。
同様に、Humane AiもCosmosという名前のOSを持っており、これはAi Pinを動かし、今年の3月に出荷される予定です。
Rabbit r1のTeach Modeの分析
Day Optimizer の創設者 Trevor Lohrbeer氏がこの記事において、Rabbit r1のプレゼンビデオを深く分析して、構造的な機能についての類推を行ってます。以下はその記事の参考訳を含みます。
出典: A Deep Dive Into Rabbit AI’s “Teach Mode”
Teach Modeのデモ:Rabbit r1に具体的なアクションをトレーニングする方法
- いずれのデモにおいても、実操作でRabbit r1にトレーニングを実施し、一度覚えたら、同じ操作の繰り返しはもちろん、異なるデータ入力が必要なケースにおいても入力した音声で対応する様になる(Airbnbのデモにおいて、トレーニングはバルセロナ(スペイン)の予約をしてるが、トレーニング後はロンドンの予約を自動的に実施している)
- Rabbit社は、R&Dチームが世界の主要なアプリ(モバイルアプリ、ウェブアプリ、デスクトップアプリ)のトレーニングを独自に行っているとのこと。

Midjourneyを経由してイメージの生成を行うデモ
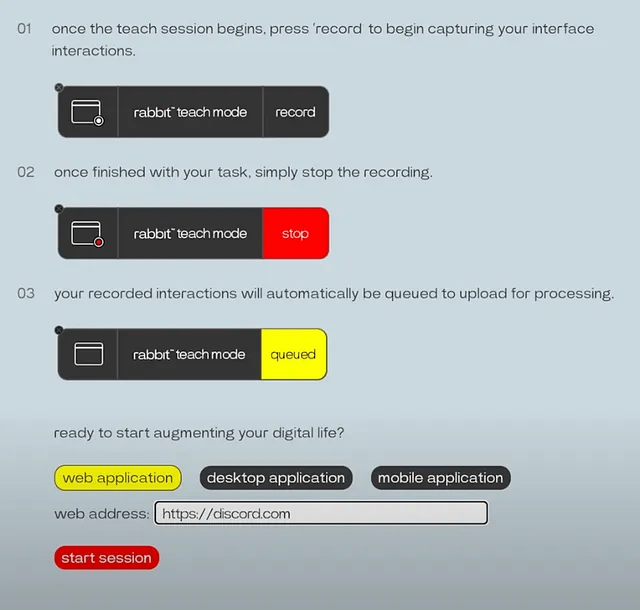
CESでの発表では、実験的な「Teach Mode」を使って、AIがMidjourney経由で画像を生成するように教える様子が見られた。
- Rabbitの「Teach Mode」ページにアクセスします。
- ウェブアプリケーションのURLを入力します。 (https://discord.com)
- 「セッション開始」を押します。
- タスクを達成するために必要なアクションを実行します。 (Midjourneyを介して画像を生成する)
- タスクが終了したら「停止」を押します。
- Rabbitがタスクを一般化できるように、記録されたタスクを注釈付けします。 (デモ中に説明されたが示されていない)
AirBnBを経由して部屋のレンタルを行うデモ
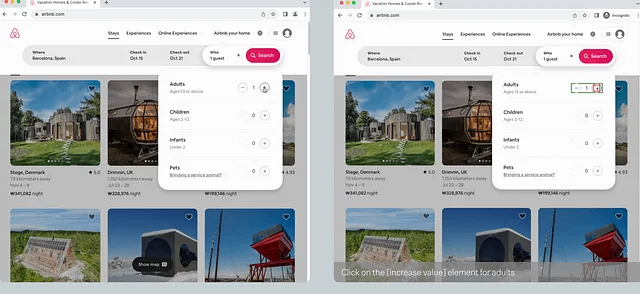
- このデモでは、ユーザーがAirbnbを通じて部屋を予約している様子と並行してLarge Action Model(LAM)が観察して実行している様子により、LAMの舞台裏を見ることが出来ます。
- 映像中には、LAMがユーザーと同じアクションを取りながら、ユーザーがやり取りしていると検出したユーザーインターフェイス(UI)要素をハイライト表示する様子が映し出されています。
- RabbitのLAMは、階層的なUI要素検出を使用しており、個々のHTMLコントロールをより高いレベルの概念的コントロールにグループ化しているように見えます。
- 以下画像には、ユーザーが大人の数を増やすために+アイコンを押すと、LAMが赤でプラスボタン自体を識別するだけでなく、対応するマイナスボタンを含む、より高いレベルの「大人の数」コントロールを緑色でハイライト表示する様子が見られます。
Teach Modeについての分析
HTMLの分析ではなく、アプリ画面の直接的な画像分析を行い、階層的な入力処理手順を生成
- HeaP: Hierarchical Policies for Web Actions Using LLMsと呼ばれる論文を参照していて、個々のそのメカニズムが説明されている
- この手法によって、HTMLベースのウェブアプリのみならず、スマホアプリの画面に対しても同様の分析が可能になっている
- HTMLよりはるかに消費トークン数が少ない、と説明されている。
マルチモーダルLLM
マルチモーダルLLMを採用している可能性は高く、それもTeach Mode時においてユーザー操作も含めたトレーニングを行っているので、(ページ全体ではなく)画像で写ってる部分のみのHTMLを読み込んで処理している可能性があり、それによってかなり処理速度を早めることができると思われる。
複数モデルの採用
LAMは複数のモデルによって構成されている可能が高い。ソフトウェアアプリケーション内でタスクを検出し、それぞれ別々のステップに分けることで、独自のカスタマイズされたモデルを使用して問題を実行していると思われる。
WEB自動化のオープンソフトを使っている可能性
- スクリプトが作成できたら、それを実行することができるOSSはいくつか存在する。例として、Playwright、Puppeteer、Cypressなどがあり、これらはすべて、ブラウザ内での行動を記録して、後で再生可能なスクリプトを生成する機能を提供します。LAMは、これらのWEB自動化ツールのためのスクリプトを生成するために訓練させることができ、Rabbitがクラウドベースの仮想マシンを介してタスク実行をスケールさせることが可能になります。
- このようなツールは、セッション cookies や ローカルストレージデータを保存して認証に必要な情報を保持し、後で同じユーザーとしてスクリプトを実行することができます(もちろんセッションが失効するまでは)。
しかし、Rabbit社のページには次の内容が記載されており少し違う状況の模様
「新しいモデルを支援するために、私たちはデータ収集プラットフォームから、トランスフォーマースタイルのアテンションとグラフベースのメッセージパッシングを組み合わせ、さらにデモンストレーションや例に導かれたプログラム合成器を利用する新しいネットワークアーキテクチャまで、技術スタックを一から設計しました。」
WEBページ操作の際の不足しているパラメーター、変化、エラーの処理
- これについては、Rabbit社はシンボリックアルゴリズムとニューラルネットワークの両方を使用するハイブリッドシステムを作成したと述べてる。
まとめ
以上のような発表内容、動画、関連記事などからまとめてみましたが、Rabbit r1 と Large Action Model の可能性についてお伝え出来てればと思います。 Large Action Model は始まったばかりです。続報の記事についてご期待ください。



