
【RAGがわかる】社内勉強会の内容を特別公開!

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
自然言語処理案件やAIソリューション開発案件をリードしている黒田です。こちらはクリエーションラインアドベントカレンダー 16日目の記事です。
先日社内で実施した勉強会の内容を公開します。テーマはRAG(Retrieval-Augmented Generationの略)です。
勉強会の経緯
今回なぜRAGの話をするかというと、弊社のAIソリューション事業戦略の1つであるエンタープライズLLMと密接に関係があるテーマだからです。
目次

目次です。職種に関係なく全員にわかってもらえる内容を目指しました。今日の目標として、この話を聞いた後に、RAGがわかった気になって、RAGって面白そうだなと思っていただけたら、大成功かなと思います。
RAGとは

RAGの単語の意味はそのまま訳すと検索/増強/生成になるのですが、
要するに大量の情報から必要なものを見つけ出し、それを使って新しい文章を作る技術です。
それも1つの情報源だけじゃなくて複数から検索できる点が特徴です。RAGを使うと企業や組織が持つ大量の情報から必要な知識を効率的に抽出できます。
実はRAGはLLMより歴史が長く、1990年代創業のAsk.comや、2010年代のIBM WatsonもRAGと言えます。2020年代にOpenAIのChatGPTをはじめとしてLLMがたくさん登場したり、LangChain、LlamaIndexなどRAGを構築するのに便利なOSSが登場したことで、LLMを用いたRAGの注目度が一気に高まっています。
従来の検索との違い

RAGは従来の検索である"キーワード検索"とは以下の点で違います。
・検索時に入力するのが単語ではなく自然文(話し言葉)である。曖昧な表現で検索ができる。
・検索で見つかった記事に書かれている文章を自分が使いたい内容に作り直す必要がなく、出てきた回答をほとんどそのまま使えるので時短になる。
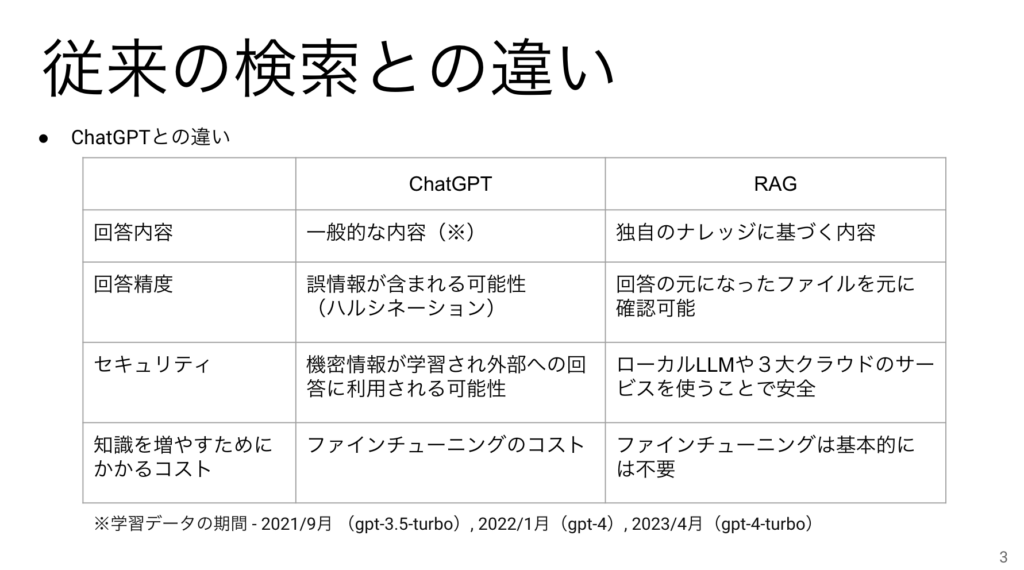
もう一つ違いを説明したいことは、ChatGPTと何が違うの?という話です。
まず、ChatGPTは汎用なLLMを使っているので、一般的な内容で回答をします。RAGには企業の独自のナレッジを元に回答させることができます。
つぎに、回答精度ですが、ChatGPTは誤情報が含まれやすく(ハルシネーション)、それを判断するにはもう一度検索しなおす必要があるのに対し、RAGは回答の元になったファイルを参照できるようにして回答することができるので情報が正しいかどうか判断しやすかったり、わからないことははっきりわからないと言えたりする点が異なります。
その次が、セキュリティです。ChatGPTだと入力した情報が外部に流出して学習などに利用されてしまう場合がありますが、RAGの場合はその心配が要りません。
最後に、ChatGPTに専門知識を与えるためにはファインチューニングをするしかないのでコストがかかりますが、RAGはファイルを増やせば賢くなるのでファインチューニングが必ずしも必要ないという点が魅力です。

RAGの中の検索機能は全体の一部にすぎません。スライドの中の吹き出しにあるように、何についてどんな風に回答して欲しいのかをユーザーが自由に決めることができるのがRAGの本当の魅力です。
RAGによる今後の業務の変化
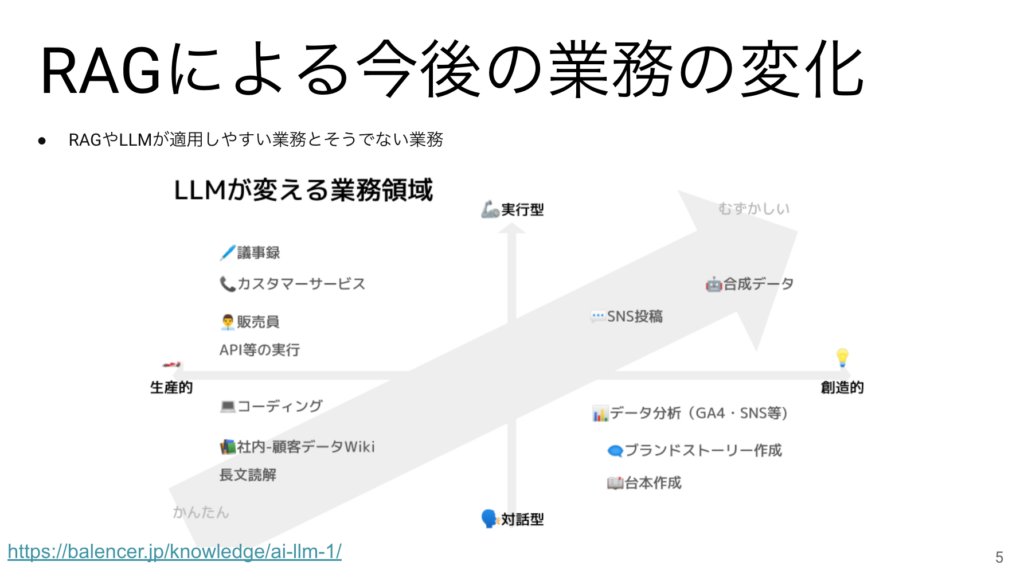
こちらの図はLLMが影響を与えると言われている業務領域なのですが、RAGの場合も同じと考えてよいと思います。一般的には手順や入出力がはっきりしている業務は適用がしやすく、そうでない業務は適用が難しいとされています。
適用できる領域にいると、自分の仕事がAIに奪われると思うかもしれませんが、AIにお任せできるところはお任せして、よりクリエイティブな仕事をする時間をもらえたと思うのが健全です。
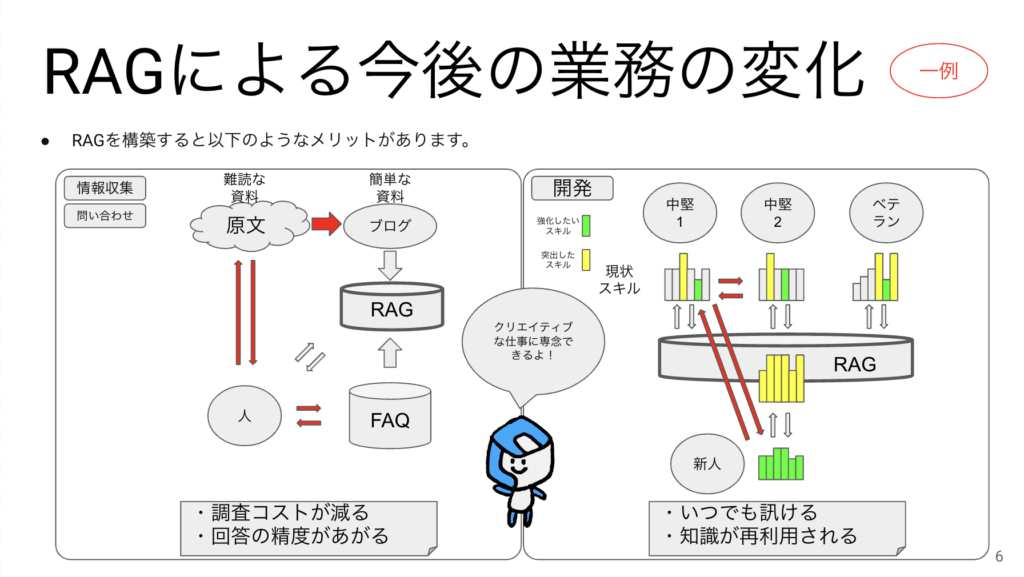
今後自社にRAGを構築して活用すると、どんな風に業務が変化するかを具体例で説明します。
左側は情報収集や問い合わせに関連する業務です。英語の論文や記事など、難読な資料を一人一人が読む必要がなくなって、社内で誰か1人でも資料を読んで簡略化できれば、他の人はRAGに問い合わせができるようになります。FAQもRAGに入れてしまえばお客様からの問い合わせに対して最適な回答を素早く手に入れることができるようになります。
右側は開発現場ですが、社員ごとに保有スキルに差があるような状態で、RAGに各人の突出したスキルの情報を入力しておけば、その人が不在の時間帯でもRAGにノウハウを問い合わせることができます。新人が入ってきた時もわからないことはRAGに質問してもらうようにすれば先輩社員の対応負荷は減ります。RAGに対しては24h365日質問できる状態になるので、新人であっても知識をどんどん増やしていけます。
クリエーションラインとしてこういったRAGを活用していることは対外的にも大きなアピールになるはずです。
RAG基本用語
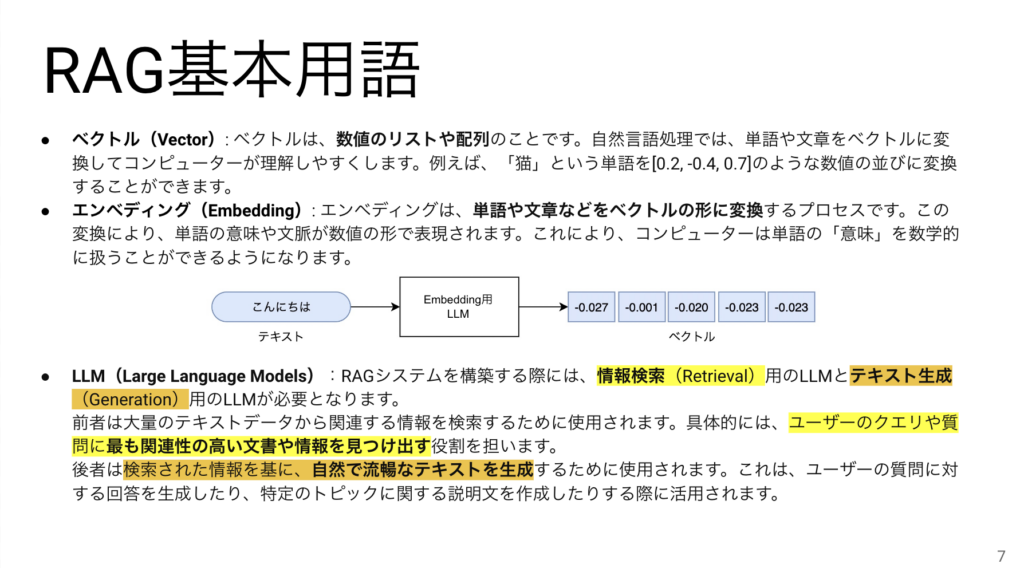
ここからようやく本編の方に入って参ります。用語は3つだけ厳選しました。ベクトルとエンべディングの関係は中央の図がわかりやすく、テキストをEmbedding用のLLMに入力するとベクトルになります。以降のページで説明しますが、RAGにとってLLMは構成要素の1つです。そして、情報検索用途のLLMとテキスト生成用途のLLMがそれぞれ存在することを覚えておいてください。
RAGの仕組み
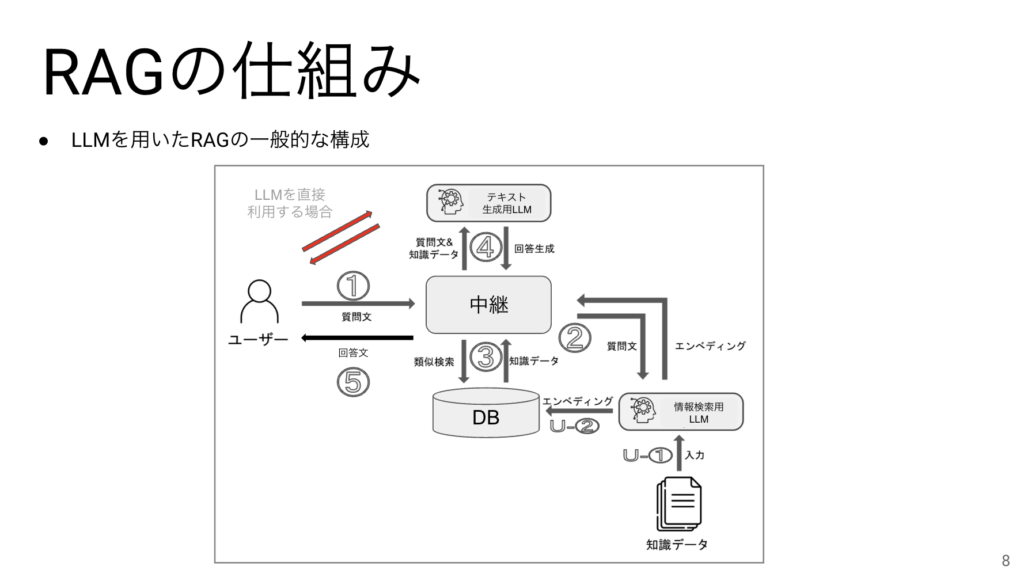
こちらがRAGの仕組みをできるだけ簡潔に書いたものです。
左上の赤い矢印は参考までにテキスト生成用LLMを直接利用する場合の流れを表しています。この場合は、質問文がそのままテキスト生成用LLMに入力されるのですが、RAGの場合は、中継機能が事前に質問文から知識データを探して、その質問文と知識データをテキスト生成用LLMに入力するので、知識データを加味した回答ができるようになるのです。
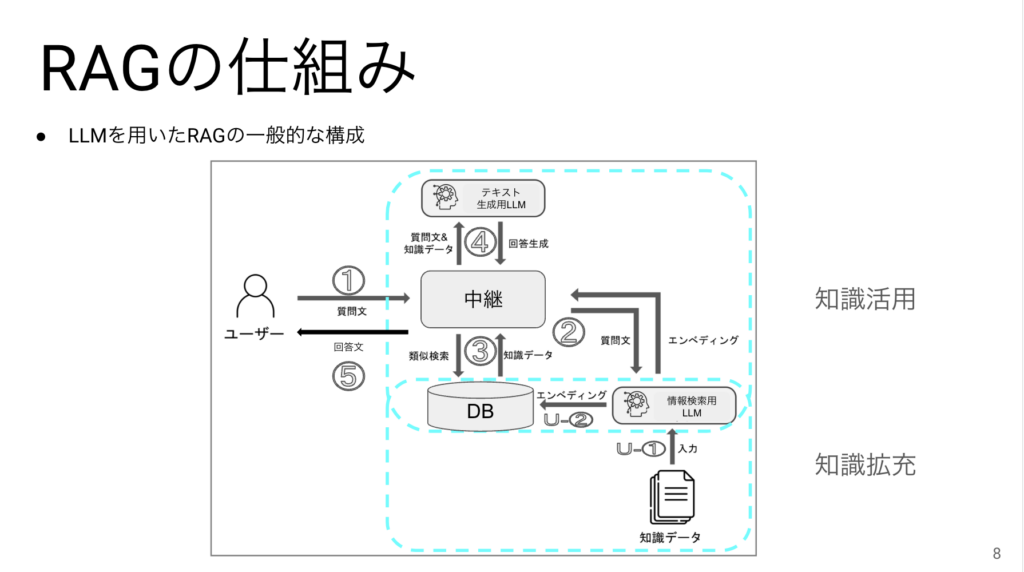
RAGの仕組みは役割的に2つのパートに別れています。1つは知識を活用するための部分、もう1つは知識を拡充するための部分です。
通常は先に知識を拡充してから知識を活用するので、今日もこの順番で説明していきます。
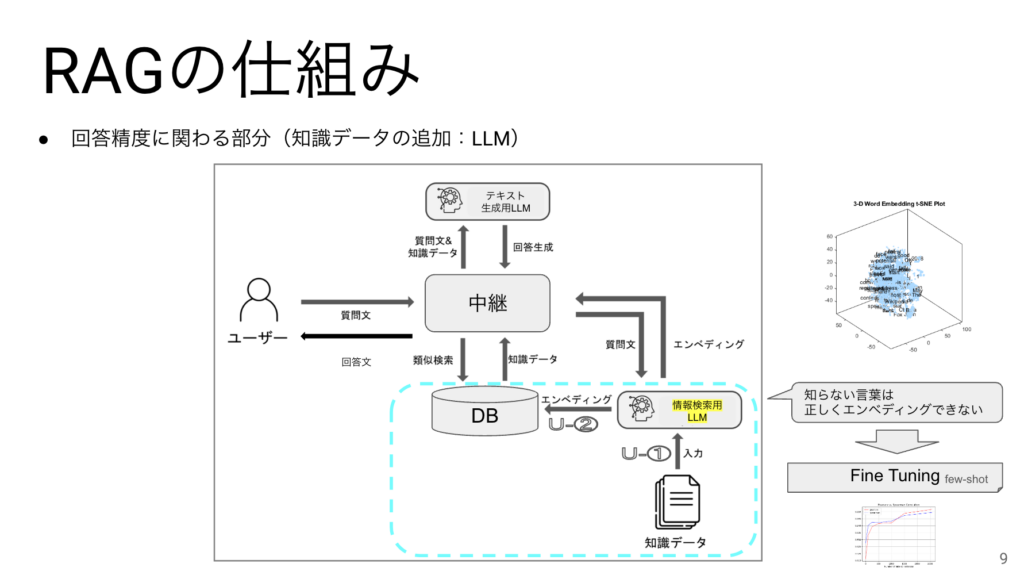
知識の拡充で一番大切なのはエンべディングをするためのLLMになります。このLLMが知らない単語は正しくエンべディングされないことに注意が必要です。
エンべディングされた情報はDBに格納されます。後半でDBの種類を説明しますが、その種類によって性能や精度に差がでることがわかっています。
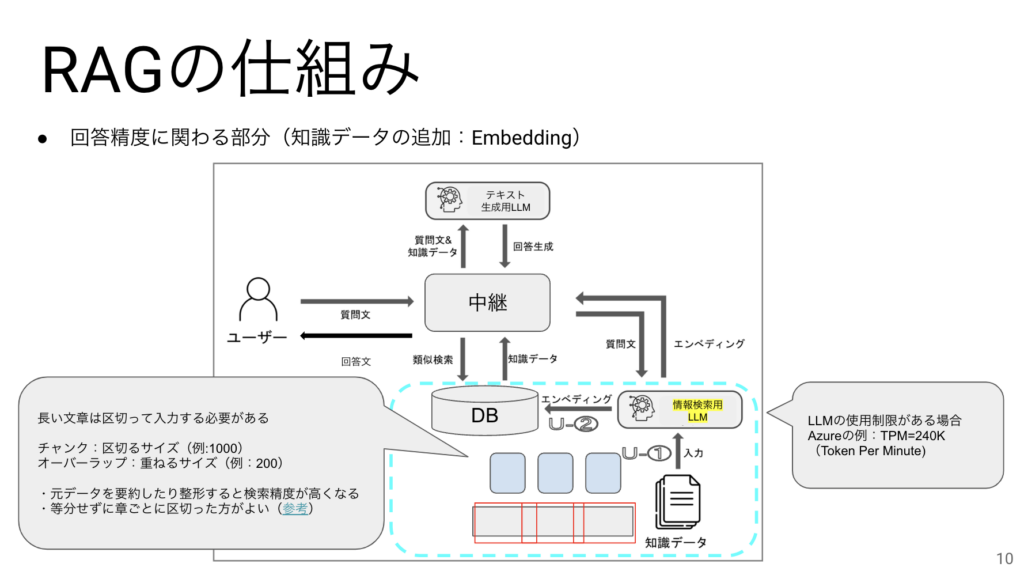
エンべディングの際に気をつけたいポイントが2つあります。まずはLLMの使用制限です。AzureなどではTPMといって1分間に使用できるトークン数に上限があり、それを超えてLLMを使おうとするとエラーが発生するようになります。もう一つは長い文章を分割する際のチャンクサイズなどの設定です。これについては扱うデータによって最適な数値に変えるのがよいでしょう。等分にする理由は、ファイルが大量にある時に個別にチャンクサイズを調整するのが難しいからなのですが、最近では等分はせずに自動的に章ごとに切り出す方が回答精度があがるといわれています。
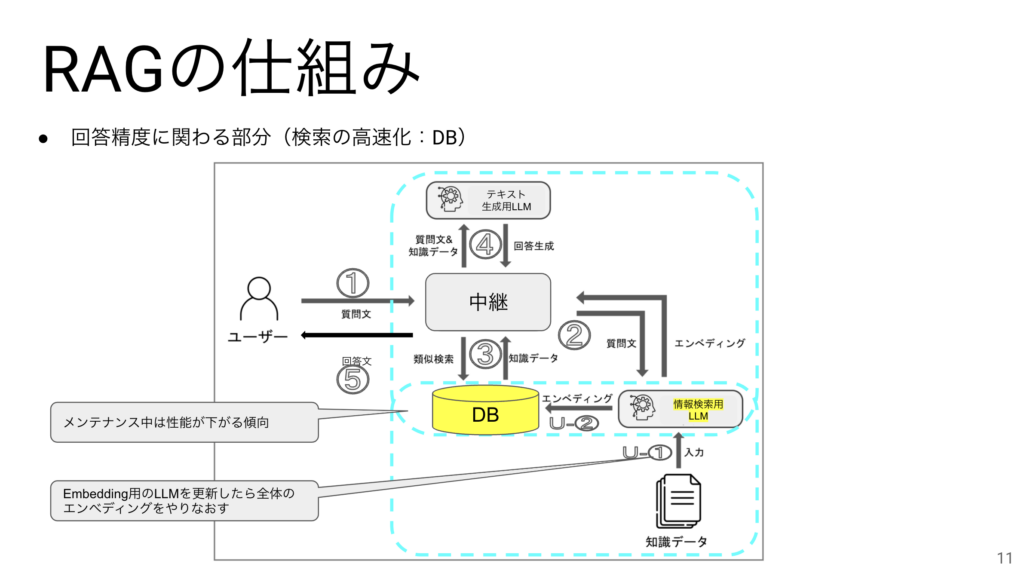
LLMはまだまだ発展途上ですがオープンソースの方が進化が早いと言われています。そしてもし、RAGを構築した後に、Embedding用のLLMを更新したくなった場合は、動作確認の上、RAGに組み込むと同時に、新しいLLMを用いてベクトルを再生成をする必要があります。運用中にインデックスの更新をする場合は、一時的に性能が下がることが懸念されます。この性能低下が少ないDBも登場してきています。
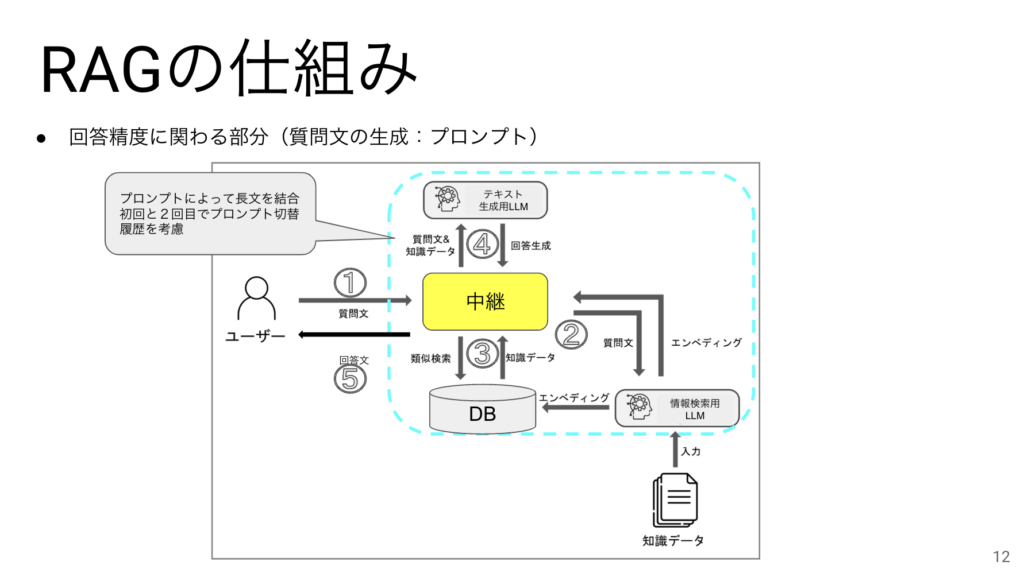
RAGの中継機能があることでLLMとのやりとりの内容を途中で加工することができます。
例えばテキスト生成用LLMに質問文と知識を投げるためにプロンプトを使うのですが、
そのプロンプトで長文を結合したり、初回と2回目以降で異なる回答をさせることにも役立ちます。
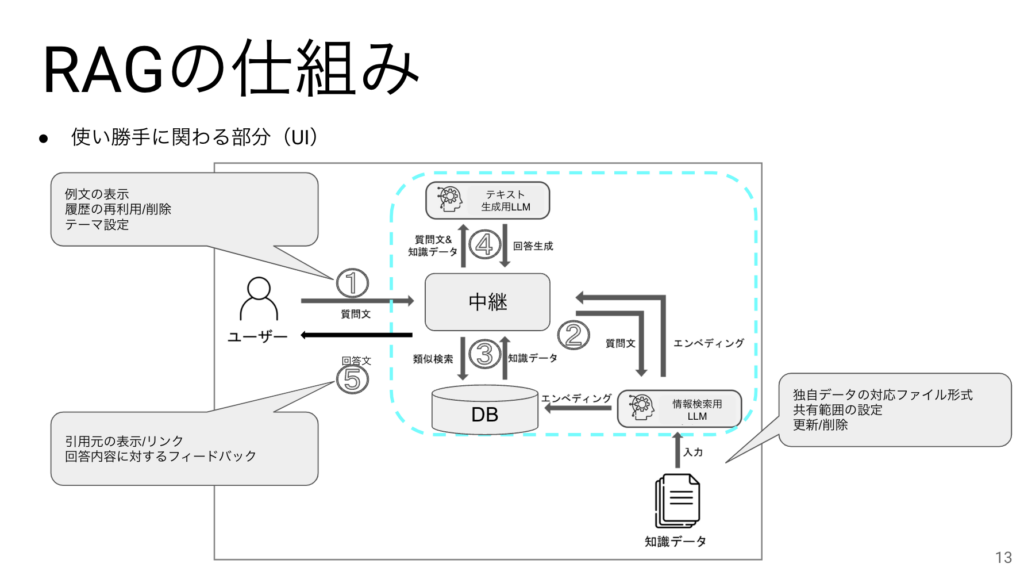
ユーザーに対してはChatに不慣れなユーザー向きに例文を表示したり、過去の履歴を再利用できるようにしたり、壁紙を変更できるようにすればユーザービリティが上がりそうです。回答内容については引用元があった方が判断がしやすいのですが、それでもユーザーが回答に満足したかはフィードバック(Good/Bad)で集計できるようにするのが最近の傾向になります。
LangChain/LlamaIndexについて
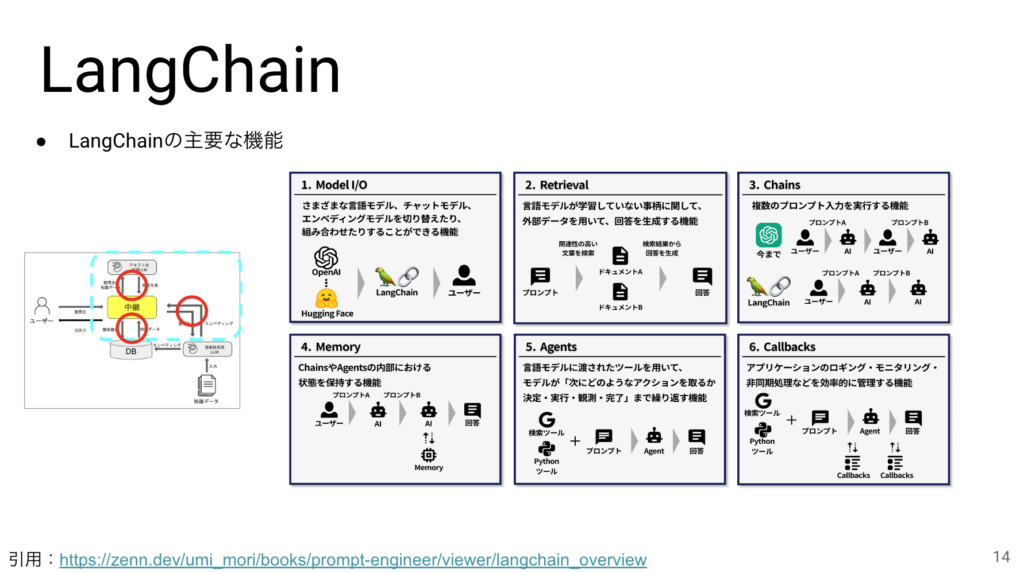
これまでに説明してきた仕組みの中で、中継機能を担うOSSの代表格がLangChainです。このページに載せている機能は中継に必要な機能の代表例になります。
今日は詳細は割愛して概要を説明していきます。Model I/OとRetrievalはRAGそのものです。Chainsは複数のプロンプトを連携させる機能です。Memoryは一連の対話に変数を与えることで会話の状態を保持する機能です。AgentsはLLMの応答内容を使って他のツールを起動することができます。例えばWiki記事や天気を取ってきて会話に使う事ができます。その他、CallbacksといってAIの処理の繋ぎ目を拾って別の処理を実行させてログをとったりモニタリングをする機能が用意されています。
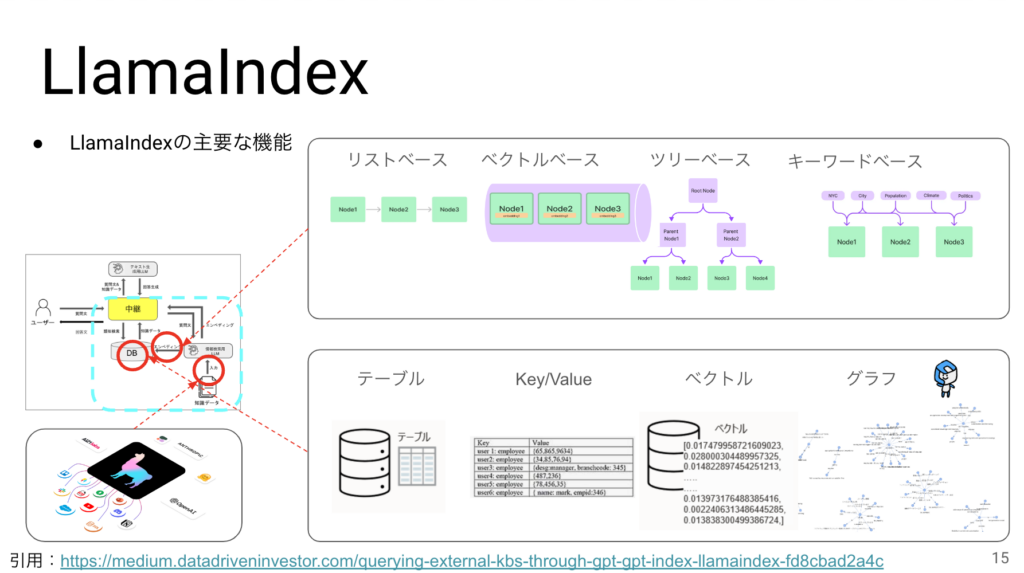
LlamaIndexについては、今日の説明では敢えて知識拡充の肝となるOSSという紹介の仕方をしたいと思います。LangChainのラッパーと言われることが多く、一緒に使うケースもよく見ます。LlamaIndexの特徴は
1:非常に多くの種類のデータソースからデータを取り込むことができる
2:エンべディングの際に様々な種類のインデックスを作成することができる
3:DBもあらゆる形式に対応している。
現在、世の中的にはベクトルDBが主流になっていますが、最近になって弊社が得意なグラフDBがRAGの精度面で有用とされる事例が増えています。
Azure/AWS/GCPのRAG関連サービス
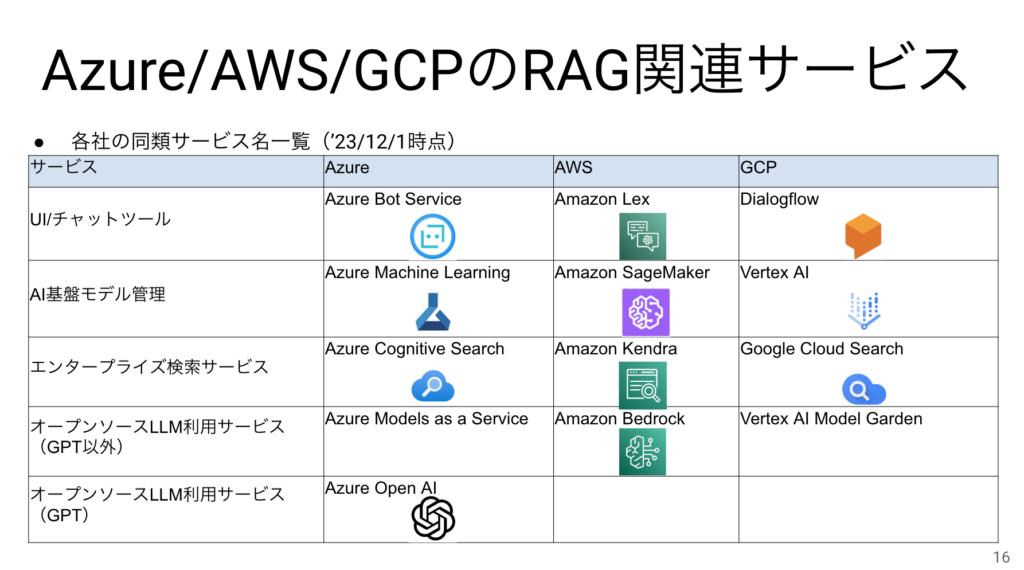
3大クラウドでの中ではAzureが一番早くOpenAIをSaaSにしましたが、現時点では概ねどこも同様のサービスを揃えています。
RAGのメンテナンス

ここまでRAGの仕組みについて説明してきましたが、RAGは一度構築して終わりではなく、メンテナンスが伴います。 主な場面としてコンテンツを整備したり、精度向上をしたり、操作性を向上させたりをし続けることで、いわゆる使えば使うほど賢くなるシステムになります。
まとめ
まとめです。RAGの勉強会ということで、従来の検索との違いや、RAGの仕組みについて学びました。また、RAGを構築する上で中枢となる機能を持つLangChainやLlamaIndexについても概要を学びました。そして、RAGを導入すると業務にどんな影響があるかについても共有ができたので、今日の目標を達成できたのではないかと思います。
以上で発表を終わります。お疲れ様でした。
明日以降のブログにも乞うご期待!
We're Hiring!
クリエーションラインでは、このような勉強会を通して新たな技術を積極的に取り入れ、弊社が目指すビジョン「IT技術によるイノベーションにより顧客とともに社会の進化を実現する」を一緒に進めていく開発メンバーを募集しております。特にAI/ML経験者、自然言語処理経験者は大歓迎です!
ご関心のある方は弊社のお問い合わせページより、是非お気軽にご連絡ください! 一緒に社会を変えたい開発者・エンジニアの皆様の応募を心よりお待ちしております!
Author
自然言語処理案件とLLM活用案件をリード。LLM活用のその先を探求中。情報共有とナレッジ活用に注力。人の強みを引き出し活かせる仕事に存在意義を感じる今日この頃。趣味は旅行や食べ歩き。気に入った風景は360度撮影し、食事は3D撮影してから戴きます。



