
LLM&ナレッジグラフ 〜RAGの精度向上にグラフデータベースを活用する〜
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

こちらはクリエーションラインアドベントカレンダー23日目の記事です。
このブログは、今年の12月にクリエーションラインの社内勉強会で発表させていただいた内容をそのまま掲載するもので、RAGの精度向上にグラフデータベースの使用が効果があることを机上検証によって示した結果をまとめたものです。ご参考にしていただければ幸いです。

まず簡単な自己紹介からさせていただきます。
私は、荒井 創(あらい はじめ)と申します。
クリエーションラインで約1年半Neo4jエンジニアとしてNeo4jのセールス・カスタマーサポート・トレーニング・ウェビナー講師を担当させていただきました。
現在は、大手通信会社のプロジェクトでAI Chatbot、すなわちRAGの開発に従事させていただいております。
今回は、Neo4jエンジニアとしての経験とRAGの開発経験を活かして、
RAGの開発にNeo4jを活用できないかという視点で検証を行いましたので、その結果を発表させていただきます。

通常、RAGはベクターデータベースを基盤として動作します。
今回は、ベクターデータベースの代わりに、Neo4jなどのグラフデータベースを使用した場合の動作について比較・検証を行いました。
また、グラフデータベースとベクターデータベースのハイブリッド方式でRAGを動作させた場合についても検証を行いました。
まだ検証中の段階ですが、中間報告として発表させていただきます。

目次はご覧の通りです。
まず、グラフデータベースをベースにRAGを作成する場合の仕組みの概要をご説明させていただきます。
次に、参考のためにベクターデータベースをベースにRAGを作成する場合の仕組みの概要もご説明いたします。
そして、ハイブリッド方式を使用した場合に具体的な質問文を入力して実際の動作をお見せします。
そしてグラフデータベース単体でRAGを作成した場合のクエリの応答例、
ベクターデータベース単体でRAGを作成した場合のクエリの応答例、
ハイブリッド方式を使用してRAGを作成した場合のクエリの応答例を示し、比較いたします。
最後に、まとめと展望を述べます。
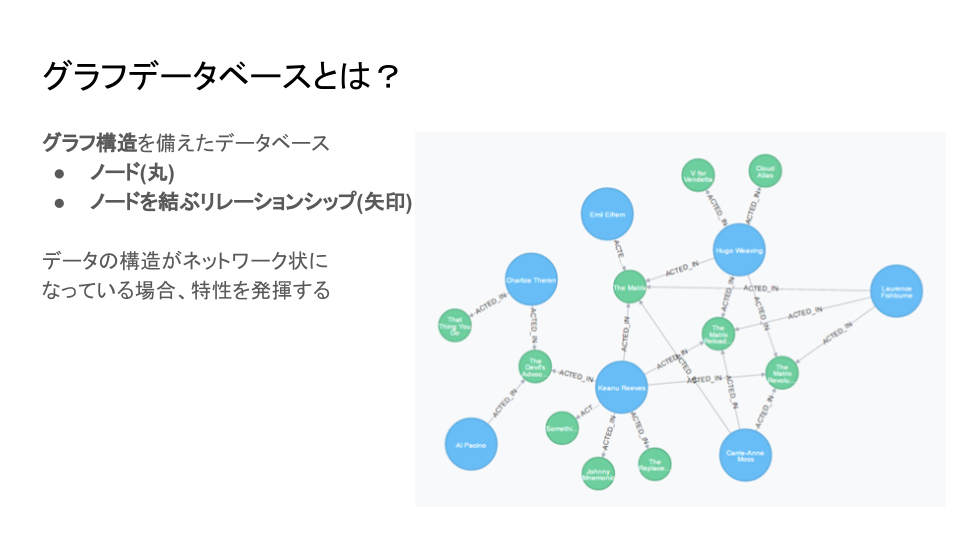
まず、グラフデータベースについて簡単に概念を説明します。
グラフデータベースとは右の図のようなグラフ構造を備えたデータベースのことです。
グラフ構造とは、丸で表されているノードとノード同士を結ぶ矢印で表されているリレーションシップから成る構造です。
グラフデータベースはデータの構造が図のようにネットワーク状になっている場合に特性を発揮します。

次に、ベクターデータベースについて簡単に説明します。
AIで言葉を処理する場合は、文章の意味を数字の列に置き換えて考えます。
この数字の列のことをベクトルと呼びます。
文章の意味をベクトルに置き換えて考えることにより、文章の意味がどれだけ似ているかを素早く計算することができるようになります。
このベクトルの格納と処理に特化したデータベースがベクターデータベースです。
文章や画像や音声のようなデータの類似性を素早く判断したいときに活躍します。
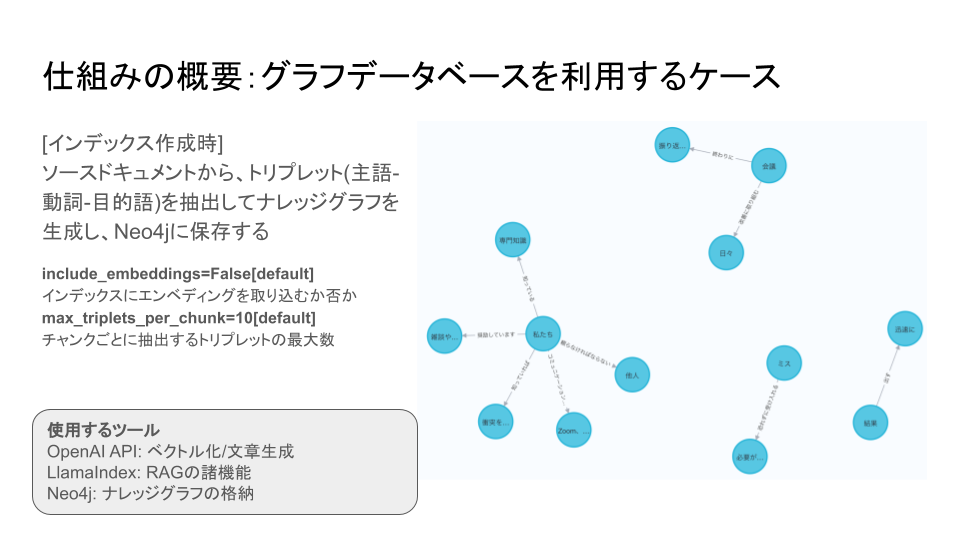
まず、グラフデータベースをベースにRAGを作成する場合の仕組みの概要をご説明させていただきます。
まず、RAGに与える専門知識を記述したソースドキュメントから右図のようなナレッジグラフを抽出します。
後ほど提示しますが、今回ナレッジグラフの作成には、クリエーションラインのホームページに記載されているCulture of Creationlineというクリエーションラインの文化に関する3153文字の記述をソースドキュメントとして使用しました。
この過程によって、RAGはクリエーションラインの文化についての専門知識を取得することになります。
このドキュメントから主語、動詞、目的語の3つの語句からなるトリプレットと呼ばれる組を抽出し、右図のようなグラフの形にしてNeo4jに保存します。
今回グラフデータベースを使用してRAGを構築するにあたって使用したツールは次の3つです。
まず、OpenAI API。こちらは単語やテキストのベクトル化や文章生成のために使用しました。
次に、LlamaIndex。こちらはRAGを実現するための中核となるIndexなどの諸機能を担っています。
最後に、Neo4j。こちらはRAGの知識を格納するナレッジグラフを保存しておくためのグラフデータベースです。
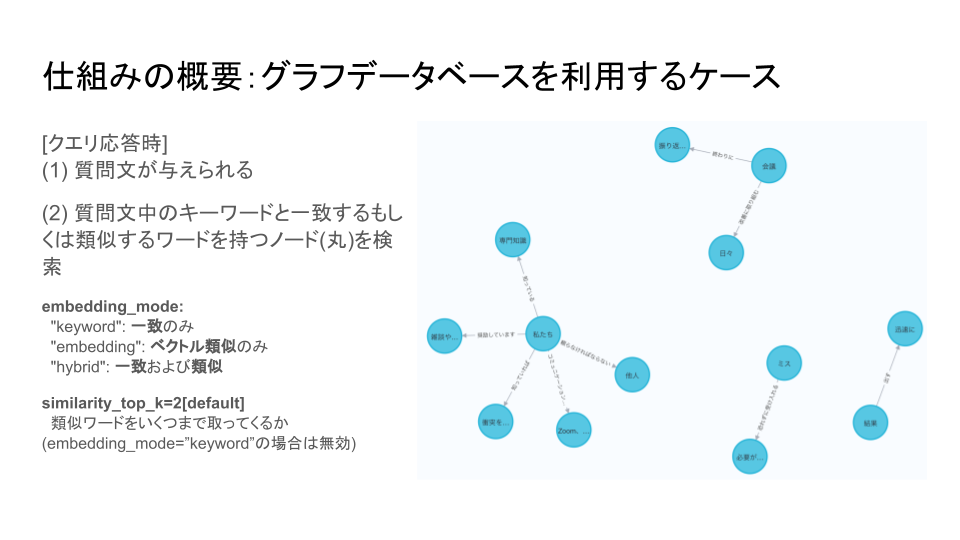
これまでは、質問文を実際にRAGに入力する以前に、RAGに知識を格納しておくために必要な準備段階でしたが、ここからは、実際に質問文にRAGが応答する際の動作になります。
質問文が与えられると、RAGは質問文に含まれるキーワードと一致する、あるいは類似する語句を持つノードを検索します。
ここでノードというのは、右図における水色の丸、すなわち主語や目的語が格納されている場所になります。
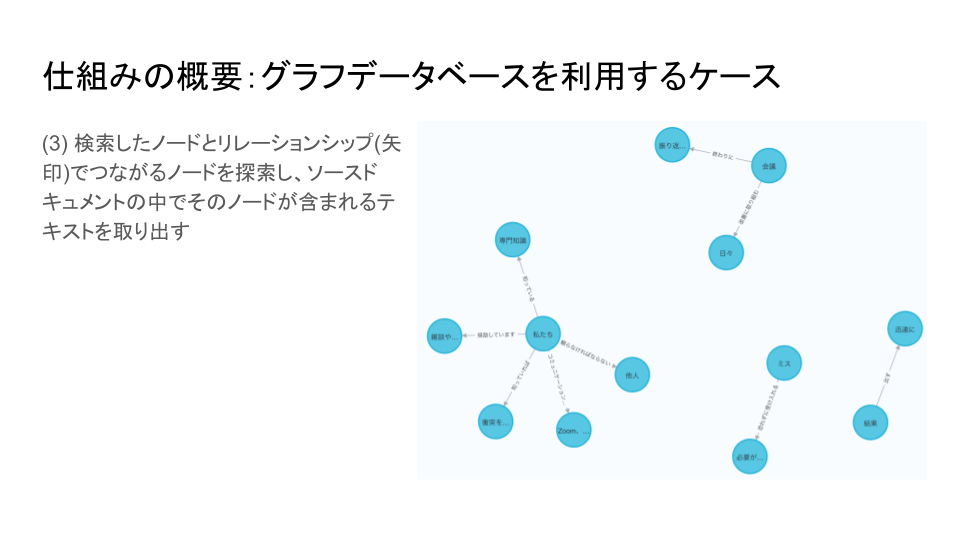
次に、検索に引っかかったノードとリレーションシップでつながっているノードを探索します。
リレーションシップとは、水色の丸同士を結ぶ矢印のことです。
この過程で、検索に引っかかったノードと関連性のある語句が芋づる式に取り出せることになります。
その後、ソースドキュメントを参照し、元の文章においてそれらの関連語句が含まれていたテキスト、つまり関連文書を取り出します。
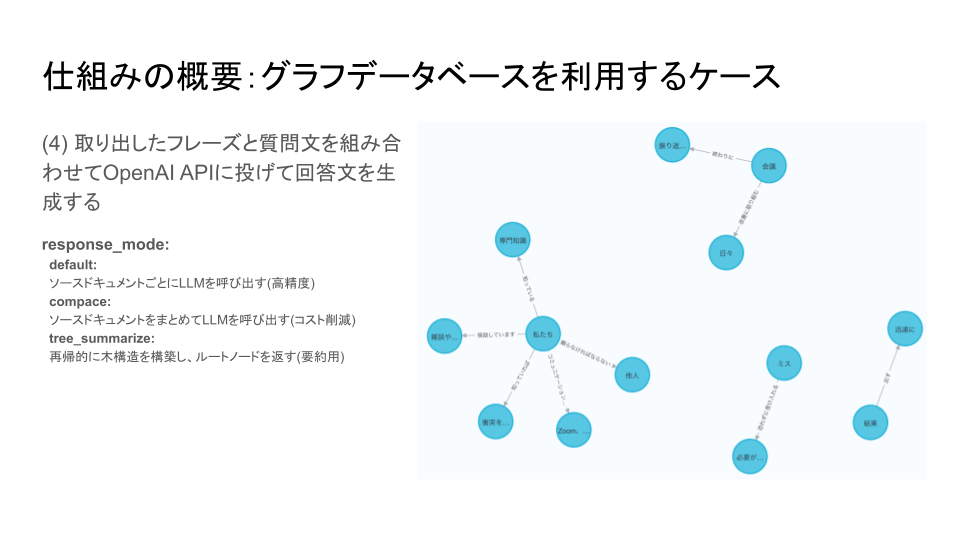
最後に、これらの関連文書と質問文を組み合わせた新たな質問文をOpenAI APIに投げて、回答文を生成してもらいます。
質問文にRAGが応答する際の動作は以上になります。
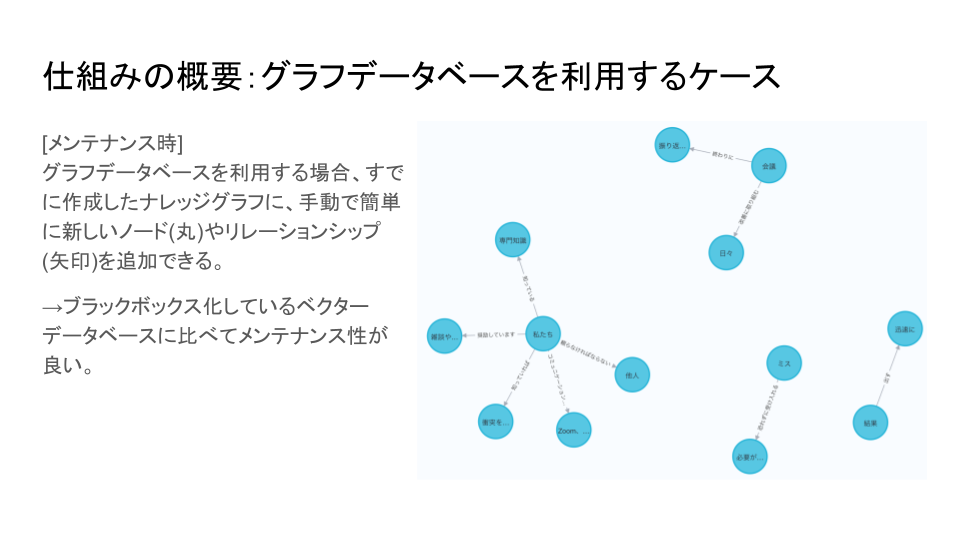
こちらは補足ですが、グラフデータベースを利用する場合のメリットとして、すでに作成したナレッジグラフに、手動で簡単に新しいノードやリレーションシップを追加できるという点があげられます。
次に説明するベクターデータベースの場合に比べると、知識の格納状態が人の目に分かりやすく、メンテナンスがしやすいというメリットがあります。
次に、ベクターデータベースをベースにRAGを作成する場合の仕組みの概要を簡単にご説明させていただきます。
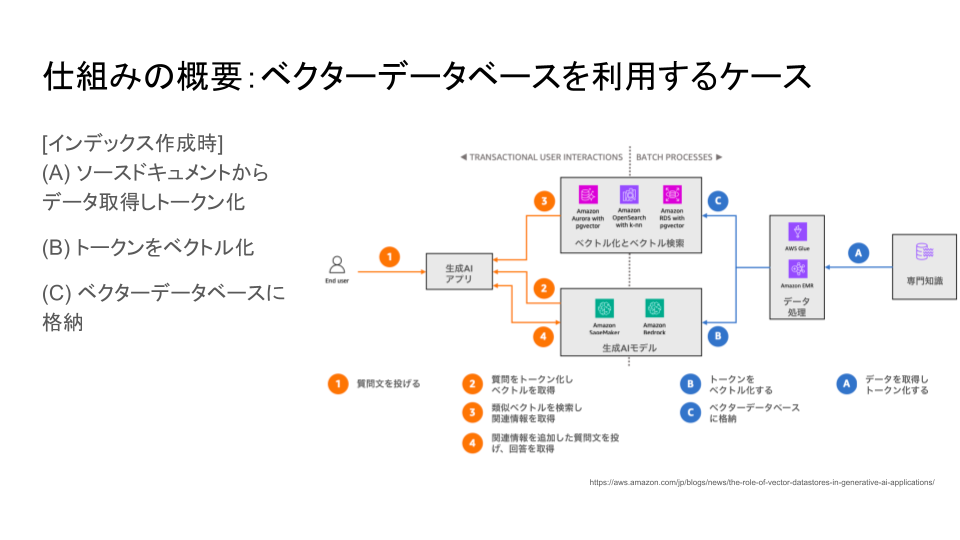
まず、RAGに知識を格納しておくために必要な準備を行います。
右端の専門知識を格納しているデータベースから、ソースドキュメントを取得し、テキストをトークンと言われる小さな語句に分解します。
次に、それぞれのトークンをOpenAI APIを使用してベクトル化します。
最後に、テキストをベクトル化したトークンと一緒にベクターデータベースに格納します。
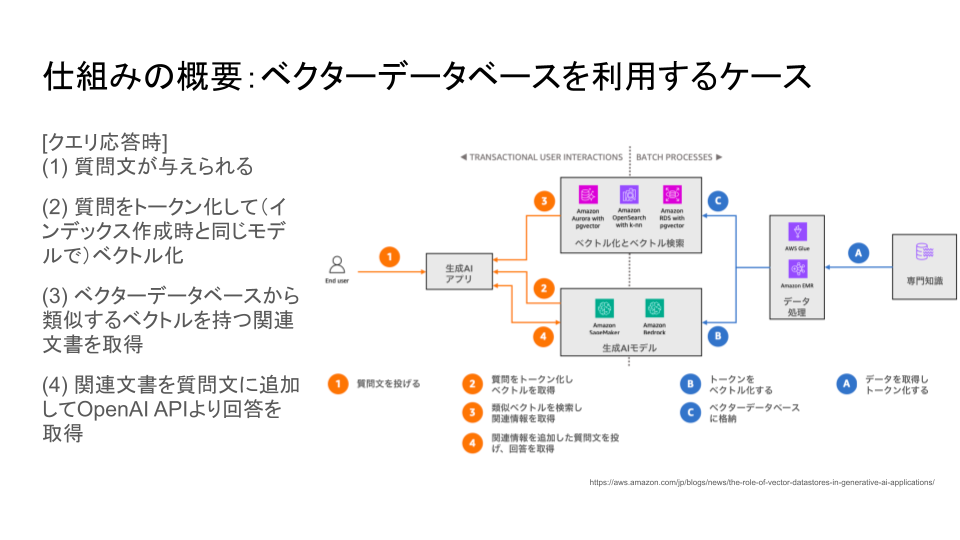
これまでは、質問文を実際にRAGに入力する以前に、RAGに知識を格納しておくために必要な準備段階でしたが、ここからは、実際に質問文にRAGが応答する際の動作になります。
質問文が与えられると、質問文をトークンと言われる小さな語句に分解し、先程と同じようにOpenAI APIを使用してベクトル化します。
そして、ベクターデータベースから類似するベクトルを持つ関連文書を取得します。
最後に、これらの関連文書と質問文を組み合わせた新たな質問文をOpenAI APIに投げて、回答文を生成してもらいます。
質問文にRAGが応答する際の動作は以上になります。
こちらが、今回使用した専門知識を含むソースドキュメントです。
小さくて見えないと思いますが、クリエーションラインのホームページに記載されているCulture of Creationlineというクリエーションラインの文化に関する3153文字の記述になります。
このドキュメントを先述の手順でグラフデータベースあるいはベクターデータベースに格納することによって、RAGはクリエーションラインの文化についての専門知識を取得することになります。

それでは、実際のRAGの動作を確認してみましょう。
今回は、グラフデータベースとベクターデータベースを組み合わせて使用したハイブリッド方式によるクエリの回答を見てみます。
事前準備したデモ動画を見て、グラフデータベースによる回答、ベクターデータベースによる回答、ハイブリッド方式による回答の順序で動作を確認しましょう。

実際のクエリの応答例を見てみましょう。
まず、グラフデータベースのみを使用した場合です。
どのような性格の人にクリエーションラインはおすすめですか?という質問文に対し、
「クリエーションラインは、役割を担っているメンバーが重要であり、上司の地位や偉さに関係なく、お互いの役割が尊重されるチームです。したがって、クリエーションラインには、協力的でチームプレーヤーの性格を持つ人がおすすめです。」
という回答が返ってきました。
事前にソースドキュメントからナレッジグラフを構築するのにかかった時間が69.4秒、質問文を投げてから回答が返ってくるまでにかかった時間が18.8秒です。

次に、ベクターデータベースのみを使用した場合です。
さきほどと同じ質問文に対し、
「クリエーションラインは、謙虚さ、尊敬、信頼、喜びといった価値観を重視する人におすすめです。また、ミスを恐れずに積極的に行動し、スピード感を持って取り組むことができる人にも適しています。さらに、チームメンバーとのコミュニケーションを大切にし、お互いを知ることを奨励する文化に参加したい人にもおすすめです。」
という回答が返ってきました。
事前のソースドキュメントのベクトル化とデータベース格納にかかった時間は0.9秒と非常に短く、質問文を投げてから回答が返ってくるまでにかかった時間は13.6秒です。

最後に、グラフデータベースとベクターデータベースを組み合わせたハイブリッド方式を使用した場合です。
さきほどと同じ質問文に対し、
「クリエーションラインは、謙虚で尊敬し信頼できる人々におすすめです。クリエーションラインの文化では、HRT(謙虚、尊敬、信頼)の理念が重要視されています。また、効果的なフィードバックを行うことも求められており、ビジネスへの影響に焦点を当てることが重要です。したがって、クリエーションラインでは、協調性のある、他のメンバーとの関係を大切にする性格の人が適しています。」
という回答が返ってきました。
グラフデータベースのみやベクターデータベースのみの場合に比べて、詳しく、的を射た回答文が返ってきています。
事前学習にかかった時間が150秒、質問文を投げてから回答が返ってくるまでにかかった時間が20.8秒です。

最後に簡単なまとめと展望を述べます。
今回様々な質問文について、グラフデータベース方式・ベクターデータベース方式・ハイブリッド方式によるそれぞれの応答を比較した結果、グラフデータベースを利用するメリットが分かってきました。
ベクターデータベース方式でも自然なクエリ応答文が得られますが、グラフデータベースと組み合わせたハイブリッド方式により、さらに洗練された応答文が得られます。
このように、RAGの精度向上にはグラフデータベースによるナレッジグラフを用いることが効果があることが分かりました。
今後の課題ですが、パラメータチューニングによる応答時間や精度向上の調査などの深い調査がまだできていないため、今回の結果についてはさらなる改善の余地があります。
私の発表は以上となります。ご清聴ありがとうございました。



