
MongoDB同士のデータマイグレーションのベストプラクティスを探る ~mongosyncの基本的な使い方編~ #mongodb #datamigration

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
MongoDBテクニカルサポートの山森です。前回の記事「MongoDB同士のデータマイグレーションのベストプラクティスを探る ~mongodump/mongorestore編~」に引き続き、mongosync編です。
前回のおさらい
前回の記事で、以下の点に注意することでmongodump/mongorestoreがMongoDB同士のデータマイグレーションツールとして使えそう、という話をしました。
- mongodump+(データの移動)+mongorestoreにかかる時間をシステムのメンテナンス時間として許容できる
- 移行元サーバにダンプファイルを一時的に配置することができる(圧縮オプションを使用すればかなり小さくすることが可能)
本番環境だとシステムメンテナンスの時間が十分に取れなかったり、ダンプファイルを一時的に配置するストレージの余裕がなかったりするかもしれません。mongosyncについて、これらの懸念点をカバーした使い方ができるのか見ていきましょう。
検証環境
Primary 1台、Secondary 1台のレプリカセットを構成しました。
(※検証用の最小構成です。公式ドキュメントではPrimary 1台+Secondary 2台が最小の推奨構成であることに注意してください)
本当はスタンドアロン同士で検証したかったのですが、mongosyncが読み取り懸念(read concern)の設定を必ず参照するらしく、以下のようなエラーが出て実行できませんでした。
※↓ブログの仕様上、画面にすべての出力を表示できないので、見づらい方ははExternを押してください。別ウィンドウで表示されて見やすくなります。
(NotAReplicaSet) node needs to be a replica set member to use read concern
{"time":"2024-11-07T04:35:40.279913Z","level":"fatal","serverID":"baccdc90","mongosyncID":"coordinator","stack":[{"func":"Wrapf","line":"258","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/internal/labelederror/labelederror_constructors.go"},{"func":"Wrap","line":"238","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/internal/labelederror/labelederror_constructors.go"},{"func":"runMongosyncWithCtx","line":"121","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/internal/mongosync/app.go"},{"func":"runMongosync","line":"83","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/internal/mongosync/app.go"},{"func":"(*Command).Run","line":"274","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/vendor/github.com/urfave/cli/v2/command.go"},{"func":"(*App).RunContext","line":"332","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/vendor/github.com/urfave/cli/v2/app.go"},{"func":"main","line":"31","source":"/data/mci/8f916aeefa625952c2271e8891f7ed27/src/github.com/10gen/mongosync/cmd/mongosync/main.go"},{"func":"main","line":"271","source":"/opt/golang/go1.22/src/runtime/proc.go"},{"func":"goexit","line":"1695","source":"/opt/golang/go1.22/src/runtime/asm_amd64.s"}],"error":{"msErrorLabels":["serverError"],"clientType":"destination","database":"mongosync_reserved_for_internal_use","collection":"resumeData","operationDescription":"Restoring bootstrap data from the resume data doc for mongosync with id: coordinator.","failedCommand":"FindOne","message":"failed to initialize mongosync: failed to restore resume data from destination collection mongosync_reserved_for_internal_use.resumeData: failed to get bootstrap data from the resume data doc for mongosync with id 'coordinator' in destination collection mongosync_reserved_for_internal_use.resumeData: failed to execute a command on the MongoDB server: (NotAReplicaSet) node needs to be a replica set member to use read concern"},"message":"Mongosync exited with an error."}
公式ドキュメントには「スタンドアロンでは使えない」という明確な記述はありませんでしたが、クイックスタート内に「mongosyncは 2 つのクラスター間でデータを同期します。各クラスターは、レプリカセットとシャーディングされたクラスターにすることができます。 いずれかがシャーディングされたクラスターである場合は、 mongosyncのシャーディングされたクラスターの制限を参照してください。」という記述があるので、レプリカセットかシャーディングで構成したクラスター間で使うことしか想定されていないのでしょう。皆さんは俺の屍を越えてゆけ。
少し脇道にそれましたが、検証環境の話に戻ります。ここに登場するインスタンスはすべてESXi上のVMで構築しており、すべて同セグメントのネットワークに所属しています。
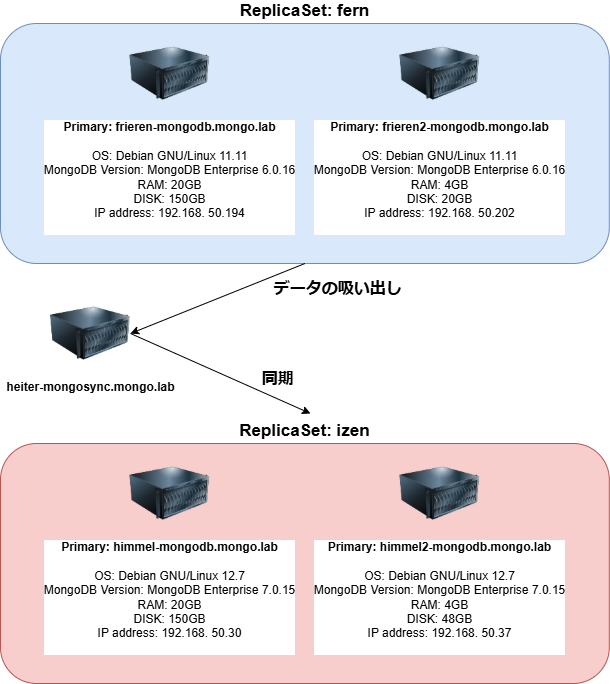
ReplicaSet「fern」から、heiter-mongosyncを経由してReplicaSet「izen」にデータを同期させます。
mongosyncを使うメリット
mongosyncはマイグレーション対象のmongodインスタンスの上以外でも稼働させられるのがメリットです。例えば、サービスイン後のインスタンスは設定変更が許可されていなかったり、必要であっても決裁が必要な場面があるかもしれません。下準備として、ユーザ作成とロール設定は必要ではありますが(後ほど解説します)、システム管理者としては本番環境のインスタンスの操作は極力避けたいものです。
オンプレミスの環境で、同ラック内にマウントしたmongodインスタンス同士で、コンソールPCを経由してmongosyncで同期させる…という使い方も可能かと思います。(昨今でそんなオンプレミスの環境は少なそうではありますが…。)
mongodump/mongorestoreを使う場合は、実行中のmongodインスタンスとやり取りするため、実行中のデータベースのパフォーマンスへの影響を及ぼす可能性がありました。これはMongoDB公式ドキュメントの「MongoDB ツールを使用した自己管理型配置のバックアップと復元」内の「パフォーマンスへの影響」内でも言及されています。
一方で、mongosyncのドキュメント「ホスティング」内で「mongosyncユーティリティは、ソースクラスターまたは宛先クラスターのいずれかに近いハードウェアでホストできます。 クラスター内のmongodまたはmongosインスタンスのいずれかと同じサーバーでホストされている必要はありません。 この柔軟性により、宛先クラスターにデータをプッシュまたはプルして、宛先クラスターで実行されているmongodまたはmongosインスタンスへの影響を最小限に抑えることができます。」という記載がありますので、インスタンスへの影響を抑える意味でもmongosyncは有効です。
mongosyncのインストール
公式ドキュメントによると、MacOSおよびLinuxでの動作がサポートされています。Windowsは今のところはないようです…。もしかしたらWSLで行けるかもしれませんが今回は試していません。
Linuxのプラットフォームサポート(2024年11月現在)は以下の通りです。
- Amazon Linux 2
- Red Hat Enterprise Linux (RHEL) 7
- Red Hat Enterprise Linux (RHEL) 8
- Ubuntu 18.04
- Ubuntu 20.04
今回はUbuntu 20.04のServer install imageをheiter-mongosync.mongo.labにインストールして使います。mongosyncは公式ドキュメントの手順にしたがってインストールしていきましょう。
ダウンロード
nika@heiter-mongosync:~$ curl -O https://fastdl.mongodb.org/tools/mongosync/mongosync-ubuntu2004-x86_64-1.8.1.tgz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 17.2M 100 17.2M 0 0 5547k 0 0:00:03 0:00:03 --:--:-- 5547k
nika@heiter-mongosync:~$ ls -lh
total 18M
-rw-rw-r-- 1 nika nika 18M Nov 6 07:12 mongosync-ubuntu2004-x86_64-1.8.1.tgz
解凍
nika@heiter-mongosync:~$ tar -zxvf mongosync-ubuntu2004-x86_64-1.8.1.tgz mongosync-ubuntu2004-x86_64-1.8.1/LICENSE mongosync-ubuntu2004-x86_64-1.8.1/THIRD-PARTY-NOTICES mongosync-ubuntu2004-x86_64-1.8.1/bin/mongosync
PATHを通して動作確認を兼ねたバージョンチェック
nika@heiter-mongosync:~$ sudo cp -ip mongosync-ubuntu2004-x86_64-1.8.1/bin/mongosync /usr/local/bin/ nika@heiter-mongosync:~$ printenv | grep PATH PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin nika@heiter-mongosync:~$ mongosync --version version: 1.8.1 git version: c77e2a0df00921d2aab54310f15a604504e352fc build tags: ssl, sasl, gssapi, failpoints Go version: go1.22.8 os: linux arch: amd64 compiler: gc
とっても簡単でしたね!
下準備①:mongosyncで使用するユーザを用意する
mongosyncを使うときはユーザを指定する必要があります。必要な権限については公式ドキュメントの「ロール」に記載があります。同期元(ソース)と宛先のクラスターで権限が異なることに注意してください。こんなときなにかとrootやadminで済ませてしまいがちですが、きっと勇者ヒンメルならば最低限のロールを保有したユーザを作成すると思ったので、私もそうしました。
今回は同期タイプ「default」のロールを付与します。データベースadminにスイッチ(use admin)してからcreateUserを実行することで、そのクラスタのデータベースすべてが対象となります。
移行元のユーザ作成コマンドは以下の通りです。
use admin
db.createUser({
user: "frieren",
pwd: "soso_no_frieren",
roles: [
{ role: "backup", db: "admin" },
{ role: "clusterMonitor", db: "admin" },
{ role: "readAnyDatabase", db: "admin" }
]
})
実行した結果は以下の通りです。ok: 1,があれば正常に作成されています。
Enterprise fern [direct: primary] admin> db.createUser({
user: "frieren",
... user: "frieren",
... pwd: "soso_no_frieren",
... roles: [
... { role: "backup", db: "admin" },
{ role: "clusterMonitor", db: "admin" },
... { role: "clusterMonitor", db: "admin" },
... { role: "readAnyDatabase", db: "admin" }
... ]
... })
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1732069946, i: 1 }),
signature: {
hash: Binary.createFromBase64('AAAAAAAAAAAAAAAAAAAAAAAAAAA=', 0),
keyId: Long('0')
}
},
operationTime: Timestamp({ t: 1732069946, i: 1 })
}
念のためにユーザが正常に作成されたのか確認します。
実行コマンド
db.getUser("frieren")
実行結果
Enterprise fern [direct: primary] admin> db.getUser("frieren")
{
_id: 'admin.frieren',
userId: UUID('31dab86e-a21f-4e3d-93e3-3921fb5ce5da'),
user: 'frieren',
db: 'admin',
roles: [
{ role: 'readAnyDatabase', db: 'admin' },
{ role: 'backup', db: 'admin' },
{ role: 'clusterMonitor', db: 'admin' }
],
mechanisms: [ 'SCRAM-SHA-1', 'SCRAM-SHA-256' ]
}
移行先のユーザ作成コマンドは以下の通りです。
use admin
db.createUser({
user: "himmel",
pwd: "brave",
roles: [
{ role: "clusterManager", db: "admin" },
{ role: "clusterMonitor", db: "admin" },
{ role: "readWriteAnyDatabase", db: "admin" },
{ role: "restore", db: "admin" }
]
})
念のためにgetUserで確認しましょう。コマンドは以下の通りです。
db.getUser("himmel")
コマンド実行結果
Enterprise admin> db.getUser("himmel")
{
_id: 'admin.himmel',
userId: UUID('caead06f-31d2-4f02-bf10-082b0287ab62'),
user: 'himmel',
db: 'admin',
roles: [
{ role: 'readWriteAnyDatabase', db: 'admin' },
{ role: 'clusterMonitor', db: 'admin' },
{ role: 'restore', db: 'admin' },
{ role: 'clusterManager', db: 'admin' }
],
mechanisms: [ 'SCRAM-SHA-1', 'SCRAM-SHA-256' ]
}
下準備②:実行コマンドを作成する
mongosyncを実行する際のコマンドを作成していきます。ここでもMongoDBではおなじみの接続文字列を使います。" "で囲まれたmongodb://~の部分が接続文字列です。公式ドキュメントの「クラスターの接続」の章も参考にしてください。
今回の検証で使用するコマンドは以下の通りです。
mongosync \
--logPath /home/nika/mongosync_log \
--cluster0 "mongodb://frieren:soso_no_frieren@frieren-mongodb.mongo.lab:27017/?authSource=admin" \
--cluster1 "mongodb://himmel:brave@himmel-mongodb.mongo.lab:27017/?authSource=admin"
使ってみる
さっそくmongosyncを使っていきたいのですが、その前に、mongosyncは複数の状態を経てデータのマイグレーションを行うことを知っておく必要があります。
以下の画像は公式ドキュメントのものです。mongosyncをはじめて起動するとまず「IDLE State」になります。この時はまだデータの同期をせずに待機しています。
その後、作業者からの指示をトリガーに「RUNNING State」となり、データの同期が始まります。作業者が「COMMITING State」への移行を指示しない限り、データの同期が続きます。
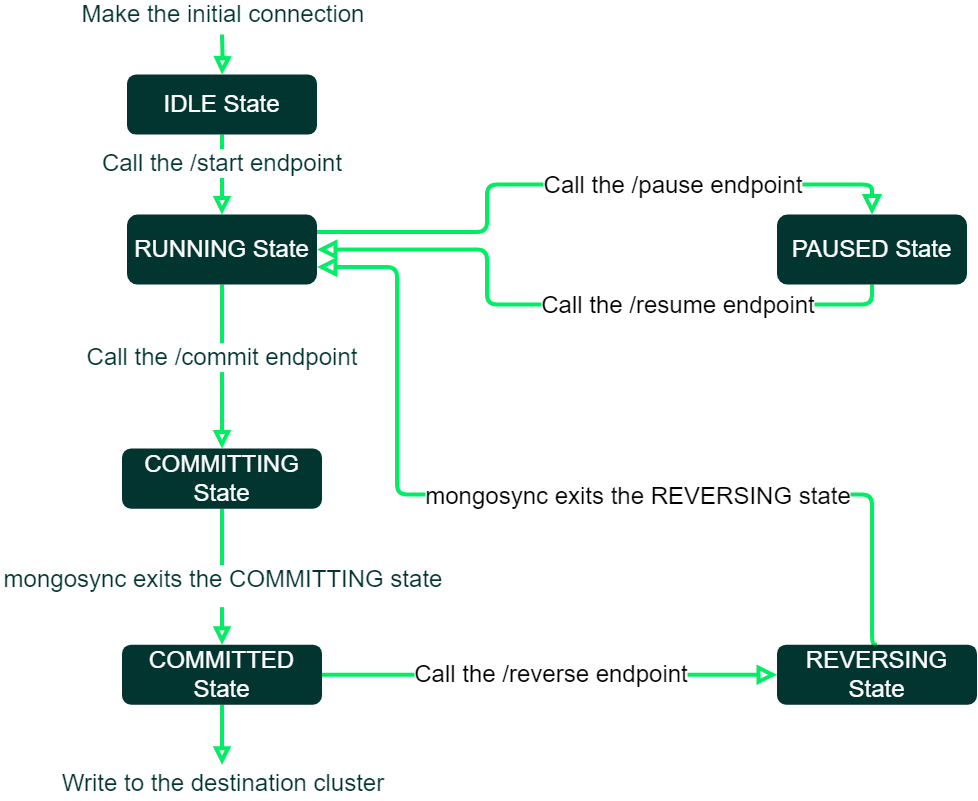
ここで注意しなければならないのは、COMMITING Stateへの移行=カットオーバープロセスの開始という点です。mongosyncでは、カットオーバーは「アプリケーションの向きをソースクラスターから宛先クラスターへ切り替える」ことを意味します。作業者がCOMMITING Stateへの移行を指示した後のデータの再同期はできません(想定されていません)。
アプリケーションはソースクラスターに読み書きしながら、mongosyncで宛先クラスターにデータを同期させつつ、COMMITING Stateに移行して新しいクラスターへのカットオーバーを行う…という使い方が正しいようです。うまく使えばサービスのダウンタイムがほとんどなくカットオーバーができそうです。
詳細は、公式ドキュメントの「mongosyncについて」「カットオーバープロセスの終了」もあわせて確認してください。
①IDLE Stateにする
それでは、先ほど作成した実行コマンドを実行してみましょう。初期接続を行った後、IDLE Stateに移行するのですが、初期接続にはしばらくかかります。フォアグラウンドで実行すると以下のようになり、応答が帰ってこなくなります。Ctrl+Cで止めてしまうとmongosyncも止まりますので、別ウィンドウをもう一つ立ち上げて作業することにします。
nika@heiter-mongosync:~$ mongosync \ > --logPath /home/nika/mongosync_log \ > --cluster0 "mongodb://frieren:soso_no_frieren@frieren-mongodb.mongo.lab:27017/?authSource=admin" \ > --cluster1 "mongodb://himmel:brave@himmel-mongodb.mongo.lab:27017/?authSource=admin" (応答が返ってこなくなる)
ログファイルを見てみましょう。問題なければ"Running webserver."のメッセージが出て、IDLE Stateになっています。
nika@heiter-mongosync:~$ tail -3 mongosync_log/mongosync.log
{"time":"2024-11-20T02:51:27.570617Z","level":"debug","serverID":"1a602296","mongosyncID":"coordinator","operationID":"34db4b61","clientType":"destination","database":"mongosync_reserved_for_internal_use","operationDescription":"Restoring collection stats.","attemptNumber":0,"totalTimeSpent":"1.793µs","retryAttemptDurationSoFarSecs":0,"retryAttemptDurationLimitSecs":600,"collection":"statistics","message":"Trying operation."}
{"time":"2024-11-20T02:51:27.673197Z","level":"debug","serverID":"1a602296","mongosyncID":"coordinator","operationID":"ff5aba57","clientType":"destination","database":"mongosync_reserved_for_internal_use","operationDescription":"Restoring UUID map.","attemptNumber":0,"totalTimeSpent":"1.932µs","retryAttemptDurationSoFarSecs":0,"retryAttemptDurationLimitSecs":600,"collection":"uuidMap","message":"Trying operation."}
{"time":"2024-11-20T02:51:27.770569Z","level":"info","serverID":"1a602296","mongosyncID":"coordinator","port":27182,"message":"Running webserver."}
正常に稼働していれば127.0.0.1:27182でポートが開いています。これがmongosyncのプロセスが動いているポートです。ssコマンドで確認してみましょう。
mongosyncのプロセスが、対象レプリカセットのクラスターに接続しに行っていることも、あわせて分かりますね。
nika@heiter-mongosync:~$ sudo ss -anput
[sudo] password for nika:
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
udp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=773,fd=12))
udp UNCONN 0 0 192.168.50.173%ens160:68 0.0.0.0:* users:(("systemd-network",pid=771,fd=15))
tcp LISTEN 0 4096 127.0.0.1:27182 0.0.0.0:* users:(("mongosync",pid=253089,fd=9))
tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=773,fd=13))
tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=849,fd=3))
tcp ESTAB 0 0 192.168.50.173:22 192.168.50.206:55007 users:(("sshd",pid=252954,fd=4),("sshd",pid=252840,fd=4))
tcp ESTAB 0 0 192.168.50.173:52074 192.168.50.194:27017 users:(("mongosync",pid=253089,fd=27))
tcp ESTAB 0 0 192.168.50.173:45784 192.168.50.30:27017 users:(("mongosync",pid=253089,fd=24))
tcp ESTAB 0 0 192.168.50.173:52048 192.168.50.194:27017 users:(("mongosync",pid=253089,fd=19))
tcp ESTAB 0 0 192.168.50.173:45800 192.168.50.30:27017 users:(("mongosync",pid=253089,fd=32))
tcp ESTAB 0 0 192.168.50.173:36570 192.168.50.202:27017 users:(("mongosync",pid=253089,fd=21))
tcp ESTAB 0 0 192.168.50.173:36562 192.168.50.202:27017 users:(("mongosync",pid=253089,fd=18))
tcp ESTAB 0 0 192.168.50.173:45810 192.168.50.30:27017 users:(("mongosync",pid=253089,fd=34))
tcp ESTAB 0 36 192.168.50.173:22 192.168.50.206:54567 users:(("sshd",pid=251451,fd=4),("sshd",pid=251284,fd=4))
tcp ESTAB 0 0 192.168.50.173:52076 192.168.50.194:27017 users:(("mongosync",pid=253089,fd=29))
tcp ESTAB 0 0 192.168.50.173:45682 192.168.50.37:27017 users:(("mongosync",pid=253089,fd=26))
tcp ESTAB 0 0 192.168.50.173:45666 192.168.50.37:27017 users:(("mongosync",pid=253089,fd=23))
tcp ESTAB 0 0 192.168.50.173:45690 192.168.50.37:27017 users:(("mongosync",pid=253089,fd=33))
tcp ESTAB 0 0 192.168.50.173:45772 192.168.50.30:27017 users:(("mongosync",pid=253089,fd=22))
tcp ESTAB 0 0 192.168.50.173:36584 192.168.50.202:27017 users:(("mongosync",pid=253089,fd=28))
tcp ESTAB 0 0 192.168.50.173:36594 192.168.50.202:27017 users:(("mongosync",pid=253089,fd=31))
tcp ESTAB 0 0 192.168.50.173:52044 192.168.50.194:27017 users:(("mongosync",pid=253089,fd=17))
tcp ESTAB 0 0 192.168.50.173:45698 192.168.50.37:27017 users:(("mongosync",pid=253089,fd=36))
tcp LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=849,fd=4))
実際にIDLE Stateなのか確認してみましょう。勘の良い方はお気づきかもしれませんが、mongosyncはweb serverとして動いているので、APIでやり取りすることができます。progressエンドポイントにリクエストを投げると、今のmongosyncの状態を確認することができます。具体的なリクエストの例は、公式ドキュメントもあわせて確認してください。
今回使用するコマンドは以下の通りです。
curl localhost:27182/api/v1/progress -XGET
実行するとjsonで答えが返ってきます。stateの項目を見ると確かにIDLEになっていますね。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/progress -XGET | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 206 100 206 0 0 41200 0 --:--:-- --:--:-- --:--:-- 41200
{
"progress": {
"state": "IDLE",
"canCommit": false,
"canWrite": false,
"info": null,
"lagTimeSeconds": null,
"collectionCopy": null,
"directionMapping": null,
"mongosyncID": "coordinator",
"coordinatorID": ""
},
"success": true
}
②同期を開始する(RUNNING Stateにする)
同期を始める前に、ソースと宛先でデータベースの中身が異なることを確認しておきましょう。mongosyncが走ると、「salmon_employee」のコレクションがhimmel側に同期されるはずです。
ソース(frieren-mongodb.mongo.lab)側
Enterprise fern [direct: primary] admin> show dbs admin 220.00 KiB config 176.00 KiB local 2.09 MiB salmon_employee 14.12 GiB
宛先(himmel-mongodb.mongolab)側
Enterprise eizen [direct: primary] admin> show dbs admin 220.00 KiB config 324.00 KiB local 2.36 GiB
さっそく同期をかけていきます。RUNNING Stateにするには、startエンドポイントにリクエストを投げます。今回実行したコマンドは以下の通りです。
curl localhost:27182/api/v1/start -XPOST \
--data '
{
"source": "cluster0",
"destination": "cluster1"
} '
実行した結果は以下の通りです。{"success":true} が帰ってきていれば同期プロセスが開始されています。確認のため、もう一度progressエンドポイントにリクエストを投げてみましょう。stateがRUNNINGになっており、コレクションの同期が進んでいることが分かりますね。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/progress -XGET | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 427 100 427 0 0 11540 0 --:--:-- --:--:-- --:--:-- 11861
{
"progress": {
"state": "RUNNING",
"canCommit": false,
"canWrite": false,
"info": "collection copy",
"lagTimeSeconds": 70,
"collectionCopy": {
"estimatedTotalBytes": 106141836452,
"estimatedCopiedBytes": 8619884269
},
"directionMapping": {
"Source": "cluster0: frieren-mongodb.mongo.lab:27017",
"Destination": "cluster1: himmel-mongodb.mongo.lab:27017"
},
"totalEventsApplied": 0,
"mongosyncID": "coordinator",
"coordinatorID": "coordinator"
},
"success": true
}
③カットオーバープロセスを開始する(COMMITED Stateにする)
しばらく待ってからhimmel側のデータベース構成を確認してみると、確かにsalmon_employeeが同期されています。
Enterprise eizen [direct: primary] admin> show dbs admin 220.00 KiB config 316.00 KiB local 3.36 GiB mongosync_reserved_for_internal_use 428.00 KiB salmon_employee 14.45 GiB
mongosyncの状態を確認してみましょう。stateはRUNNINGのままです。これでcommitするとデータの同期が止まり、カットオーバープロセスが始まるわけですが、本当にcommitして大丈夫でしょうか?commitの公式ドキュメントに従い、確認してみましょう。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/progress -XGET | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 436 100 436 0 0 106k 0 --:--:-- --:--:-- --:--:-- 106k
{
"progress": {
"state": "RUNNING",
"canCommit": true,
"canWrite": false,
"info": "change event application",
"lagTimeSeconds": 0,
"collectionCopy": {
"estimatedTotalBytes": 106679720810,
"estimatedCopiedBytes": 106679720810
},
"directionMapping": {
"Source": "cluster0: frieren-mongodb.mongo.lab:27017",
"Destination": "cluster1: himmel-mongodb.mongo.lab:27017"
},
"totalEventsApplied": 0,
"mongosyncID": "coordinator",
"coordinatorID": "coordinator"
},
"success": true
}
公式ドキュメントより:

canCommitはtrueになっており、lagTimeSecondsも0になっていますね。実際にアプリケーションを動かしている場合は、この段階でソースクラスターへの書き込みをストップします(サービス停止)。
commitエンドポイントにリクエストを投げてみましょう。今回使用したコマンドは以下の通りです。
curl localhost:27182/api/v1/commit -XPOST --data '{ }'
実行結果は以下の通りです。{"success":true}が帰ってきていれば成功しています。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/commit -XPOST --data '{ }'
{"success":true}
念のためprogressエンドポイントで確認してみましょう。ドキュメントではCOMMITING StateからCOMMITED Stateに移行すると書かれていましたが、すぐにstateがCOMMITEDになっていました。
「カットオーバープロセスの終了」ドキュメント内に、COMMITED-Stateになるための動作についての記載がありました。今回検証していたドキュメントでこのようになったのは、インデックスを設定していなかったからかもしれません。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/progress -XGET | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 430 100 430 0 0 419k 0 --:--:-- --:--:-- --:--:-- 419k
{
"progress": {
"state": "COMMITTED",
"canCommit": false,
"canWrite": true,
"info": "commit completed",
"lagTimeSeconds": 0,
"collectionCopy": {
"estimatedTotalBytes": 106679720810,
"estimatedCopiedBytes": 106679720810
},
"directionMapping": {
"Source": "cluster0: frieren-mongodb.mongo.lab:27017",
"Destination": "cluster1: himmel-mongodb.mongo.lab:27017"
},
"totalEventsApplied": 0,
"mongosyncID": "coordinator",
"coordinatorID": "coordinator"
},
"success": true
}
「カットーオーバープロセスの終了」のドキュメントによると、この段階で宛先クラスターが書き込み可能であることを確認(ドキュメント内の④)、ソースクラスターから宛先クラスターに本当にデータが同期されたかどうかを確認します(ドキュメント内の⑤)。確認方法は「データ転送を確認する」のドキュメントにも記載がありますので、あわせて参照してください。
データの同期が完了したかどうかを確認する、最終的な責任は移行作業を実施した人間にあります。MongoDBのマイグレーションに限った話ではありませんが、初めて使うツールについては必ず事前に検証を行ってください。移行作業手順は複数人でレビューを行い、データの同期がとれているか確認する方法についても、プロジェクト内で合意を取っておきましょう。
④カットオーバープロセスを完了する(mongosyncの終了)
さて、ここでは同期が完了し、アプリケーションの向きを宛先クラスターに切り替えたものとします(カットオーバープロセスの終了)、この段階で、フォアグラウンドで実行していたmongosyncをストップできます。
実行時に--logPathを指定したので、ログファイルが残っています。ちなみにlogPathを指定しないと標準入力にログが垂れ流しになります。
nika@heiter-mongosync:~$ ls -lh mongosync_log/ total 7.0M -rw------- 1 nika nika 7.0M Nov 20 05:26 mongosync.log
同期にかかった時間を比較する
ログから、同期にどのぐらいの時間を要したのか確認してみましょう。同期を始めた時刻はstartエンドポイントにリクエストを投げた時間とします。
nika@heiter-mongosync:~/mongosync_log$ grep "api/v1/start" mongosync.log
{"time":"2024-11-20T05:00:47.183422Z","level":"info","serverID":"c4d73584","mongosyncID":"coordinator","uri":"/api/v1/start","method":"POST","body":"\n {\n \"source\": \"cluster0\",\n \"destination\": \"cluster1\"\n } ","clientIP":"127.0.0.1","traceID":"a6b2e71c-308a-4728-bb05-5e1864666d4e","message":"Received request."}
canCommitになった時刻は以下の通りです。
{"time":"2024-11-20T05:11:05.776026Z","level":"info","serverID":"c4d73584","mongosyncID":"coordinator","status":200,"body":"{\"progress\":{\"state\":\"RUNNING\",\"canCommit\":true,\"canWrite\":false,\"info\":\"change event application\",\"lagTimeSeconds\":0,\"collectionCopy\":{\"estimatedTotalBytes\":106679720810,\"estimatedCopiedBytes\":106679720810},\"directionMapping\":{\"Source\":\"cluster0: frieren-mongodb.mongo.lab:27017\",\"Destination\":\"cluster1: himmel-mongodb.mongo.lab:27017\"},\"totalEventsApplied\":0,\"mongosyncID\":\"coordinator\",\"coordinatorID\":\"coordinator\"},\"success\":true}","traceID":"f89e3805-093f-47e0-aed8-c9feedbbf191","latency":"117.512µs","message":"Sent response."}
かかった時間は約10分18秒でした。同じコレクション「salmon_employee」でmongodump(mongorestore)を使用した前回の記事の結果は以下の通りです。100GB程度では移行時間に大きな差はないように見えます。
| gzip(圧縮) | mongodump | mongorestore | 合計 |
| なし | 3:12 | 6:45 | 9:57 |
| あり | 8:04 | 6:17 | 14:21 |
しかし、mongodump(mongorestore)を用いる場合の実際の移行時間は mongodumpでデータをダンプ化する時間+ダンプ化したデータを宛先クラスターに転送する時間+mongorestoreでリストアする時間の合計となります。当然作業者のオペレーションも必要です。そう考えると、データの同期を完了してあと速やかに宛先クラスターにカットオーバーできるmongosyncのほうが、サービス停止がほとんどなくマイグレーションが出来そうですね。
追加調査:COMMITED-State後に再同期をかけられるのか?
ちなみに、rsyncのように差分同期をかけることはできるのでしょうか?同期が終わったクラスタにmongosyncを再度実行し、progressエンドポイントにリクエストして今の状態を取得してみます。IDLEではなくCOMMITEDとなっていました。状態を保存しているようです。レプリカセットizen内に「mongosync_reseived_for_internal_use」というデータベースが作成されていたので、そこで管理しているのかもしれません。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/progress -XGET | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 408 100 408 0 0 99k 0 --:--:-- --:--:-- --:--:-- 99k
{
"progress": {
"state": "COMMITTED",
"canCommit": false,
"canWrite": true,
"info": "commit completed",
"lagTimeSeconds": 0,
"collectionCopy": {
"estimatedTotalBytes": 1,
"estimatedCopiedBytes": 0
},
"directionMapping": {
"Source": "cluster0: frieren-mongodb.mongo.lab:27017",
"Destination": "cluster1: himmel-mongodb.mongo.lab:27017"
},
"totalEventsApplied": 0,
"mongosyncID": "coordinator",
"coordinatorID": "coordinator"
},
"success": true
}
この状態でStartエンドポイントにリクエストしてみます。
nika@heiter-mongosync:~$ curl localhost:27182/api/v1/start -XPOST --data '
{
"source": "cluster0",
"destination": "cluster1"
} ' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 287 100 216 100 71 210k 71000 --:--:-- --:--:-- --:--:-- 280k
{
"success": false,
"error": "InvalidStateTransition",
"errorDescription": "the current state: `COMMITTED` is not equal to the expected current state: `IDLE` or mongosync cannot transition from: `COMMITTED` to: `RUNNING`"
}
このようなエラーが出て、COMMITTED-StateからはRUNNING-Stateに遷移できませんでした。やはり作業者がデータの同期が完了したことを確認し、作業者のタイミングでカットオーバープロセスを行うのが正しい使い方と言えるでしょう。
まとめ:mongosyncはマイグレーションに使えるのか?
以下のような特徴を持つマイグレーションツールであることが分かりました。
- アプリケーションを動かしながら、裏でデータの同期をかけることができる(データ移行中のサービスの停止が必要ない)
- 100GB程度では移行時間にあまり差がなかったが、データ量が大きくなるほどmongosyncを使うメリットが大きくなる
- mongosyncの想定したカットオーバープロセスに従うことが重要
MongoDBテクニカルサポートでは、mongosyncやmongodump(mongorestore)といった公式ツールであればサポートが可能です。しかし、(繰り返しになりますが)最終的な責任は移行作業を実施した人間にあります。事前にしっかりと検証を行い、移行作業手順を作成し、複数人でレビューを行ったうえでマイグレーション作業を行ってください。
蛇足・・・「引っ越し=トラック」のイメージがあるので、アイキャッチ画像にはトラックを使用しました。2歳の息子はトラックが大好きです。男児の中には、一定数はたらくくるまが好きな層がいますよね。何が彼らを引き付けるのでしょう…。



