
Neo4j-大量データの読み込み 2015#neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本記事は、「Neo4jの大量データインポート 2020 」にリニューアルしました。
Neo4jは、CSVファイルから大量データの読み込みを行います。CSVファイルの扱いは煩雑なイメージがあるかも知れませんが、そもそもNeo4jはスキーマレスのデータベースであるためにテーブルなどの事前準備が不用な上、ヘッダやデータタイプ設定、複数ファイルの扱いなどを考慮した専用ツールで簡単に大量データを扱うことができます。今回は、Neo4jのマニュアルで紹介されているCSVファイルを使って、LOAD CSVとneo4j-importの使用方法を解説します。
関連記事-CL-Lab
Neo4j-グラフデータベースとは
Cypher Query Language(QL)-構成要素編
Cypher Query Language(QL)-初級編
Neo4j-大量データの読み込み
関連記事-Qiita
WindowsでNeo4jを使ってみる
MacでNeo4jを使ってみる
SoftLayerでNeo4jを使ってみる
AWSでNeo4jを使ってみる
Neo4jウェブインターフェースを使い倒す
Neo4jの最適な利用方法について
他のデータベース及びデータストアとの連携
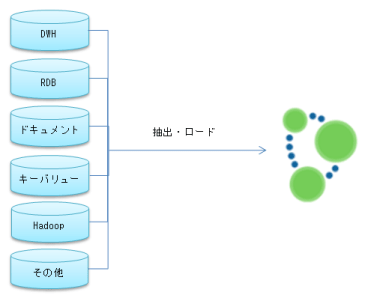
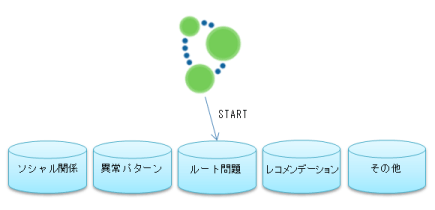
Neo4jは既存の様々なタイプのデータベースやデータストアからデータを抜き出して、速やかにサブジェクト毎のグラフデータベースを構築し、グラフ流の問題解決に臨むことを強く意識しています。とても複雑な関係性を含む問題、理想的な経路探し、ある種の異常パターンの検索、欠落した箇所の発見、ある種のパターンとパターン間の比較、レコメンデーションなどの問題は、Neo4jが卓越した能力を発揮できる領域です。このようなアプローチでは、対象の問題に関わるキー項目だけを抜き出して、グラフ構造のデータに集積して処理する方式が考えられます。
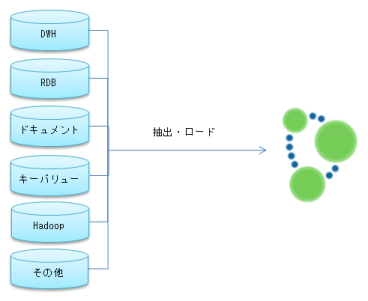
グラフデータベースのデータマート
Neo4jのグラフデータベースは一つのディレクトリの中に収まるようなとてもシンプルな構成になっています。そして、グラフデータベースの格納先を切り替えてNeo4jを再起動すれば、対象のグラフデータベースに接続できるようになっています。つまり、従来のデータマート的な使い方にぴったり当てはまります。Neo4jはデータパターンをメモリ上に展開するため、サイズが大きい多くの属性を持ったノードを広範囲にわたって集計するような処理に向いていません。しかし、広範囲であっても、分析に必要な少量のキー項目だけを持たせている場合は、おそらくグラフ問題以外の複雑な集計処理などにも応用できるでしょう。
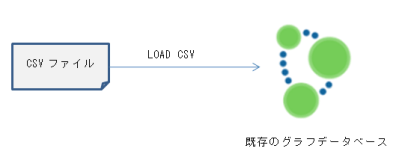
2種類のインポート方式
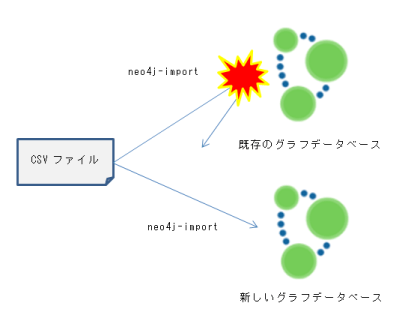
CSVファイルを利用して大量データを読み込むには、「LOAD CSV」又は「neo4j-import」という2つの方式を利用します。
Neo4jでは、頻繁にJSON形式のデータを利用しています。主にアプリケーションがCypherクエリにパラメーターを引き渡す時や戻り値のコンテナーとして使っています。
LOAD CSV
LOAD CSVは、既存のデータベースに対してデータの取り込みを行います。LOAD CSVは、CSVファイルからデータを読み込んで、ノードや関係性の追加や削除、属性の追加、削除、更新などを行います。注意点としては、一時的にメモリを使うためにデータサイズがJavaのヒープメモリを超えてしまうとオーバーフローを起こし、処理途中のデータはすべてロールバックされてしまいます。但し、ヒープメモリのオーバーフローは回避策があります。非常にサイズが大きいCSVファイルを読み込むときは、「USING PERIODIC COMMIT number」のように、一度のトラザクションとして処理する行数を制限することができます。
neo4j-import
neo4j-importは、CSVファイルからデータを取り込み、新規のデータベースを構築します。この方式では、登録するノードに対し、データベース全体で一意的なIDを付与する必要があります。そしてノード間の関連性の設定においても、始点ノードIDと終点ノードIDを指定する必要があります。この方式の用途としては、既存の関係型データベースや他のデータストアから抽出したデータをグラフデータベースへ移行することが考えられます。neo4j-importは、読み込んだデータから最低限の整合性のチェックなどを行いますが、グラフデータストアへダイレクトに流していくためにJavaのヒープメモリの問題は発生しません。そして、データの取り込みが終わった際には、「conf/neo4j-server.properties」の「org.neo4j.server.database.location=database-directory」のグラフデータベースの格納先ディレクトリを変更し、Neo4jを起動することで、新しいグラフデータベースに接続できます。
LOAD CSVの使用方法
以下では、Neo4jマニュアルのサンプルを使って、LOAD CSVの事例を数パターン説明します。
Load CSV(http://neo4j.com/docs/milestone/query-load-csv.htm)
CSVファイルのフォーマット
LOAD CSV で規定しているCSVファイルのフォーマットは、次のとおりです。
- UTF-8
- 改行は\n(Linux)/\r\n(windows)
- デフォルトのデリミタ―はコンマ(,)です
- 任意のデリミタ―も利用可能です。例えば、「IELDTERMINATOR ';'」のように定義できます
- 文字列はダブルクォテーション("string")で囲むのが原則です。例えば、数字を文字として扱う場合や文字列に引用符がついている場合などです。特にデータタイプを意識しなくても良い場合は、省略しても問題ありません。
- 引用符付きの文字列が使用可能です。読み込むときに、引用符は自動的に外されます。「The "Symbol"」のような結果を期待するデータの読み込みは「"The ""Symbol"""」のように設定します。
- エスケープ文字は「\」を使います。上記の属性値の場合は、「"The \"Symbol\""」ように表現できます
- CSVファイルの中にヘッダ(フィールド名)を指定する場合は、1行目に指定する必要があります。CSVファイルの中にヘッダを指定せず、ヘッダだけを別ファイルに指定することや、構文のなかで属性名を定義し、CSVファイルのなかの属性値とマッピングさせることも可能です。
LOAD CSVの実行方法
Neo4jウェブインターフェースの利用
コマンドラインのプロンプトに1構文ずつ入力して実行します。
neo4j-shellの利用
neo4j-shellの場合は、コマンドラインのプロンプトに入力する方法と、シェルスクリプトを書く方法があります。
次は、コマンドラインのプロンプトに入力する方法です。
$ neo4j-shell
neo4j-sh (?)$ LOAD CSV WITH HEADERS FROM "http://neo4j.com/docs/2.2.0-M04/csv/query-tuning/movies.csv" AS line
> MERGE (m:Movie { title:line.title })
> ON CREATE SET m.released = toInt(line.released), m.tagline = line.tagline;
次は、シェルでラッピングする方法です。
#!/bin/bash
neo4j-shell << EOF
LOAD CSV WITH HEADERS FROM "http://neo4j.com/docs/2.2.0-M04/csv/query-tuning/movies.csv" AS line
MERGE (m:Movie { title:line.title })
ON CREATE SET m.released = toInt(line.released), m.tagline = line.tagline;LOAD CSV WITH HEADERS FROM "http://neo4j.com/docs/2.2.0-M04/csv/query-tuning/actors.csv" AS line
MATCH (m:Movie { title:line.title })
MERGE (p:Person { name:line.name })
ON CREATE SET p.born = toInt(line.born)
MERGE (p)-[:ACTED_IN { roles:split(line.roles,";")}]->(m);LOAD CSV WITH HEADERS FROM "http://neo4j.com/docs/2.2.0-M04/csv/query-tuning/directors.csv" AS line
MATCH (m:Movie { title:line.title })
MERGE (p:Person { name:line.name })
ON CREATE SET p.born = toInt(line.born):EOF
LOAD CSVの例文1:ヘッダ無しのパターン
Artist.csv
"1","ABBA","1992"
"2","Roxette","1986"
"3","Europe","1979"
"4","The Cardigans","1992"
LOAD CSV FROM 'file:///C:/temp/csv/artists.csv' AS line
CREATE (:Artist { name: line[1], year: toInt(line[2])})
LOAD CSV FROM 'file:///C:/temp/artists.csv':ヘッダがないCSVファイルの読み込み書式です
CSVファイルの格納場所は、次にように3タイプの書き方が可能です。
ローカルのディレクトリ: file:///tmp/data/datafile.csv、file:///C:/Temp/data/datafile.csv
リモートサーバー:http://mypage.data.com/data/dafile.csv 、https://mypage.data.com/data/dafile.csv
オブジェクトストレージ:http://mybucket/data/dafile.csv、 https://mybucket/data/dafile.csv
AS line:lineはエイリアス名で行の識別子です。通常は、「識別子.属性名」の書式で使います。
CREATE (:Artist { name: line[1], year: toInt(line[2])}) :artists.csvの全体に対して「:Artist」というラベルを付けています。そして、CSVファイルのなかにヘッダが存在しないパターンなので、各属性値はインデックス「0」から始まるリストとして読み込んでいます。name: line[1]の場合、「属性名:LIST[1]」であり、結果値としては {name: "ABBA"}を示しています。今回のケースでは、line[0]は使われていませんが、LOAD CSVに読み込んだデータのノードIDは、Neo4jが自動的に割り当てます。
LOAD CSVの例文2:ヘッダ有りのパターン
artists-with-headers.csv
"Id","Name","Year"
"1","ABBA","1992"
"2","Roxette","1986"
"3","Europe","1979"
"4","The Cardigans","1992"
LOAD CSV WITH HEADERS FROM 'file:///C:/temp/csv/artists-with-headers.csv' AS line
CREATE (:Artist { name: line.Name, year: toInt(line.Year)})
LOAD CSV WITH HEADERS FROM:CSVファイルの1行目をヘッダとして処理します
CREATE (:Artist { name: line.Name, year: toInt(line.Year)}):「 name: line.Name」の場合、「属性名:識別子.ヘッダ名(属性名)」のようにデータを読み込んでいます。
LOAD CSVの例文3:デリミタ―のカスタマイズ
artists-fieldterminator.csv
"1";"ABBA";"1992"
"2";"Roxette";"1986"
"3";"Europe";"1979"
"4";"The Cardigans";"1992"
LOAD CSV FROM 'file:///c:/temp/csv/artists-fieldterminator.csv' AS line
FIELDTERMINATOR ';'
CREATE (:Artist { name: line[1], year: toInt(line[2])})
FIELDTERMINATOR ';:コンマの変わりにセミコロンをデリミタ―で使っています
LOAD CSVの例文4:トランザクション処理の行数制限
LOAD CSV文で非常に大量のデータを取り込むときは、1回のトラザクションで処理するデータの行数を制限し、Javaのヒープメモリが溢れないようにする必要があります。デフォルトは、1000行です。
USING PERIODIC COMMIT [行数]
LOAD CSV FROM 'http://neo4j.com/docs/2.2.0-RC01/csv/artists.csv' AS line
CREATE (:Artist { name: line[1], year: toInt(line[2])})
neo4j-importの使用方法
以下では、Neo4jのマニュアルの例示を使って、neo4j-importの使用方法を数パターン説明します。
Import Tool(http://neo4j.com/docs/milestone/import-tool.htm)
neo4j-importが使えるのは、Linux版のみです。Windows版では、Neo4jImport.batを使いますが、商用版のみの配布です。Linux版も、商用版に比べてコミュニティ版は、若干制約があります。例えば、neo4j-backupが使えません。しかし、年商5億円以下の企業で、Neo4jの商用版が必要な場合、条件次第では「Start upバージョン」が低予算で使えるかも知れません。それについては、「Neo4j社」又は、「クリエーションライン社」にご相談お願いします。単なる検証目的であれば、30日のトライアル版が使えます。
CSVファイルのフォーマット
neo4j-import で規定しているCSVファイルのフォーマットは、前項のLOAD CSVと殆ど同じですが、いくつかの違いがあります。
- 1つの構文でノードと関係性の両方のCSVファイル、ヘッダファイルをそれぞれ複数指定し、同時に読み込みことができます
- 既存グラフデータベースに対するインポートはできません。neo4j-import を使った場合は、常に新しいグラフデータベースが作られます
neo4j-importの実行方法
neo4j-importの場合は、OSのコマンドラインで実行します。もちろん、シェルスクリプトを書いても構いません。注意すべきは、1構文が1データベースになることです。構文を実行してからの追加や変更は、Neo4jを起動してから、LOAD CSVやCypherクエリで行います。なお、neo4j-importは、Neo4jが起動中でなくても実行できます。
$ neo4j-import --into /opt/disk1/data/neo4j/graph1.db --nodes movies.csv --nodes actors.csv --relationships roles.csv
neo4j-import:例文1
次のパターンは、映画の題材にしたノーマルなneo4j-import用のCSVファイルです。
movies.csv
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
movieId:ID:neo4j-importを使う場合は、グラフデータベース全体で一意のノードIDをユーザーが付与する必要があります。LOAD CSVを使う場合は、Neo4jが自動的に割り当てます
year:int:数字として使いたい場合は、データのタイプを指定できます
:LABEL:このケースでは、ラベルもCSVファイルの中に定義しています。ラベルは「Movie;Sequel」のようにセミコロンで区切っています。ラベルは「Movie:Sequel」のようにサブラベルを定義し、階層化することができます。
actors.csv:
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles.csv
関係性定義用のCSVファイルです。
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
:START_ID:関係性設定のための始点ノードのIDです。ここでは俳優の名前(属性)になっています
role:映画のなかの配役であり、関係性の属性として設定します
:END_ID:関係性設定のための終点ノードのIDであり、始点ノードのIDと繋がます。
:TYPE:関係性のタイプを示しています
次の構文が、上記の3つのCSVファイルのインポート文です。複数のファイルを指定していますが、すべて一つのグラフデータベースとして扱われます。
neo4j-import --into /opt/disk1/data/neo4j/graph1.db --nodes movies.csv --nodes actors.csv --relationships roles.csv
--into /opt/disk1/data/neo4j/graph1.db:グラフデータベースの格納先ディレクトリを指定します
--nodes movies.csv:ノード用のCSVファイルを指定します。コンマ区切りで複数のファイルを指定することもできます
--relationships roles.csv:関係性設定用のCSVファイルを指定します。コンマ区切りで複数のファイルを指定することもできます。
neo4j-import:例文2
次のパターンは、デリミタ―をセミコロンにし、属性値はシングルクォーテーション(')、ラベルはバーティカルバー(|)に区切って配列にしています。
movies2.csv
movieId:ID;title;year:int;:LABEL
tt0133093;'The Matrix';1999;Movie
tt0234215;'The Matrix Reloaded';2003;Movie|Sequel
tt0242653;'The Matrix Revolutions';2003;Movie|Sequel
actors2.csv
personId:ID;name;:LABEL
keanu;'Keanu Reeves';Actor
laurence;'Laurence Fishburne';Actor
carrieanne;'Carrie-Anne Moss';Actor
roles2.csv
:START_ID;role;:END_ID;:TYPE
keanu;'Neo';tt0133093;ACTED_IN
keanu;'Neo';tt0234215;ACTED_IN
keanu;'Neo';tt0242653;ACTED_IN
laurence;'Morpheus';tt0133093;ACTED_IN
laurence;'Morpheus';tt0234215;ACTED_IN
laurence;'Morpheus';tt0242653;ACTED_IN
carrieanne;'Trinity';tt0133093;ACTED_IN
carrieanne;'Trinity';tt0234215;ACTED_IN
carrieanne;'Trinity';tt0242653;ACTED_IN
neo4j-import --into path_to_target_directory --nodes movies2.csv --nodes actors2.csv --relationships roles2.csv --delimiter ";" --array-delimiter "|" --quote "'"
neo4j-import:例文3
次のパターンは、ヘッダを別ファイルしたケースです。既に巨大なサイズのCSVファイルが存在し、後付けでヘッダを定義するようなケースで利用できます。
movies3-header.csv
movieId:ID,title,year:int,:LABEL
movies3.csv
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
actors3-header.csv
personId:ID,name,:LABEL
actors3.csv
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles3-header.csv
:START_ID,role,:END_ID,:TYPE
roles3.csv
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
neo4j-import --into path_to_target_directory --nodes movies3-header.csv,movies3.csv --nodes actors3-header.csv,actors3.csv --relationships roles3-header.csv,roles3.csv
neo4j-import:例文4
次のパターンは、ヘッダとCSVファイルがそれぞれ複数存在するようなケースです。例えば、Hadoopの処理では、結果ファイルが複数出力されるのが一般的です。
movies4-header.csv
movieId:ID,title,year:int,:LABEL
movies4-part1.csv
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
movies4-part2.csv
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
actors4-header.csv
personId:ID,name,:LABEL
actors4-part1.csv
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
actors4-part2.csv
carrieanne,"Carrie-Anne Moss",Actor
roles4-header.csv
:START_ID,role,:END_ID,:TYPE
roles4-part1.csv
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
roles4-part2.csv
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
neo4j-import --into path_to_target_directory --nodes movies4-header.csv,movies4-part1.csv,movies4-part2.csv --nodes actors4-header.csv,actors4-part1.csv,actors4-part2.csv --relationships roles4-header.csv,roles4-part1.csv,roles4-part2.csv
neo4j-import:例文5
上記の例文では、ラベルをCSVファイルの中の1フィールドとして定義していますが、それは必須ではありません。ラベルはファイル単位で指定することができます。それによって、さらに柔軟なデータの取り込みができます。
equels5.csv
movieId:ID,title,year:int
tt0234215,"The Matrix Reloaded",2003
tt0242653,"The Matrix Revolutions",2003
actors5.csv
personId:ID,name
keanu,"Keanu Reeves"
laurence,"Laurence Fishburne"
carrieanne,"Carrie-Anne Moss"
roles5.csv
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
neo4j-import --into path_to_target_directory --nodes:Movie movies5.csv --nodes:Movie:Sequel sequels5.csv --nodes:Actor actors5.csv --relationships roles5.csv
--nodes:Movie movies5.csv: movies5.csvのデータは、すべて「:Movie」というラベルで登録されます。
neo4j-import:例文6
ノードのラベルだけではなく、関係性のタイプもファイル単位で指定することができます。
movies6.csv
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
actors6.csv
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles6.csv
:START_ID,role,:END_ID
keanu,"Neo",tt0133093
keanu,"Neo",tt0234215
keanu,"Neo",tt0242653
laurence,"Morpheus",tt0133093
laurence,"Morpheus",tt0234215
laurence,"Morpheus",tt0242653
carrieanne,"Trinity",tt0133093
carrieanne,"Trinity",tt0234215
carrieanne,"Trinity",tt0242653
neo4j-import --into path_to_target_directory --nodes movies6.csv --nodes actors6.csv --relationships:ACTED_IN roles6.csv
--relationships:ACTED_IN roles6.csv: roles6.csvの関係性は、すべて「:ACTED_IN」タイプで設定されます。
neo4j-import:例文7
属性のタイプをヘッダに指定することもできます。
movies10.csv
movieId:ID,title,year:int,:LABEL
tt0099892,"Joe Versus the Volcano",1990,Movie
year:int年度を数字タイプとして指定しています。
actors10.csv
personId:ID,name,:LABEL
meg,"Meg Ryan",Actor
roles10.csv
:START_ID,roles:string[],:END_ID,:TYPE
meg,"DeDe;Angelica Graynamore;Patricia Graynamore",tt0099892,ACTED_IN
roles:string[]:タイプの属性を文字列のリストで取り込んでいます。
neo4j-import --into path_to_target_directory --nodes movies10.csv --nodes actors10.csv --relationships roles10.csv
neo4j-import:例文8
基本的にノードIDは、グラフデータベース全体で一意性を持つべきですが、一意の一連の番号をIDとして利用する場合、それぞれの異なるラベルの中で同じIDを持たせて利用することができます。次の映画と俳優のデータのIDは同じです。このIDは、関係性設定のための始点ノードID、終点ノードIDとして使えます。
movies7.csv
movieId:ID(Movie),title,year:int,:LABEL
1,"The Matrix",1999,Movie
2,"The Matrix Reloaded",2003,Movie;Sequel
3,"The Matrix Revolutions",2003,Movie;Sequel
movieId:ID(Movie): 「:Movie」ラベルでは、一連の番号をIDとして使うと宣言しています。
actors7.csv
personId:ID(Actor),name,:LABEL
1,"Keanu Reeves",Actor
2,"Laurence Fishburne",Actor
3,"Carrie-Anne Moss",Actor
personId:ID(Actor): 「:Actor」ラベルでは、一連の番号をIDとして使うと宣言しています。
roles7.csv
:START_ID(Actor),role,:END_ID(Movie)
1,"Neo",1
1,"Neo",2
1,"Neo",3
2,"Morpheus",1
2,"Morpheus",2
2,"Morpheus",3
3,"Trinity",1
3,"Trinity",2
3,"Trinity",3
neo4j-import --into path_to_target_directory --nodes movies7.csv --nodes actors7.csv --relationships:ACTED_IN roles7.csv
neo4j-import:例文9
次は、CSVファイルを割愛して構文だけを紹介しますが、1構文で複数のヘッダファイルと複数のCSVファイル、関係性のファイルを処理することができます。
neo4j-import --into path_to_target_directory --nodes movies4-header.csv,movies4-part1.csv,movies4-part2.csv --nodes actors4-header.csv,actors4-part1.csv,actors4-part2.csv --relationships roles4-header.csv,roles4-part1.csv,roles4-part2.csv
neo4j-importの様々なオプション
次は、neo4j-importで利用できる様々なオプションです。
--delimiter delimiter-character
属性値のデリミタ―のデフォルトはコンマですが、他の文字又はTAPなどが使えます
--array-delimiter array-delimiter-character
属性値自体を適切なデリミター区切って配列型の値にすることができます。デフォルトはセミコロンですが、タブや他の文字も使えます
--quote quotation-character
属性値の引用符のデフォルトは、ダブルクォテーションです。次は、すべて「"Go away", he said.」を表現しています。
①"""Go away"", he said."
②"\"Go away\", he said."
③'"Go away", he said.'
--id-type id-type
ノードIDは、「STRING, INTEGER, ACTUAL」の何れかを指定できます。デフォルト値は、「STRING」です。
--processors max-processor-count
インポートのために使えるプロセス数(スレッド数と同意)を指定します。デフォルトでは、CPUのコア数です。
--stacktrace
プログラムの実行過程を記録したスタックフレームをログとして残すことができます
--bad file-name
ここに任意のファイル名を指定してインポートに失敗したデータをログとして記録することができます。neo4j-importで関係性の設定は、ノードIDに依存して行います。ある関係性の設定で始点と終点のとちらかのノードIDが存在しなければ、インポートは失敗します。デフォルトのログファイルは、「not-imported.bad」です。
--bad-tolerance max-number-of-bad-entries
何件までのインポートエラーを許容するかを数字で設定できます。ここで設定した数字を超えるエラーデータが発生した場合はインポートを中止します。ある程度の数のエラーなら、無視してインポートの継続を優先し、グラフデータベース作成後、エラーデータを修正してLOAD CSVで完了することも可能でしょう。しかし、ソースデータに重大なミスがあったりして大量のエラーデータが発生した場合は、その原因を見つけてソースデータを取り直したほう良い場合もあるでしょう。デフォルトは1000件です。
まとめ
今回は、Neo4jへの大量データの取り込み方法を紹介しました。Neo4jの大量データ取り込みツールの特徴や使い方を理解し、ちょっと工夫するだけで、Neo4jの潜在的な可能性をさらに引き出すことができます。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



