
DifyでQ&Aアプリを作ったらJSONの取り扱いとイテレーションでハマった話 #dify #ai
はじめに
DifyはオープンソースのLLMアプリケーション開発プラットフォームです。GUIを用いてローコード・ノーコードでアプリを作ることが可能です。
今回、習作としてQ&AアプリをDifyで作ってみて、ハマった点を紹介したいと思います。記事タイトルにあるように、JSONの取り扱いと、繰り返し処理であるイテレーションでハマりました。ただ、もしかすると使い方が悪いのかもしれないので、ちゃんとした解決方法があれば教えていただけると幸いです。
作成したQ&Aアプリ
完成形は次の通りです。
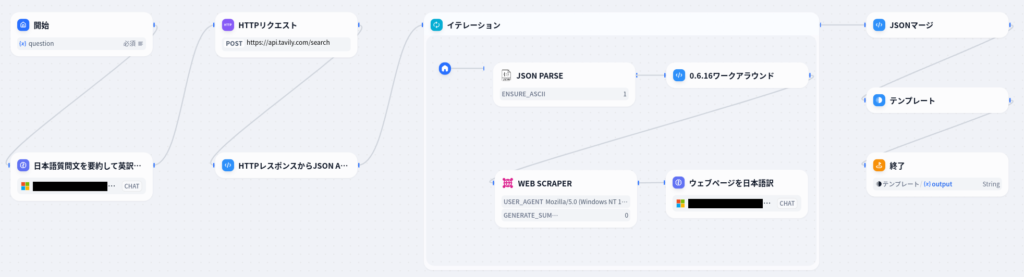
おおまかな動作としては、
- 日本語の質問文を受け取る。
- GPT-4で日本語の質問文を英訳・要約する。
- Tavilyでウェブ検索し、URLを5つ取得する。
- 取得した5つのURLそれぞれについて、ウェブページを取得し、GPT-4で内容を日本語訳・要約する。
- 結果を整形して出力する。
という形になっています。
もちろん、いきなりこの形を作ったのではなく、何度も試行錯誤しつつこの形となりました。ハマった点をご紹介していきます。
ブロック(ノード)の出力変数が表示通りに動かない
Difyでは各処理を行うブロック(ノード)を組み合わせ、そのブロック間でデータを受け渡してアプリを構築します。が、このブロック間でのデータの受け渡しがとてもわかりづらく、誤解を招く形で、大変厄介です。例えば、このDify組み込みのTavilyサーチの設定を見てください。
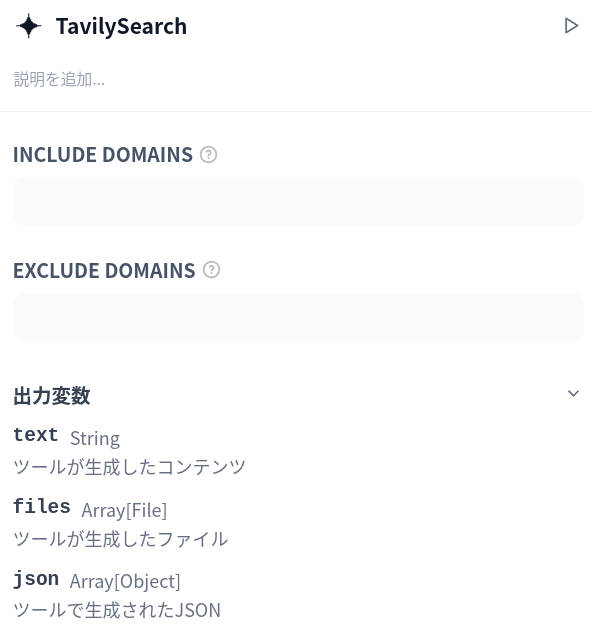
出力変数として text、files、json とあるので「textには検索結果のページ要約、filesには検索結果のページ全体、jsonに検索結果のURLなどのメタデータが入っているんだろうな」と予想するかと思います。ところが実際の結果を見てみると、files、jsonには何も入っておらず、textに検索結果のURLとページ要約が5件まとめて入っています。

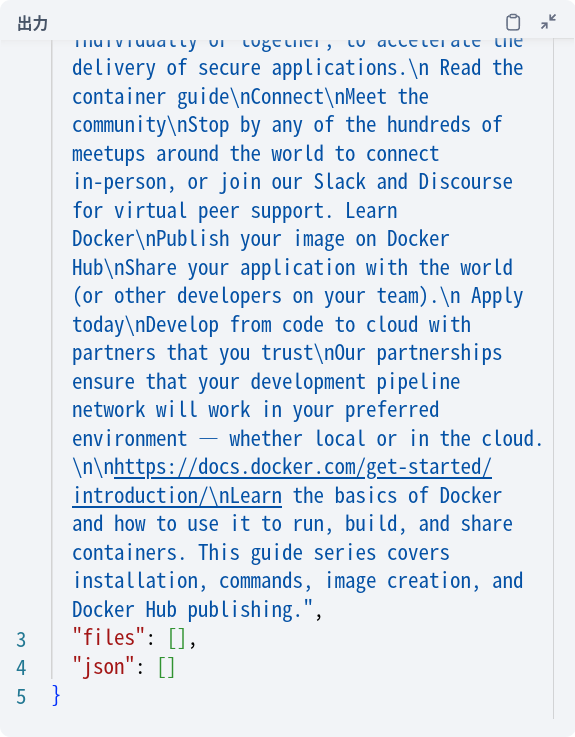
何か間違っているのか…?と思ったのですが、コードを見てもjsonをわざわざtextにひとまとめに入れています。
- https://github.com/langgenius/dify/blob/0.8.2/api/core/tools/provider/builtin/tavily/tools/tavily_search.py#L93-L94
- https://github.com/langgenius/dify/blob/0.8.2/api/core/tools/provider/builtin/tavily/tools/tavily_search.py#L124
想像した通りの files も json も使えないので、結果5件を個別に処理したい場合には分割するコードを書かなければいけません。
一方、任意のHTTPエンドポイントに任意のJSONリクエストペイロードを送信できる「HTTPリクエスト」を見てみましょう。
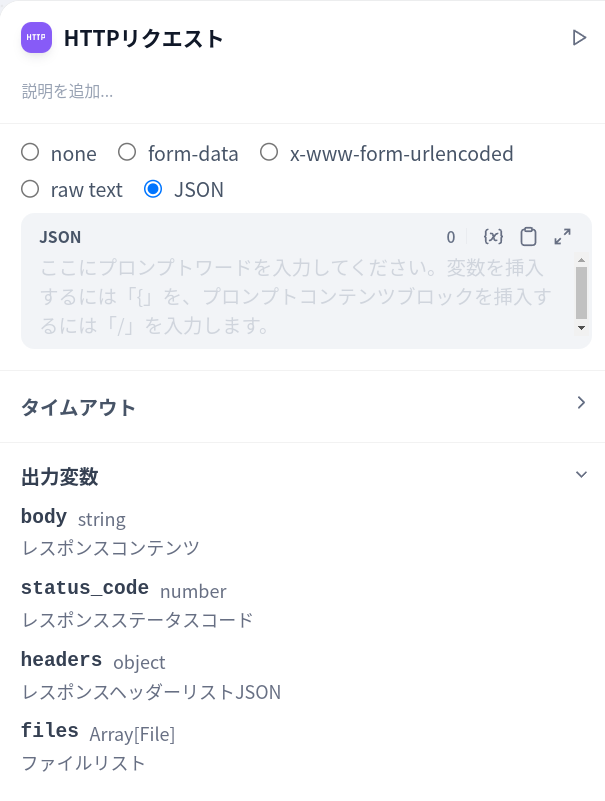
こちらでは表示されている出力変数の通りに値がセットされます。コードもそのようになっています。
実際の結果もそのようになっています。


bodyにJSONレスポンスペイロードが(文字列として)そのまま入っているので、これを処理すればよさそうです。本来であれば、JSONそのものとして取得できればよいのですが…次項で述べます。
JSONをブロック(ノード)間で受け渡ししようとすると処理が複雑化する
Difyには組み込みツールとしてJSON Parseがあり、これを使えば目的のデータを取り出せます。先の例を見てみましょう。
{
"status_code": 200,
"body": "{\"query\":\"what is docker?\",\"follow_up_questions\":null,\"answer\":null,\"images\":[],\"results\":[{\"title\":\"What is Docker? | GeeksforGeeks\",\"url\":\"https://www.geeksforgeeks.org/introduction-to-docker/\",
...
}
results の配列が取り出したいデータです。
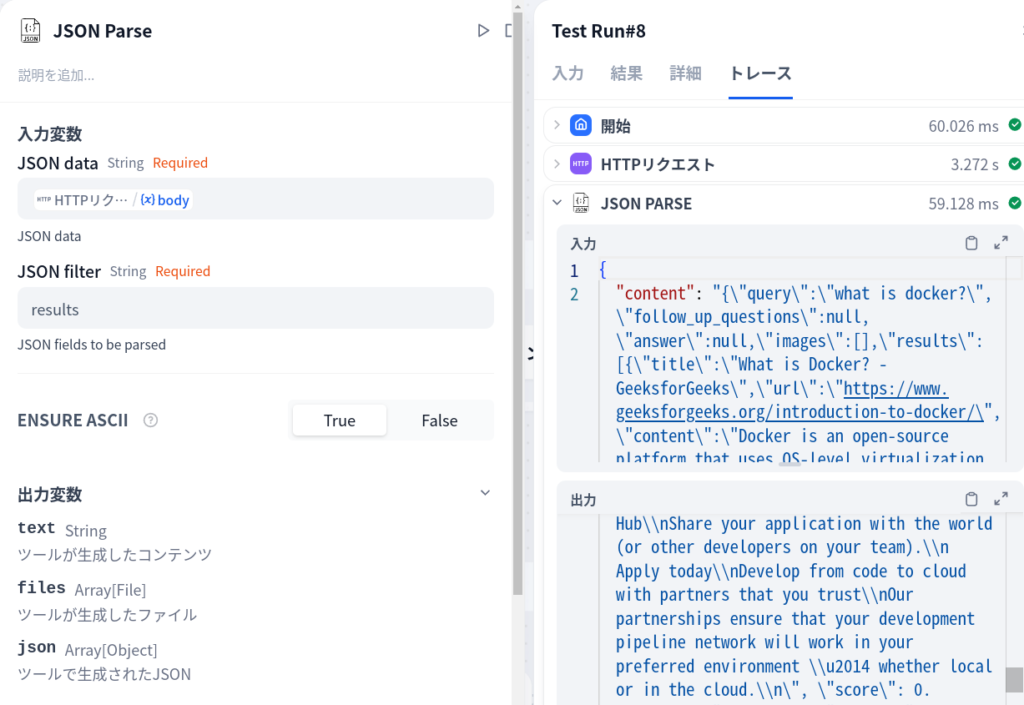
このようにJSON Parseで results を指定すれば、
{
"title":"What is Docker? | GeeksforGeeks",
"url":"https://www.geeksforgeeks.org/introduction-to-docker/",
...
}
が出力変数jsonに入っているように見えるのですが、実際はまたしても出力変数textに入っています。


コードを見ると、やはりJSONをわざわざ文字列に変換してtextとして返しています。JSON Parseは文字列を抽出するものであり、JSONの一部をそのまま取り出すものではないという仕様かもしれません。
仕方ないので次のようなPythonコードで result 配列を取り出し、Array[Object]として出力するようにしました。
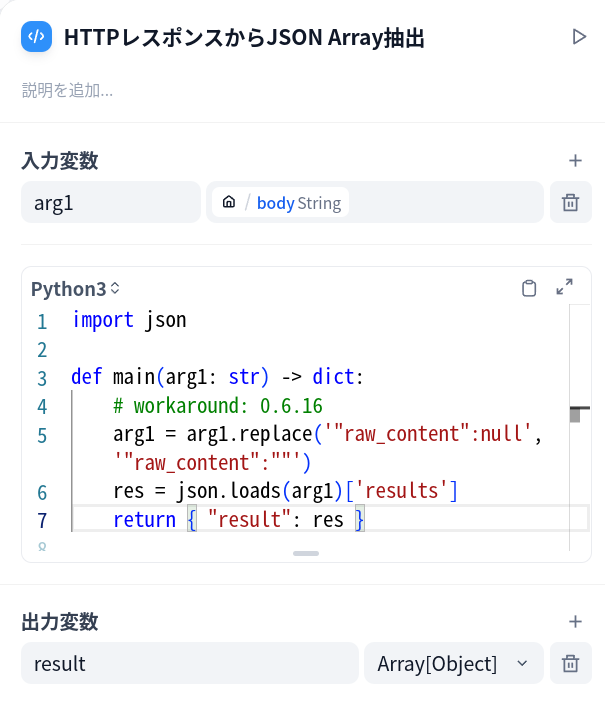
import json
def main(arg1: str) -> dict:
# workaround: 0.6.16
arg1 = arg1.replace('"raw_content":null','"raw_content":""')
res = json.loads(arg1)['results']
return { "result": res }
このうち
# workaround: 0.6.16
arg1 = arg1.replace('"raw_content":null','"raw_content":""')
この部分はDify 0.7.0以降では修正済みなので必要ありません。
- Code tool fails when null property exists in object
- fix: code tool fails when null property exists in object
また、Dify 0.7.0以前ではJSON Parseの結果がおかしくなる部分があります。
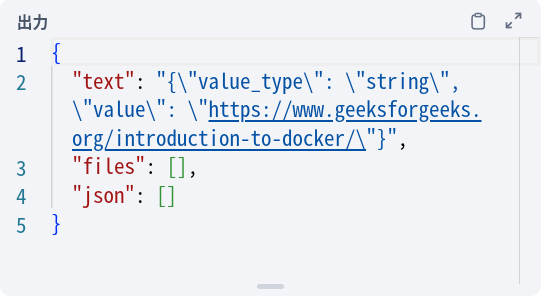
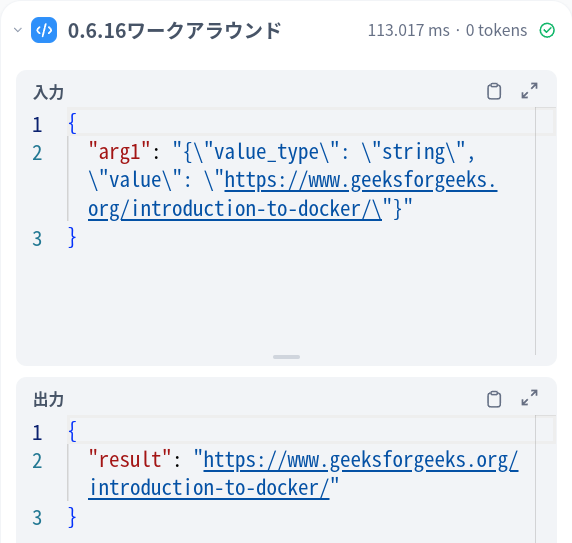
単に文字列を取り出そうとしているのに、なぜか "value_type": "string" うんぬんという型指定?みたいなものが一緒にくっついてきてしまっています。そのため次のようなPythonコードを間に噛ませています。
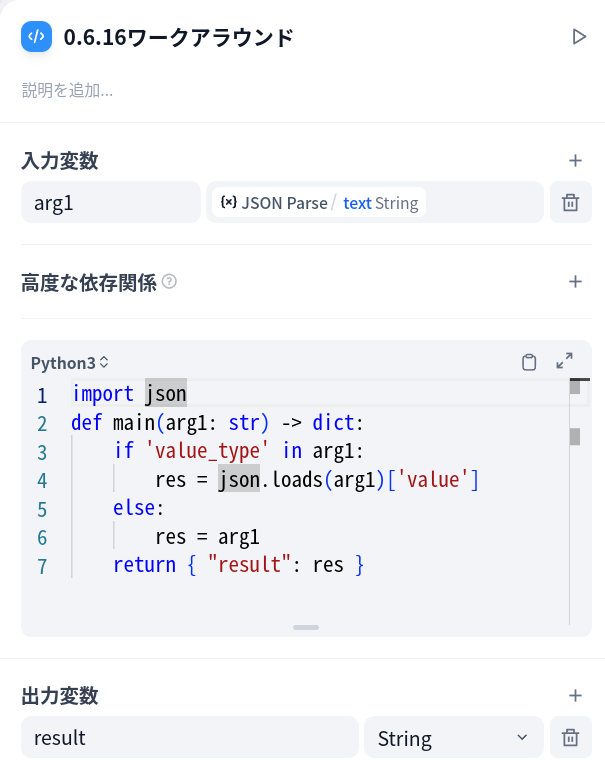
import json
def main(arg1: str) -> dict:
if 'value_type' in arg1:
res = json.loads(arg1)['value']
else:
res = arg1
return { "result": res }
Dify 0.7.0以降だと、このコードがあってもなくても問題ありません。ただ、どこでこの違いが起こったのかは見つけられませんでした。
このようにJSONの取り扱いにハマることが多いと感じました。修正済のものもありますが、仕様のように思われるものもありますし…。
イテレーションが並列(パラレル)実行されない
このアプリでは、Tavilyで取得した5つのURLそれぞれについて、ウェブページを取得し、GPT-4で内容を日本語訳・要約する部分を、イテレーションで実行しています。

ところが、このイテレーションは並列(パラレル)で実行されず、直列(シリアル)で実行されてしまいます。そのため1ループの処理完了におおざっぱに1分かかるとすると、このイテレーションを抜けるのに5分かかってしまいます。
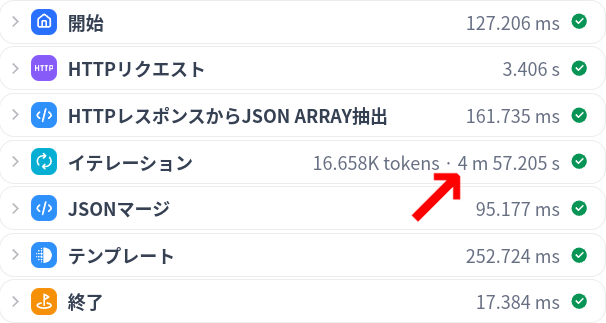
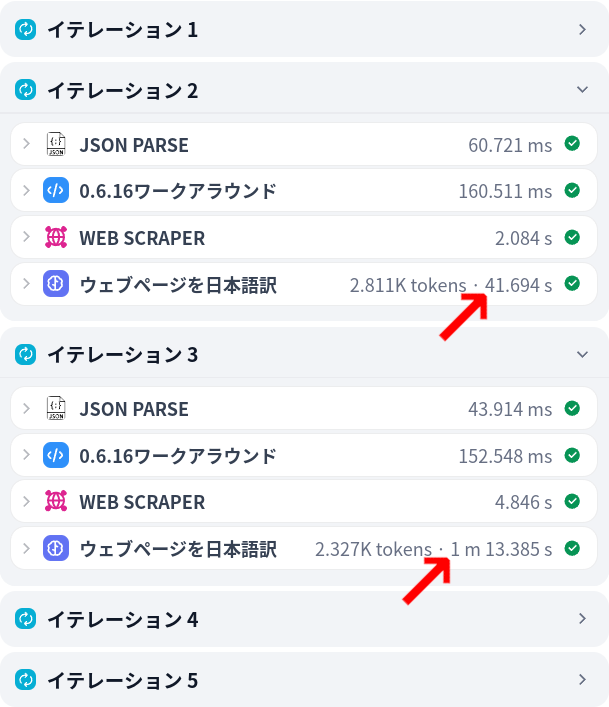
Dify 0.8.0でパラレル実行が実装されたのでは? と思われるかもしれませんが、イテレーションそのもののパラレル実行はまだ非対応です。> Add Parallel and Loop Module Functionality to Iteration Block
そのため現状ではこのアプリのユーザ体験は良くないのですが、イテレーションのパラレル実行は2024年Q4ごろの実装を目標としているそうなので、その後であれば良くなっていることを期待したいと思います。
まとめ
本稿ではDifyで習作としてQ&Aアプリを作成する中でハマった点を紹介しました。ローコード開発プラットフォームとしてとっつきやすい面はあるものの、直感的でない部分やコードを書いて回避しなければいけない点があるなど、コードを書けない人にとってはまだまだハードルが高いなと感じました。
Difyはまだまだ開発中の若いソフトウェアなので、本稿で紹介した以外にもバージョンアップによるデグレード(fix config of CODE_MAX_STRING_LENGTH)などもありました。
今回紹介したハマり点も、Difyのバージョンアップによって解消されていくかもしれません。引き続きDifyの動向を注視していきたいと思います。
Author
Chef・Docker・Mirantis製品などの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



