
【Event-Driven Architectureへの道】データメッシュ概要、イベント駆動型データメッシュ

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
データメッシュとは?
データメッシュは、2019年にZhamak Dehghani氏によって以下の論文で提唱された新たなデータアーキテクチャです。
「Data Mesh Principles and Logical Architecture
(データメッシュの原理と論理的なアーキテクチャ)」(2020年)Zhamak Dehghaniの二つの論文は、具体的なテクノロジーの提唱ではなく、テクノロジーに囚われないモデルの追求と、論理的なアーキテクチャの方向性が概念論として説明しています。
これまでのデータレイクやデータウェアハウス(DWH)のようにデータを1箇所に集めて管理するアプローチではなく、分散して管理するアプローチのことです。各ドメイン毎にデータを持ち、ドメインごとの各チームがドメイン間のデータの連携を原則に基づき統制することです。
データメッシュが注目されているのは、今までの1箇所に集めて管理するデータにおける課題があり、解決するアプローチとして期待されているからです。ビジネスや業務の分析のため1箇所に集められたデータは、集まってはいるもののドメインごとにバラバラに作成、共有、利用されており、これらを解決したい状況に陥っている企業が多いのが実情です。また、データを取得する各ドメインがデータに対しての責任を持たないため、データを活用しやすい形に整える作業するためにデータエンジニアが必要で、また、その負担に繋がっています。
データメッシュは、このような状態を改善するためのアプローチで、データを自ドメインごとに責任を持ちながら管理して、他ドメインに提供できるような、Data as a Productとして提供するための設計思想・アーキテクチャを提唱しています。
データメッシュは、このデータを分散して管理する上で、4つの主要原則に基づいており、各ドメインにあたる組織が、この原則をベースに規律やルールを設けることで、ビジネスにおけるデータの伝達する方法に役立ちます。
データメッシュアーキテクチャイメージ
データメッシュの4つの原則
原則1:ドメインのオーナーシップ
自ドメインのデータ責任は自ドメイン内に存在しており、自ドメインの変更または修正は、他ドメインの承認や許可は必要がないとされます。ただ、自ドメインから他ドメインにデータを公開する対象の選択が重要となりますが、ドメイン駆動設計を行う必要があります。業務をモデリングして、そのモデルとシステムを対応付けることで業務における変更または修正を行いやすい状態にすることが重要です。データの活用については、データが決められたルールに則って収集されているかが重要となります。データメッシュのように分散して管理されたデータアーキテクチャは、責任がドメインに分散されるため、各ドメインが、データに対するオーナーシップを正しく認識し、収集したデータの加工も各ドメインが担当します。データの規模や構造に精通している各ドメインが効率的にデータを整えられるので利用効果が非常に期待できます。
原則2:製品としてのデータ(Data as a Product)
他ドメインに提供するデータは、まるで自ドメインの実際のプロダクト、製品であるかのように取り扱うことが求められます。データを使用するユーザーに対して、そのデータがどこに存在するかを明確にして保証して、規制などの観点から安全性が担保し、アクセスするのに大変なデータだと思われないように、誰もが使いたいデータとして、自ドメインは他ドメインに提供するデータをプロダクトとして扱う必要があります。また、自ドメインで管理するデータの中には、自分たちのデータと関係ないデータも含まれています。このような状況でも、トラブルなどを防止するために自ドメインのオーナーシップは重要となり、データにアクセスしやすい、データが正確である、データの説明が充実している、などの考慮が必要です。
タイムスタンプ付きデータ:他ドメインに提供するデータは、タイムスタンプ付きにする必要があります。例えば、データをクエリする時に、そのクエリがいつ実行されたかに関係なく、一貫した結果を取得できるようにする必要があります。但し、自ドメイン内で到着するデータを他ドメインに提供する際に遅れて到着したデータの場合は一貫した結果を提供することが難しい場合があります。このような場合は、結果整合性などでも記載した通り、データを提供するタイミングをコントロールするこも必要です。
マルチモーダル「一つのデータに対する情報が複数(multi)の形式(mode)で存在しているデータ」なデータの提供:他ドメインからのデータアクセス方法としてはAPIが推奨されていますが、実運用ではそれだけに拘る必要はありません。一つのデータに対する情報が複数の形式で存在するため、提供形態は考える必要があります。例えば、大量のデータの一括提供を求めるケース、ストリーミングによる連続したデータの提供を求めるケース、少量のデータをリアルタイムで求めるケース(この場合はAPIが最適)など、利用ユースケースに応じて提供形態を変えるのが理想的です。
プッシュまたはプルによるデータ提供:プル(pull)では、REST API、SQL、GraphQL、クラウドストレージなどのタイプがあり、プッシュ(push)では、イベントストリームによる提供があります。
データの加工・修正:特定のユースケースや、データソースに合わせて分析に利用しやすいように、収集・整備され、理解しやすい説明を記述して提供します。
イベント駆動型データ:イベントストリームにより提供されるリアルタイムで構成されたデータなどを提供します。
データプロダクトの構成を詳しく見てみると、いろいろな段階を流れるさまざまな種類のデータがあり、運用データは、多くの場合、非構造化データとして取り込まれます。それが、前処理として、クリーンアップされ、イベントとエンティティに構造化されます。
上記のような必要な要素が含まれている製品プラットフォームの一例として、Starburst Platform があります。すべてのデータソースに単一のコントロール ポイントがあり、あらゆるデータにきめ細かいアクセス制御が可能です。Starburst Platformについては、次回のブログで紹介したいと思います。
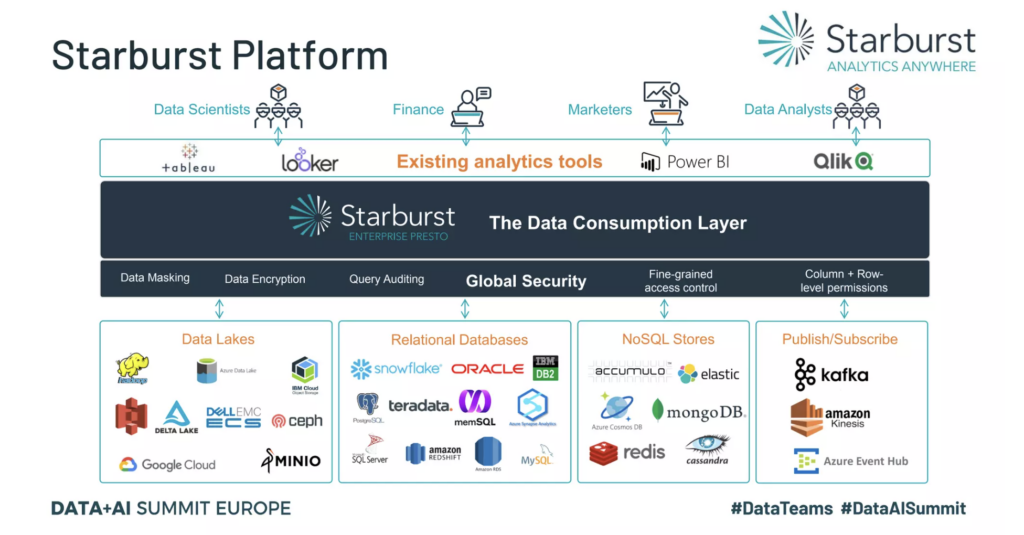
原則3:フェデレーション(連合)ガバナンス
自ドメインが自主性を持ってモデリングしたデータを構築して、提供するために、全ドメイン共通のポリシーと標準化ルールの定義などが必要です。また、ドメイン横断で均質な特性を持つデータプロダクトを整備・共有しながら継続的に運用していくためのフェデレーションガバナンスが重要です。例えば、[1] 幅広いテクノロジー、言語、API、セルフサービスツールなどを利用してデータメッシュを構築することが最善であるのか、であったり、[2] サポートが困難になったりしないのか、[3] データ処理要件のポリシーが組織横断で整備されているか、など適切に構築されるデータメッシュを考える必要があります。
言語、フレームワーク、APIのサポート:新しいものに捉われずに自ドメインにとって最も最善となるものを選択してサポートする。例えば、各ドメインで利用されるプログラミング言語やMySQLや、PostgreSQLなどのデータベース製品を利用して、シンプルかつ効率的に問題を解決できて、長期的にサポートやメンテナンスに追われることがないようにする。
データのライフサイクル要件の確定:データにはライフサイクルが存在します。収集するメタデータの指定方法や、低品質のデータを流さないSLA、データの公開プロセスなど(データが作成、更新、削除されるプロセス)を明確化する。
セキュリティーポリシーの確立:一般データ保護規制、消費者プライバシー保護、個人情報・機密情報の管理と削除など、テータを構築して提供するための重要な原則を取り決める必要がある。
クロスドメイン多義語の標準化:あるドメインのエンティティはlong、あるドメインは、string UUIDが使用されているなど、相互運用性を考えると共通の識別子を利用するための標準化を定義する。
セルスプラットフォームサービスの形式化:セルフサービスで使えるデータ管理ツールやプラットフォームも必要で、更にドメイン横断でデータ共有するための最低限のルールと統制された運用が求められます。
原則4:セルスサービスプラトフォーム
各ドメインのチームメンバーは、その全てがITの専門家ではないため、データプロダクトの特性を自ら担保するための使いやすいツールやデータプラットフォームが重要です。セルフサービスを構成するには、優先順位、既存ツールとフレームワーク、文化によって異なりますが、セルフサービスプラットフォームを選択するためのポイントがあります。
データと依存関係の検出:データメッシュに参加する全ドメインが利用可能なデータを簡単に参照、検索することが必要です。データの場所、API、メタデータ、オーナーなどを含めたデータカタログの提供が必要です。
データ管理コントロール:データのライフサイクルの管理を標準化しますが、リソース、ストレージ、リポジトリ、デプロイメント、パイプライン、モニタリング、メタデータの収集が容易であることが重要です。
アクセス制御:機密情報によるアクセス制御などの検討が必要です。どの環境でも当たり前のように利用されてますが、実際のデータに安全な方法でアクセスするための統一的な方法として、ドメイン チームによって管理される AWS IAM のロールベースのアクセスを使用するなどです。
構築におけるリソース:自ドメインで既に利用可能なリソースの最適化と追加リソースなどを検討が必要です。プラットフォームの部分は選択するツールやテクノロジによって大きく異なりますが、イベント駆動型のデータメッシュであればイベントストリームまたはトピックを比較的簡単に要求できる、Apache Kafka(または、Confluent)がまず最初に検討する、など環境に合わせて様々な検討項目が存在します。
SaaSでセルスサービス提供:データへのアクセス、データへの変換、データの場所などの使いやすさが満たされているSaaSなどの提供があります。
データメッシュアーキテクチャ
データ メッシュアーキテクチャは、ドメインチームが独自に自ドメインおよび他ドメインのデータ分析を実行できるようにするアプローチです。その中核となるのは、4つの原則に記載した各責任あるチームとその運用および分析データを備えたドメインです。ドメインチームは運用データを取り込み、独自の分析を実行するためのデータ製品として分析データモデルを構築します。また、他のドメインのデータニーズに応えるために、データ契約を伴うデータ製品を公開することを選択する場合もあります。
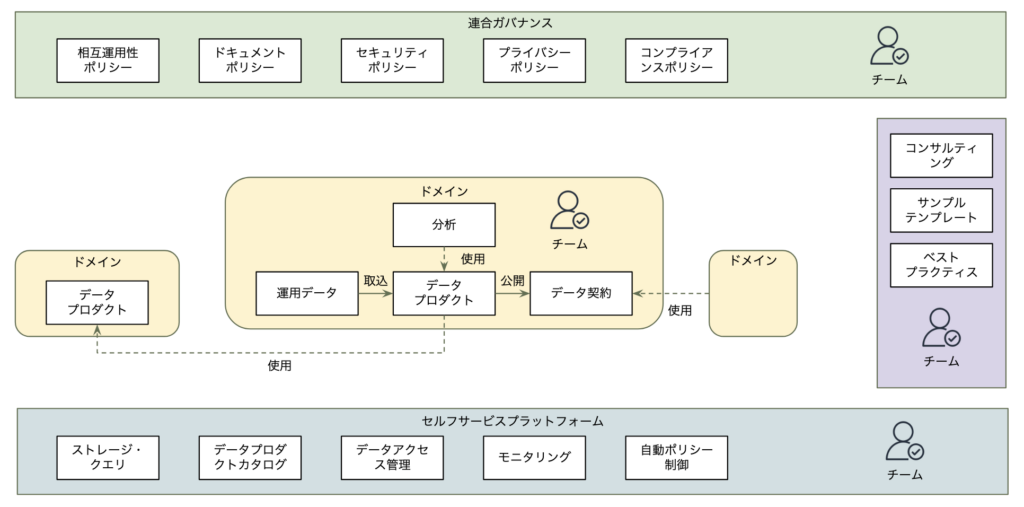
ドメインチームは、フェデレーテッド(連合)ガバナンスグループにおける相互運用性、セキュリティ、文書化標準などのポリシーに基づき、他のチームと合意形成します。更に、利用可能なデータ製品を検出、理解、使用する方法を把握した後、データを扱うプラットフォームチームが提供するセルフサービスのドメインに依存しないデータプラットフォームにより、ドメインチームは独自のデータ製品を簡単に構築し、独自の分析を効果的に行うことができます。更に、ドメインチームが有効利用を促進するために、分析データのモデル化、データ プラットフォームの使用、相互運用可能なデータ製品の構築と維持の方法について、推進チームがドメイン チームをコンサルティングします。
イベント駆動型データメッシュとは?
イベント駆動型データメッシュについて触れたいと思います。イベント駆動型データメッシュは、データメッシュ上にイベント駆動型アーキテクチャを組み込むことです。これにより、イベント駆動型の柔軟性と拡張性が得られ、データメッシュの機能をより小さいコンポーネントとして実装できるため、テスト、操作、保守が容易になるドメインが作られ、データメッシュ全体の価値がより高まります。
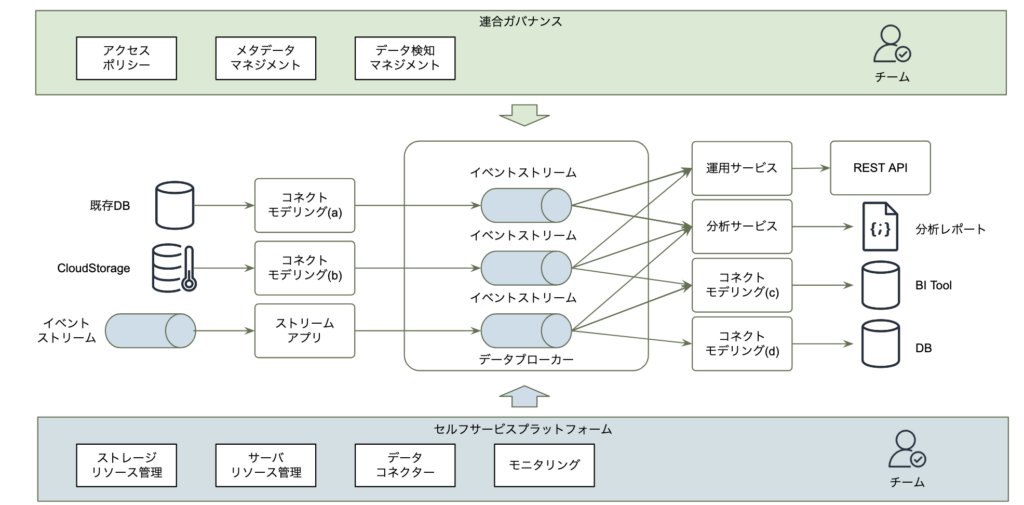
イベント駆動データメッシュの概要を以下の図に記載していますが、左から既存DBやCoudStorage、イベントストリームのデータを自ドメインの所有者がコネクタからデータブローカーに書き込みます。その後、データを他ドメインに提供するために、メタデータを検出するAPIエンドポイントを公開します。また、イベントストリームをサポートしていない既存のDBなどにセルフサービスコネクタを通してデータの修正、更新などを行います。運用サービスや分析サービスは、イベント駆動型の製品(Apache Kafkaなど)からデータを集計、調整して利用します。ガバナンスは、アクセスポリシー、データマネージメント、セルフサービスは、組織やドメインのシステム要件に合わせて利用、管理できるようにします。
まとめ
今回の記事では、最近注目されている、データを分散して管理するための「データメッシュ」の基本となる4原則を取り上げました。今までのシステム・データ基盤でおm当たり前に行っている内容も存在していましたが、体系化された4原則をドメイン横断で取り組む必要性や、ドメインごとに最適なデータ製品などを選択してData as Productとして提供することの重要性を感じていただけたかと思います。今回紹介したデータメッシュの設計思想・アーキテクチャを取り入れて、業務を効率化するために重要となるデータの有効活用を更に加速し、自社のサービスの向上や課題解決に繋がれれば大変幸いです。
お気軽にご相談ください
マイクロサービス・イベントドリブンについて
興味関心があり、ご相談があれば
以下よりお問い合わせください




