
MongoDB Atlasで全文検索を行う:データタイプのマッピング #MongoDB #NoSQL
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
データタイプのマッピング
MongoDB Atlas上で日本語を含む多言語の全文検索が可能になりましたので使い方などを連載しています。一連の記事は、[関連記事]を参照してください。今回は、データタイプのマッピングについてご紹介します。データタイプのマッピングとは、全文検索のインデックスを作成する際、対象のドキュメントのフィルドに対し、どのようなAtlasサーチのデータタイプを適用してインデックスを作成するかを設定する事を意味します。データマッピングは、全文検索の効率とデータサイズ、クエリの書き方にも影響します。検索要件に適したマッピングになってないと、意図した検索ができないこともあります。Atlasサーチでは、ダイナミックマッピングとスタティックマッピングの2つの方法を提供しています。
[関連記事]
ダイナミックマッピングとスタティックマッピング
ダイナミックマッピング
MongoDBのBSONのデータタイプに対して既定のAtlasサーチのデータタイプを自動的に付けてインデックスを作成します。この方式は、適用できるデータタイプの種類に制約があります。また、DISKを大量に消費し、パフォーマンス低下に繋がる可能性もあります。
- mappings.dynamic:true
- スキーマ未確定、Atlasのお試しなどの用途
- すべてのファセットタイプは使えない (String Facets/Numeric Facets/Data Facets)
[ファセットとは]
値又は範囲よって結果をグループ化し、グループごとにカウントを返すような用度に特化されたデータタイプです。例えば、特定の商品種類を含むドキュメントの数を把握するなど。
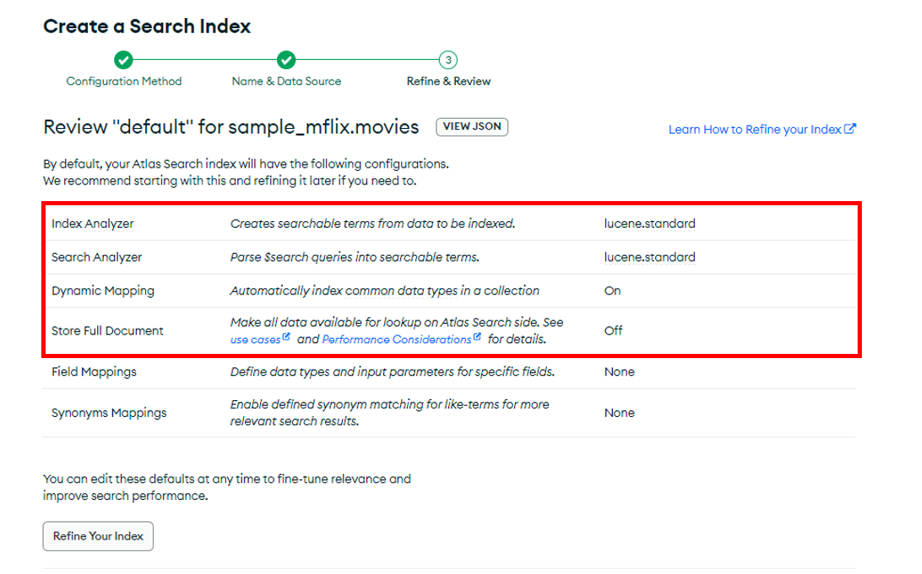
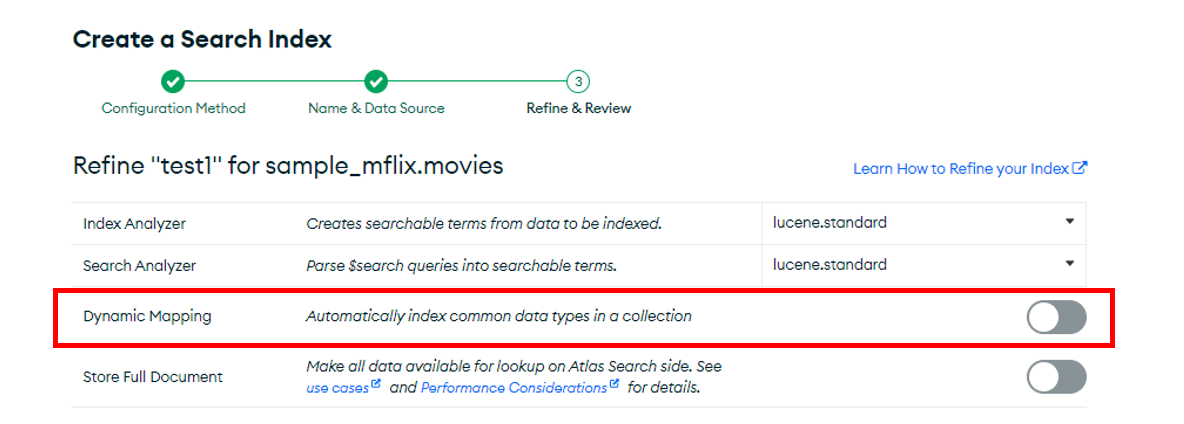
下図の赤枠内のコレクションレベルのオプションは、該当のコレクション全体に対して適用されます。ダイナミックマッピングはデフォルトでOnになっており、この状態でサーチインデックスを作成すると、ドキュメント内のすべてのフィルドがインデックス作成の対象になります(検索で使わないフィルドまでインデックス作成の対象になります)。
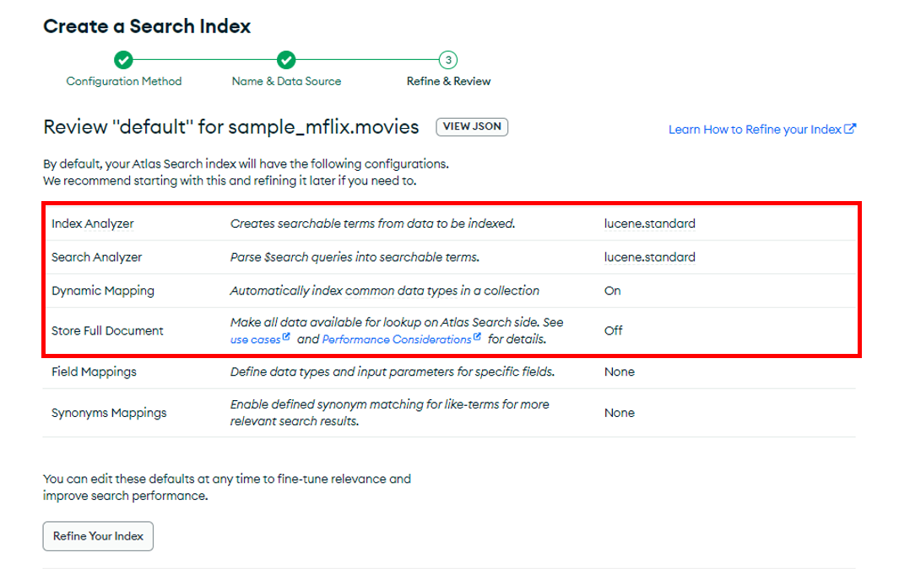
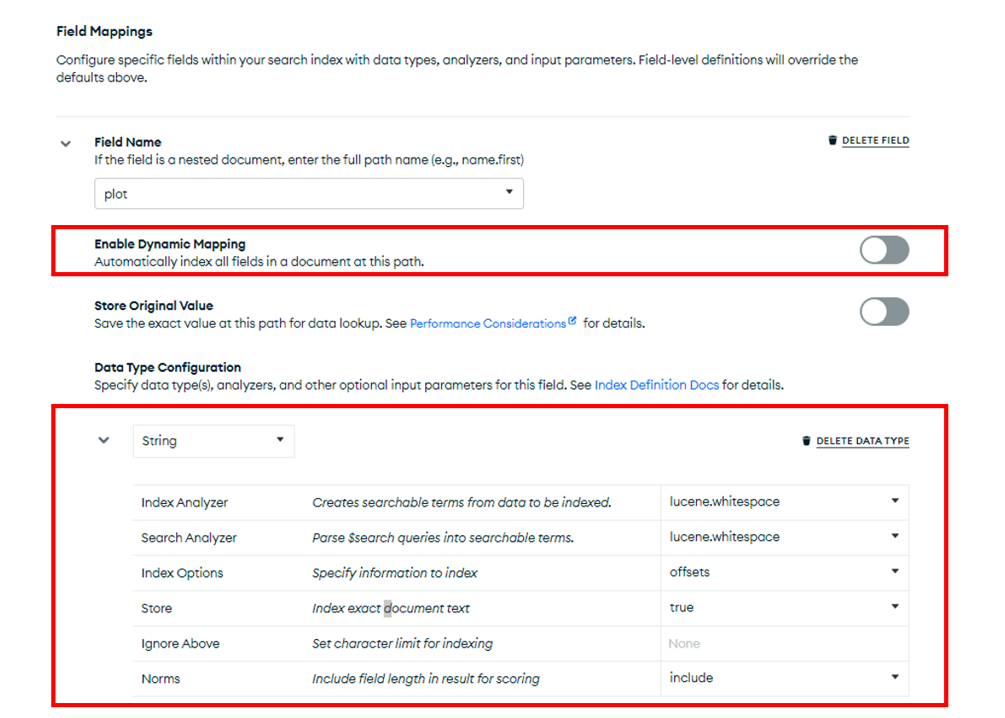
コレクションレベルのダイナミックマッピングを使わず、フィルドレベルのダイナミックマッピングを使って、検索対象のフィルドのみを絞ってサーチインデックスを作成することもできます。[Refine Your Index]をクリックすると、編集画面に切り替わります。そこで、コレクションレベルのダイナミックマッピングを停止し、例示のようにフィルドのパスを設定します。ここで設定したオプションは、コレクションレベルのオプション設定をすべてオーバライドします。例示では、plotに対してマッピングをしています。パスの設定は、key.subkeyのようにネストされたフィルドに対しても可能です。
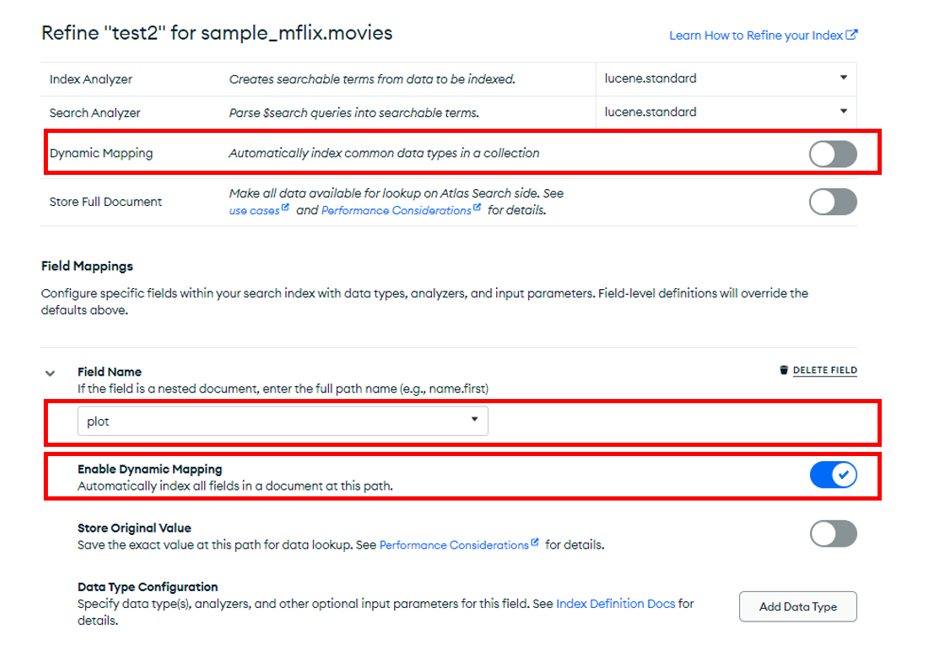
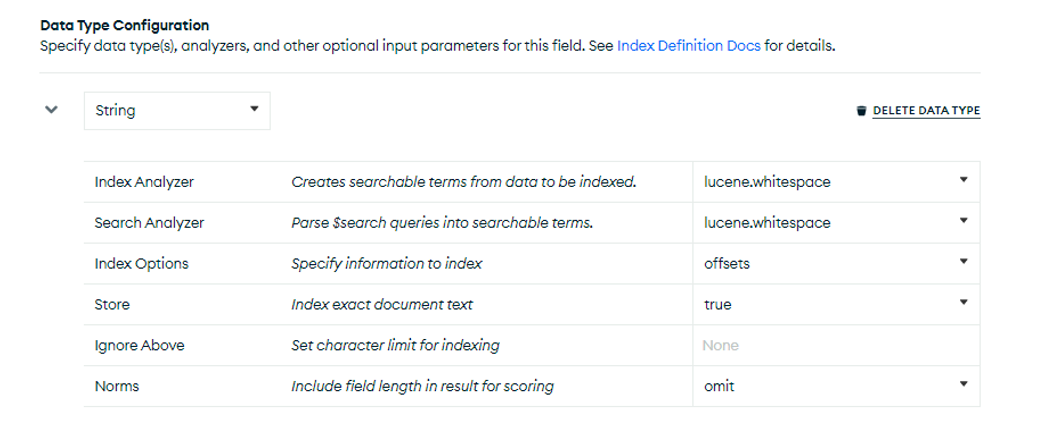
フィルドレベルのマッピングを利用する場合、適切なデータタイプを明示的に設定してください。サーチインデクスのデータタイプは検索効率および検索クエリの書き方にも影響します。用度に合わない設定をした場合、意図したサーチができない、又は無駄にインデックスサイズが大きくなるなどの問題を引き起こす可能性があります。ここでは、説明文をホワイトスペースで区切った単語単位の文字として解析し、インデックスを作成しています。
"plot": "The/story/of/the/life/and/career/of/the/famed/baseball/player,/Lou/Gehrig."
ダイナミックマッピングだから、明示的なデータタイプのマッピングは不要では、という疑問があり、データタイプのマッピングをしないパターンでインデックスを作成してみましたが、データタイプを設定しないと検索結果が得られませんでした。
オプションの詳細は、次を参照してください。
https://www.mongodb.com/docs/atlas/atlas-search/define-field-mappings/
インデックス作成ができたらクエリを実行してみましょう。
下記のクエリは、plotフィルドでbaseballという単語が含まれるドキュメントを検索し、5行まで表示しています。$projectでは、表示するフィルドの設定を行っています。
db.movies.aggregate([
{
$search: {
"index": "test1",
"text": {
"query": "baseball",
"path": "plot"
}
}
},
{
$limit: 5
},
{
$project: {
"_id": 0,
"title": 1,
"plot": 1
}
}
])
[
{
plot: 'A trio of guys try and make up for missed opportunities in childhood by forming a three-player baseball team to compete against standard children baseball squads.',
title: 'The Benchwarmers'
},
{
plot: 'A young boy is bequeathed the ownership of a professional baseball team.',
title: 'Little Big League'
},
{
plot: 'A trained chimpanzee plays third base for a minor-league baseball team.',
title: 'Ed'
},
{
plot: 'The story of the life and career of the famed baseball player, Lou Gehrig.',
title: 'The Pride of the Yankees'
},
{
plot: 'Babe Ruth becomes a baseball legend but is unheroic to those who know him.',
title: 'The Babe'
}
]
スタティックマッピング
ダイナミックマッピングを使わず、フィルドおよびデータタイプを明示的に設定してサーチインデックスを作成する方式です。
- mappings.dynamic:false
- 製品レベルの実装
下図のようにコレクションレベルのダイナミックマッピングは使用しません。
フィルドレベルのダイナミックマッピングも使用しません。フィルドのパスを明示的に設定し、適切なデータタイプを設定します。
インデックス作成ができたらクエリを実行してみましょう。
db.movies.aggregate([
{
$search: {
"index": "test2",
"text": {
"query": "baseball",
"path": "plot"
}
}
},
{
$limit: 5
},
{
$project: {
"_id": 0,
"title": 1,
"plot": 1
}
}
])
[
{
plot: 'A trio of guys try and make up for missed opportunities in childhood by forming a three-player baseball team to compete against standard children baseball squads.',
title: 'The Benchwarmers'
},
{
plot: 'A young boy is bequeathed the ownership of a professional baseball team.',
title: 'Little Big League'
},
{
plot: 'A trained chimpanzee plays third base for a minor-league baseball team.',
title: 'Ed'
},
{
plot: 'The story of the life and career of the famed baseball player, Lou Gehrig.',
title: 'The Pride of the Yankees'
},
{
plot: 'Babe Ruth becomes a baseball legend but is unheroic to those who know him.',
title: 'The Babe'
}
]
データタイプの制限について
MongoDBのBSONタイプに対するAtlasサーチのデータタイプは、マッピングのタイプによって制限があります。ダイナミックマッピングは、すべてのパーセントタイプを設定できません。
| BSON Type | Atlas Search Field Type | Dynamic Indexing? |
| Array | △ | |
| Boolean | boolean | 〇 |
| Date | date | 〇 |
| Date | dateFacet | ー |
| Double | number | 〇 |
| Double | numberFacet | ー |
| 32-bit integer | number | 〇 |
| 32-bit integer | numberFacet | ー |
| 64-bit integer | number | 〇 |
| 64-bit integer | numberFacet | ー |
| Object | document | 〇 |
| Object | embeddedDocuments (for array of objects) | ー |
| ObjectId | objectId | 〇 |
| String | string | 〇 |
| String | stringFacet | ー |
| String | autocomplete | ー |
△→配列の場合、要素がすべて配列タイプであることが求められます。データが含まれていたりすると、インデックスを作成しません。
まとめ
今回は、データマッピングの種類と使い方を簡略に紹介しました。データマッピングでは、データをどのように格納するかを指定します。サーチインデックスを作成する際に検索要件に合わせ、適切なデータタイプをマッピングすることは、検索効率の最適化のためにとても重要です。適切なデータタイプのマッピングができてない場合、意図したサーチができない、又は無駄にDISKを消費するような問題を引き起こす可能性があります。次回では、日本語の全文検索を紹介します。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



