
Neo4j version5 概要 #neo4j #グラフDB

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
Neo4jのメジャーアップデート バージョン5が2022年10月24日にリリースされました。バージョン5で強化された点、これまでのバージョンからの変更内容などを紹介しています。
この内容はNeo4j社の資料を翻訳・まとめたものです。


Neo4j 5が以前のバージョンから進歩した点を要約すると次のようになります。
1. パフォーマンス:データに対するより深い質問に、より迅速に答えることができます。
2. 無制限のスケーリング:スケールアウトやスケールアップに伴う手動作業やインフラコストが大幅に削減されます。
3. アジリティ:どこでも簡単にNeo4jをデプロイ、実行、管理できます。

Neo4jを使用したプロジェクトに関わる各関係者、予算担当者、ITアーキテクト、開発者、オペレータのどの視点から見ても、Neo4j 5は大いにメリットがあります。
- 機能が追加され、使いやすくなったにもかかわらず、以前と同様の費用で使用できます。
- スケールアウト・スケールアップしても安定したパフォーマンスが発揮されます。
- クエリの記述方法が洗練され、性能も桁違いに向上しました。
- データベースのコピーや管理にかかる労力が削減されました。

Neo4j 5は、わずかな労力で拡張可能な高性能グラフデータプラットフォームを提供するための複数年にわたる努力の集大成です。どのようなクラウドでも動作し、管理も非常に簡単です。


グラフのナビゲーションとトラバースがよりシンプルな構文になりました。
- リレーションシップのフィルタをインラインで記述できるようになりました。
- ラベルの表現により洗練された記述を採用しました(スライドには論理和、否定、グルーピング、繰り返しを例示しています)。
新しいクエリの記述についての公式ドキュメントはこちら

Neo4jはアンカーフィルタを含むクエリを動作させた場合、ホップ数が増加してもレスポンス時間はほぼ一定(O(1))となります。
1秒間に1~10個のクエリではなく1000個のクエリを処理できるので、人間やアルゴリズムにとって、劇的な創造性と生産性の向上がもたらされます。

K-Hopクエリのアルゴリズムが、深さ優先から幅優先へと変更され、性能が向上しました。
Neo4jは、あるベンチマークで中途半端な性能でしたが、Neo4j 5では8ホップで1000倍の性能の向上が見られました!
参考情報:Tigergraphは各エッジを一定方向にのみ保存します。もしシステムがエッジを一定方向にしか保存しない場合、K-hop、Path、アルゴリズムなどのクエリに対して誤った結果を生成することになります。

Neo4j 5では新たに次のインデックスに対応したため、テキスト検索の改善、クエリの改善、空間データの利用対応、クエリの高速化が図られます。
- リストや文字列配列の全文インデックス
- 範囲検索やプレフィックス・サフィックス検索など多くの述語に対応するRANGEインデックス
- 2D、3Dの座標に対応するPOINTインデックス
インデックスの拡張についての公式ドキュメントはこちら


スケールアウト・スケールアップが必要な理由とそれによって起こりうる課題についてまとめました。
- Neo4jの採用により、データベース数は増加し続けます。より多くのデータベースを導入することによって解決を図りますが、手作業の量とインフラコストがかさむことが懸念されます。
- 1秒あたりに処理しなければならないクエリ数は増加し続けています。同じデータベースのコピーを多く用意することによって解決を図ります。その際、コピーを自動的に管理し、インフラの柔軟性を維持する必要があります。
- 非常に大きなデータセットを扱うケースが生じてきますが、ハードウェアの限界があります。シャーディング(複数のデータベースへのデータ分散)を行うことによって解決を図ります。その場合、シャードを1つのデータベースのように扱えることが必要です。
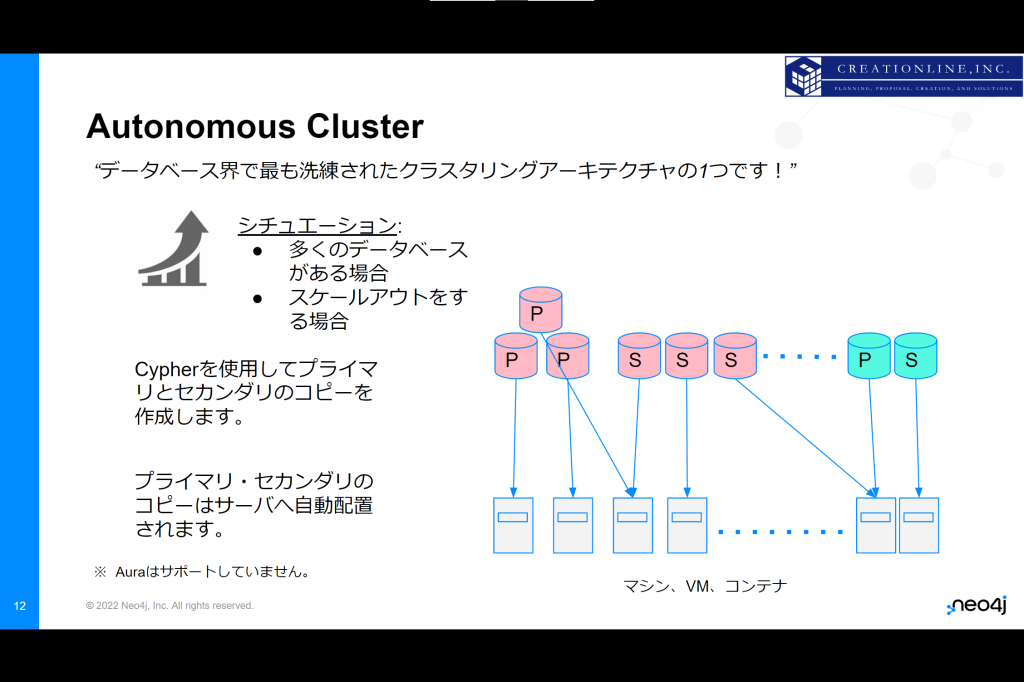
Autonomous Cluster(オートノマス クラスタ)
クラスタリングアーキテクチャとして、v4.xまではCausal Clusterがありましたが、これに代わってv5からはAutonomous Clusterが提供されています。
Autonomous Clusterでは、
・データベースのコピーをいくつ作るか
・いくつのサーバーに分散させるか
を決めるだけで自動的に、そして最適な状態でコピーが配置されます。そのため、クラスタの管理を自律化させることが可能です。

Autonomous Clusterはスケールアウトに対応しています。
サーバ台数を変更した場合でも、その状態に合わせてコピーはサーバーへ自動配置されます。
そのため、手作業の大幅な削減が可能であり、インフラを最大限柔軟に活用することができます。
また、複数データベースにも対応しております。

Fabricとは、グラフを複数のデータベースにパーティション化して分散したり、統合して問い合わせを行う方式のことです。
この機能により、単一のCypherクエリを使用して、同じ DBMS または複数の DBMS 内のデータを簡単に問い合わせできます。
v5では、複数のクラスタに存在するデータに対しクエリ実行する際のプロキシが不要となりました。
これにより、異なるクラスタにデータが存在していたとしてもデータ取得を容易に行えます。

Fabricを作成する場合、これまでは設定ファイルに記述する必要がありましたが、
v5ではFabricデータベース作成コマンドを使用してFabricを瞬時に作成できるようになりました。
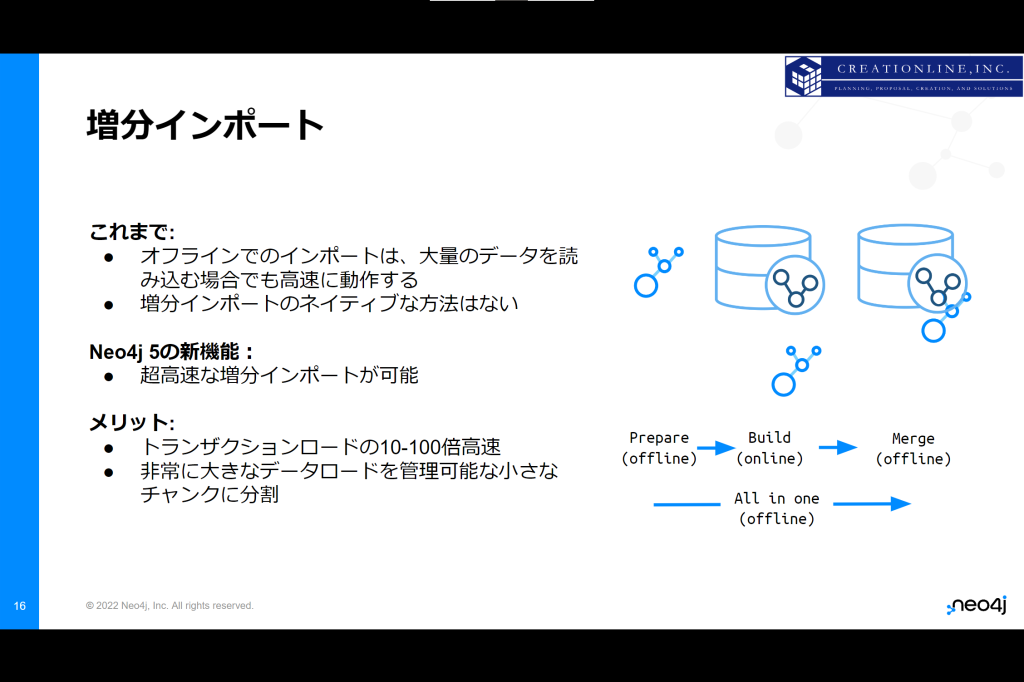
v5では増分インポートに対応しました。
これまでは増分インポートがなかったため、大量のデータを取り込む場合、1回のトラザクションで処理するデータの行数を制限し、ヒープメモリが溢れないようにする必要がありました。
v5では増分インポートに対応し、これまでのトランザクションを使ったデータロードに比べて10-100倍高速にデータのインポートが可能となっています。そして、大量のデータを取り込む場合でも分割してインポートができます。

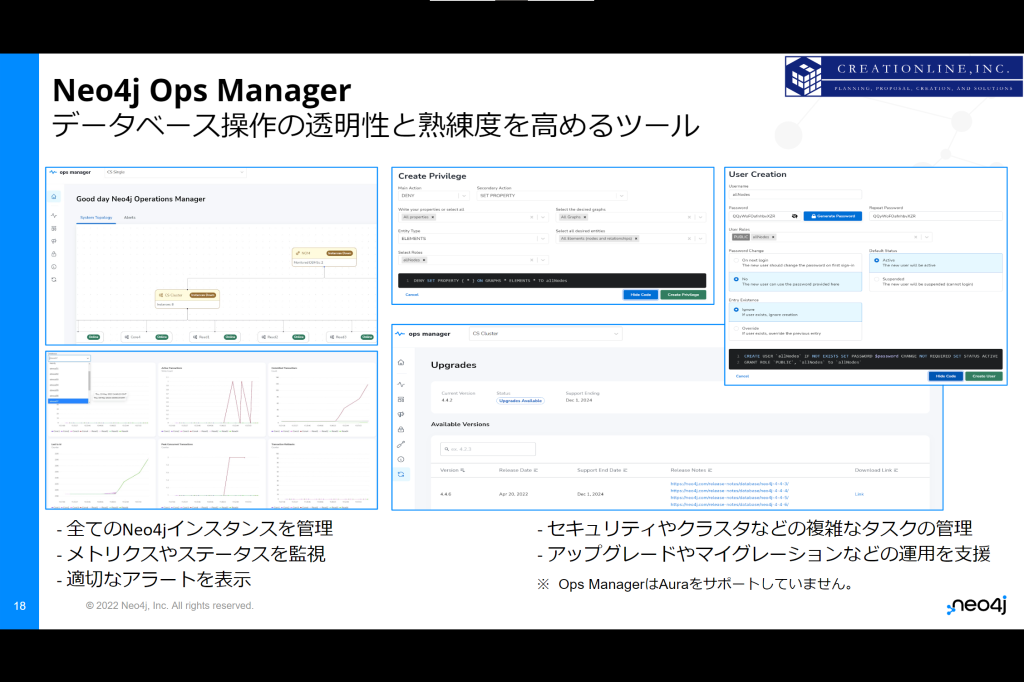
Neo4j Ops Managerは統合データベース管理ツールで、Neo4j Enterprise Edition 4.4 以降であれば使用することができます。
データベース、インスタンス、およびクラスタ全体の運用指標を総合的に見通すことができる管理制御用のUIコンソールです。

v5では月1回程度の頻繁なリリースが行われる予定です。
さらに、AuraとセルフマネージドのEnterprise Editionでの互換性が確保されています。
そのため、Auraで開発およびテストを行い、セルフマネージド環境で本番運用を行うことが可能ですし、もちろん逆パターンも可能です。
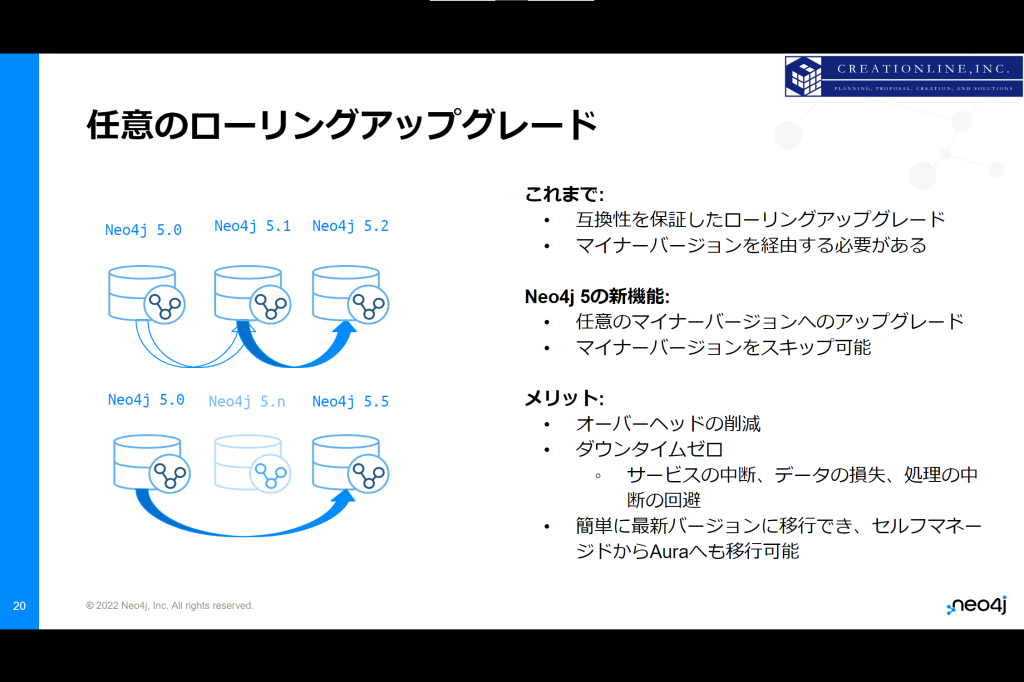
v5ではマイナーバージョンをスキップしてアップグレートができるようになりました。
そして、可用性と耐障害性を維持した状態で、クラスタのアップグレードが可能です。
アップグレードについての公式ドキュメントはこちら
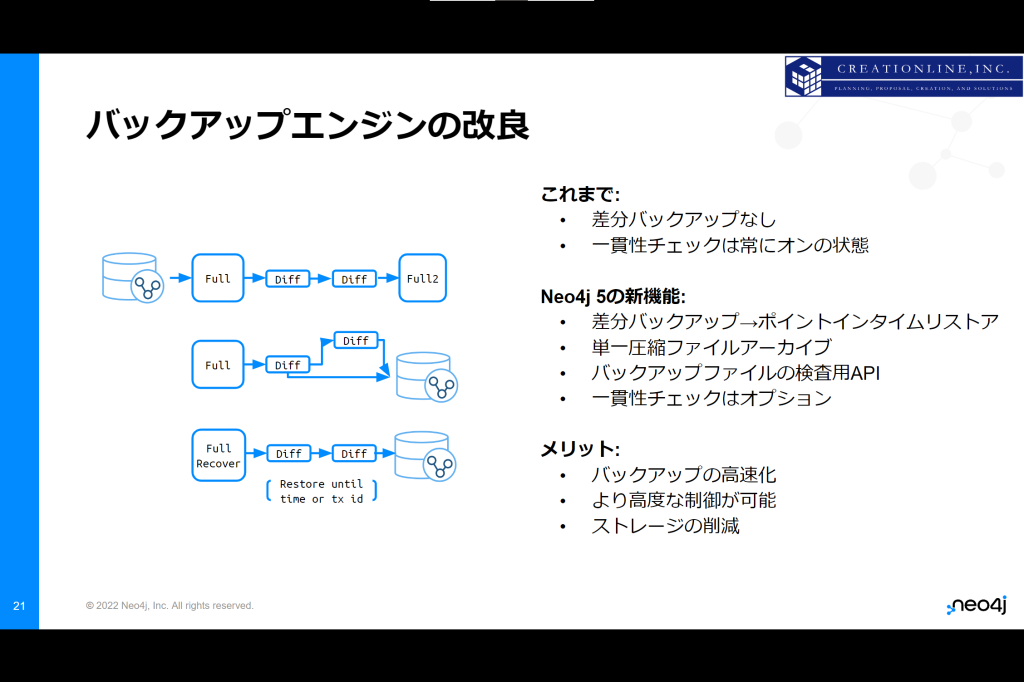
これまで用意されていたバックアップの種類は、フルバックアップと増分バックアップでした。
v5ではフルバックアップと差分バックアップが用意されています。
フルバックアップと差分バックアップを使うことで特定の時点またはトランザクションIDまで復元できます。
また、バックアップはファイルシステム内に単一の圧縮ファイルとして保存されるため、ストレージの削減が実現できます。
そしてオンラインバックアップおよび復元で使用されるneo4j-admin database backup/restoreコマンドは、バックアップファイルの検査と管理のための APIが備わっています。
さらにオンラインバックアップの場合、これまではデータベースバックアップの一貫性は自動的にチェックされていましたが、v5ではオプションとなりました。
バックアップについての公式ドキュメントはこちら





