
Cypher Query演習用のグラフデータベース #neo4j

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
この記事は、Neo4j v4.0(2020-01)に合わせて更新しています!
Neo4jのクエリ言語であるCypherがなかなか上達しないという悩みを聞くと、筆者は「グラフを忘れて思い切りRDB的な事をやってみたらどうですか」と答えます。大概、Cypherに十分慣れていない内に、パターンマッチのような新しい概念に取り組んでいるからです。
その演習用のデータベースとして開発したのが、「Cypher Query演習用のグラフデータベース」です。中身は、架空のECサイトの販売履歴です。
次の書籍は、色々試してみたことをまとめた結果です。

セットで開発したCypher Queryなどは、2015年10月29日、『Cypherクエリー言語の事例で学ぶグラブテータベースNeo4j』(著者:李 昌桓、監修:クリエーションライン株式会社、発刊:株式会社インプレスR&D)のようにリリースされました。
著作権について
販売履歴データベースの著作権はクリエーションライン社にありますが、ご利用において特に制限はありません。ご自由に利用してください。
グラフDBのスキーマ
グラフDBでは、スキーマをみれば、データベースの構成が一目瞭然に把握できます。
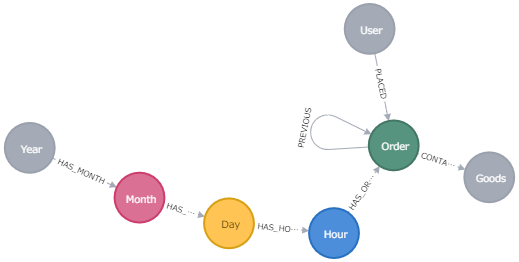
販売履歴データベースの構築
販売履歴データベースは、次のリンクからダウンロードできます。
ファイルを解凍し、内容を確認してみてください。LOAD CSVで「My販売履歴データベース」が作れるようになっています。
create-salesdb-ddl.txt # LOAD CSVでデータベースを構築するソースコード csv/ec-users-10000.csv # ユーザーデータ csv/ec-goods-10000.csv # 商品データ csv/ec-sales-10000.csv # 販売履歴データ
- CSVファイルを${NEO4J_HOME}/import配下にコピー
- Neo4jサーバーを起動
- create-salesdb-ddlを参考にして実行
販売履歴データベースの構築開始
Neo4jブラウザーから、次のように実行します。
制約及びインデックス作成
後続のCypherにインデクスが必要なものがあります。
CREATE CONSTRAINT cnt_uid ON (u:User) ASSERT u.uid IS UNIQUE;
CREATE CONSTRAINT cnt_gid ON (g:Goods) ASSERT g.gid IS UNIQUE;
CREATE CONSTRAINT cnt_oid ON (o:Order) ASSERT o.oid IS UNIQUE;
CREATE INDEX idx_day FOR (d:Day) ON (d.day);
ユーザーノードの作成
LOAD CSV WITH HEADERS FROM "file:///ec-users-10000.csv" AS line
CREATE (u:User { uid:line.uid, born:toInteger(line.born), gender:line.gender })
商品ノードの作成
LOAD CSV WITH HEADERS FROM "file:///ec-goods-10000.csv" AS line
CREATE (g:Goods { gid:line.gid, color:line.color })
販売履歴ノードの作成
//USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///ec-sales-10000.csv" AS line
CREATE (o:Order{oid:line.oid, number:toInteger(line.number),
price:toInteger(line.price),
date:substring(line.datetime,0,10),
datetime:line.datetime})
ユーザーと販売履歴間の関係性の作成
殆どのグラフDBでは、RDBとは違ってデータの結合関係を永続化します。
内部的にリレーションシップ(PLACED)の前後に始点と終点のIDを持ちます。
//USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///ec-sales-10000.csv" AS line
MATCH (u:User { uid:line.uid }), (o:Order { oid:line.oid})
CREATE (u)-[:PLACED]->(o)
販売履歴と商品間の関係性の作成
//USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///ec-sales-10000.csv" AS line
MATCH (o:Order { oid: line.oid}), (g:Goods { gid:line.gid})
CREATE (o)-[:CONTAINS]->(g)
年月日時間ノードの作成
WITH range(9,11) AS months, range(0,23) AS hours
FOREACH(month IN months |
CREATE (y:Year {year: 2014})
CREATE (m:Month {month: month})
MERGE (y)-[:HAS_MONTH]->(m)
FOREACH(day IN (CASE
WHEN month IN [1,3,5,7,8,10,12] THEN range(1,31)
WHEN month = 2 THEN
CASE
WHEN y.year % 4 <> 0 THEN range(1,28)
WHEN y.year % 100 <> 0 THEN range(1,29)
WHEN y.year % 400 <> 0 THEN range(1,28)
ELSE range(1,29)
END
ELSE range(1,30)
END) |
CREATE (d:Day {day: day})
MERGE (m)-[:HAS_DAY]->(d)
FOREACH( hour IN hours |
CREATE (h:Hour {hour: hour})
MERGE (d)-[:HAS_HOUR]->(h))))
年月日時間と販売履歴間の関係性の作成
//USING PERIODIC COMMIT 500
LOAD CSV WITH HEADERS FROM "file:///ec-sales-10000.csv" AS l
MATCH (y:Year { year:toInteger(substring(l.datetime,0,4))})-->(m:Month { month:toInteger(substring(l.datetime,5,2))})-->(d:Day { day:toInteger(substring(l. datetime,8,2))})-->(h:Hour {hour:toInteger(substring(l.datetime,11,2))})
MATCH (o:Order { oid:l.oid } )
CREATE (h)-[r:HAS_ORDER]->(o)
ユーザーの最新の販売履歴と過去の販売履歴間の関係性の作成
//2つ以上の販売履歴を持つユーザー
MATCH (u:User)-->(o)
WITH u.uid AS uname, count(o.oid) AS ocnt
WHERE ocnt > 1
//販売履歴を昇順に並べる
MATCH (u:User { uid:uname})-->(o)
WITH u.uid AS uname, o.oid AS oname
ORDER BY uname, oname
//ユーザー毎にオーダー番号リストを作成
WITH uname, collect(oname) AS oname
//RETURN uname, collect(oname) AS oname
//foreachの利用し、同ユーザーのすべの販売履歴の関係性を作成
FOREACH(i IN RANGE(0, size(oname)-2) |
FOREACH(order1 IN [oname[i]] |
FOREACH(order2 IN [oname[i+1]] |
MERGE (o1:Order {oid:order1})
MERGE (o2:Order {oid:order2})
MERGE (o1)<-[:PREVIOUS]-(o2))))
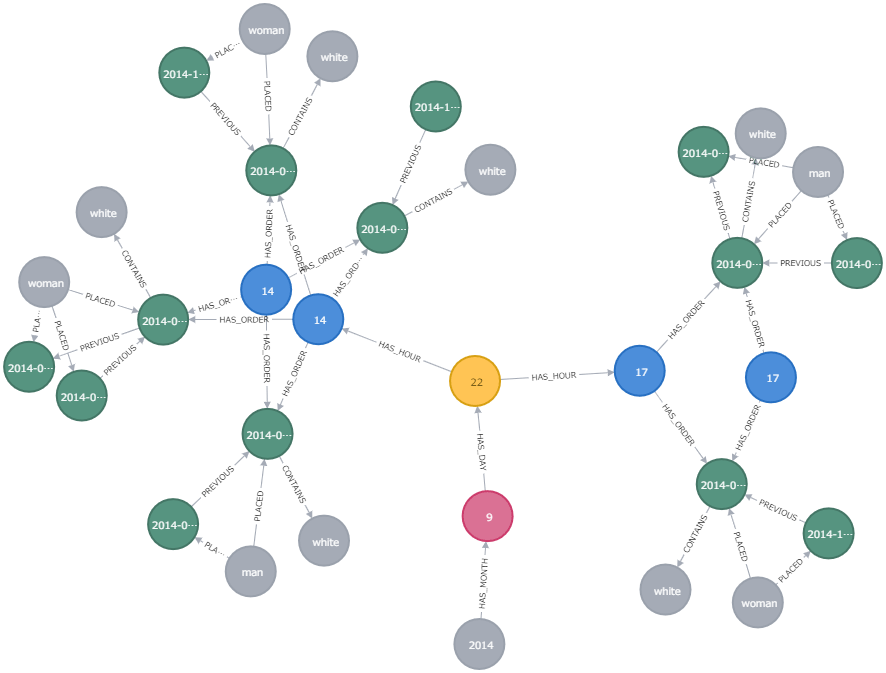
Neo4jブラウザーから接続し、次のCypher構文でグラフを出力してみてください。
Cypherにおいて、アスキーアートの線はRDBで言えばジョイン(結合)を意味します。
MATCH (y:Year {year:2014})-->(m:Month {month:9})-->(d:Day {day:22})-->(h)-->(o)--(all)
RETURN *
LIMIT 25
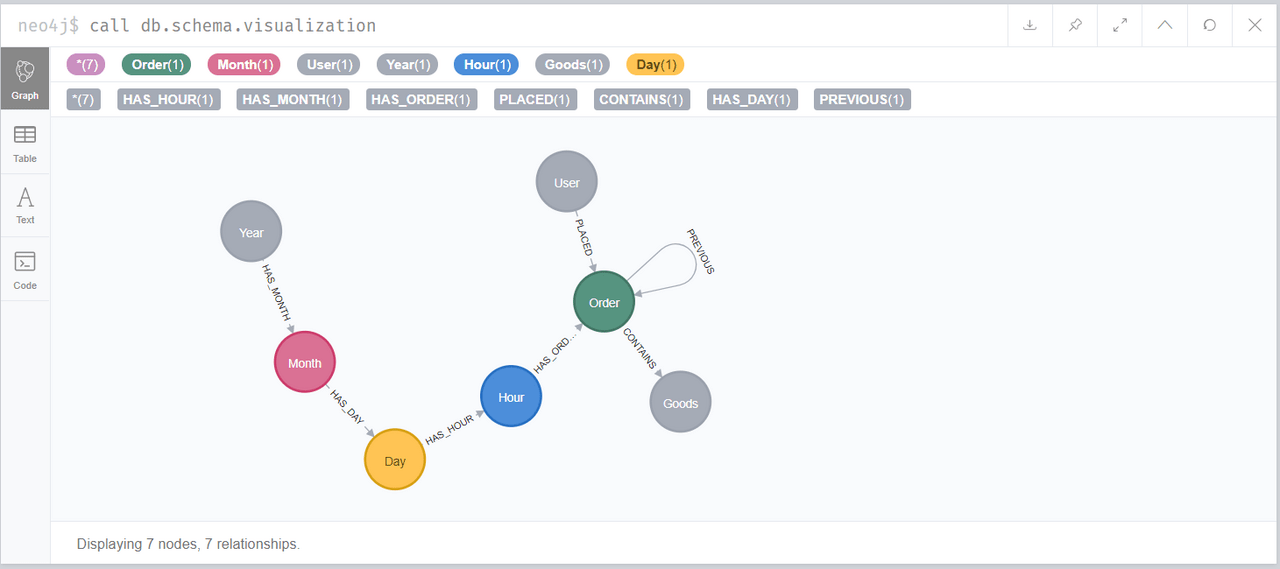
データベースのスキーマを出力してみましょう。
Neo4j v3.x
call db.schema
Neo4j v4.x
call db.schema.visualization
販売履歴データベースの利用方法
パターンマッチを意識せず、初歩的なデータ表示、集計、クロス集計などSQLを書くような感覚で、色々Cypherを書いてみることです。
Cypherは、汎用的なクエリ言語です。
2014年9月の総売上金額
MATCH (y:Year{year:2014})-->(m:Month{month:9})-->(d)-->(h)-->(o)
RETURN sum(o.number * o.price) AS 金額
金額
106485340
2014年9月の金曜日の「22時から翌日01時」までの売上金額
MATCH
(y:Year{year:2014})-->(m:Month{month:9})-->(d)-->(h)-->(o)
WHERE
(d.day IN [5,12,19,26] AND h.hour IN [22,23]) OR
(d.day IN [6,13,20,27] AND h.hour=0)
WITH y.year AS tyear, m.month AS tmonth, d.day AS tday, h.hour AS thour, sum(o.number * o.price) AS total
ORDER BY tday, thour
RETURN
tyear+"-"+tmonth+"-"+tday+" "+thour+"h" AS 日時,
total AS 金額
日時 金額
"2014-9-5 22h" 182824
"2014-9-5 23h" 223862
"2014-9-6 0h" 249152
"2014-9-12 22h" 91454
"2014-9-12 23h" 203124
"2014-9-13 0h" 122270
"2014-9-19 22h" 39428
"2014-9-19 23h" 36708
"2014-9-20 0h" 83610
"2014-9-26 22h" 138828
"2014-9-26 23h" 152066
"2014-9-27 0h" 160288
2014年9月の年齢別男女別の売上金額
かなり複雑なクロス集計が簡単に書けてます。
グラフDBは結合済みのデータから処理を開始します。SQLのように結合関係を紐解く必要がありません。
だからこそ、複雑な処理を高速に行うことができます。
MATCH (y:Year {year:2014})-->(m:Month {month:9})-->(d)-->(h)-->(o)<-[:PLACED]-(u)
WITH u, sum(o.number * o.price) AS total
WITH
CASE WHEN u.born > 1994 AND u.gender="man" THEN sum(total) END AS lt20m,
CASE WHEN u.born > 1994 AND u.gender="woman" THEN sum(total) END AS lt20w,
CASE WHEN u.born > 1984 AND u.born <= 1994 AND u.gender="man" THEN sum(total) END AS lt30m,
CASE WHEN u.born > 1984 AND u.born <= 1994 AND u.gender="woman" THEN sum(total) END AS lt30w,
CASE WHEN u.born > 1974 AND u.born <= 1984 AND u.gender="man" THEN sum(total) END AS lt40m,
CASE WHEN u.born > 1974 AND u.born <= 1984 AND u.gender="woman" THEN sum(total) END AS lt40w,
CASE WHEN u.born > 1964 AND u.born <= 1974 AND u.gender="man" THEN sum(total) END AS lt50m,
CASE WHEN u.born > 1964 AND u.born <= 1974 AND u.gender="woman" THEN sum(total) END AS lt50w,
CASE WHEN u.born > 1954 AND u.born <= 1964 AND u.gender="man" THEN sum(total) END AS lt60m,
CASE WHEN u.born > 1954 AND u.born <= 1964 AND u.gender="woman" THEN sum(total) END AS lt60w,
CASE WHEN u.born <= 1954 AND u.gender="man" THEN sum(total) END AS gt60m,
CASE WHEN u.born <= 1954 AND u.gender="woman" THEN sum(total) END AS gt60w
WITH collect(lt20m) AS lt20am,
collect(lt20w) AS lt20aw,
collect(lt30m) AS lt30am,
collect(lt30w) AS lt30aw,
collect(lt40m) AS lt40am,
collect(lt40w) AS lt40aw,
collect(lt50m) AS lt50am,
collect(lt50w) AS lt50aw,
collect(lt60m) AS lt60am,
collect(lt60w) AS lt60aw,
collect(gt60m) AS gt60am,
collect(gt60w) AS gt60aw
RETURN
head(lt20am) AS 男年齢20以下,
head(lt20aw) AS 女年齢20以下,
head(lt30am) AS 男年齢30以下,
head(lt30aw) AS 女年齢30以下,
head(lt40am) AS 男年齢40以下,
head(lt40aw) AS 女年齢40以下,
head(lt50am) AS 男年齢50以下,
head(lt50aw) AS 女年齢50以下,
head(lt60am) AS 男年齢60以下,
head(lt60aw) AS 女年齢60以下,
head(gt60am) AS 男年齢60上,
head(gt60aw) AS 女年齢60上
男年齢20以下 女年齢20以下 男年齢30以下 女年齢30以下 男年齢40以下 女年齢40以下 男年齢50以下 女年齢50以下 男年齢60以下 女年齢60以下 男年齢60上 女年齢60上
2,697,130 3,381,830 5,130,839 5,522,689 5,471,666 3,766,844 5,734,831 4,794,380 5,682,058 4,630,580 3,285,838 3,143,985
>上記のCypherは、「Cypherクエリー言語の事例で学ぶ グラフデータベースNeo4j」から抜粋しています
# まとめ
Cypherは、汎用性が高いクエリ言語です。論理構成力が優れているために、簡潔な構文で色んなことができます。
色々シナリオを作り、チャレンジしてみたください!
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



