
LangChainのRAGチュートリアルをやってみた(前編) #langchain #langgraph #rag #azure #openai
はじめに
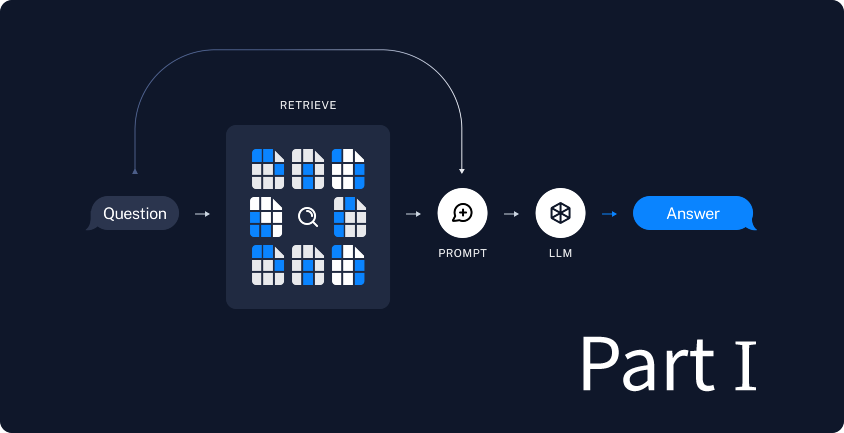
本稿では LangChain のチュートリアル Build a Retrieval Augmented Generation (RAG) App: Part 1 を Azure OpenAI を使って実施してみた記録です。
LLMのみに基づいた生成AIでは、LLMモデルが知らない内容を無理に回答しようとする場合、おかしな結果を生成してしまいがちです。例えば、社内のみで共有されている文章について知らないと回答するならまだしも、まったく間違った内容を生成されては困ります。
そこで、RAG (Retrieval Augmented Generation; 検索拡張生成) という検索技術と生成AIを組み合わせたアプローチの出番です。先の例で言えば、検索で得た社内文章をもとに、生成AIで回答を作成するので、正しい答えである可能性が高まります。
RAGについては他記事も参照してください。
- 【RAGがわかる】社内勉強会の内容を特別公開!
- 【CLくんブログ】Tokyo RAG user group Meetup で弊社エンジニアが講演しました!
- 【エンタープライズLLM】社内データを元に回答してくれるChatGPTを作るには? RAG・LLM技術を利用して価値ある企業独自のAIを作るためのテクニック
- Azure AI SearchでRAGしてみよう! チャットプレイグラウンドとWebアプリ編
LLMを使用したアプリケーションを開発するためのフレームワークであるLangChainのチュートリアルには簡単なRAGを実装する方法がありますので、このチュートリアルに本記事に独自の内容も含めてやってみましょう。
前提
本稿では次の環境を前提として進めます。
多少のバージョン違いは読み替えてください。また、次の有料リソースを利用します。
- Azure OpenAI
- gpt-4o (2024-08-06)
- text-embedding-ada-002 (2)
こちらも多少のバージョン違いは読み替えてください。
実施
ではチュートリアルを見ながら実際のコードを作成していきます。
このチュートリアルでは、特定のウェブページの内容に基いて、1回きりの質疑応答を行うLangGraphアプリケーションを作成しています。本記事の独自要素として、弊社の「スキルアップ支援制度」に対する質問に答えられるようにしてみましょう。回答は弊社 Tech blog の記事「みんなで育むスキルアップ支援制度・正式導入を決定しました」に記載された内容に基づくようにします。
モデルの設定
Azure OpenAI のモデルなどの必要設定項目はハードコーディングせず、python-dotenv を使って環境変数経由で読み込みます。
import os
from dotenv import load_dotenv
load_dotenv()
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model=os.getenv("AZURE_OPENAI_MODEL"),
model_provider="azure_openai",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
)
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
model=os.getenv("AZURE_OPENAI_EMBEDDING_MODEL"),
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
openai_api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
)
Azure の設定項目はややこしいので注意が必要です。 AZURE_OPENAI_MODEL は gpt-4o (2024-08-06) をAzureにデプロイした際の名前、 AZURE_OPENAI_EMBEDDING_MODEL は text-embedding-ada-002 (2) をAzureにデプロイした際の名前です。どちらもモデル名を入れてはいけません。
さらに、gpt-4o のバージョン(2024-08-06)と AZURE_OPENAI_API_VERSION は異なります。ここでは 最新の GA API リリース で示されている 2024-10-21 になります。
AZURE_OPENAI_ENDPOINT と AZURE_OPENAI_API_KEY は両者で共通です。別々に準備しても構いません。
ベクトルストアの設定
from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings)
ここでは例として、メモリ内に一時保存するだけのベクトルストア実装である InMemoryVectorStoreを利用します。
そしてエンベディングする際に用いる関数は先の AzureOpenAIEmbeddings で設定したモデルを使います。
データの取得
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://www.creationline.com/tech-blog/hr/76913",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("content_post", "tech_header")
)
),
)
docs = loader.load()
Beautiful Soupで取得したい内容のみを指定し、LangChainのWebBaseLoaderでそれを読み込んでいます。ヘッダやフッタ、サイドナビなどの共通パーツは除外するようにしています。
チャンク化(チャンキング)
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
separators=["\n\n", "\n", "。"],
chunk_size=100, chunk_overlap=50
)
all_splits = text_splitter.split_documents(docs)
取得したブログ記事全体を RecursiveCharacterTextSplitter.from_tiktoken_encoder でチャンク化(チャンキング)します。
チャンク化にはバイト対符号化(BPE; Byte Pair Encoding)としてOpenAIのtiktokenを利用するようです。tiktokenについては過去ブログ「ChatGPTやAzure OpenAI Serviceの課金単位「トークン」とは? 計算してみよう」もご覧ください。
デフォルトではチャンクの区切りが改行だけなので、日本語文には向きません。そのため、 separators=["\n\n", "\n", "。"] により、チャンクの区切りを改行と句点「。」とします。
RecursiveCharacterTextSplitterでは、tiktokenで割り出されたトークン数が chunk_size で指定した数を下回るまでチャンク化します。そのトークン数をここでは 100 としています。さらに、チャンクの前後を指定のトークン数だけチャンクに含めるようにもできます。ここではその前後の含みを 50 としています。
このチャンク設定は RAG の精度に大きな影響を与えるため指定が難しいです。既に挙げた通り、和文・英文でトークン化・チャンク化の設定が異なったり、取り込みたいデータによってもその指定が異なることも有り得るでしょう。ベストな数値例というものは難しく、実際に動かして見極めていくしかないかもしれません。
実際にこのコードから得られるチャンク化の結果は次の通りです。少し手で整形しています。
[
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='2025.03.25\nみんなで育むスキルアップ支援制度・正式導入を決定しました\n\nCL HRn-ogasawara81'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='クリエーションラインのCHROの小笠原です。'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='\n2024年7月からトライアル運用を始めた「スキルアップ支援制度」は、メンバー一人ひとりのスキル向上やチャレンジを後押しする制度として、有効に機能していることが確認できました'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='。また、トライアル期間中に発生したさまざまなケースにも、リーダー陣が会社全体の視点から議論を重ね、柔軟に対応することができました。'),
<snip>
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='。多くのメンバーがこの制度を活用し、自らのスキルを高めることで、「個人の成長が、会社の成長につながる」——そんな好循環を生み出していきたいと考えています'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='。'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='今後も制度の活用状況を見ながら柔軟にしくみをアップデートし、より多くの人が成長できる仕組みを整えていきます。'),
Document(metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='最後までお読みいただき、ありがとうございました。')]
]
おおむね日本語として1文=1チャンクとして処理できているようです。ちなみに先に挙げたチャンク化の設定や調整を行わない場合、複数の文の塊が1チャンクとなってしまっていました。
チャンクのエンベディングと保存
_ = vector_store.add_documents(documents=all_splits)
チャンクをエンベディングし、ベクトルストアに保存します。
ところで「エンベディング」と「ベクトル化」はどう違うのでしょうか? 「ベクトル化」とは、ある要素を行列(ベクトル)に変換することを表す一般的な概念です。一方で「エンベディング」は、ある要素を行列(ベクトル)に変換する際、その意味を反映するようにします。言い換えると似たものは近いベクトルになるように変換します。つまり、「エンベディング」は「ベクトル化」のいち概念ということになります。
RAG用プロンプトの読み込み
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
LangSmithに保存されているRAG用プロンプトを読み込みます。
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
これを翻訳すると、
あなたは質問回答タスクのアシスタントです。次の取得したコンテキストを使用して質問に答えてください。答えがわからない場合は、わからないとだけ言ってください。最大3つの文を使用し、答えは簡潔にしてください。
質問: {question}
コンテキスト: {context}
回答:
となります。「取得したコンテキスト」とは、ベクトルストアから検索して得られたチャンクになります。検索方法などは後述します。このように質問文に「コンテキスト」として補足情報を与えることで、回答の精度を上げるという狙いです。
アプリケーションの状態
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
class State(TypedDict):
question: str
context: List[Document]
answer: str
LangGraphアプリケーションのデータを制御する状態です。質問・コンテキスト(チャンク)・回答がそれに当たります。
取得ノード
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
ここではベクトルストアから簡単な類似検索 (similarity_search)を用いてチャンクを取り出しています。質問文(state["question"])をエンベディングし、そのベクトルに類似したベクトルのチャンクをデフォルトで上位4件を取り出します。ちなみにこの類似検索における上位n件を top_k と呼びます。
生成ノード
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
先に読み込んだRAG用プロンプトをテンプレートとして、質問文(state["question"])とチャンク(state["context"])を当て込んで gpt-4o に投入します。その回答文が response.content となります。
グラフの構成と実行
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
question="クリエーションラインの「スキルアップ支援制度」とは?"
result = graph.invoke({"question": question})
print(f'Context: {result["context"]}\n\n')
print(f'Answer: {result["answer"]}')
LangGraphについては過去ブログ「LangGraphをLLMなしでちょっと触ってみよう」「LangGraphとAzure OpenAIを組み合わせてみよう」を参照してください。
結果
次のようになりました。一部出力を見やすいように整形しています。
(langgraph) % ./60_rag_tutorial.py
Context: [
Document(id='cc2f4839-9b5d-4357-b04c-d589d9888b38',
metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='スキルアップ支援制度について'),
Document(id='b8eabdce-00b2-4cc9-94f5-e070a2c2fcb1',
metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='【本題に入る前に】スキルアップ支援制度とは何か?'),
Document(id='abe2e444-4dda-4c2e-b21b-74337a083bf3',
metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='スキルアップ支援制度とは、スキル開発費用の一部を会社が負担することで、メンバーの皆さんのスキル開発を奨励することを主目的とした制度です'),
Document(id='f6c5ac02-c03a-45a3-8bb2-3d5fc82ffda0',
metadata={'source': 'https://www.creationline.com/tech-blog/hr/76913'},
page_content='\n2024年7月からトライアル運用を始めた「スキルアップ支援制度」は、メンバー一人ひとりのスキル向上やチャレンジを後押しする制度として、有効に機能していることが確認できました')
]
Answer: クリエーションラインの「スキルアップ支援制度」とは、スキル開発費用の一部を会社が負担し、メンバーのスキル向上やチャレンジを奨励する制度です。2024年7月からトライアル運用が始まりました。この制度はメンバー個々のスキル向上を後押しするものです。
コンテキスト(得られたチャンク)を利用し、より確からしい答えを得ることができました。
ちなみにコンテキストが空の場合は次の答えになります。
Answer: 申し訳ありませんが、クリエーションラインの「スキルアップ支援制度」についての具体的な情報は提供されていません。
検索して得られたコンテキストが重要な意味を持っていることがわかります。
全ソースコード
# https://python.langchain.com/docs/tutorials/rag/
import os
from dotenv import load_dotenv
load_dotenv()
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model=os.getenv("AZURE_OPENAI_MODEL"),
model_provider="azure_openai",
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
)
#-----
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
model=os.getenv("AZURE_OPENAI_EMBEDDING_MODEL"),
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
openai_api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
)
#-----
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
#-----
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://www.creationline.com/tech-blog/hr/76913",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("content_post", "tech_header")
)
),
)
docs = loader.load()
#-----
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
separators=["\n\n", "\n", "。"],
chunk_size=100, chunk_overlap=50
)
all_splits = text_splitter.split_documents(docs)
#-----
_ = vector_store.add_documents(documents=all_splits)
#-----
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
#-----
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
#-----
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
question="クリエーションラインの「スキルアップ支援制度」とは?"
result = graph.invoke({"question": question})
print(f'Context: {result["context"]}\n\n')
print(f'Answer: {result["answer"]}')
まとめ
本稿では LangChain のチュートリアル Build a Retrieval Augmented Generation (RAG) App: Part 1 を Azure OpenAI を使って実施してみました。チュートリアルの内容をそのまま使うのではなく、弊社 Tech blog の記事「みんなで育むスキルアップ支援制度・正式導入を決定しました」に記載された内容に基づいて、「スキルアップ支援制度」について答えられるようにしました。
RAG (Retrieval Augmented Generation; 検索拡張生成) という検索技術と生成AIを組み合わせたアプローチにより、生成AIが知らない内容についても別のデータソースを検索し、回答を生成できるようになりました。このデータソースの格納と検索には、チャンク化(チャンキング)や、エンベディングというベクトル化の一種といった技術が用いられています。過去の記事(Azure AI SearchでRAGしてみよう! チャットプレイグラウンドとWebアプリ編)では意識せずに使っていた要素を本稿ではより詳しく見てみたので、以前よりRAGについての理解が深まったと思います。
今回は1回きりの質疑応答だったので、次回のチュートリアル Part 2では、内容を引き継いだ状態で繰り返し質疑応答ができるように改良していきます。
Author
Chef・Docker・Mirantis製品などの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



