
dotData Enterpriseを使用してKaggleの回帰問題を解いてみた
はじめに
dotData EnterpriseはAutoMLのツールで、テーブルデータを対象とした特徴量エンジニアリングに強みを持っています。今回はKaggleのデータをそのままdotData Enterpriseに適用する方法を紹介し、どのような動きをするのかや、実務に落とし込むためにはどのように使っていけばいいかについて考察してみます。
使ってみた
準備
使用データ
使用データはKaggleのCar Price Prediction Multiple Linear Regressionを使用します。欠損値はないですが、カテゴリーデータが多く、前処理がやや面倒なデータセットになっています。データセットの情報は以下の通りとなっています。
- Car_ID→ユニークID
- Symboling→リスク評価値。値が小さいほど安全で大きいとリスクが高いと考えられる。−3~+3の範囲のカテゴリー変数。
- carCompany→自動車会社名。カテゴリー変数
- fueltype→自動車の燃料タイプ、ガソリンまたはディーゼル。カテゴリー変数
- aspiration→自動車に使用される吸気装置。カテゴリー変数。
- doornumber→自動車のドアの数。カテゴリー変数。
- carbody→自動車のボディタイプ。カテゴリー変数
- drivewheel→駆動タイプ。カテゴリー変数
- enginelocation→自動車のエンジンの場所。カテゴリー変数
- wheelbase→自動車のホイールベース。数値変数
- carlength→車の全長。数値変数
- carheight→車高。数値変数
- curbweight→車重。数値変数
- enginetype→エンジンタイプ。カテゴリー変数
- cylindernumber→シリンダーの数。カテゴリー変数
- enginesize→エンジンのサイズ。数値変数
- fuelsystem→自動車の燃料システム
- boreratio→ボア比。カテゴリー変数
- stroke→エンジン内部のストロークまたは体積。数値変数
- compressionratio→圧縮比。数値変数
- horsepower→馬力。数値変数
- peakrpm→最大回転数。数値変数
- citympg→市内燃費。数値変数
- highwaympg→高速燃費。数値変数
- price→自動車価格。数値変数
このデータから特徴量を作成して、price(自動車価格)を予測します。今回は練習のため、このデータから3割ほどテストデータとしてあらかじめ切り出しておきました。
学習環境の構築
大まかなdotData Enterpriseの作業の流れは以下の通りとなります。
- プロジェクトの追加
- データのアップロード
- 訓練
- 評価
- 予測
1. プロジェクトの追加
まずはdotData Enterpriseにログインすると、これまで作成したプロジェクトが表示されます。今回は新規にプロジェクトを作成するので、「プロジェクトを追加」を押します。
適当なプロジェクト名と、どの程度このプロジェクトに容量を割り当てるか入力し、プロジェクトを追加します。
先ほどのプロジェクトの一覧の画面に戻りますので、そこから先ほど作成したプロジェクトを選択します。
2. データのアップロード
使用するデータのアップロードをします。左バナーのデータセットをクリック後に、データソース画面に移動をクリックします。
ファイルアップロードをクリックします。
ドラックアンドドロップでファイルをアップロードします。今回は事前に訓練データとテストデータを分けているので、それらをアップロードします。アップロードができたらスキーマを登録します。
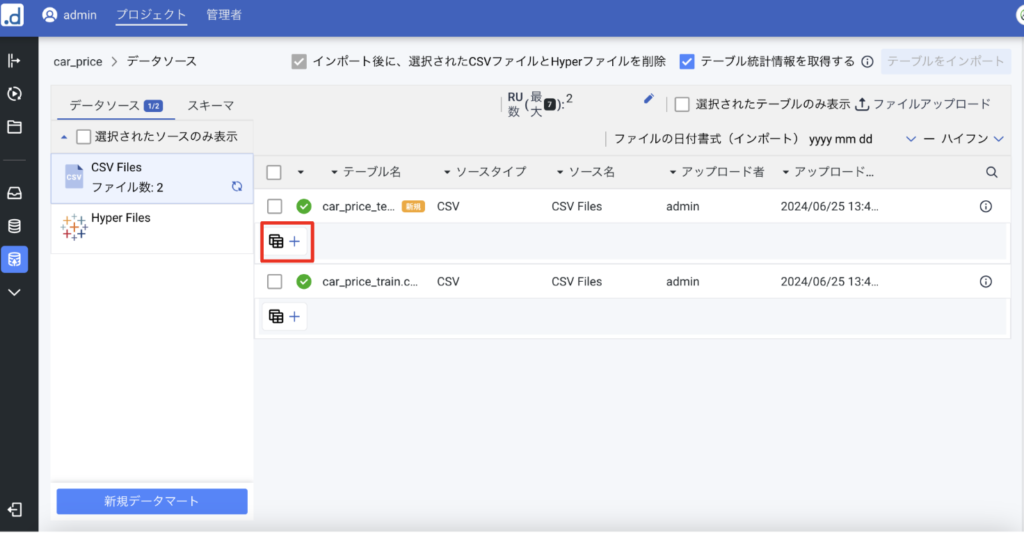
こちらの画面ではそれぞれのカラムのデータ型(分析データ型)を登録します。スキーマ名と分析データ型を選択して登録して「スキーマを保存」をクリックします。
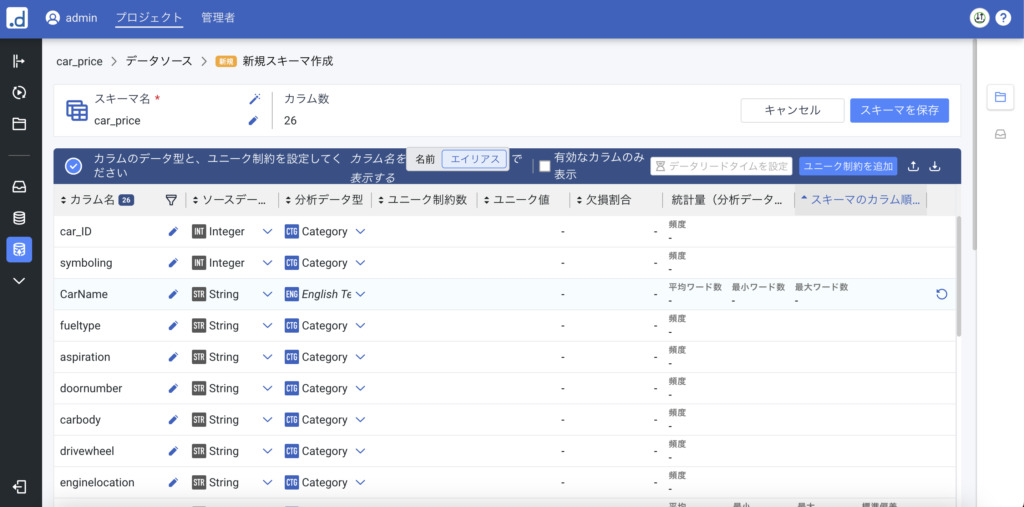
カラムの構造が同じであればスキーマが自動で割り当てられます。
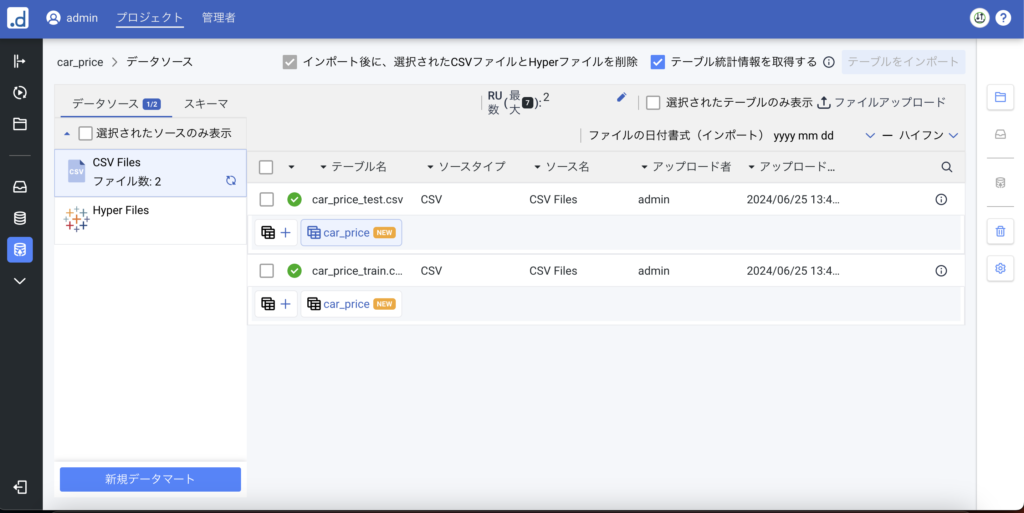
アップロードしたファイルにチェックを入れ、テーブルをインポートをクリックします。
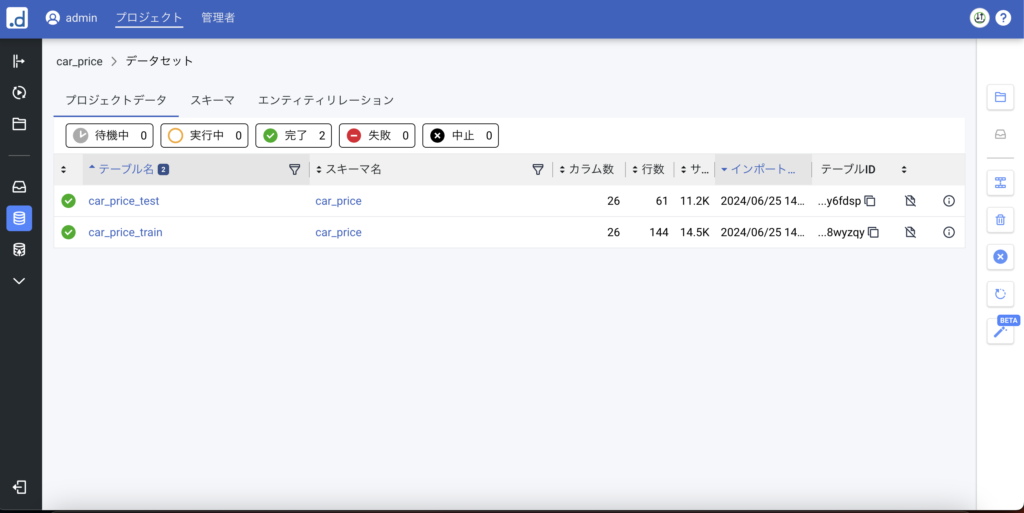
データセットをクリックして、データが登録されていることを確認します。
3. 訓練
プロジェクトのトップ画面から「ユースケースを追加」をクリックします。
今回は「回帰」を選択します。
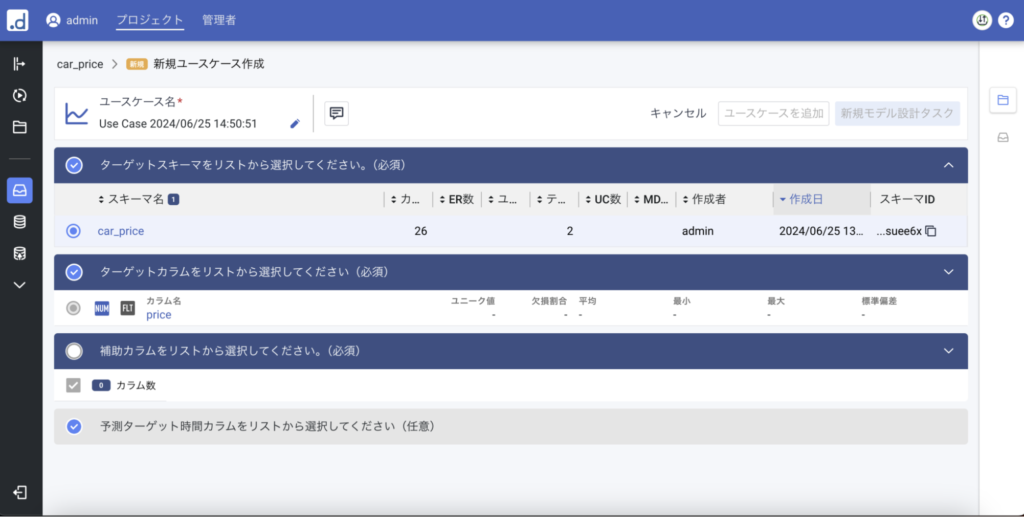
先ほど作成したスキーマと、ターゲットカラムとして目的変数を選択します。
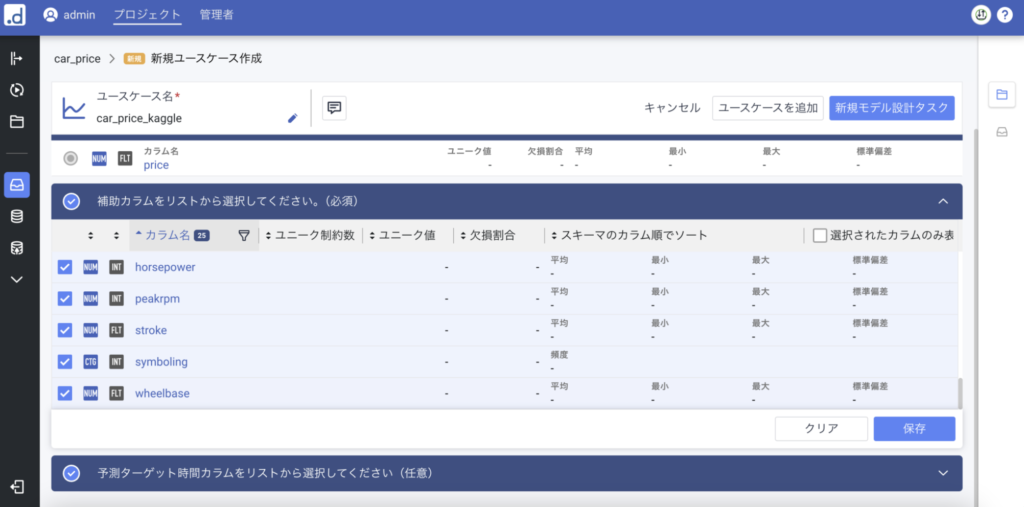
補助カラムとして、テーブル内で説明変数として使用したいカラムを選択します。
今回はCar_ID以外全てにチェックを入れます。
ここまでできたら「新規モデル設計タスク」をクリックして学習の準備を進めます。
また、ターゲットテーブルとして訓練に使うテーブルを選択します。追加でテーブルをインポートし、結合することができます。そのときは、先ほどのデータセットの準備のときと同様の手順でテーブルをインポートしたのちに、こちらからエンティティを張ることができますが、今回は対象外なので割愛します。
データスロットの設定から、検証データの割合(あらかじめ検証データを切り出しておき、それをテーブルとしてここで指定することも可能)の設定や、外れ値の除去など訓練の諸条件をこちらで指定することができます。今回は特に指定せずデフォルトのまま(訓練データ割合=70%)とします。「モデル設計タスクを実行」をクリックすると学習が始まります。
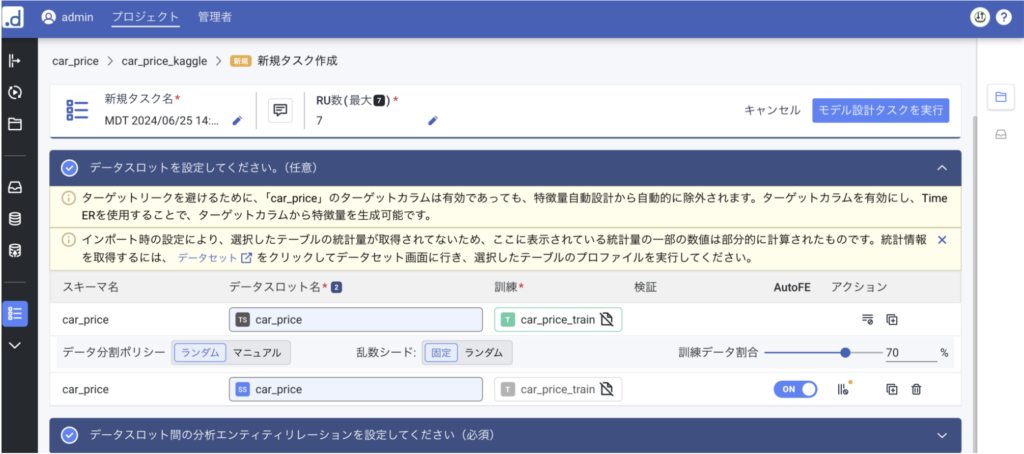
訓練が終わるまでしばらくかかるので、終わるまで待ちます。
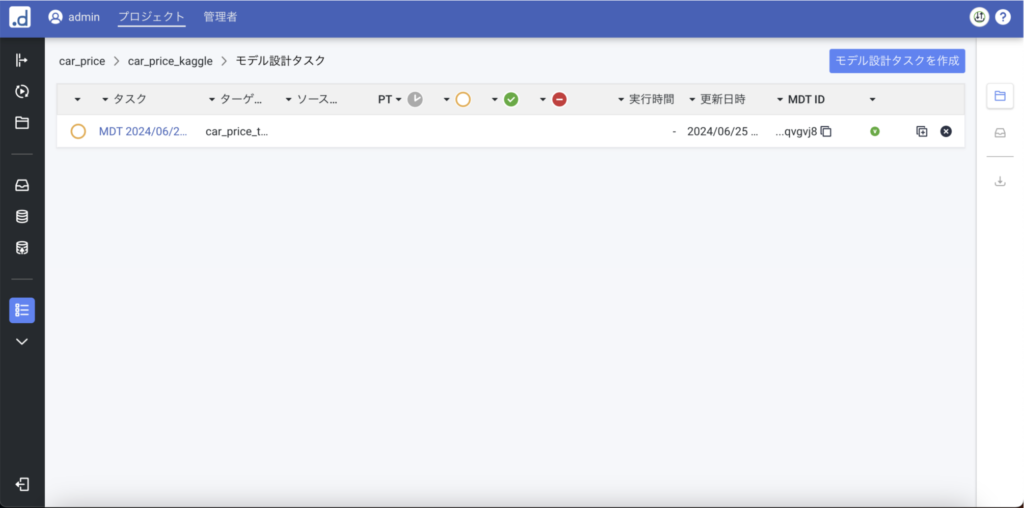
4. 評価
訓練が終わったので結果を確認します。
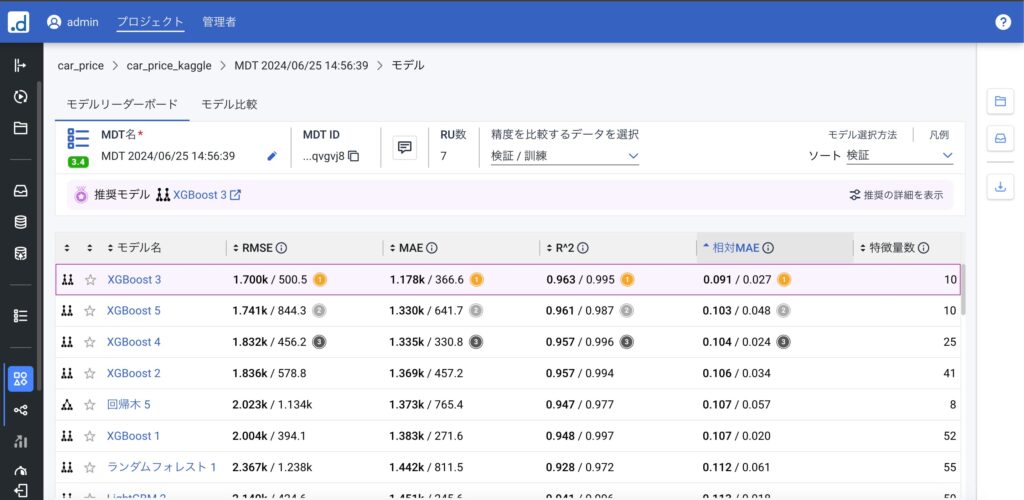
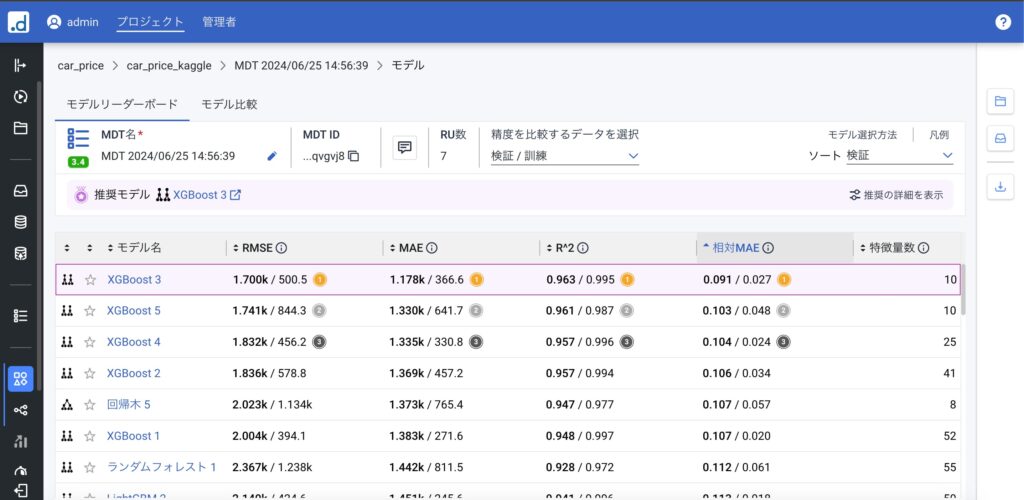
このように複数のモデルを実行しており、そのモデルごとに評価指標の計算結果が出力されています。評価指標も検証データと訓練データの結果が併記されており、過学習しているかなどの確認もこちらでできます。回帰の場合評価指標はRMSE,MAE,決定係数、相対MAEとなります。同じモデルであっても特徴量の生成方法に違いがあり、下に表示されているだけでもXGBoostで特徴量が10~52個とばらつきがあることがわかります。最も良かったXGBoost3を確認してみます。
このように誤差の分布や特徴量探索をした結果どのような特徴量を生成したかも確認できます。
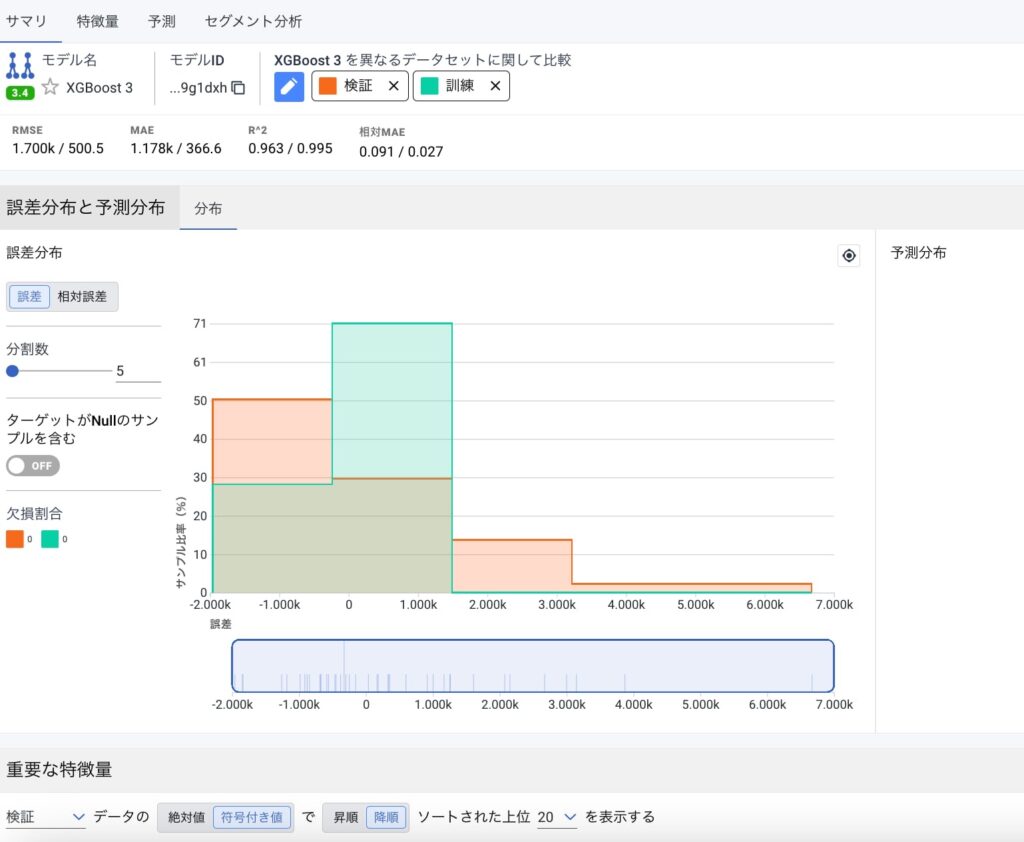
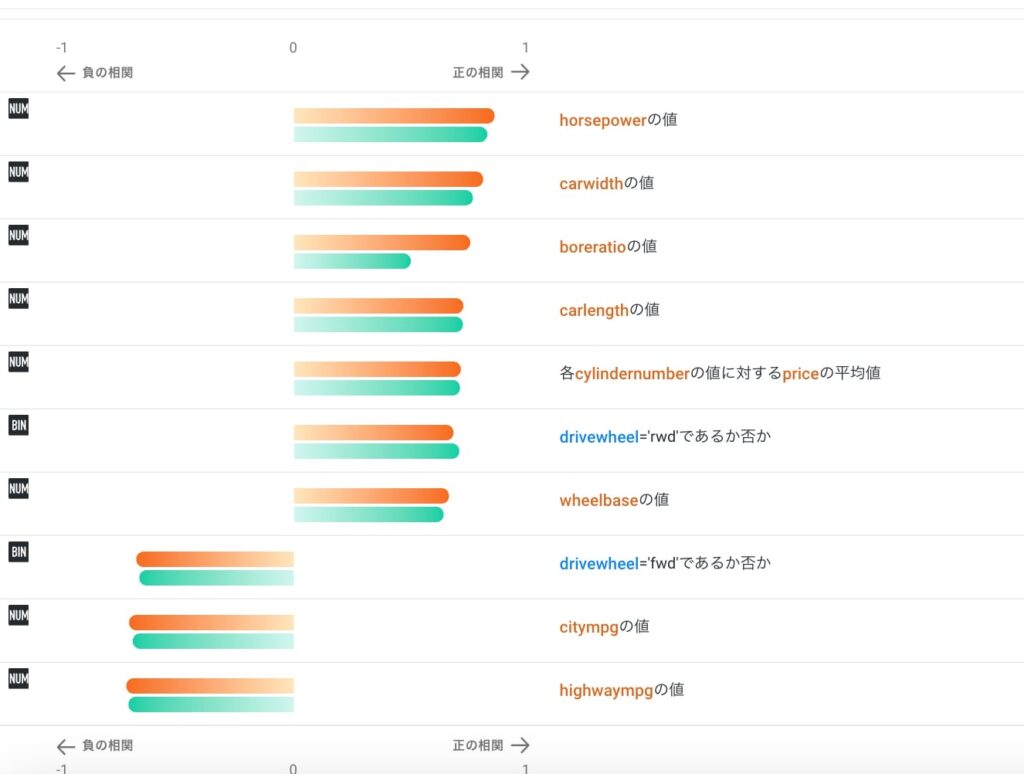
使用した特徴量の情報やメトリック、訓練結果などをCSVでダウンロードしてくることもできるので、特徴量探索の参考にも使えそうな感じがします。カテゴリー変数をone-hotベクトル化した中でも学習に効きそうな一部だけを取り出したり、目的変数との関係から特徴量を生成したりさまざまな探索をしていることが読み取れます。
5. 予測
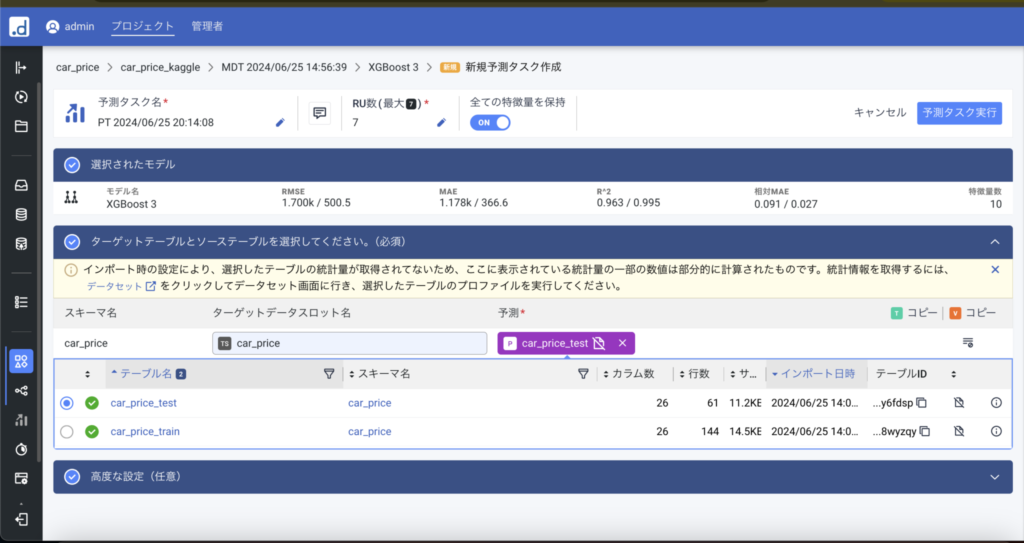
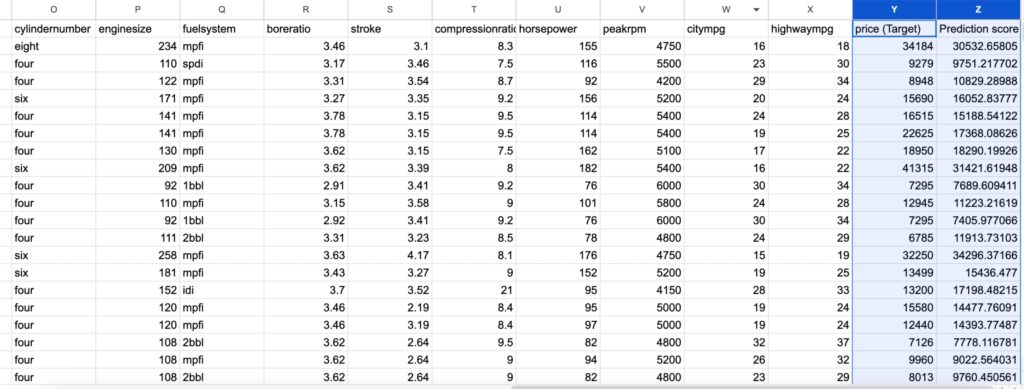
上記モデルでtestデータで推測してみます。先ほど結果を確認した画面で、ターゲットとなるテーブルを選択し、「予測タスク実行」を押すとテストデータに対して予測が実行されます。
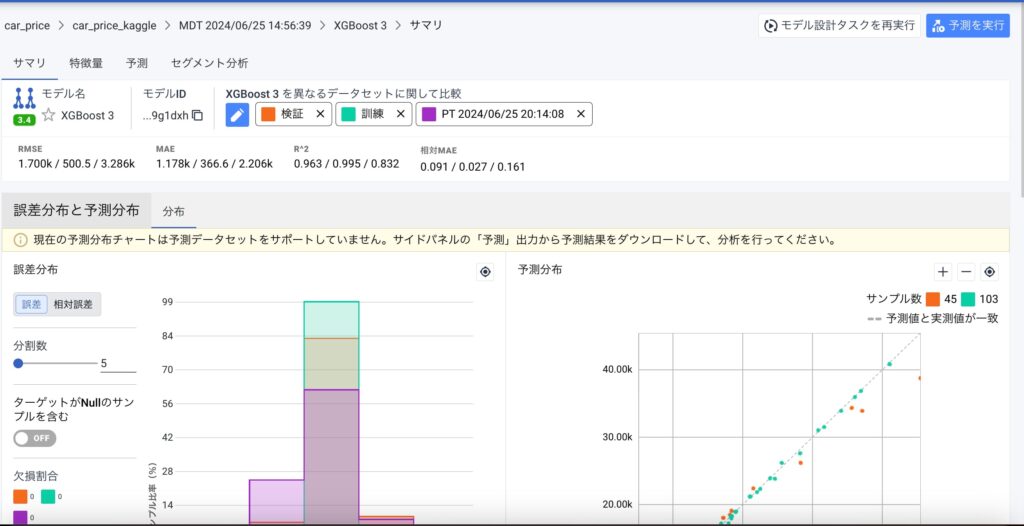
このように紫色のPT~がテストデータの結果となり、確認してみると決定係数で検証データが0.963、テストデータが0.832なので、ややスコアが落ちていることが確認できます。
テストデータでは効きの悪い特徴なども確認できるので、データの偏りや特徴量の生成方法に洞察が得られることもあり得ます。また、今回はXGBoostの中でも特徴量が少ないモデルを採用しているので、たくさんの特徴量を採用しているモデルと比較してみても面白いかもしれないです。
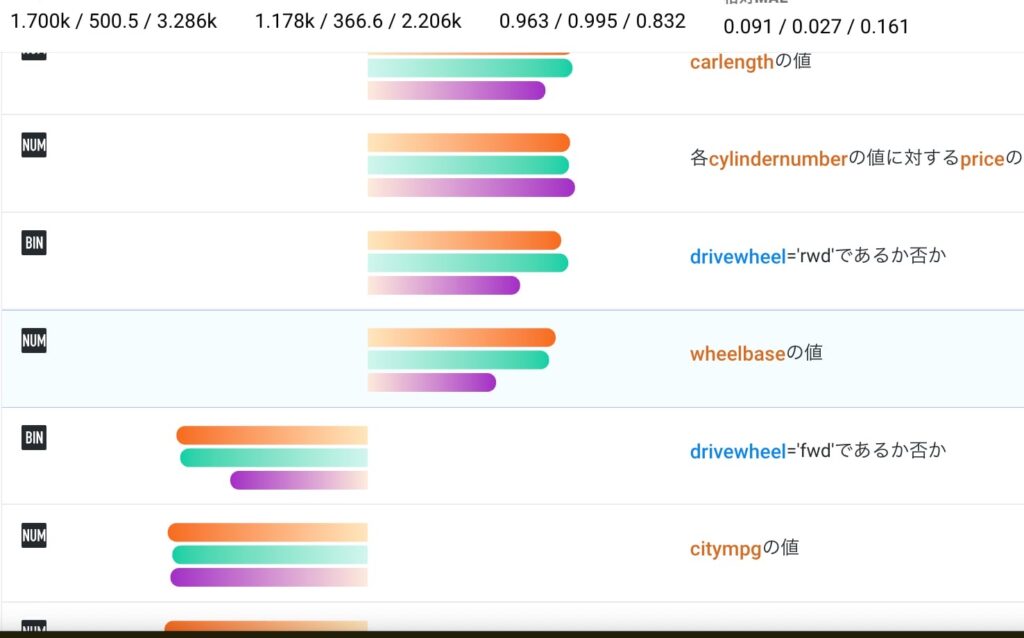
予測結果をダウンロードすることも可能なので、ここから残差などを計算しどのようなデータが結果に寄与しているのかなどの考察も可能です。
まとめ
今回はKaggleのcarpriceのデータセットを使用してdotData Enterpriseの学習をしてみました。今回は詳しい考察はしていないですが、これだけカテゴリー変数が多く特徴量生成が面倒なデータセットであっても手早く訓練をする子ができました。得られた学習結果から、どのようにデータセットを作り直すかや、特徴量探索をするかなどの洞察に役立てることができるツールであると感じました。
Author
アプリ→ネットワーク→情シス担当者→現在データサイエンティストという経歴のエンジニア。テーブルデータから画像のような非構造データまで様々なデータの取り扱い経験有り。最近はデータサイエンティストの養成にも興味を持っている。趣味は離島の写真を撮ること。



