
【CLくんブログ】G検定資格を取得した! – AIのモヤモヤが晴れてきた


そろそろ本腰を入れてAI/機械学習を学ぼうかな、、
そう思っているITな皆さま向けにおススメなG検定にチャレンジしました!
無事に合格したので資格試験の教訓とAI周りのモヤモヤが解消した話をしたいと思います。
日々入ってくるAI関連のニュース、雑誌のChatGPT特集、AIによって無くなる仕事などの書籍を目にすると時代に置いて行かれるのではと不安にさえなる今日この頃。あまりの移り変わりの速さにそっと目を閉じて終わったら結果を教えて下さい、と言いたくなりそうですが、意を決して2024年の1月試験に目標を定めて年末から学習を始めました。
というのもクリエーションラインでは、数年前からMLOpsでAWS Sagemaker Canvasのプロジェクトを支援させて頂いているのですが、昨年から新たにLLM/RAGに関するお話も増えてきていました。社内外のデータサイエンティストの方と打合せをすると、やはり用語もさることながら、その手前でモデル学習って具体的にどんなプロセスで何をするのか?という所からちんぷんかんぷんです。会社的にもAI/LLMに力を入れている中でビジネスサイドがこれではまずいよね、と思いエンジニアチームに遅れての取組みとなりました。
そんなこんなで学習を始めると、ITに身を置く者に馴染みのあるIBM社のWatsonとChatGPTの違いやロボットがどのような仕組みをしているのか、など読んでいても面白い内容です。加えて、教師あり/教師無しなど??だった機械学習の分野についても理解できるようになり、楽しく学習できるシラバス構成となっています。
今回のブログでは2つのトピックでお話したいと思います。
① 資格取得のポイント:試験内容と学習方法など
② 学んだ事:AIに関するモヤモヤを解消した話
①資格取得のポイント
G検定は「ディープラーニングに関する基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているかを検定する。」というジェネラリスト向けの資格となります。JDLAではディープラーニングを実装するエンジニア向けのE資格も実施しています。
(クリエーションラインではどちらも内部での推奨資格となっています)
試験内容は120分のオンライン試験となり知識問題が200問出題されます。資格の合格率は高いものの、統計の知識を持ち合わせていない初学者からすると、統計関数を使った手法や用語の理解は、テキストを一度読んだだけで合格できるほど簡単ではない内容です。
<G検定 シラバス>
・人工知能(AI)とは
・人工知能をめぐる動向
・人工知能分野の問題
・機械学習の具体的手法 ★
・ディープラーニングの概要
・ディープラーニングの手法 ★
・ディープラーニングの社会実装に向けて
・数理・統計 ★
<学習の流れとポイント>
1. 公式テキストで全体を掴む →20時間(5時間×4日)
G検定の公式テキストを読みながらポイントや用語をノートに書いて学習を進めました。全部で20ページぐらいの分量です。機械学習が発展してきた歴史やディープラーニングで行われている処理の仕組み、またAI学習モデルの著作権の扱いなど実務にも関係する内容を体系的に学ぶことが出来るため、AI/機械学習の分野の全体像が見えてきます。各章の章末に問題があり、試験で問われる観点も意識しながら進められます。
2. 用語の深堀り →10時間
シラバスの↑の★の章ではAI技術用語が多く、かつテキストではさらっと触れられているだけのものもあります。そのため、Web検索をしながらそれぞれの特徴などの理解を深めました&ノートに追記して隙間時間で見直し整理しました。(例えば強化学習のQ学習やSARSAの違いなどはWebで調べるとより理解が深まります)
3. 模試や問題集で理解を深める →10時間(2時間×2回+答合わせ)
「模試をやりこむ」という試験の鉄則はG検定でも有効です。模試をやることで傾向を把握する、時間配分のペースを掴む、理解が曖昧なところが分かる、という効果があります。初めて模試をやった際は時間が足らず20問ほど残ってしまいました。模試を通じて1問1問にかけられる時間の間隔をつかめた事で本番は少し時間を残して終えることが出来ました。
試験対策としては目新しいことはありませんが、学習の進め方や学習時間など参考になればと思います!
<学習教材>
・深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版
→全体の範囲を網羅的に説明されており大枠を掴むうえで良いテキスト
詳しい解説がない用語などもあり、問題集やWeb検索で補う必要あり。
・最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版
→問題から解説という構成となり、解説が丁寧に記載されており理解を促す内容。
私は時間切れで問題集は途中でしたがこの2冊で学習すれば十分に合格が出来ます。
・Webメディア:
Zero to One 体験型学習ブログ
AI Smiley DXを推進するAIポータルメディア
→用語を調べる際に参考となります。
② 学んだ事 - AIに関するモヤモヤ解消
今回の資格取得の目的として、「AI/LLMにまつわるモヤモヤを解消したい」がありました。どんなモヤモヤがあったかを振り返ると大きく3つあります。まだまだ学び途中ですが学習前よりは視界が良好です。
モヤモヤその①:そもそもAIって何?
ChatGPTについてはブログの構成を考えたりメール文書を作ってもらったりと活用していますが、そもそも生成AIって何?従来からある統計解析や機械学習と何が違う?など今いちピンと来ていませんでした。今も正確に理解したと言うのは抵抗がありますが、学習を通じて大枠はつかめました。
カテゴリーの整理(ユースケース)
■ 機械学習 :統計理論に基づいた分類や回帰の手法。
(ロジスティック回帰、SVM、ニューラルネットワーク、クラスタリングなど)
→製品の需要予測、交通渋滞の遅延、製造装置の安全な稼働時間に利用。
■ ディープラーニング(ニューラルネットワークの発展系)
・画像認識/生成:画像の濃淡(特徴)と位置が変わっても認識できるよう学習モデル
→不良品検品、医療診断、イラスト生成ツール
・音声認識/生成:音響解析/音響モデル/発音辞書/言語モデルを一つのモデルに実装
→電話による音声対話、音声合成ツール
・自然言語処理:大規模コーパスを事前学習させて文字生成の精度向上
→ChatBot、テキスト要約、感情分析など
・強化学習:目的となる報酬を最大化するように行動を学習
→囲碁AlphaGOなどのゲームAIやロボット制御などに応用
発展の流れ (ディープラーニング登場後)
1. 識別モデルの精度向上
2010年代に登場したディープラーニング技術により画像認識など識別モデルの精度が飛躍的に向上した。特に画像認識では2015年に人間の認識エラー率の4%を抜きました。言語モデルも登場し言語処理や音声処理の技術が進化した。
2. 生成モデルの発展
さらにGANやVAEの技術により画像生成タスクAIも発展した。これらの技術進化の延長でGPTやBERTが誕生した。それにより、イラスト画像を生成する技術や自然言語処理における質問応答や意味的類似度判定などの高度なタスクが実行できるようになり、実世界で利用できるレベルに到達し一気に普及した。
3. マルチモーダルやAGIの世界に
現在はさらに画像/音声/自然言語の処理を組み合わせたマルチモーダルのモデルが実用化してきている、深層強化学習などの発展によりAGIも模索されている。
モヤモヤその②:データの分析業務って何をどうする?
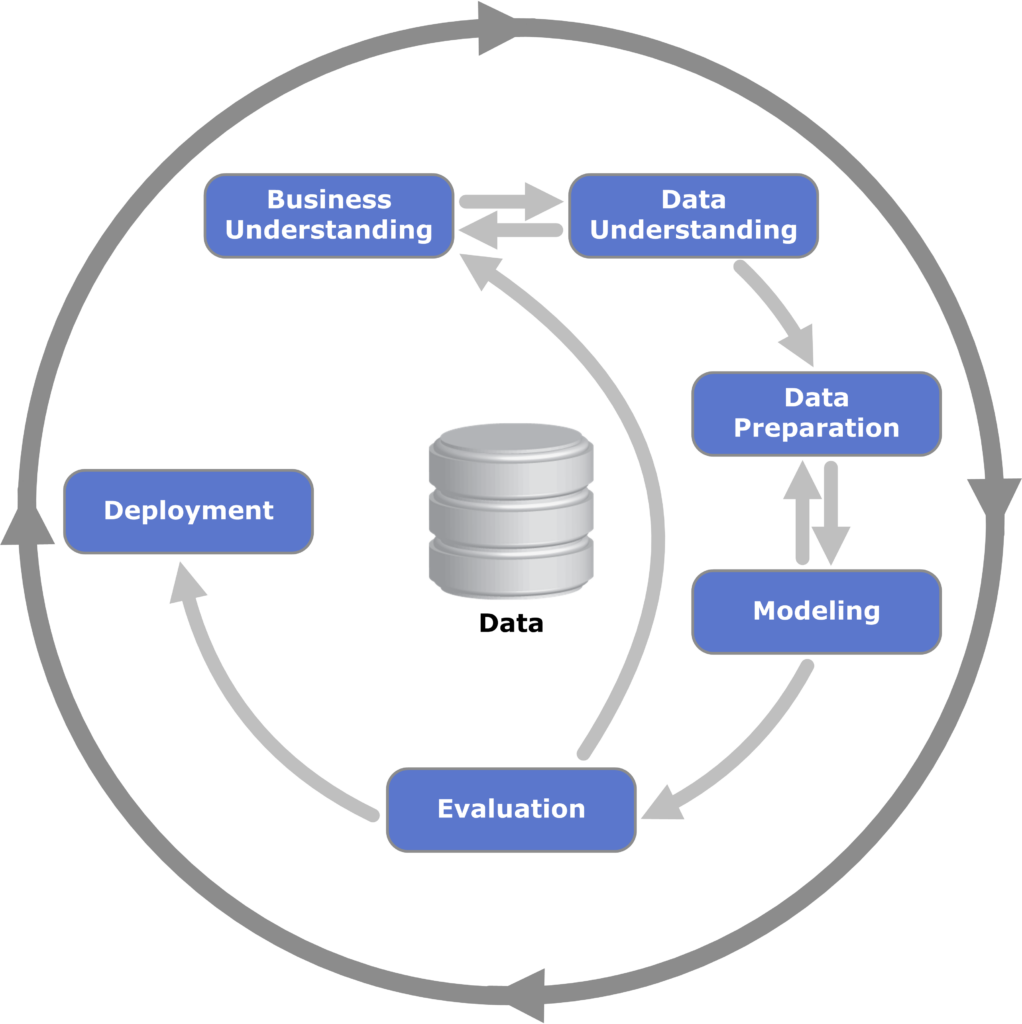
LLMは2020年代になって登場しましたが、それ以前にもデータ分析業務はありました。社内外のデータサイエンティストの方がどの様な知識に基づいてどのようにデータ分析をしているのか?な状況でした。
新しい用語ではありませんが、CRISP-DM (Cross-industry standard process for data mining)でデータを収集して加工して学習モデルを構築しているかについての具体的なイメージをもてるようになりました。
・データ準備:欠損値処理、外れ値除去、ダミー変数化、特徴量作成
・モデリング:学習モデルとして回帰/分類、画像/音声/時系列などデータ種類
・評価 :回帰にはRMSE、分類には再現率/適合率など
MLOpsはこれらの流れを効率化し一元的に管理するツールとなり、AutoMLや特徴量エンジニアリングというのはデータ準備やモデル作成を自動化/効率化するソリューションになります。
モヤモヤその③:色々なソリューションがあって、、、
クラウド事業者が提供するAIソリューション(Microsoft社のAzure OpenAI、Google社のVertexAI、AWS社のBedrock/Sagemaker) はプラットフォームとして自然言語/音声/画像認識の学習済みモデルを利用できます。オープンソースの深層学習フレームワークやライブラリを利用して独自モデルの構築(カスタムトレーニング)ができるプラットフォームとなります。
一方でIT業界では元々アナリティクスの分野にデータマイニングのソリューションがあり、クラスター分析やロジスティック回帰など機械学習アルゴリズムが使われていました。BI (Business Inteligence) ソリューションでは金融向けの不正利用検知や製造業での設備の異常検知などの分析機能を有しています。また、DWH分野のDatabriks社やデータ加工ソリューションのAlyteryx社は特徴量エンジニアリングやMLOpsの機能を有しています。
さらに、OpenAIの対抗馬としてのAnthoropicやCohereがあり、またMLOpsの分野ではAIのGithubと言われるHugging FaceやMLOpsの分野でDotodata, DataikuやH2O.ioなどのスタートアップがでてきています。
色々あって素人にはかなり分かりづらい様相、、
たどり着いた現時点の結論としては其々のプレーヤーが生成AIや機械学習を用いたデータ分析を便利にする機能を追加してきている、その中で垣根がなくなって来ているということ。
・クラウド事業者 :独自のAIモデル(OpenAIやGemini)とMLOps/AutoMLの機能拡充
・DWH/BIベンダー:MLOpsや特徴量エンジニアリングの機能を拡充 (Databricks, Altelycsなど)
・スタートアップ :LLMやMLOpsの分野で色々と登場(Anthoropic, Cohere、 Hagging Face、Dotdata, Dataikuなどなど)
若干、資格を通じた学びからは離れてきましたが、ディープラーニングや生成AIの基本的な内容を押さえることで、各ソリューションや事業者の特徴を理解しやすくなる、というのは実感としてもあり自信をもってお伝え出来ます!最後に、ここまでのAIの素人が資格取得を通じて生成AIや機械学習を用いたデータ活用に関する解像度が上がっている感が伝われば嬉しいです。生成AIに興味のある方、IT業界の方はおススメの資格となりますので是非チャレンジしてみて下さい。
AI関連ブログはこちら
Author
2020年に生まれたCLキャラクター。CL内ではビジネス企画/マーケティングを担当。2024年はCLの取組みや学んだことを中心に発信していきます!アジャイル開発、クラウドネイティブ、AI/機械学習を中心にトレンドを調べたりプロジェクトチームに聞いたりして勉強中!



