
MongoDB のデータを Neo4j で可視化してみる #Neo4j #MongoDB #Graph
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
本稿では、表題の通り、MongoDB のデータを Neo4j で可視化する ‘連携’ を試してみます。MongoDB のデータは JSON ドキュメントのテキストですが、Neo4j のグラフ理論をもってグラフ化することにより、データの表す意味を人間が直感的に理解できるようにすることが目的です。
MongoDB とは
ドキュメント型のNoSQLデータベースです。柔軟性と拡張性を持ち、リレーショナルデータベースよりも柔軟に検索したり、インデックスを活用した効率的なデータ探索が可能です。RDB のテーブルに相当するものが ‘コレクション’ になり、レコードに相当するものが ‘ドキュメント’ となります。詳しくは、こちらをご覧ください。
Neo4j とは
関係型データベースの性能問題を解決するため、2000年頃から開発が始まったグラフデータベースです。グラフデータベースは、グラフを描画するのではなく、グラフ理論の頭脳をもってデータ処理を行うことができる、とても汎用性の高いデータベースです。詳しくは、こちらをご覧ください。
本稿で使用するドキュメント (MongoDB のデータ)
とある架空システムの “cluster” と、その cluster に属する “node” の関係を表したドキュメントを使用します。
node ドキュメント
{ id: "n1", type: "Node", name: "Node-01" }
node を表します。nodes という名前のコレクションに格納されます。Neo4j と連携するとき、id と type のフィールドはドキュメント内に必須なので追加しておきます。id は node ごとに一意の値であり、type の値は ‘Node’ 固定です。それ以外は、名前を表す name フィールドがあるだけのシンプルなドキュメントです。
cluster ドキュメント
{ id: "c3", type: "Cluster", name: "Cluster-03", active_nodes: [ "n1", "n5" ], standby_nodes: [ "n6" ] }
cluster を表します。clusters という名前のコレクションに格納されます。id, type, name は node ドキュメントと同じで、type の値は ‘Cluster’ 固定です。active_nodes と standby_nodes は、この cluster に属する node を node の id の配列として指定します。cluster と node は、1:n の関係になっています。
検証環境
検証環境は docker コンテナで作成します。筆者の環境では、docker ホストとして Ubuntu20.04 を使用しています。
※docker のインストールに関しては説明を省略させていただきます。
必要なファイルの準備
1. docker ホストのホームディレクトリに、検証で使用するディレクトリを作成します。
~$ mkdir -p mongo/db mongo/initdb.d mongo/configdb neo4j/data neo4j/plugins neo4j/logs
2. $HOME/mongo/initdb.d 配下に、MongoDB にドキュメントを追加するためのスクリプト init.js を追加します。node × 6 台と cluster × 3 つのデータです。 このスクリプトは、MongoDB のコンテナが作成された後に自動で実行されます。
db.createUser({
user: "mongo",
pwd: "mongo",
roles: [
{ role: "readWrite", db: "sample" }
]
});
db.auth("mongo", "mongo");
db = db.getSiblingDB("sample");
db.nodes.insertMany([
{ id: "n1", type: "Node", name: "Node-01" },
{ id: "n2", type: "Node", name: "Node-02" },
{ id: "n3", type: "Node", name: "Node-03" },
{ id: "n4", type: "Node", name: "Node-04" },
{ id: "n5", type: "Node", name: "Node-05" },
{ id: "n6", type: "Node", name: "Node-06" }
]);
db.clusters.insertMany([
{ id: "c1", type: "Cluster", name: "Cluster-01", active_nodes: [ "n1", "n2", "n3" ] },
{ id: "c2", type: "Cluster", name: "Cluster-02", active_nodes: [ "n3", "n4" ] },
{ id: "c3", type: "Cluster", name: "Cluster-03", active_nodes: [ "n1", "n5" ], standby_nodes: [ "n6" ] }
]);
3. init.js の権限を変更します。
~/mongo/initdb.d$ chmod o+rw init.js
4. $HOME/neo4j/plugins 配下に、MongoDB と Neo4j の連携に必要な以下の jar ファイルをダウンロードします。
~/neo4j/plugins$ wget https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/4.4.0.7/apoc-4.4.0.7-all.jar && \ wget https://repo1.maven.org/maven2/org/mongodb/bson/3.12.11/bson-3.12.11.jar && \ wget https://repo1.maven.org/maven2/org/mongodb/mongo-java-driver/3.12.11/mongo-java-driver-3.12.11.jar && \ wget https://repo1.maven.org/maven2/org/mongodb/mongodb-driver/3.12.11/mongodb-driver-3.12.11.jar && \ wget https://repo1.maven.org/maven2/org/mongodb/mongodb-driver-core/3.12.11/mongodb-driver-core-3.12.11.jar && \ wget https://repo1.maven.org/maven2/com/fasterxml/jackson/core/jackson-annotations/2.13.3/jackson-annotations-2.13.3.jar && \ wget https://repo1.maven.org/maven2/com/fasterxml/jackson/core/jackson-core/2.13.3/jackson-core-2.13.3.jar && \ wget https://repo1.maven.org/maven2/com/fasterxml/jackson/core/jackson-databind/2.13.3/jackson-databind-2.13.3.jar
5. ホームディレクトリ配下に、docker-compose.yml ファイルを作成します。ファイルの内容は、以下の様にします。
version: "3.9" services: mongo: container_name: mongo-test image: mongo:latest ports: - 27017:27017 volumes: - $HOME/mongo/initdb.d:/docker-entrypoint-initdb.d - $HOME/mongo/db:/data/db - $HOME/mongo/configdb:/data/configdb environment: TZ: Asia/Tokyo MONGO_INITDB_ROOT_USERNAME: "root" MONGO_INITDB_ROOT_PASSWORD: "example" MONGO_INITDB_DATABASE: "sample" neo4j: container_name: neo4j-test image: neo4j:latest ports: - 7474:7474 - 7687:7687 volumes: - $HOME/neo4j/data:/data - $HOME/neo4j/plugins:/plugins - $HOME/neo4j/logs:/logs environment: NEO4J_apoc_export_file_enabled: "true" NEO4J_apoc_import_file_enabled: "true" NEO4J_apoc_import_file_use__neo4j__config: "true"
6. ファイルの準備完了後は、以下の様になります。
~$ tree . ├── docker-compose.yml ├── mongo │ ├── configdb │ ├── db │ └── initdb.d │ └── init.js └── neo4j ├── data ├── logs └── plugins ├── apoc-4.4.0.7-all.jar ├── bson-3.12.11.jar ├── jackson-annotations-2.13.3.jar ├── jackson-core-2.13.3.jar ├── jackson-databind-2.13.3.jar ├── mongodb-driver-3.12.11.jar ├── mongodb-driver-core-3.12.11.jar └── mongo-java-driver-3.12.11.jar
docker コンテナの作成
先程作成した docker-composey.yml から、コンテナを作成します。
~$ docker-compose up -d
正常に起動すると、以下の様になります。
~$ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------------------------------------------- mongo-test docker-entrypoint.sh mongod Up 0.0.0.0:27017->27017/tcp,:::27017->27017/tcp neo4j-test tini -g -- /startup/docker ... Up 7473/tcp, 0.0.0.0:7474->7474/tcp,:::7474->7474/tcp, 0.0.0.0:7687->7687/tcp,:::7687->7687/tcp
Neo4j ブラウザ
Neo4j ブラウザは、HTTP/HTTPS で Neo4j サーバーに接続し、対話式でグラフデータベースを操作できる GUI ツールです。この Neo4j ブラウザからコマンドを入力し、MongoDB から取得したデータを基にグラフを描画することになります。
1. Web ブラウザーから、以下の URL を指定します。
http://<docker ホストの IP アドレス>:7474/browser/
2. 接続 (ログイン) 画面が表示されます。
3. 初期設定は以下の値になっていますので、[Connect] をクリックして接続します。
- username: neo4j
- password: neo4j
4. パスワードの変更を求められるので、任意の値を指定して [Change password] をクリックします。
5. 変更後、以下の様な画面が表示されます。
Neo4j APOC
APOC は "A Package Of Component" の略で、Neo4j の機能を拡張するためのアドオンライブラリです。APOC の中には MongoDB クライアントも含まれており、これを使用すれば、 MongoDB に接続して検索などのクエリを送信することができます。
MongoDB に接続してデータの取得
少々長いですが、'neo4j$' と表示されているテキストボックスに、以下のコマンドを入力して実行します。

call apoc.mongo.aggregate('mongodb://mongo:mongo@mongo-test/sample.clusters', [ { `$lookup`: { from: 'nodes', localField: 'active_nodes', foreignField: 'id', as: 'active_node', pipeline: [ { `$unset`: [ '_id' ] } ] } }, { `$lookup`: { from: 'nodes', localField: 'standby_nodes', foreignField: 'id', as: 'standby_node', pipeline: [ { `$unset`: [ '_id' ] } ] } }, { `$unwind`: { path: '$standby_node', preserveNullAndEmptyArrays: true } }, { `$unset`: [ '_id', 'active_nodes', 'standby_nodes' ] } ]) yield value
すると、以下の結果が返ってきます。APOC で MongoDB に接続し、データを取得することができました。また、aggregate を使って、少し複雑な集計の処理も問題なく行うことができました。

コマンド解説
call apoc.xxx で、APOC の機能を呼び出すことができます。今回は MongoDB の集計処理を行うために、call apoc.mongo.aggregate を実行しました。以後は MongoDB のパイプライン (処理の連鎖) の書き方になりますので、詳しくはこちらを参照してください。
‘mongodb://mongo:mongo@mongo-test/sample.clusters’ は MongoDB への接続文字列です。mongo:mongo はユーザー名とパスワード、mongo-test は docker コンテナのホスト名、sample.clusters は、sample というデータベースの clusters コレクションを操作の対象にすることを表します。
‘$’ ではじまるフィールドは “オペレータ” と言い、ドキュメントの操作 (処理) 内容を表します。ここでは、コマンドに使用した各オペレータを紹介します。
| オペレータ | 詳細 | 参考文献 |
| $lookup | RDB のように、2 つのコレクションを結合します。 | こちら |
| $unset | 出力時に、不要なフィールドを削除 (非表示) します。 | こちら |
| $unwind | preserveNullAndEmptyArrays が true の場合、path で指定したフィールドが null や空の配列でもドキュメントを出力します。このとき、path で指定したフィールドは削除 (非表示) されます。データがないフィールドは出力に含めたくない場合に使用できます。 | こちら |
MongoDB のデータをグラフ化
本稿の最終目標になります。さきほどの MongoDB の出力 (JSON データ) から、cluster と node の関係性を表すグラフを描画してみます。
この処理も APOC を使用しますが、先ほどのコマンドでは、出力を受け取る変数 ‘value’ を設けており、ここにデータが格納されている状態になっています。次のコマンドで、取得した value を渡すことにより、「MongoDB のデータから Neo4j でグラフを描く」ことが実現できます。
これも少々長いですが、以下のコマンドを実行します。先ほどのコマンドの下の行 ([Shift] + [Enter] で改行できます) から続けて書くようにしてください。
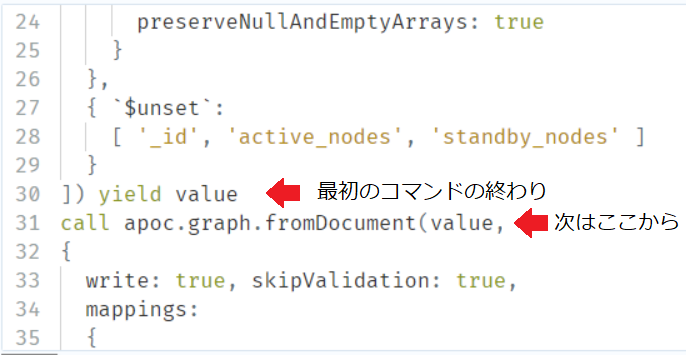
call apoc.graph.fromDocument(value, { write: true, skipValidation: true, mappings: { `$`:'Clusters{id,name}', `$.active_node`:'ActiveNodes{id,name}', `$.standby_node`:'StandbyNodes{id,name}' } }) yield graph return graph
すると、以下の結果が返ってきます。MongoDB の JSON ドキュメントから、グラフを描画することができました。グラフの見方に関しては、こちらを参照してください。
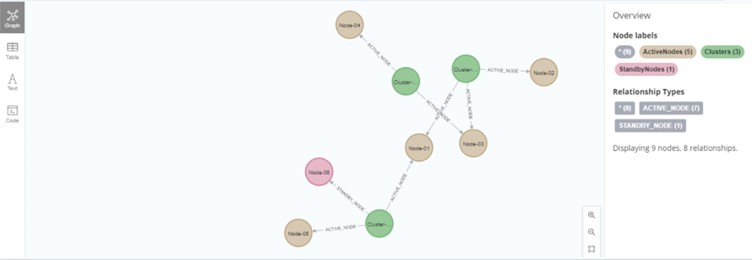
※グラフが表示されていない場合は、左のツールバーから [Graph] をクリックしてください。
コマンド解説
‘apoc.graph.fromDocument’ は、JSON ドキュメントからグラフを描画します。ですので、データが JSON である MongoDB との組み合わせに最適です。
fromDocument の詳細は、こちらを参照してください。ここでは、mapping について解説します。mapping は、グラフ描画時に表示される関連性や、ノードラベル、表示したいノードプロパティ (JSON ドキュメントのフィールドの値) を明示的に指定します。
`$` や `$.xxx` はグラフの 〇 を表し、”ノード” と言います。ノードに対して、ラベルやプロパティを記述します。
※Neo4j のノードと、本稿で使用しているデータの node とは別物です。ややこしくてすみません。
尚、紐づけに関しては、割と良しなにやってくれるので、ラベル名にこだわりがなく、ノードの全プロパティを表示して良い場合は、mapping は省略しても構いません。
| ノード | 概要 | 値 |
| `$` | ルートノードを表します。本稿では、JSON データの cluster に該当します。 | 'Clusters{id,name}' Clusters はノードラベル、{ } 内の値はノードプロパティ |
| `$.xxx` | ルートノードと関係性があるノードです。xxx の部分には、JSON データに含まれる、ルートと関連性のあるフィールド名を指定します。本稿では、active_node と standby_node が該当し、それぞれ cluster に属する node を表します。 | 'ActiveNodes{id,name}' 'StandbyNodes{id,name}' ラベルとプロパティの関係は `$` と同じ |
mapping については、こちらが参考になります。
さいごに
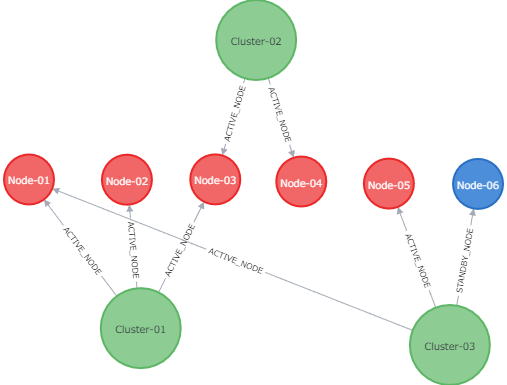
MongoDB のドキュメントから、Neo4j のグラフにする目的は達成しました。さいごに、表示されたグラフを整形して、もう少しわかりやすくしてみましょう。node を一列に整列し、cluster との関連をわかりやすくしてみました。また、cluster ノードの円を大きくし、上位であることを明確にしてみました。あと、色もなんとなく変えてみました。結果、以下の様なグラフに仕上がりました。
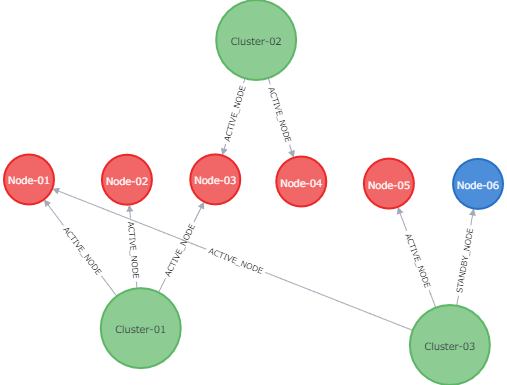
単なる JSON のテキストではわかり辛いのですが、このようにグラフ化して整形すると、
- Node-01 と Node-03 が複数の cluster で被ってしまっていること
- Standby は Node-06 しかなく Cluster-03 しか備えていないこと
- 他、cluster や node の数など
といった関連性が、一目瞭然でわかると思います。
以上より、MongoDB のドキュメントをデータソースとして Neo4j のグラフを描画 (連携) し、可視化できることがわかりました。MongoDB のデータの関連性を可視化したい場合は、 MongoDB と Neo4j との連携を是非お試しください。
参考: MongoDB には "MongoDB Charts" というツールもあります。



