
グラフデータベースを選ぶ際に考慮すべき16のこと(前編)#neo4j #cypher #acid #htap #graphdatabase

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本ブログは 「Neo4j」 社の技術ブログで2022年4月8日に公開された「 16 Things to Consider When Selecting the Right Graph Database」の日本語翻訳です。
 Neo4j プロダクトマーケティング担当VP Dave Packer
Neo4j プロダクトマーケティング担当VP Dave Packer

貴社に適したグラフテクノロジーを選ぶのは大変難しいことです。このブログでは、グラフデータベース、関連ツール、そしてそれらを販売・サポートするベンダーの中から、どのようなものを選べばよいかを説明します。
グラフデータベースを活用してビジネスを成功させるためには、各ベンダーのソリューションが以下の条件をどう満たしているか把握することが重要です。
目次:グラフデータベースを選ぶ際に考慮すべき16のこと
- グラフネイティブなストレージと処理
- プロパティグラフ
- グラフクエリ言語
- データの取込みと統合
- 開発ツール
- グラフの可視化
- グラフデータサイエンス
- OLTP、OLAP、HTAPアプリケーションのサポート
- ACIDコンプライアンス、耐久性、一貫性
- 高可用性(HA)
- スケーラビリティとパフォーマンス
- 企業のセキュリティとプライバシー
- デプロイメントの柔軟性
- オープンソース・コミュニティ
- ビジネスパートナーおよびテクノロジーパートナー
- ベンダーの信頼性とレジリエンス
- Neo4j:選ばれ続けるグラフデータベース
(注:高可用性(HA)以降は後編にて)
グラフネイティブなストレージと処理
グラフネイティブなストレージは、グラフデータベースの整合性と性能の基本であり、グラフのノードを結んでいる実世界のつながりが一次的で永続的なデータエレメントとして保存されることを保証します。
また、ネイティブグラフデータモデルは、ビジネスの仕組みをそのまま表すことができます。例えば、ビジネスアプリケーションで必要とされる製品データモデルを表現することでアプリケーション開発がより簡単に、直感的に行えるようになります。
グラフネイティブなストレージではない場合、リレーションシップ情報が喪失、切断、放棄され、データの破損につながり、データベースの中央ナビゲーションシステムが壊れてしまうことがあります。まるで、GPSの案内に従って一方通行の道を進んだら、その先の橋が水没していて立ち往生してしまうようなものです。
非グラフネイティブのデータベースは、グラフのデータやリクエストを独自の列や文書のパラダイムに変換することで、グラフの機能を模倣しています。これらの余分なコード層は、クエリやアプリケーションのパフォーマンスを低下させます。データ変換の際にデータのニュアンスやエラーを隠蔽してしまい、グラフデータの破損を引き起こしたり黙認したりします。更に、多くの場合、グラフの機能を模倣するためのデータ変換等に加えて、複雑なクエリや結合(join)が必要になります。
よって、比較評価の一環として、グラフデータベースがネイティブなグラフ処理を行うか、ソフトウェアのなかに非ネイティブな変換が隠されているかを確認しましょう。
インデックスフリーの隣接性により、複雑なグラフデータセット間でも超高速に検索できます。データベースには、あるノードから次のノードへのポインタが格納されています。このような高速かつ予測可能な性能は、グラフネイティブな環境でのみ実現可能です。これとは対照的に、非グラフネイティブのアプローチはグラフアプリケーションのパフォーマンス、スケーラビリティ、信頼性を低下させます。
インデックスフリーの隣接性を持つ完全グラフネイティブなストレージと処理がNeo4jの特徴です。Neo4jは、クエリのパフォーマンスとスケーラビリティを最大化しながらデータの完全性を維持する最上の機能を備えています。Neo4jのグラフネイティブなストレージと処理は、画期的なアプリケーションのためのアジャイルな基盤を提供します。そのアプリケーションによって、TCOが削減でき、より早く、より低いリスクで利益をもたらすことができます。
プロパティグラフ
プロパティグラフがグラフデータベースをパワフルにします。プロパティグラフではデータエレメントとリレーションシップ(ノードとコネクション)は、ともにファーストクラス、主要データエレメント(ファーストクラスエンティティ)として扱われます。リレーションシップはデータエレメントと同様に重要です。リレーションシップとデータエレメントによって、ビジネスの仕組みをモデル化した、つながりのあるデータのセマンティックな(意味のある)基盤が提供できます。
ビジネスの仕組みのモデル化とは、誰が誰を知っているか、何が好きか、どこで買い物をするか、誰がどの材料を供給するか、どの部品がどの製品に使われているかなどの情報のつながりです。
データエレメントとそれに関連するリレーションシップは、詳細とコンテキストを提供するプロパティを持ち、リッチなクエリをサポートします。
アプリケーションがグラフをクエリすると、データベースはノード(エレメント)を結ぶパス(リレーションシップ)を検索し、クエリを完了させてマッチした結果を返します。
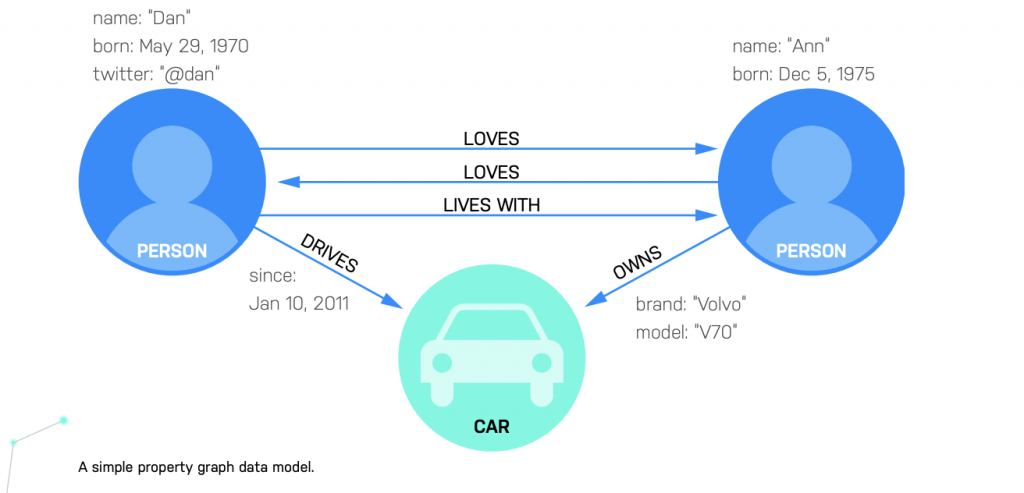
Neo4j は柔軟なネイティブプロパティグラフを提供し、新しいデータモデルのプロトタイピングを容易にし、ビジネスニーズの変化に応じてそれらを適応させることができます。他のグラフデータベースでは、固定プロパティのグラフや従来のRDF(Resource Description Framework)形式を使用しているため、多くの場合、わずかな変更でもスキーマの書き換えや複雑なクエリのコーディング、長い開発期間を必要とします。
グラフクエリ言語
SQLは標準的なリレーショナルクエリ言語ですが、行と列のクエリ用に設計されています。グラフのパラダイムに適応するには、単純に非効率的で複雑すぎるのです。グラフデータベースクエリのためにいくつかの独自言語が進化しましたが、最有力の言語はCypherとGremlinの2つであり、ほとんどのグラフデータベース製品で使用されています。
ほぼすべてのグラフデータベースベンダーは、Cypher、Gremlin、またはその両方を直接サポートしています。また、Gremlinしかサポートしていないものは、ApacheのCypher for Gremlinプロジェクトを使って、Cypherをサポートしているデータベースやツールに対してGremlinのコードを実行することができます。そのため、ISOのコミュニティでは、Cypherベースの標準言語をSQLの姉妹言語として認めようとする取り組みが行われています。
SQLやCypherなどの宣言型言語は、Javaなどの命令型言語とは対照的に、学習、記述、読み取り、デバッグが容易です。また、どのように取得するかではなく、何を取得するかをデータベースに指示するだけなので、利用が容易です。Cypherがなければ、開発者はデータベースのグラフスキーマに精通し、各グラフ探索の実行方法を指定しなければならず、学習曲線とコードの複雑さを増大させることになります。
クエリ言語によっては、実行前にバイナリパッケージへのコンパイルが必要なものもあります。コンパイルはパフォーマンスを最適化することができますが、クエリの作成、構築、実行がより複雑になり、その場でクエリをデバッグしたり変更したりすることができなくなります。
Neo4jは、クエリ言語Cypher(openCypher)の開発元として、すべてのグラフ技術に宣言型言語を使用しています。
開発者とユーザーは、すべてのグラフプロジェクトにおいて、宣言型クエリの利点、生産性、容易性を得ることができます。
![Neo4j[ホワイトペーパー]Powering-Recommendations](https://no-cache.hubspot.com/cta/default/6168413/0a3cf578-a3a3-4d0c-84f0-85ffc26b5557.png)
データの取込みと統合
グラフデータベースの完全性と有用性は、データセットがどれほど組織の業務システムと密接に統合されているかに依存します。そのため、強力なデータの取込みと統合は、グラフアプリケーションプラットフォームにおいて非常に重要です。
CSVファイルのインポートはほとんどのデータベースで可能ですが、高速な一括取込みが可能であるかも確認が必要です。また、グラフデータベースは、データのロードに伴い、迅速かつ確実にリレーションシップを作成することが重要です。
一括取込み処理では、すべてのデータが取り込まれるまでインデックス構築と一貫性チェックを延期することができ、それによってロードとインデックス作成のプロセスを高速化することができます。
ベンダーが主張する高性能な取込み機能には注意が必要です。なぜなら、ベンダーはしばしばデータの整合性を無視してその速度を達成し、データに穴や塊が発生して分析に影響を与えるからです。
データセットは急速に変化するため、採用しようとしているデータベースが、必要に応じてデータや関連するリレーションシップの変更、追加、削除に対応できることを確認しましょう。
定期的な更新をサポートするために、Apache HopやKafkaなどのオープンソースツールや、Informatica、TIBCO、Trifactaなどの商用ツールをサポートするグラフデータベースを検討しましょう。
Hadoopのようなビッグデータ技術を導入済みですか?そうであれば、グラフデータベースがそれらと容易に統合できることを確認しましょう。Apache Sparkのようなデプロイ済みのデータ処理技術を使用することが理想的です。
データレイクを利用してデータウェアハウスにデータを供給する場合や、Apache Sparkの分析処理エンジンを利用する場合は、グラフデータベースがそのソースデータとも容易に統合できるようにする必要があります。
現在最も成熟し、広く利用されているグラフデータベースであるNeo4jは、これらの高度な取込み技術や手法をすべてサポートしています。開発者、DBA、ユーザーの生産性を最大化しながら、Neo4jを迅速かつ確実にインフラに統合することができます。
開発ツール
開発者が不足している現状を踏まえて、グラフデータプラットフォームには強力なグラフアプリケーションを迅速かつ堅牢に作成するためのさまざまなツールが含まれているべきです。
そのためにはまず、グラフ探索、明確なクエリ作成、そして結果の理解を支援する視覚的な開発環境が必要です。開発者の生産性を最大化するためには、以下のような機能を備えた環境が必要です。
- キーワードの色分けと自動補完
- 結果セットの可視化を支援するグラフ描画ツール
- ナレッジや指示をわかりやすく共有するためのストーリーボードツール
拡張性のあるカスタムソリューションを構築するためには、グラフデータベースへのデータロード、エンタープライズ・アプリケーションへのグラフ結果の統合、さらにはアプリケーションへのグラフデータベースの組み込みを可能にするドライバとAPIが必要です。
Neo4jは、Java、JavaScript、.NET、Python、Goの商用サポートを提供しており、またNeo4jコミュニティでは、その他さまざまな言語用のドライバを提供しています。さらに、Neo4jでは、アプリケーション・ロジック、UI、クラウド・コンテナを完備したグラフ・アプリケーションをOEM製品に組み込むことが可能です。
すべての開発ツールを統合し、グラフデータベースシステムを作成、修正、維持するための一貫した強力な場を提供する開発者用ローンチパッドがあれば理想的でしょう。
Neo4j Desktopは、グラフ開発のための統合されたローンチパッドです。Neo4jデータベースへのアクセス、豊富なプロシージャライブラリ、グラフアプリケーションの例などを提供しています。
グラフの可視化
ソフトウェアエンジニアリングのライフサイクルをサポートするツールに加え、グラフプラットフォームは、開発者、データサイエンティスト、データベース管理者、情報システム担当者、ビジネスユーザーなど多様なユーザーのニーズに対応する必要があります。
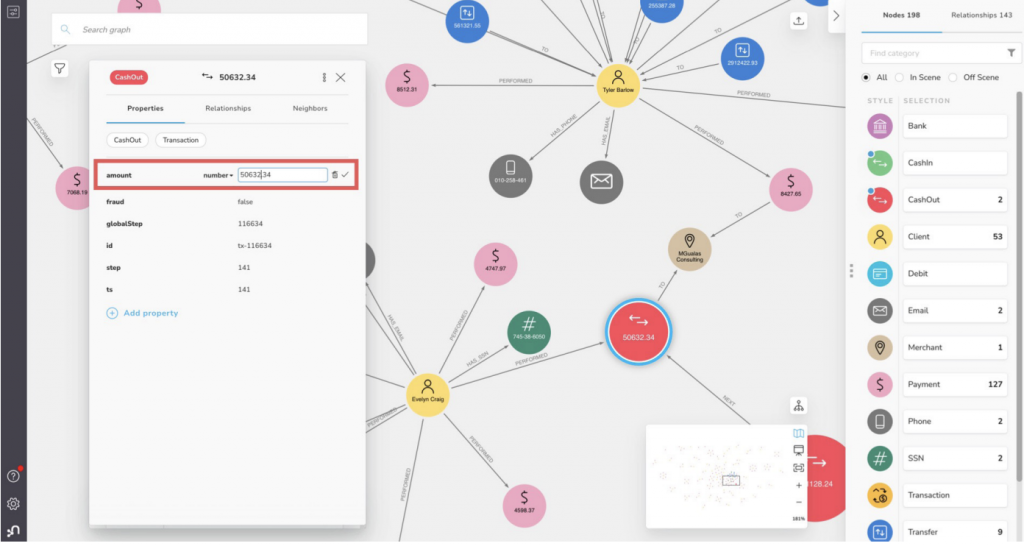
グラフデータの可視化ツールを利用すると、グラフデータのつながりをさまざまな方法で素早く探索できます。例えば、ノードやリレーションシップのフィルタリング、グラフの一部取得、プロパティの編集、パスのハイライト、ノードのカスタマイズなどです。
グラフの可視化ツールの要件としては次のようなものも挙げられます。
- グラフパターンに隠された意味の深堀り
- グラフビューの共有とグラフデータセットの探索
- グラフモデルやコンテンツの提示と出力
- (ビジネスユーザーが使い慣れている)Google検索と類似した自然言語検索
- ビルトインのクエリ提案と自動補完による、グラフの使い方の習得
Neo4jは、Neo4j Browserという開発者向けの視覚的なWebベースグラフブラウザに加え、Neo4j Bloomというコードレスグラフ可視化ツールを提供します。Neo4j Bloomでは、グラフ技術の初心者からエキスパートまでがデータを簡単に探索できます。また、サードパーティのソフトウェアベンダーやグラフコミュニティが提供する強力なNeo4j可視化ツールも存在します。
グラフデータサイエンス
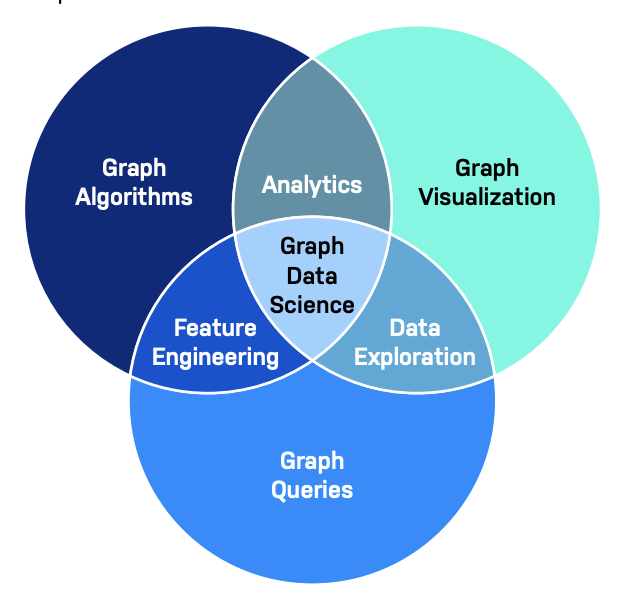
グラフデータベース技術の急成長を支えているものの一つがグラフデータサイエンスです。グラフデータサイエンスは、すべてのグラフデータの根底にある実世界の関係性に基づき、高度なグラフ分析、アルゴリズム、AI/MLを採用しています。これにより、従来の分析や統計が完全に見逃していたビジネスの根本的な原動力となるものを発見できるようになります。
グラフアルゴリズムによって、グラフデータ内のパターン、パス、クラスター、類似性を容易に特定できるようになります。これはビジネスに役立つ洞察やAIアプリケーションのサポートに活用できます。あらゆるグラフアルゴリズム、また、その使用方法に関するドキュメントやトレーニングを提供するグラフベンダーを選ぶことをおすすめします。
先進的な企業は、グラフデータサイエンスを利用して、より優れた、そしてより迅速な予測と意思決定を行っています。これにより、利益、製品開発、顧客満足を促進することでグラフデータベースへの投資を回収しています。
Neo4j Graph Data Scienceは、強力なグラフ分析、世界で最も広範なグラフアルゴリズムライブラリ、業界唯一の商用グラフ埋め込みを含んでいます。Neo4j Graph Data Scienceは、数百億ノードという大規模なプロダクション環境において、そのパワーと有効性を最大限に発揮できるように緊密に統合されており、他社の玉石混合型のソリューションとは一線を画します。
OLTP、OLAP、HTAPアプリケーションのサポート
従来のデータベースアプリケーションは、一般的に以下の2つの機能カテゴリーに分けられます。
- ビジネスを運営するためのトランザクションを行うOLTP(オンライントランザクション処理)アプリケーション
- データウェアハウス、ビジネスインテリジェンス、データマイニング、分析などを行うOLAP(オンライン分析処理)アプリケーション
グラフデータベースは多くの場合、トランザクション機能と分析機能を統合したHTAP(ハイブリッドトランザクション分析プラットフォーム)として利用されます。そのためには、幅広いユースケース、データインタフェース、デプロイ環境、プログラミング言語、ユーザーのスキルセットをサポートするグラフプラットフォームが必要です。
グラフプラットフォームを選択する際には、どれほど広範なテクノロジーやアプリケーションと統合できるのかを見極めることが重要です。さらに重要なのは、ビジネスで使用するアプリケーションとの連携がどれだけ充実しているかを知ることです。
Neo4jは、無数のトランザクションおよび分析アプリケーションと統合可能なため、容易に、貴社のアプリケーション戦略の重要な役割を担うことができます。
ACIDコンプライアンス、耐久性、一貫性
グラフデータベースは密接につながっているため、すべてのトランザクションのすべての部分を失敗なく完了させることが非常に重要です。この特性がACIDコンプライアンスと呼ばれるもので、Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、Durability(耐久性)の頭文字をとったものです。
トランザクションの一部だけが完了し、他の部分は失敗した場合、グラフデータベースは破損した状態のまま放置されることがあります。リレーションシップはぶら下がったままどこにもつながらず、グラフエンティティは存在しないプロパティを参照し、グラフのノードは一方からしか到達できない状態です。その後、グラフの更新や変更を行うと、データ破損が広がり、データベースの大部分が使用不可になります。
トランザクションによるデータ破損は、キーバリューストアのような非ネイティブのグラフデータベースで特に発生しやすくなっています。これは、高いスループットを実現するために、単一キーレベルでしかACIDをサポートしていないためです。この状態では、障害が発生するのはごく当然のことといえるでしょう。
ACIDに準拠していないデータベースで不完全なトランザクションが発生すると、グラフ内の関係を削除したり、さらには、関係が存在しないところに関係を表示したりする原因となります。グラフデータの破損は、その後のクエリでは検出されません。クエリ結果は正常に見えるからです。しかし、結果も、結果の元となる関係も、破損しているのです。そのため、気づかずにビジネスの計画や意思決定を誤ったデータに基づいて行なってしまう危険があります。これがグラフデータベース破損によって生じる最も恐ろしいことです。
Neo4jは100%ACIDに準拠しているため、グラフの破損を防ぎ、グラフデータの完全性を保持することで、ビジネス上の意思決定に活用できる信頼性の高いデータを提供します。
続きは後編の記事にてご覧いただけます。
![Neo4j[ホワイトペーパー]CCPA-and-Privacy-Compliance](https://no-cache.hubspot.com/cta/default/6168413/138d2d70-127d-4ca7-a670-031d789894da.png)



