
各Hadoop製品の特徴について
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
大規模データの分散処理プラットフォームであるHadoopは、Apache Hadoopを筆頭として、オンプレミスではCloudera/MapR/Hortonworksのような製品、クラウドではAmazon EMR/Azure HDInsight/Google Dataprocのような製品が登場しています。ここでは、各Hadoop製品を簡略に紹介し、Hadoopクラスタ―の調達とジョブ処理、Cloud型Hadoopの特徴について触れてみました。
Hadoop製品の紹介
Apache Hadoop
Apache Hadoopは、リレーショナルデータベースの最高峰であるデータウェアハウスエンジンが太刀打ちできないほどの大規模のデータを、ネットワーク上に並べた複数のサーバで分散処理することを可能にする、オープンソースのソフトウェアです。始まりはGoogleの技術です。Googleは、かつて誰も経験していない規模のデータを保存するためのストレージ技術とプログラミングモデルを論文として公開しました。
-
The Google File System
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung,2003
https://research.google.com/archive/gfs.html -
MapReduce: Simplified Data Processing on Large Clusters
Jeffrey Dean and Sanjay Ghemawat,2004
https://research.google.com/archive/mapreduce.html
この論文をきっかけに、効率的な大規模データ処理を渇望していた企業が次々と技術開発に乗り出しました。2006年、その有志が集まる形で、Apache財団の下でHadoop 0.1.0がリリースされました。現在、HadoopはApache財団のトッププロジェクトになっています。
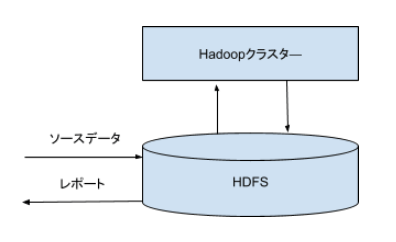
Hadoopの中身は、複数のサーバをネットワーク上に並べて利用する技術、大規模のデータを安全に保存し、かつ読み書きの性能も優れたストレージ技術(HDFS)、プログラムを簡単に書くためのフレームワークに関する技術、Hadoopクラスター上で利用可能なアプリケーションなど、多数のソフトウェアで構成されています。
現在、Apache Hadoopは、大規模のデータ処理ツールとして広く使われており、機能的にも、スタート時点に比べると見違えるほど進化しています。さらに注目すべきことは、Apache Hadoopは、大規模の分散データ処理を目指すソフトウェアのプラットフォームにもなっていることです。
プラットフォームとしてのHadoopは、数多くの素晴らしいソフトウェアの誕生を促しました。HiveのようにSQLそっくりのクエリでデータ処理が出来るもの、超ビッグなランダムIOに強いHBase、散乱している異なるパターンのデータ処理フレームワークを統合したSpark等々。
Apache Hadoopは、一般的にCloudera、MapR、Hortonworksなどのプロバイダーを通して利用出来ます。さらに、Hadoopクラスターを一時的な計算資源として提供するAzure HDInsightやAmazon EMR、Google Dataprocなど通しても利用出来ます。Apache Hadoopのオリジナルパッケージをそのまま利用することも出来ますが、すべて自己責任の下になります。
Cloudera/Hortonworks
ClouderaやHortonworksは、有償でHadoopディストリビューションを販売しているプロバイダー(かつ製品)です。これらは、Apache Hadoopをベースにして、ソフトウェアの種類や機能を自分達のビジネス感覚に合わせてカスタマイズしたり、インストールや運用周りで独自の機能を加えたりしています。
MapR
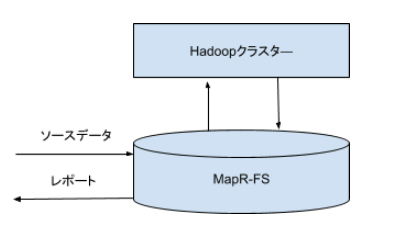
MapRは、ClouderaやHortonworksと仲間ですが、ちょっと異次元の存在です。MapRは、HDFSというHadoopの根幹になるファイルシステムを、なんと、独自に作り変えてしまいました(JavaからC言語で)。MapRファイルシステムというものです。HDFSがよっぼど嫌いだったのでしょう。おかげ様で、めちゃくちゃ速くなったと聞いています。
HDFSは、データを読み書きするとき、Linuxのシェルコマンド(lsとかcpとか)が使えません。hdfsのようなコマンドを使う必要があります。MapR-FSは、今まで使っていたツールやAPIがそのまま使えるメリットがあります。
Amazon EMR
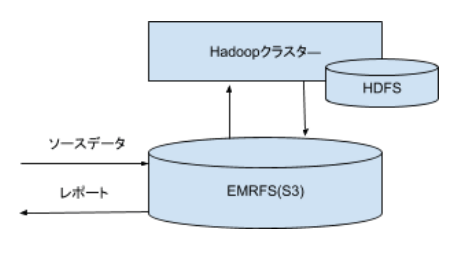
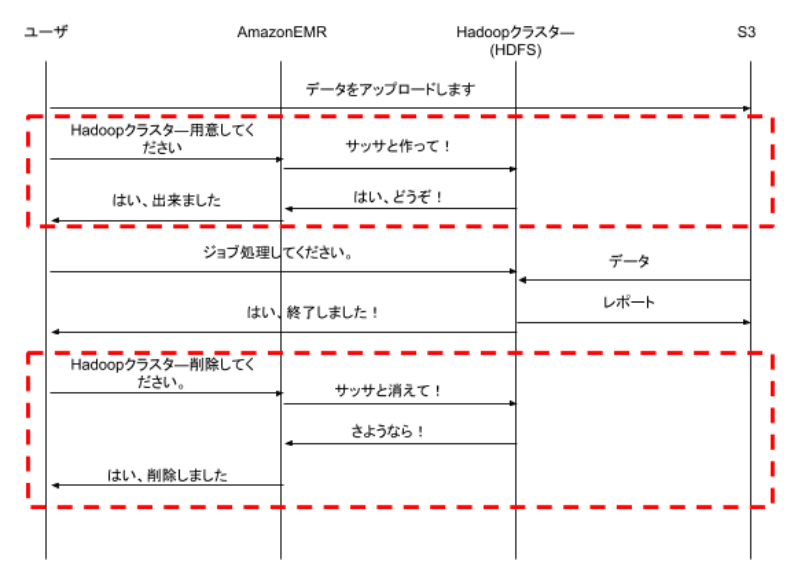
Amazon EMRは、AWSが提供しているHadoopサービスです。おそらく、Amazon EMRは、いわゆるCloud型Hadoopサービスの始まりです。Amazon EMRは、Hadoopクラスターは、必要なときに調達して利用する一時的な計算資源だというビジョンを提示しました。
Amazon EMRは、HadoopクラスターをEC2上に構築し、永続データはS3に保存します。
S3は、データを読み書きするための独自のインターフェースをもっています。ですから、Hadoopクラスターに依存しているHDFSとは違って、Hadoopクラスターが存在しない状態でもデータを読み書き出来ます。データが溜まってくると、Hadoopクラスターを調達して、S3にあるデータを読み込んで処理します。
Azure HDInsight
HDInsightのHadoopクラスターは、Microsoft Azureが提供しているCloud型Hadoopサービスです。Hadoopディストリビューションは、Yahooジャパンで採用したことで有名なHortonworksをペースにしています。対応OSは、Microsoftらしく、Linux版だけではなく、Windows版も提供していましたが、Windows版は2018年7月31日に終了することになっています。
HDInsightは、HadoopクラスターをAzureのVMに構築し、永続データはBlob Storage又はData Lake Storeに保存します。Blob Storage又はData Lake Storeは、簡単に説明すると、S3のような存在です。
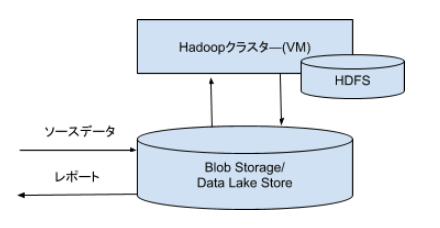
Blob Storageは、最大500TBまで使えるストレージで、それ以上の容量が必要な場合は、複数のストレージアカウントを利用します。Data Lake Storeは、論理的に容量無制限のストレージです。
Google Dataproc
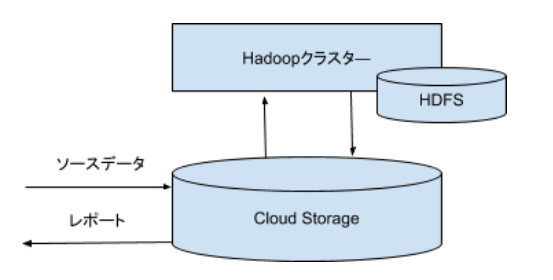
Dataproc は、Googleが提供しているCloud型Hadoopサービスです。Spark、Hadoop、Hive、Pigなど広く使われているアプリケーションを絞ってコンパクトなHadoopクラスターを提供しています。Googleは、Hadoopの起源にもなった技術を打ち出した会社で、大規模分散データ処理のための自社製品を既に持っています。ですから、Hadoopアプリケーションに依存せずにいく戦略なのかもしれません(あくまでの勝手な推測)。
DataprocはHadoopクラスターをGoogle CloudのVMに構築し、永続ストレージはGoogle Cloud Storageを利用しています。
Hadoopクラスタ―の調達とジョブ処理
オンプレミスの場合
Hadoopクラスターは、固定資産として大事に扱われます。何かあれば、エンジニアが徹夜をいとわず対応してくれます。夜間バッチしかないような用途でも、データは昼も夜もアップロードされるケースが多いので、Hadoopクラスターに火を入れておくことは、必要なことになります。
下の図を見てください。オンプレミスにおけるHadoopクラスターのライフサイクルとデータ蓄積、ジョブ処理のフローです。
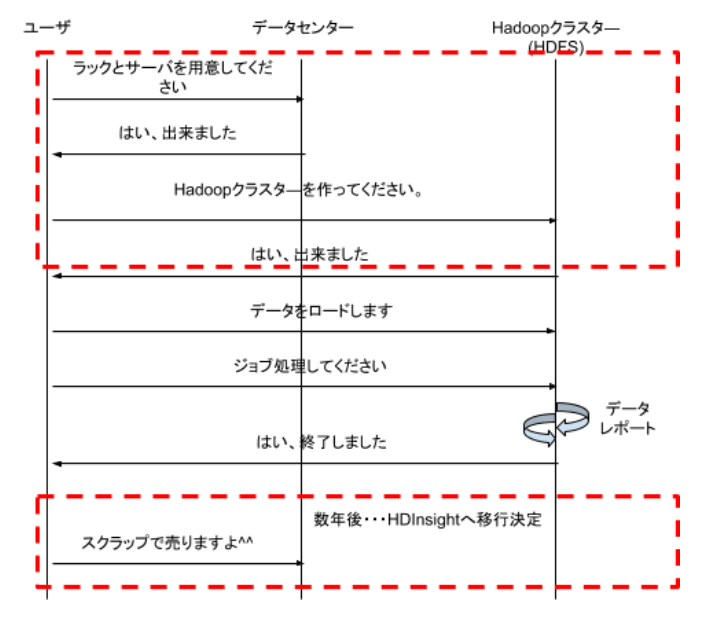
Hadoopクラスターの構築や維持管理が大変なそうだということは容易に想像出来ます。それでも、事情によっては必要になるかもしれません。
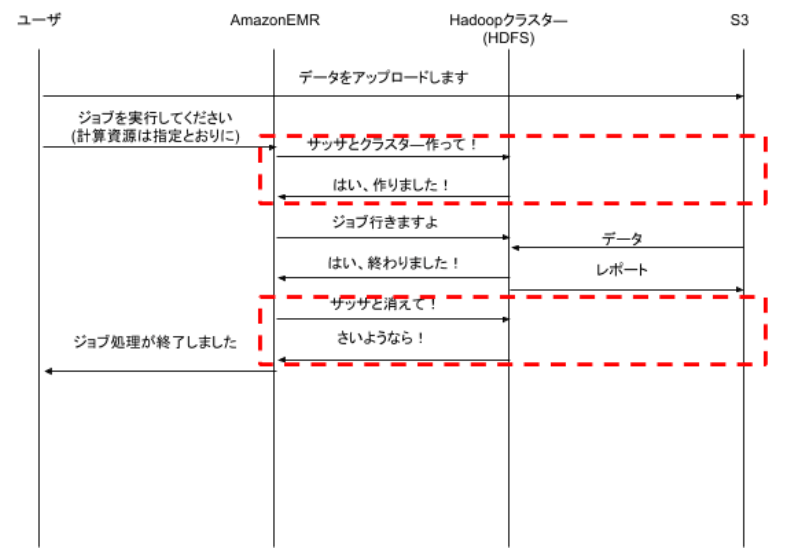
Amazon EMR
Amazon EMRは、一時的な計算資源としてのHadoopクラスターという思想に、最も徹底しています。
Hadoopクラスターの標準構成で、マスターノードは冗長化していません。そして、ワーカーノードなしのの構成も可能です。ワーカーノードなし構成は、学習やプログラムのデバッグ時に便利です(安い)。ワーカーノードの数は、Hadoopクラスターが稼働中の状態でも増減出来ます。さらに、オートスケールが利用出来ます。
Standard(1 Master(Active/Standby), 0 worker)
Standard(1 Master(Active/Standby), 1-N worker)
Amaon EMRでは、インタラクティブモードとバッチモード、2つのタイプのHadoopクラスターが利用出来ます。
インタラクティブモード
このモードでは、Hadoopクラスターを一時的な計算資源として利用することも、継続的にキープして利用することも可能です。
バッチモード
このモードでは、Hadoopクラスターを一時的な計算資源としてのみに利用します。しかも、ジョブの投入時に必要な計算資源を指示しておくと、その通りのHadoopクラスターを調達してジョブ処理を行い、ジョブ処理が終了した暁には、Hadoopクラスターも消えます。このモードで、Hadoopクラスターはまるで紙コップのように扱われます。
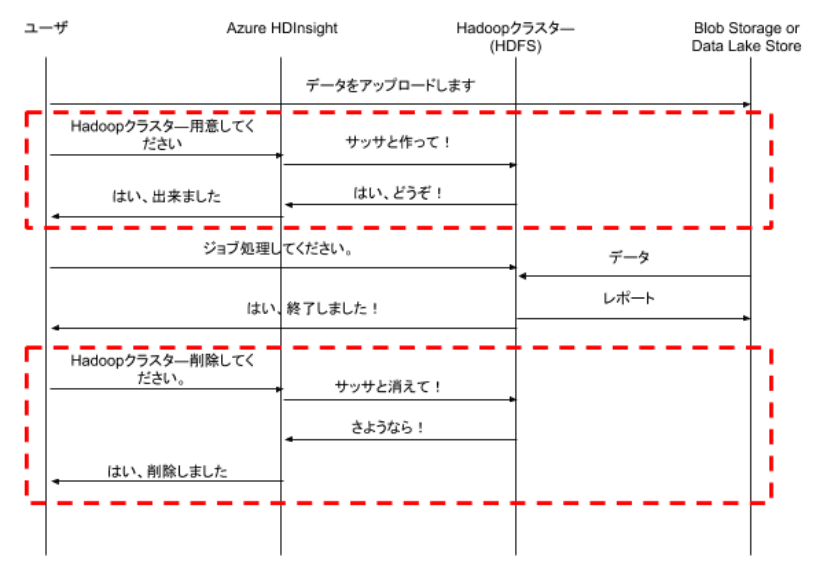
Azure HDInsight
HDInsightでHadoopクラスターは、一時的な計算資源として利用することもできれば、継続的にキープして利用することも出来ます。先ほど説明した、Amazon EMRのインタラクティブモードと同等な構成です。
クラスターの標準構成で、マスターノードが冗長化されており、シングルマスター構成やワーカーノードなしのの構成は許されません。ワーカーノードの数は、Hadoopクラスターが稼働中の状態でも増減出来ます。
Standard(2 Master(Active/Standby), 1 worker)
Standard(2 Master(Active/Standby), 1-N worker)
Amazon EMRのバッチモードような標準構成はありません。
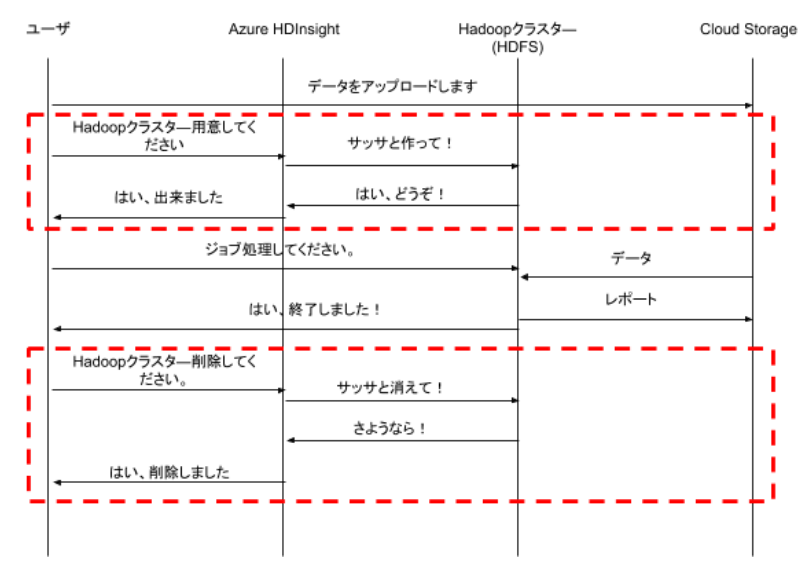
Google Dataproc
Google DataprocのHadoopクラスターも、一時的な計算資源として利用することもできれば、継続的にキープして利用することも出来ます。こちらの構成も、Amazon EMRのインタラクティブモードと同等な構成です。
Dataprocは、Hadoopクラスターの構成における柔軟性が最も優れています。シングルマスター構成、ワーカーノードなしの構成もできれば、マスターをクラスター化した堅牢な構成も出来ます。ワーカーノードの数は、Hadoopクラスターが稼働中の状態でも増減出来ます。
Standard(1 Master, 0 worker)
Standard(1 Master, 1-N worker)
Standard(3 Master(Cluster), 1-N worker)
Amazon EMRのバッチモードような標準構成はありません。
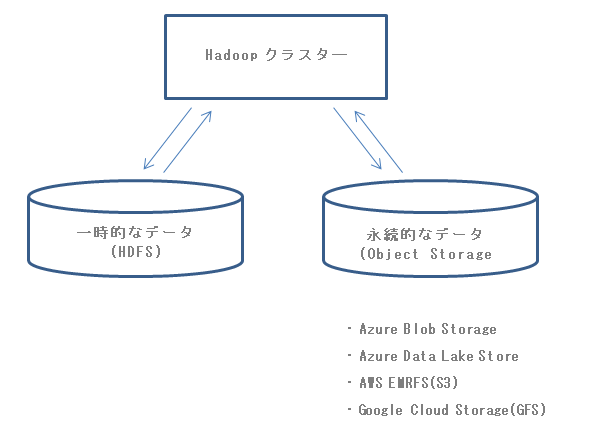
Cloud型Hadoopの特徴について
計算資源とストレージの分離
Cloud上で計算資源は、拘束している時間に比例して課金されます。通常、直ぐ使わない時には計算資源をストップして節約したいという発想に結びつきます。しかし、HadoopクラスターとHDFSは一体化されているために、Hadoopクラスターをストップするにも、シャットダウンするにも、HDFS上にあるデータの扱いが問題になります。シャットダウンすると、データは消えてしまうし、ストップしたらデータの読み書きが出来なくなります。
この問題に対してCloud型Hadoopサービスでは、データをネットワーク上のオブジェクトストレージに保存することで解決しています。もっと、細かいことを言うと、ソースデータだけではなく、データ処理結果やデータ処理のためのスクリプト、実行ファイルさえもオブジェクトストレージに保存します。
そうすることで、Cloud上のHadoopクラスターは、データを気にすることなく、エラスティックに必要な時に必要なだけの計算資源を調達出来るようになりました。さらに、Hadoopクラスターが稼働中の状態でワーカーノードの数も増減出来ます。
ただ、Azure HDInsightのHadoopクラスターやAmazon EMR、Google DataprocがHDFSをまったく使わないかと言うとそうではありません。一時的に使用するストレージとしては、HDFSが必要です。
一時的な計算資源としてのHadoopクラスター
Cloud上では、Hadoopクラスターとデータを保存するためのストレージを分離できることと、10分ぐらいの短時間でHadoopクラスターが調達出来ることで、Hadoopクラスターを必要な時だけの一時的な計算資源として利用できます。もちろん、Hadoopクラスターを継続的に利用することもできますが、アプリケーションのバージョン管理が必要な場合やクラスタ―で故障が発生した場合などは、新しいHadoopクラスタ―を調達するのが一般的です。
まとめ
今回、各社Hadoop製品の特徴を捉えることはできないかということでアプローチしましたが、正直なところ容易ではありませんでした。ただ、筆者がはじめてHadoopに関わった頃(2011年)に比べると、Hadoopクラスタ―を提供しているプロバイダーも利用できるアプリケーションの種類も爆発的に増えています。
オンプレミスではApache Hadoopを筆頭にCloudera、MapR、Hortonworksの順でプロバイダーが登場し、Cloud型Hadoopでは、Amazon EMR、Azure HDInsight、Google Dataprocの順でサービスを開始しています。
特に、様々なテータ処理パターンに合わせて最適なタイプのアプリケーション構成(ツールミックス)ができるようになっているなと感じます。2011年頃にさかのぼると、Hiveが使えないと、自前のMapReduceプログラムを書くしかないような状況でした。
まとめに入って振り返ってみると、各社のHadoop製品の特徴をとらえて、それぞれを浮き彫りにしているかどうかには自信がないまま、記事を締めています。それは、言い換えると、各社の製品がそれぞれの個性はあるものの、本質的なところでは殆ど差がない状態になっていると言えるかも知れません。
| 製品名 | 計算資源 | 主ストレージ | 課金 | 備考 |
|---|---|---|---|---|
| Apache Hadoop | オンプレミス | HDFS | ー | すべてのHadoopクラスターの母 |
| Cloudera | オンプレミス | HDFS | ー | 総合パッケージ |
| Hortonworks | オンプレミス | HDFS | ー | 総合パッケージ |
| MapR | オンプレミス | MapR-FS | ー | 総合パッケージ、Amazon EMRでも使える |
| AmazonEMR | VM | EMRFS(S3) | 従量課金(時間単位) | 総合パッケージ |
| Azure HDInsight | VM | Blob Storage/Data Lake Store | 従量課金(分単位) | 総合パッケージ |
| Google Dataproc | VM | Google Storage | 従量課金(秒単位) | 「Hadoopコア+Spark」のとてもシンプルなクラスタ― |
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



