
Docker、Jupyter Notebook、VCSツールで機械学習のチーム開発

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
こんにちは、クリエーションラインの朱です。
今回はデータ分析チームが機械学習プロジェクトを進めるにあたり行っているチーム開発方法についてお話をしたいと思います。
マネジメント視点ではなく、技術的な視点から共有したいと思います。
Jupyter Notebook使用を前提条件にしていますので、Jupyter Notebookを使わない方も軽くお読み頂ければと思います。
統合開発環境(IDE)を構築する(Dockerの導入)

Dockerはコンテナ型の仮想化環境を提供するオープンソースソフトウェアです。インスタンス(コンテナ)の起動が早く、動作がVMより軽いのが特徴です。コンテナ内の性能はローカル環境の性能とほぼ同じです。
DockerにはEnterprise版もありますが、今回は機能的には十分のCommunity版を使用します。
Dockerを導入する理由ですが、チームで開発を行いますので、各ツールのバージョンを統一するのが必須です。些細なバージョンの違いでも動きが違う可能性があるので、Dockerを導入することで各メンバーの開発環境を統一し、新メンバーの環境を速やかに構築できます。
(Java開発の場合、統合開発環境であるEclipseを使うのが同じ理由です。Eclipseと同じくstylesheet、formatの定義ができればさらに良いですが、個人的にemacsで整形をやっていますが、チーム開発にはあんまりお勧めできません)
通常、Dockerのコンテナを使うにはDockerイメージが必要です。今回使いたい環境は既存のDockerイメージも使用できるのですが、私のほうがpythonを開発言語で、sparkで並列処理も行ったりしますので、jupyter/pyspark-notebookイメージを利用してカスタマイズしてみました。
以下がその時のDockerfileです。
FROM jupyter/pyspark-notebook LABEL MAINTAINER "Jiajun Zhu" USER $NB_USER RUN pip install spark-sklearn # Install Keras RUN conda install --yes 'tensorflow=1.3*' RUN conda install --yes 'keras=2.0*' # Use the latest version of hyperopts (python 3.5 compatibility) RUN pip install https://github.com/hyperopt/hyperopt/archive/master.zip # Elephas for distributed keras RUN pip install elephas RUN mkdir ~/workspace
jupyterのDockerリポジトリに用途に応じてJupyter Notebookイメージが提供されているので、自分に合うDockerイメージを使えば良いでしょう。
以下jupyter/scipy-notebookを利用してJupyter Notebookの統合開発環境を軽く構築出来ました。
- Docker CEのインストール
apt-get install docker-ce
- イメージのpull
docker pull jupyter/scipy-notebook
- コンテナの起動
docker run --name=scipy-notebook -it jupyter/scipy-notebook
Dockerのコンテナを起動後にコンテナ内にJupyter Notebookのサーバが起動済みなので、メッセージに従ってJupyter Notebookを開きます。
Jupyter Notebookの書き方
Jupyter Notebookが機械学習の定番ツールとして広く使われています。但し、チーム規模が大きくなり、レビュー、履歴の確認等バージョン管理の要件が出てくる場合はJupyter Notebookの管理が面倒なことになります。ここのバージョン管理はVCSツールを使うことを想定しています。VCSはVersion Control Systemの略称で、現在広く使われているSVN、Git等がVCSツールです。
Jupyter Notebook管理の問題点
一般的には Jupyter Notebook の管理には以下のものが考えられますが、自分にはあんまり満足できないです。
1、Jupyter NotebookをそのままVCSツールで管理する
問題点:Jupyter NotebookがJSON形式のため、VCSツールから履歴を確認すると、JSONの比較になりますので、readability(可読性)がないと言ってもいいです。
2、Jupyter Notebookをpython形式に変換してからVCSツールで管理する
問題点:pythonのファイルなので、1の問題が解決できますが、開発がJupyter Notebook上で行うため、毎回変換の手間がかかります。
3、Jupyter NotebookをGoogle Drive等に置く
問題点:googleのcolaboratoryがGoogle Drive上でJupyter Notebookを動かすので、使い方としては存在しますが、ご存じの通り、Google Driveのスナップショット機能がとてもVCSツールとは言えません。
この問題に関しては機械学習がソフトウェア開発と違ってそんなにソースの履歴を追求しないので、ソースが重複しても、新しいNotebookをどんどん作れば良いので、困らないチームもいますが、自分としては、しっかりソースを共通化した上で、この問題を解決したいところです。
Jupyter Notebookのバージョン管理の問題点を改善するため、ソフトウェア開発で使われるMVC Design Patternを導入します。
Jupyter NotebookからModel(M)、View(V)とController(C)を分離しますが、ソースを分離すると、折角Jupyter Notebookにセルがあり、処理フローを記述できる素晴らしい機能があるのに使えなくなりますので、 処理フローのみをJupyter Notebookに残します。ユーザインタフェース(View)が存在しないので、Jupyter NotebookがView(V)であり、処理フローを制御するためのController(C)でもあります。下図のように、model_module.pyがModelを担当します。
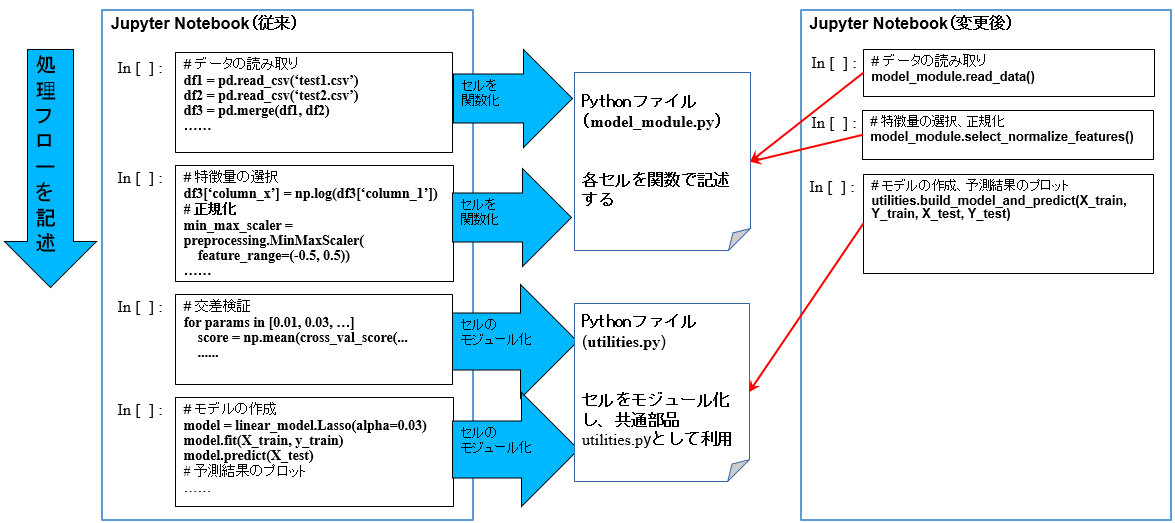
また、機械学習フロー上、前処理と学習アルゴリズムの呼び出し、交差検証等様々な処理がありますが、機械学習のプロジェクトは基本PDCAのサイクルを回しながらやって行きますので、PDCAの仮説検証のため前処理が一番変更される部分と思います。前処理をmodel_moduleに関数化し、学習アルゴリズムの呼び出し、交差検証等PDCAサイクルに影響されない部分をモジュール化し、完全にJupyter Notebookから分離します。
こうすることで、Jupyter Notebook自体がほぼソースコードを持たず、検証結果の表示と処理フローの記載のみを担当することになります。これらは履歴比較対象ではありませんので、チーム開発でVCS(git等)使う場合はJupyter Notebookの履歴比較(JSONの比較)が必要なくなります。処理フローに対応するソースがPythonファイルにあるので、比較もしやすいです。
また、機械学習プロジェクトではprototypingが非常に重要なプロセスです。実際にコンサルだけで終わってしまうプロジェクトも存在しますが、最近RPA(Robtic Process Automation)が流行っていて、エンドユーザが最終的には自分の仕事を自動化できるツールを求めています。このAIツールを納品するために、Design Thinkingで考えましょう。
上記のようにJupyter Notebookを書くことで、仮説検証後のprototypingが非常に楽になります。(Jupyter Notebookをそのまま使わせるのが別の話ですが)。部品がすべて出来ていて、Jupyter Notebook上の処理フローをprototypeに実装するだけです。しかも部品が既にテスト済みなので、品質も保証できます。こうしてエンドユーザに使ってもらってPDCAを回しながらprototypeをどんどん改善していくのが私の考えです。
終わり
以上でDocker、Jupyter Notebook、VCSで機械学習プロジェクトのチーム開発を紹介いたしました。
あくまで自己流ですが、参考にしてもらえたら幸いです。
では。



